mssql与mysql_mysql和mssql对比
由于工作原因,程序需要适配两种类型的数据库,所以把一些sql语句写法对比总结一下
本篇及后续随笔都将使用一个极其简单的场景(课室,学生,1对多)来演示,请先创建表
mysql
CREATE TABLE IF NOT EXISTS `class` (
`Id` int(11) NOT NULL,
`Name` varchar(50) NOT NULL DEFAULT '0',
PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS `student` (
`Id` int(11) NOT NULL,
`ClassId` int(11) NOT NULL,
`Name` varchar(50) NOT NULL DEFAULT '0',
PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
mssql
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Class](
[Id] [int] NOT NULL,
[Name] [nvarchar](10) NULL,
CONSTRAINT [PK_Class] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Student](
[Id] [int] NOT NULL,
[ClassId] [int] NULL,
[Name] [nvarchar](10) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
数据的插入语句mysql和mssql一样
INSERT Class (Id, Name) VALUES (1, '1年3班');
INSERT Class (Id, Name) VALUES (2, '1年1班');
INSERT Class (Id, Name) VALUES (3, '1年4班');
INSERT Class (Id, Name) VALUES (4, '1年2班');
INSERT Student (Id, ClassId, Name) VALUES (1, 3, '小a');
INSERT Student (Id, ClassId, Name) VALUES (2, 1, '小b');
INSERT Student (Id, ClassId, Name) VALUES (3, 2, '小c');
INSERT Student (Id, ClassId, Name) VALUES (4, 1, '小d');
INSERT Student (Id, ClassId, Name) VALUES (5, 2, '小e');
INSERT Student (Id, ClassId, Name) VALUES (6, 3, '小f');
INSERT Student (Id, ClassId, Name) VALUES (7, 2, '小h');
INSERT Student (Id, ClassId, Name) VALUES (8, 3, '小i');
INSERT Student (Id, ClassId, Name) VALUES (9, 4, '小j');
INSERT Student (Id, ClassId, Name) VALUES (10, 3, '小k');
INSERT Student (Id, ClassId, Name) VALUES (11, 3, '小l');
INSERT Student (Id, ClassId, Name) VALUES (12, 3, '小m');
INSERT Student (Id, ClassId, Name) VALUES (13, 4, '小n');
INSERT Student (Id, ClassId, Name) VALUES (14, 1, '小o');
INSERT Student (Id, ClassId, Name) VALUES (15, 4, '小p');
INSERT Student (Id, ClassId, Name) VALUES (16, 2, '小q');
p.s. mysql和mssql的表名不区分大小写,但是避免混淆,演示时mssql会首字母大写
一、分页写法
假设一页5条数据,取第1页
1.1 主流写法
mysql
select * from student limit 0, 5
mssql(分页前必须要order by 一下,否则报错,mysql没有这限制)
select * from Student order by Id offset(5 * 0) rows fetch next 5 rows only
1.2 用行号来分页
mysql:通过自定义变量使用行号
SELECT * from (SELECT @row:=@row+1 AS row, student.* FROM student, (select @row := 0) r ORDER BY student.Id) student WHERE row > (0 * 5) AND row <= ((0+1) * 5)
mssql:通过系统函数来使用行号
select * from (select ROW_NUMBER() over(order by Id) as row, * from Student) as Student where row > (0 * 5) and row <= ((0+1) * 5)
好像还有between and 的写法也行
二、取前几条数据
mysql没有top的写法,只能用limit 0, 1
select * from student limit 0, 1
mssql则有top
select top 1 * from Student
p.s. 鉴于mssql有top可以用,所以mssql可以改上面的行号分页方式,去掉row <= ((0+1) * 5)条件,使用top 5
三、插入数据时如果有条件,且数据源不来自旧表,mysql需要加上from dual而mssql则不用
给1年1班新增一个学生,但不要重复新增
mysql
INSERT INTO student(Id, ClassId, Name) SELECT 17, 1, '小r' FROM dual WHERE NOT EXISTS(SELECT 1 FROM student WHERE ClassId = 1 AND NAME = '小r')
mssql
INSERT INTO student(Id, ClassId, Name) SELECT 17, 1, '小r' WHERE NOT EXISTS(SELECT 1 FROM student WHERE ClassId = 1 AND NAME = '小r')
