第二章 Intel 64 及 IA-32架构
第二章 Intel 64 及 IA-32架构
2.1 Intel 64 和 IA-32架构简史
下面的几个小节总结并概述了从IA-32到Intel 64架构的主要主要技术革命:从8086处理器到最新的Intel Core 2 Duo,Core 2 Quad以及Intel至强处理器5300和7300系列。为1978年发行的处理器创造的目标代码(object code,obj文件)依然能够在最新的Intel 64 及 IA-32架构处理器上运行。
2.1.1 16位处理器和分段(1978)
在IA-32架构家族出现之前是16位处理器的时代–8086和8088;8086具有16位的寄存器和16位外部数据总线,20位的寻址能力和1MB的地址空间;8088和8086类似,但8088只有8位的外部数据总线;
8086/8088位IA-32架构引入了分段技术。使用分段技术时,16位段寄存器包含一个指向最高64KB内存段的指针。使用4个段寄存器,8086/8088处理器可以最多寻址256KB空间,而不需要在段之间切换。20位地址(可以由一个段寄存器和一个附加的16位指针组成)提供1MB范围的寻址能力。
2.1.2 Intel 286处理器(1982)
Intel 286处理器位IA-32架构引入了保护模式(protected mode),保护模式使用段寄存器作为一个描述符表的选择器/指针。描述符提供24位的寻址能力(16MB),支持段交换位基础的虚拟内存管理和大量的保护机制。这些机制包括:
- 段限制检测
- 仅读和仅执行段选项
- 四级优先级
2.1.3 Intel 386处理器(1985)
Intel 386处理器是IA-32架构家族的第一款32位处理器。Intel 386处理器引入了32位寄存器,用于保存操作数和寻址。Intel 386处理器的每一个32位寄存器的低16位保留了早期处理器16位寄存器的特性,支持向后兼容。该处理器同时提供了虚拟8086模式,允许以更高的性能执行为8086/8088处理器设计的程序。
另外,Intel 386处理器支持以下特性:
- 支持最高4GB物理内存的32位地址总线
- 分段内存模型和扁平内存模型
- 分页:固定4KB页大小,提供虚拟内存管理的方法
- 支持并行阶段(流水线)(support for parallel stages)
2.1.4 Intel 486处理器(1989)
Intel 486处理器通过扩展Intel 386处理器的指令解码和执行单元为5个流水线阶段提供了更好的并行执行能力。每个阶段可以和其他阶段平行执行,最高5条指令在不同的阶段执行。
另外,该处理器添加了以下特性:
- 8-KB片上一级缓存,提升了在一个时钟周期内可执行的指令百分比;
- 整合x87FPU
- 节能和系统管理功能
2.1.5 Intel奔腾处理器(1993)
Intel奔腾处理器添加了第二条执行流水线以实现超标量性能(两条流水线,u和v,可以在一个时钟周期内执行两条指令)。片上一级缓存分离成为了指令缓存和数据缓存(I Cache和D Cache)。数据缓存使用MESI协议来支持更高效率的写回(之前的处理器使用的写通)。增加了分支预测(使用片上分支表)来提升循环结构的性能。
另外,该处理器增加了以下特性:
- 提升虚拟8086模式性能的扩展,同时支持4MB和4KB页面;
- 内部128位和256位数据通路,提升内存数据转移;
- burstable外部数据总线(例如,写回)增加到64位
- APIC,以支持多处理器系统
- 双处理器模式,以支持耦合程度较小的双处理器系统
奔腾处理器家族后续版本引入了MMX技术(multi media extesion)。Intel MMX技术使用单指令,多数据执行模型来对打包在一个64位寄存器整形数据执行并行计算。
2.1.6 P6处理器家族(1995-1999)
P6处理器基于超标量微处理器体系结构。P6家族微架构的一个设计目标在于显著的高于奔腾处理器的性能,而使用相同的0.6微米,四层金属BICMOS制造工艺。该处理器家族包括以下处理器:
- Intel奔腾Pro处理器,三路超标量(three-way superscalar),使用并行执行技术,该处理器在每个时钟周期内平均可以解码,派发,完全执行三条指令。奔腾Pro处理器在超标量实现中引入了动态执行(微数据流分析,乱序执行,高级分支预测,预测执行)。通过增加缓存该处理器性能得到了进一步的提升。和奔腾处理器相同,该处理器具有相同的两个8KB一级缓存,另外增加了256KB片上二级缓存;
- 奔腾二代处理器:在P6家族处理器上引入了MMX技术,同时增强了封装和一些硬件。一级数据和指令缓存增大到了16KB,二级缓存支持256KB、256KB、1MB。二级缓存通过一个半频率总线链接到处理器上,支持多种低功耗状态以在空闲时减少能量消耗例如AutoHALT,Stop-Grant,Sleep,Deep Sleep;
- 奔腾二代至强处理器:该处理器结合前几代Intel处理器的优良特性,包括4路,8路可扩展的和运行在全频率后端总线的2MB的二级缓存;
- Intel 赛扬(celeron)处理器:该处理器聚焦于PC市场,同时集成了128KB的二级缓存,使用PPGA(塑料针栅阵列)封装,降低了系统的设计成本;
- Intel 奔腾三处理器:在IA-32架构上引入了SSE指令集,SSE扩展通过提供新的128位寄存器集合和SIMD处理打包的单浮点数的能力,扩展了SIMD执行模型引入的MMX技术;
- 奔腾三至强处理器:通过对全速、片上和高级传输缓存的增强扩展了IA-32处理器的性能;
2.1.7 Intel奔腾4处理器家族(2000-2006)
Intel奔腾4处理器家族基于Intel NetBurst微架构;Intel奔腾4处理器引入了SSE2扩展。Intel奔腾4处理器3.4GHz,支持超线程技术,引入了SSE3扩展。Intel奔腾4处理器至尊版(Intel奔腾4处理器 5xx和6xx序列)引入了64位架构,支持超线程技术。Intel奔腾4处理器672和662引入了Intel虚拟技术。
2.1.8 Intel至强处理器(2001-2007)
Intel至强处理器(除双核Intel至强处理器LV,Intel至强处理器5100系列外)基于Intel NetBurst微架构。该系列IA-32(Intel 64)处理器设计用于多处理器服务系统和高性能工作站。Intel至强处理器MP引入对超线程技术的支持。64位Intel至强处理器3.6GHz(800MHz系统总线)引入了Intel64位架构。Dual-Core Intel至强处理器引入了双核技术。Intel至强70xx系列处理器引入了Intel虚拟化技术(在一块磁盘不同分区运行不同的操作系统)。
Intel至强5100系列处理器引入了节能,高性能的Intel酷睿微架构。该处理器基于Intel64架构,包含了虚拟化技术,双核技术。Intel至强3000系列处理器同样基于Intel酷睿微架构。Intel至强5300系列处理器在一个封装中引入了四个处理器核心,同样基于酷睿微架构。
2.1.9 Intel奔腾M处理器(2003-2006)
Intel奔腾M处理器家族是高性能,低功耗的移动处理器家族,其增强的微架构基于先前的IA-32 Intel移动处理器。该系列产品旨在延长电池寿命,并与平台创新无缝集成,从而实现新的使用模式(如扩展移动性、超薄外形和集成无线网络)。
其扩展的微架构包括:
- 支持动态执行
- 高性能,低功耗的核心,采用Intel铜互连工艺技术制造
- 片上,一级32KB指令缓存,32KB写回式数据缓存
- 先进的分支预测和数据预取逻辑
- 支持MMX,SSE,SSE2指令集扩展
- 400或533MHz,源同步处理器系统总线
- 使用增强Intel降频技术的高级功耗管理
2.1.10 Intel奔腾处理器至尊版(2005)
Intel奔腾处理器至尊版引入了双核技术。该技术支持高级的硬件级多线程。该处理器基于Intel NetBurst微架构且支持SSE,SSE2,SSE3,超线程技术,并且是64位架构。
2.1.11 Intel酷睿双核及酷睿单核处理器(2006-2007)
Intel酷睿双核处理器提供高效的能源管理,可延长电池使用的低功耗的双核性能设计。该家族和单核Intel酷睿处理器在奔腾M处理器家族上提除了增强的微架构。
该增强的微架构包括:
- Intel智能缓存,支持双核之间高效的数据共享
- 更先进的解码和SIMD技术
- Intel动态功耗管理和增强的深度睡眠模式以支持更低的能源消耗
- Intel增强的散热管理器,具有数字热传感器接口
- 支持功耗优化的667MHz总线
双核至强处理器LV和Intel酷睿双核处理器基于相同的微架构,支持IA-32架构。