四、判断结果是否为null,若为null则用别的代替
mysql:IFNULL([可能为null的字段], 默认值)
mssql:ISNULL([可能为null的字段], 默认值)
五、mysql不支持in查询里面分页,但是mssql支持
SELECT * FROM student WHERE Id IN (SELECT Id FROM class LIMIT 0, 1)
mysql会报错“This version of MariaDB doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'”
六、mysql和mssql都有distinct和group by来去重,但是mssql的order by 后面的字段必须是distinct或group by中出现的字段,而mysql无此限制
SELECT DISTINCT class.* FROM class JOIN student ON class.Id = student.ClassId ORDER BY student.Name
SELECT class.* FROM class JOIN student ON class.Id = student.ClassId GROUP BY class.Id, class.Name ORDER BY student.Name
如上语句mysql正确执行,而mssql会报错“ORDER BY 子句中的列 "student.Name" 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中。”
mssql可以用以下语句实现同等效果
SELECT class.* FROM class JOIN student ON class.Id = student.ClassId GROUP BY class.Id, class.Name ORDER BY (select top 1 Name from Student where ClassId = class.Id)
注意,用distinct去重时(如下语句),连这样改排序条件都不行,会报错“如果指定了 SELECT DISTINCT,那么 ORDER BY 子句中的项就必须出现在选择列表中。”[mssql真坑]
SELECT DISTINCT class.* FROM class JOIN student ON class.Id = student.ClassId ORDER BY (select top 1 Name from Student where ClassId = class.Id)
这里总结为:多表查询只查主表,排序依据用子表的问题,mysql可以直接写,而mssql就必须转换一下,且用distinct还无法实现需求。
☆☆☆个人推测:在mysql中order by的执行顺序是在distinct和group by之前(网上写的都是之后,我认为是错的,各位看官可以查“mysql语句执行循序”),而mssql则是在这两之后,不然怎么会一定要求排序条件要是去重的字段呢(虽然这两个谁前谁后最终效果是一样的)。☆☆☆
*(代码场景)通常排序依据都是外部传入的,查询方法本身不能知道排序依据会不会有子表的,有多少个,这里若用mssql作为数据仓储就需要多这一步额外的判断,程序相对就复杂了。[mssql真坑]
七、多表查询,主表分页
查询:班级及班级所有学生的分页,假设分页大小是2,取第2页,要求按学生名字排序
查询出来的主表的数据应该是2条,但由于join了,所以总数据行数应该是多于2行的
主表class
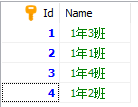
子表student

按照学生名字靠前的排序情况下,班级的顺序应该是“4班”、“3班”、“1班”、“2班”
7.1 join多1张表来限定主表的范围
mysql
SELECT class.*, student.* FROM class JOIN student ON class.Id = student.ClassId JOIN (
SELECT class.Id FROM class WHERE EXISTS(SELECT 1 FROM class JOIN student ON class.Id = student.ClassId WHERE 1=1) ORDER BY (select Name from student WHERE ClassId = class.Id LIMIT 0, 1) LIMIT 2, 2
) temp ON class.Id = temp.Id
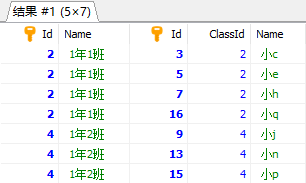
mssql
select Class.*, Student.* from Class join Student on Class.Id = Student.ClassId join (
select Class.Id from Class where exists(select 1 from Class join Student on Class.Id = Student.ClassId where 1=1) order by (select top 1 Name from Student where ClassId = Class.Id) offset (1 * 2) rows fetch next 2 rows only
) Temp on Class.Id = Temp.Id

7.2 使用distinct或者group by去重,效率较低,除非迫不得已,否则不用
mysql
SELECT class.*, student.* FROM
(
SELECT DISTINCT class.* FROM class JOIN student ON class.Id = student.ClassId ORDER BY student.Name LIMIT 2, 2
) AS class JOIN student ON class.Id = student.ClassId
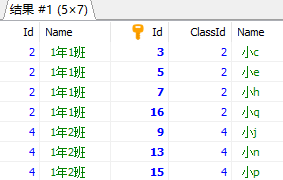
mssql
select Class.*, Student.* from
(
SELECT Class.* FROM Class JOIN Student ON Class.Id = Student.ClassId GROUP BY Class.Id, Class.Name ORDER BY (select top 1 Name from Student where ClassId = Class.Id) offset(1 * 2) rows fetch next 2 rows only
) as Class join Student on Class.Id = Student.ClassId