2.1.12 Intel至强处理器5100,5300系列和Intel酷睿二代处理器(2006)
Intel至强3000,3200,5100,5300和7300系列处理器,Intel奔腾双核处理器,Intel酷睿二代至尊版,Intel酷睿二代四核处理器,Intel酷睿二代双核处理器支持Intel64架构;都基于高性能,低功耗的65nm制程Intel酷睿微架构。Intel酷睿微架构包含下列革新特性:
- Intel宽动态执行,以提高性能和执行吞吐
- Intel智能功耗能力,减少能源消耗
- Intel高级智能缓存,支持双核心间的数据共享
- Intel智能内存访问,提升了数据带宽并隐藏了内存访问的延迟
- Intel高级数字媒体加速,使用多代SSE扩展提升了应用性能
Intel至强5300系列,Intel酷睿二代至尊处理器QX6800系列,Intel酷睿二代四核处理器支持Intel四核技术
2.1.13 Intel至强处理器5200,5400,7400系列和Intel酷睿二代处理器(2007)
Intel至强5200,5400和7400系列处理器,Intel酷睿2代四核Q9000系列处理器,Intel酷睿2代双核处理器E8000系列支持Intel 64架构;都基于增强的使用45nm制程的Intel酷睿微架构。增强的Intel酷睿微架构支持以下更优的特性:
- 基-16的除法器,更快的系统原语进一步的提高了Intel宽动态执行性能
- 更高级的Intel智能缓存,最大可增大50%的二级缓存
- 128位的shuffler引擎极大的提升Intel数字媒体加速和SSE4性能
Intel至强5400系列处理器,Intel酷睿二代四核处理器Q9000系列支持Intel四核技术;Intel至强处理器7400系列提供最高六核心和最高16MB的三级缓存
2.1.14 Intel凌动(atom)处理器(2008)
Intel凌动处理器第一代产品使用45nm制程。其架构为Intel Atom微架构,该架构为超低功耗设备优化。Intel凌动微架构特色在于两条顺序流水线,这两条流水线极大的降低了功耗,提升了电池使用时间,支持超小规格(ultra-small form factor,更小规格的电路,更大的集成度)。最初的Intel凌动处理器和后续处理器包括D2000,N2000,E2000,Z2000,C1000系列,支持下列特性:
- 增强的Intel降频技术
- 超线程技术
- 具有动态缓存大小的深度降功耗技术
- 支持最多到SSE3的指令集扩展
- 支持Intel虚拟化技术
- 支持Intel64架构
2.1.15 Intel凌动处理器家族基于silvermont微架构(2013)
Intel凌动C2xxx,E3xxx,S1xxxseries基于Silvermont微架构。基于Silvermont微架构的处理器支持最高到SSE4.2,AESNI和PCLMULQDQ的指令集扩展;
2.1.16 Intel酷睿i7处理器(2008)
Intel酷睿i7 900系列处理器支持Intel64架构;基于Nehalem微架构,使用45nm制程。Intel酷睿i7处理器和Intel至强5500系列处理器支持一下特性:
- Intel睿频技术(Turbo Boost Technology)最大程度的在散热允许范围内将其转化为性能;
- Intel超线程技术和四核技术的结合,支持4核心8线程;
- 专用能源管理单元,降低活动和空闲功耗;
- IMC(整合内存控制器),支持三通道DDR3内存;
- 8MB Intel智能缓存;
- Intel QPI(QuickPath interconnect, 处理器(不是指核心)和处理器的数据交换通道),提供点对点的芯片连接;
- SSE4.2,SSE4.1指令集;
- 第二代Intel虚拟化技术;
2.1.17 Intel至强7500系列处理器(2010)
Intel至强7500和6500系列处理器基于Nehalem微架构,使用45nm微制程。支持2.1.16节描述的相同特性,加上下述特性:
- 单个处理器封装最多可达8核心
- 至多24MB的Intel智能缓存
- 提供Intel可扩展内存互联通道和Intel7500可扩展内存缓冲连接到系统内存
- 先进的RAS,支持软件可恢复机器检查结构
2.1.18 2010 Intel酷睿处理器家族
2010 Intel酷睿处理器家族涵盖酷睿i7,i5,i3处理器,基于westmere微架构,32nm制程。包含以下特性:
- 使用Intel超线程技术和Intel睿频技术提供智能性能;
- 增强的Intel只能缓存和集成的内存控制器(iMC)
- 智能能源管理
- 片上集成的45nm集显
- 指令集范围最多支持到AESINI, PCLMULQDQ, SSE4.2和SSE4.1
2.1.19 Intel之前处理器5600系列(2010)
Intel之前处理器5600系列基于Westmere微架构,32nm制程。支持2.1.16节列出的相同特性,以及下列特性:
- 最多支持六核
- 最多支持12MB的智能缓存
- 支持AESNI, PVLMULQDQ, SSE4.2和SSE4.1指令集
- 灵活的跨处理器和IO的Intel虚拟化技术
2.1.20 第二代Intel酷睿处理器(2011)
第二代Intel酷睿处理器涵盖Intel i7,i5和i3处理器,基于Sandy Bridge微架构,32nm制程。支持下列特性:
- 酷睿i5和i7处理器的睿频技术
- Intel超线程技术
- 增强的Intel智能缓存和集成内存控制器
- 处理器图形和内置的视觉能力,如Intel Quick Sync Video, Intel Insider
- 指令集最多支持到AVX,AESNI,PCLMULQDQ,SSE4.2和SSE4.1
Intel至强处理器E3-1200同样基于Sandy Bridge微架构;
Intel至强处理器E5-2400/1400基于Sandy Bridge-EP微架构;
Intel至强处理器E5-4600/2600/1600基于Sandy Bridge-EP微架构,支持多路(单主板多个CPU,NUMA架构);
2.1.21 第三代Intel酷睿处理器(2012)
第三代Intel酷睿处理器涵盖Intel 酷睿i7,i5和i3处理器,基于Ivy Bridge微架构。Intel至强处理器E7-8800/4800/2800 v2和Intel至强处理器1200 v2同样基于Ivy Bridge微架构
Intel至强处理器E5-4600/1400 v2基于Ivy Bridge-EP微架构
Intel至强处理器E5-4600/1600基于Ivy Bridge-EP微架构,支持多路。
2.1.22 第四代Intel酷睿处理器(2013)
第四代Intel酷睿处理器涵盖Intel酷睿i7,i5和i3处理器,基于Haswell微架构。Intel至强处理器E3-1200 v3同样基于Haswell微架构。
2.2 具体发展信息
2.2.1 P6家族微架构
奔腾Pro处理器引入了一个新的微架构,通常被称为P6处理器微架构。P6微架构后来在片上L2 Cache进行了优化,称为高级传输缓存(Advanced Transfer Cache)。
该微架构是一个三路超标量体系结构的,流水线的架构。三路超标量体系结构意味着使用并行处理器技术,该处理器可以在单个时钟周期中解码,派发,完全执行三条指令。为了处理这个数量级的指令流,P6处理器使用分离的,12级超流水线,支持乱序指令执行。下图展示了带有高级传输缓存(L2 Cache)的P6处理器微架构流水线的概念视图。

为了保证给指令执行流水线提供平稳的指令和数据流支持,P6处理器微架构使用了两级缓存结构。L1 Cache包含一个8KB的I Cache和一个8KB的D Cache,两者都和流水线紧密连接。L2 Cache支持256KB,512KB或者1MB的静态随机存取器,L2 Cache通过一条全速的64位缓存总线和处理器核心连接。
P6处理器微架构的核心在于成为动态执行的乱序执行机制。动态执行包含三个数据处理概念:
- 深度分支预测:分支预测允许处理器解码分支以外的指令,以保持流水线满载。P6处理器是实现了高度优化的分支预测算法来预测指令的走向;
- 动态数据流分析:动态数据流分析需要对通过处理器的数据流进行实时分析以确定依赖关系,同时确定指令乱序执行的可能性。乱序执行核心可以监控许多指令同时以最优使用处理器执行单元的顺序执行这些指令,而同时保证数据完整性;