ORDER BY (select top 1 Name from Student where ClassId = Class.Id)
结果为
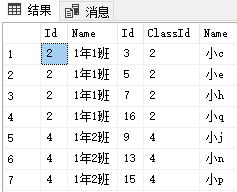
总结:7.1的写法较优,也是笔者推荐写法,当然,使用in (子查询查主表Id范围)的做法在mssql也是异曲同工之妙,但为了mysql也适用,还是用join多一张表的做法吧。7.2的相比于7.1而言,效率低了很多(数据量少时体验差不多的,只有数据量大和表的字段多时才是天差地别),要说优点的话,只有mysql的没有上面第六点那里的*(代码场景)的不便之处。
关于排序,还有一个细节,细心的读者会发现mysql和mssql查询的结果是有一点排序的差别的,虽然数据都是一样的;这是两种数据库引擎的默认排序问题,这里不深究,推荐做法是在最外层的查询中再写一次排序条件,如上面mssql的order by写法那样
八、多表更新
mysql的多表更新要把查询用到的表写在set前面,更新内容可以是任意一个表的字段
UPDATE class JOIN student ON class.Id = student.ClassId SET student.NAME = '小a', class.Name = '1年4班' WHERE student.name = '小a'
注意:多表更新时mysql不能更新查询子表,也就是如下这样写是错误的,会提示“The target table c2 of the UPDATE is not updatable”,更新c1还是可以的
update Class c1 JOIN (SELECT * FROM class where NAME = '不存在' order by Id LIMIT 0, 5) c2 ON c1.Id = c2.Id SET c2.Id = 100
mysql可以使用limit限定一次更新多少行,limit 写在最后面
update Class c1 JOIN (SELECT * FROM class where NAME = '不存在') c2 ON c1.Id = c2.Id SET c1.Id = 100 LIMIT 100
mssql的多表更新则是只能更新其中一个表,查询用到的表写在set后面,还要有from
UPDATE Student SET NAME = '小a' from Class JOIN Student ON Class.Id = Student.ClassId WHERE Student.Name = '小a'
注意:多表更新时mssql可以更新查询子表,但有两个限制
1、不能更新派生字段和常量,派生字段就是对某一个或几个字段进行了运算,如下会报错“派生表 'c2' 不可更新,因为派生表中的某一列是派生的或是常量。”
update c2 set c2.Id = 1 from Class c1 JOIN (SELECT (Id * 100) as Id FROM class where NAME = '1年3班' order by Id offset(5 * 0) rows fetch next 5 rows only) c2 ON c1.Id = c2.Id
2、不能更新多个表的字段,如下会报错“派生表 'temp' 不可更新,因为修改会影响多个基表。”
update temp set temp.cId = 100, temp.Id = 100 from (select Class.Id cId, Class.Name cName, Student.* from Class join Student on Class.Id = Student.ClassId) temp where temp.cName = '不存在'
mssql只能写查询子表来实现限定一次更新几行的效果
update c1 set c1.Name = '1年3班' from Class c1 JOIN (SELECT Id FROM class where NAME = '1年30班' order by Id offset(5 * 0) rows fetch next 5 rows only) c2 ON c1.Id = c2.Id
总结:mysql在更新方面比mssql要灵活
九、多表删除
两者的多表删除语句以及限制跟多表更新一样,还有个不值得一提的是mssql单表删除时,可以不写from
mysql
DELETE class, student FROM class JOIN student ON class.Id = student.ClassId WHERE student.name = '不存在'
注意:mysql虽然可以多表更新时用limit,但多表删除时却不能用limit(单表删除可以用),这有点奇怪。此时就必须像mssql那样使用查询子表的方式来“limit”了
mssql
DELETE c1 FROM class c1 JOIN (SELECT * FROM class where NAME = '不存在' order by Id offset(5 * 0) rows fetch next 5 rows only) c2 ON c1.Id = c2.Id
十、更新或插入
假设Id就是学生的学号,每个班的学号是不能重复的,现插入小s,班级是2班(班级Id=4),学号(学生Id)是18,此数据的写入处于一种高并发场景,比如某教职工快速点击插入
mysql
需要在建表时创建唯一索引,然后插入或更新时,只能根据唯一索引来判断是否同一条数据
INSERT INTO Student(Id, ClassId, NAME) SELECT 18, 4, '小s' ON DUPLICATE KEY UPDATE ClassId = 4, NAME = '小s';
注1:update 多个字段时,必须要用英文逗号隔开,用and隔开的会更新失败且MySQL不会有语法错误提示
mssql
不需要在建表时指定创建唯一索引,插入或更新时,再根据指定的几个字段判断是否是同一条数据(mssql终于有地方比mysql好的了)
merge Student with(HOLDLOCK) astargetusing (select 18 Id, 4 ClassId, '小s' Name) assource
on (target.Name= source.Name) --when matched then updateset ClassId = 4, Name = '小s'when not matched then insert (Id, ClassId, Name) values(18, 4, '小s');
十一、跨库查询的表名写法
mysql:[库名].[表名]
mssql:[库名]..[表名]
p.s. 此随笔只要笔者踩到新坑就会更新