- 预测执行:指的是处理器能够执行条件分支以外的尚未确定的指令并最终按原有指令流顺序提交结果的能力。为了实现预测执行,P6处理器微架构将指令派发,指令执行与结果提交分离开来。处理器的乱序执行核心使用数据流分析来执行指令池中所有可执行的指令,并将结果存储在零时寄存器中。retirement单元线性搜索指令池查找已经完成的且与其他指令没有数据依赖的或者没有未确定的分支预测的指令。当查找到已完成的指令时,retirement单元以他们开始的顺序提交这些指令的结果到内存或者IA-32寄存器(处理器的8个通用寄存器以及8个x87 FPU数据寄存器),并将其从指令池中移除。
2.2.2 Intel NetBurst微架构
Intel NetBurst微架构支持:
-
快速的执行引擎
-
以处理器频率两倍运行的算术逻辑单元ALU
-
基本的整形操作能在1/2个时钟周期内完成派发
-
超流水线技术
-
深度流水,为PC和服务器启用业界领先的时钟频率
-
频率余量和可扩展性以在未来保持业界领先地位
-
高级的动态执行 - 深度的,乱序,预测执行引擎
-
至多126条指令处于执行状态
-
流水线中至多48个加载(load)和24个存储(store)
增强的分支预测能力
-
减少更深度流水中错误预测的代价
-
高级的分支预测算法
-
4K的分支目标阵列
-
新的缓存子系统
-
L1 Cache
-
高级的执行跟踪缓存(Execution Trace Cache)存储已解码的指令
-
执行跟踪缓存从主执行循环中移除解码延迟
-
执行跟踪缓存将程序执行流路径合并于单行
-
低延迟的D Cache
-
L2 Cache
-
全速,8路片上 L2 高级传输缓存(Advance Transfer Cache)
-
带宽和性能随着处理器频率提升
-
高性能的,四倍并发的总线接口连接到Intel NetBurst微架构系统总线
-
支持四倍并发,可扩展的总线时钟以实现至高4倍有效速度
-
一秒8.5GB的带宽
-
超标量体系结构以支持平行
-
重命名的扩展寄存器以避免寄存器命名空间限制
-
64B的缓存行大小
下图为NetBurst微架构概观,该微架构流水线由三部分组成(1)前端流水,(2)乱序执行核心,(3)retirement单元

2.2.2.1 前端流水
前端以程序顺序向乱序执行核心提供指令流,执行下列功能:
- 指令预取
- 取指(未被预取的指令)
- 将指令解码为微指令(micro-op)
- 为复杂指令生成微指令和特殊指令
- 从执行跟踪缓存(execution trace cache)中传递已经解码的指令
- 使用极为先进的分支预测
该流水为解决高速,流水设计的微处理器中的一般问题设计。其中两个问题造成了主要的延迟:
- 从目标地址取指并解码的时间
- 缓存行中间的分支或分支目标导致解码带宽的浪费
流水线中的跟踪缓存的操作解决了上述问题。解码引擎不断的取指和解码,并构建微指令序列称为跟踪(trace)。在任何时间,多个跟踪(预取的分支)存储在跟踪缓存中。跟踪缓存搜索活动分支之后的指令。如果该指令也是预取分支中的第一条指令,那么从内存层次中提取和解码指令的过程就会停止,而预取分支就会成为新的指令来源。
跟踪缓存和解码引擎使用相互配合的分支预测硬件,利用分支目标缓冲区(Branch target buffer, BTBs)对分支目标的线性地址进行预测并尽快获取分支目标。
2.2.2.2 乱序执行核心
乱序执行核心乱序执行执行指令的能力是支持并行的关键因素。该特性使得处理器可以重排指令,因此如果一个微指令延迟,其他的微指令可以继续处理。处理器使用了几个缓冲区来平滑微指令流。
其核心理念在于促进并行执行能力。在上述条件下,处理器在单个时钟周期内可以派发至多6条微指令(这超过了跟踪缓存和retirement 微指令的带宽)。大多数的流水线每个时钟周期可以执行一个新的微指令,因此对每个流水线来说多条指令可以同时执行。许多算术逻辑单元(ALU)指令每个周期可以启动两次;许多浮点指令可以每两个周期执行一次。
2.2.2.3 Retirement单元
Retirement单元从乱序执行核心中接收已经执行完成的微指令的结果,并处理结果,以便按原有的程序顺序更新体系结构状态。
当一条微指令执行完成并写入结果时,该微指令退休(retire)。每个时钟周期内,至多可以退休三条微指令。处理器中的ROB(reorder buffer)缓存已经完成的微指令,顺序的更新体系结构状态,并处理器异常的顺序。Retirement单元同时跟踪分支,并向BTB(Branch target buffer)更新分支目标信息。BTB清除不再需要的预取微指令序列。
2.2.3 Intel酷睿微架构
Intel酷睿微架构引入了以下特性:
- Intel动态执行:每个处理器核心以高吞吐量取指,派发,执行以支持每个周期三条指令的retirement
- 14级流水
- 三个算数逻辑单元
- 四个译码器,支持每周期五条指令的译码
- macro-fusion和micro-fusio以提升前后端吞吐
- 每周期峰值派发微指令可达6条
- 每周期峰值微指令retirement可达4条
- 高级分支预测
- 栈指针跟踪,提升函数/程序执行跳入和跳出性能
- Intel高级智能缓存:为二级缓存到CPU核心提供更高的带宽,为单线程和多线程应用优化的性能和灵活性
- 最大4MB的二级缓存,16路组相联
- 为多核心和多线程优化的执行环境
- 256bit宽的内部数据通道,支持L2 Cache到L1 DCache更高的带宽
- Intel智能内存访问:根据数据访问模式从内存中预取数据,以减少乱序执行的Cache-miss
- 硬件预取(模块):减少一级/二级缓存cache miss的延迟
- 内存消歧(memory disambiguation)以提升预测执行引擎的效率
- Intel高级数字媒体家属:128bit SIMD指令和浮点运算性能的提升
- 大多数128bit SIMD指令可在单周期内执行完成
- 每个周期至多8条浮点操作
- 三个端口用于SIMD指令的派发执行
Intel Core 2 Extreme,Intel Core 2 Duo processors和Intel Xeon processor 5100系列在Intel酷睿微架构上实现了双核,每个核心子系统功能示意如下:

2.2.3.1 前端
Intel酷睿微架构前端为Intel动态执行引擎提供了以下增强:
- 取指单元预取指令到指令队列为译码单元提供了稳定的指令支持;
- 译码单元每个周期可译码4条指令,或在Macrofusion下每周期译码5条指令;
- Macrofusion融合两条指令作为一条译码指令(micro-ops)以提升译码吞吐;
- Microfusion融合两条微指令为一条微指令一替身retirement吞吐;
- 指令队列缓存短循环指令以提升效率;
- 栈指针追踪提升执行程序/函数跳入和跳出性能;
- 分支预测单元采用专用硬件处理不同类型的分支预测以提升分支预测性能;
- 高级分支预测算法指导取指单元取指进行译码;
2.2.3.2 执行核心
Intel酷睿微架构执行核心采用超标量和乱序执行技术,以提升IPC(instructions executed per cycle),采用了以下特性以提高执行效率和吞吐:
- 至多每周期6条微指令的派发;
- 至多每周期4条指令retire;
- 三个算逻单元;
- SIMD指令可通过三个端口派发;
- 大多数SIMD指令可以在单周期内完成;
- 至多每周期8次浮点操作;
- 高级分支预测算法指导取指单元取指进行译码;
2.2.4 Intel凌动微架构
Intel凌动微架构通过以下技术最大化单线程和多线程工作的处理性能:
- 高级微指令执行:
- 单个微指令执行从译码到retirement,包括仅寄存器相关,load,store语义指令;
- 16级,为吞吐和减少功耗优化的顺序流水;
- 双流水,以支持译码,派发,执行和retirement每周期两条指令;
- 高级栈指针以提升执行函数跳入/跳出(返回)的执行性能;
- Intel智能缓存
- 512KB,8路组相联的二级缓存;
- 为多线程和单线程优化的执行环境;
- 从L2到L1级缓存使用256bit宽的内部数据通路一替身高带宽;
- 高性能的内存访问
- L1和L2高性能的硬件预取器,按处理器接下来可能的访问预取数据以减少cache miss;
- Intel数字媒体加速
- 两个端口为执行单元派发SIMD指令;
- 大多数SIMD指令可以在单周期内完成;
- 至多每周期6次浮点操作;
- Sage Instruction Recognition(SIR),语序延迟浮点运算相对于整形指令乱序retire;
2.2.5 Nehalem微架构
Nehalem微架构为Intel酷睿i7处理器许多特性提供了基础,其建立在45nm Intel酷睿微架构的成功,提供了以下特性增强:
- 增强的处理器核心
- 分支预测和预测错误恢复的增强;
- 增强的循环指令流处理以提升前端性能并减少功耗;
- 乱序执行引擎中更深的缓冲以更好的并行;
- 增强的执行单元,加速CRC,string/text处理和数据shuffle
- 智能内存访问
- 集成内存控制器(iMC)提供更低延迟的内存访问和可扩展的内存带宽;
- 新的缓存层次结构组织,共享的L3缓存,减少了探听竞争开销(snoop traffic);
- 两级且更大容量的TLB;
- 快速的未对其内存访问;
- 超线程技术
- 每个物理核心可支持两个物理线程;
- 利用了4-wide execution engine,更大的L3缓存,更大的内存带宽;
- 专用的功耗管理革新
- 将微控制器和优化的嵌入固件集成以管理功耗;
- 嵌入式实时热,电流,功耗传感器;
- 集成功耗控制门以控制每个核心的功耗;
- 降低内存、链路子系统功耗通用性;
2.2.6 Sandy Bridge微架构
Sandy Bridge微架构基于Intel酷睿微架构和Nehalem微架构的成功,提供以下功能特性:
- Intel高级向量扩展(AVX)
- 在128bitSIMD扩展上的256bit浮点指令集扩展,在原有代码基础上提供最多两倍的性能提升;
- 非破坏性目的编码提供更灵活的编码技术;
- 256bit AVX代码,128bit AVX代码和遗留的128bit SSE代码间灵活的迁移和共存;
- 增强的前端和执行引擎
- 分离的ICache组件以支持更高的前端带宽并减少错误分支的代价;
- 高级分支预测技术;
- macro-fusion;
- 更大的动态执行窗口;
- 多精度整型计算增强;
- LEA带宽提升;
- 总体上执行延迟的减少(读端口,写回冲突,旁路延迟,部分stall);
- 更快的浮点异常处理;
- XSAVE/XRSTORE性能提升,新的XSAVEOPT指令;
- 为更宽数据通路的缓存结构增强
- 内存操作的两个对称端口使带宽加倍;
- 通过增加更多的缓存同时处理更多的in-flight load和store操作(store buffer,invalid queue)
- 内部带宽支持每周期两条load,一条store指令执行;
- 更进一步的预取技术;
- 更高带宽和更低延迟的LLC架构;
- 更高带宽的片上互联通信架构;
更多的AVX资料,参见5.13节,Intel Advanced Vector Extensions和第十四章 Programming with AVX,FMA和AVX2
2.2.7 SIMD指令
从奔腾Ⅱ和带有MMX技术的奔腾处理器家族开始,Intel 64和IA-32架构已经引入了6个扩展指令集以支持SIMD操作。这些扩展包括MMX技术,SSE扩展,SSE2扩展,SSE3扩展,补充SIMD扩展3,SSE4。这些扩展都提供了一组指令在整数向量或浮点向量(packed interger/packed floating-point)实现SIMD操作。
SIMD整型操作使用64bit MMX或128bit XMM寄存器,SIMD浮点操作使用128bit XMM寄存器。下图总结了不同的SIMD扩展操作的不同数据类型和这些数据类型如何在MMX和XMM寄存器打包存放。
Intel MMX技术在奔腾Ⅱ和带有MMX技术的奔腾处理器家族中引入。MMX指令在MMX寄存器中打包的字节,字,双字整型上执行SIMD操作。这些指令对整型数组和整形流数据操作的应用相当有用。
SSE扩展在奔腾三代处理器中引入。SSE指令操作XMM寄存器中打包的单精度浮点型或者MMX寄存器中打包的整形数据。一些SSE指令提供了状态管理,cache控制,内存排序操作。其他SSE指令针对操作数组的应用。
SSE2扩展和超线程技术一同在奔腾四代处理器中引入,SSE3提供了13指令加速SSE,SSE2和x87-FP数学计算能力。SSSE3在Intel志强5100系列处理器和酷睿2处理器中引入,提供了32条指令加速SIMD整形操作。
SSE4扩展提供了54条指令,其中47条称为SSE4.1,SSE4.1在Intel志强5400系列和Intel酷睿2 QX9650处理器中引入。其余的7条SSE4扩展指令称为SSE4.2
AESNI和PCLMULQDQ引入了7条新的指令,其中6条是基于AES加密/解密标准的算法加速原语,称为AESNI,PCLMULQDQ指令用于加速通用块加密,可以对两个64为位宽的二进制数执行无进位乘法。
Intel 64架构允许四代128-bit SIMD扩展访问至多16个XMM寄存器,IA-32提供8个XMM寄存器。
Intel高级向量扩展(AVX)为前面的SIMD指令集扩展提供了全面的架构增强,AVX引入了下列架构增强:
- 支持256bit宽(正好一个cache line/操作需要对齐)的向量和SIMD寄存器集
- 256bit浮点指令增强,至多是128bit指令集的两倍性能
- 指令语法支持通用三操作数语法,以提升指令编程灵活性和高效率的新指令集编码
- 对遗留的128bitSIMD指令集扩展到的增强,以支持三操作数语法并简化高级语言表达式的编译器向量化
- 向前兼容支持256bit AVX,128bit AVX代码和遗留的128bit指令代码

2.2.8 Intel超线程技术
Intel超线程技术是为了提升IA-32架构处理器在多线程操作系统和应用或者单线程多任务应用下的性能而开发的。该技术使得单个物理处理器使用共享的执行资源可以并发运行两个甚至更多独立的指令流(IBM POWER架构单个核心上可以并发的跑8个线程)。
Intel超线程技术是IA32架构处理器多线程能力的一种,和使用分离的物理封装的多线程不同,其使用一个处理器核心中的共享资源提供硬件级的多线程能力。结构上,一个支持Intel超线程技术的IA32处理器包含两个或者更多的逻辑处理器,每个都有自己的IA32架构状态。每个逻辑处理器有全套的IA32数据寄存器,段寄存器,控制寄存器,debug寄存器和大部分的MSRs组成,同时每个逻辑处理器都有自己的可编程中断控制器。

上图是支持Intel超线程的处理器和传统的双处理器系统的对比。和传统的使用两个或多个独立其物理IA32处理器的多处理器系统不同,支持超线程技术的IA32处理器中的逻辑处理器共享物理处理器的核心资源,包括执行引擎,系统总线接口。上电并初始化后,每个逻辑处理器可以被独立的引导去执行一个特定线程,中断或者halted。
Intel超线程技术通过单个物理核心上提供两个或者多个逻辑处理器,充分的利用了现代操作系统和高性能应用中的进程级和线程级并行,而显著的提升了处理器性能。该技术允许一个物理处理器上同时的执行两个或多个线程,每个逻辑处理器使用该物理处理器中的资源执行来自一个应用程序线程的指令流。该物理处理器核心使用乱序的指令调度一最大化的在每个周期内使用执行单元,而并发的执行两个线程。
2.2.8.1 一些实现说明
所有的Intel超线程技术配置需要:
- 支持超线程技术的处理器
- 能利用该技术的芯片组和BIOS
- 操作系统优化
更多关于超线程技术的资料:https://www.intel.com/content/www/us/en/homepage.html
在固件层(BIOS):初始化逻辑处理器的基本程序和传统的多处理器平台相同,在Multiprocessor Specification, Version 1.4中描述的多处理器系统上电和初始化的机制同样在支持超线程的处理器中使用。
为双处理器或多处理器平台设计的操作系统可能使用CPUID来确定硬件多线程功能是否存在,并确定其提供的逻辑处理器数量。现有的为双处理器或多处理器平台设计的操作系统可以在支持超线程技术的处理器上正确运行,但还是推荐进行一些代码修改以优化其性能(参见第七章 多处理器管理)
2.2.9 多核技术
多核技术是IA32架构系列处理器多线程能力的另一种。多核技术通过在一个封装中提供更多的处理器核心而增强处理器多线程能力。
Intel奔腾处理器Extreme版是第一个引入多核技术的处理器,该处理器同时支持多核和超线程技术,这意味着其最多可以提供四个逻辑处理器。双核志强处理器支持多核,超线程并支持多处理器平台。Intel奔腾D处理器同样支持多核技术,但不支持超线程技术,这意味着其最多提供两个逻辑处理器,每个逻辑处理器都独占其处理器核心的执行资源。
Intel酷睿2处理器,Intel志强3000系列,5100系列处理器和Intel酷睿双核处理器支持功耗优化的多核技术。这些处理器包括一个共享的二级缓存,二级缓存支持两个核心间高效率的数据共享而减少了对系统总线的争用。

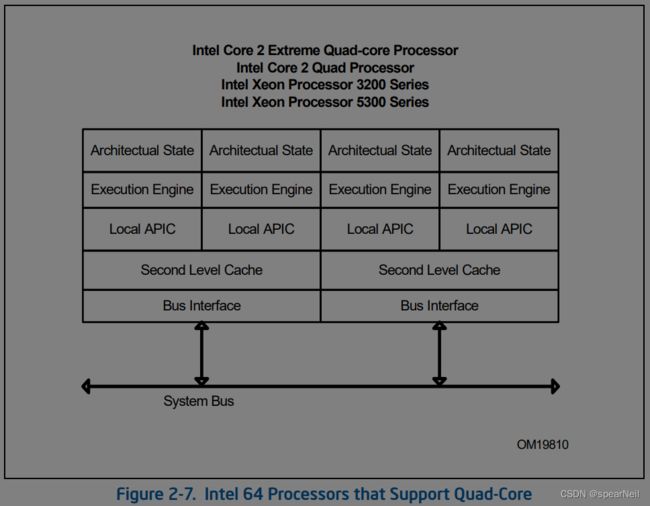

2.2.10 Intel 64架构
Intel 64架构增大软件的线性寻址空间到64bit,并支持至多52bit的物理地址空间,同时还引入了一种新的操作模式(IA-32e mode)。IA-32e模式可以在两种子模式下执行:(1)兼容模式允许64为操作系统不加修改的运行大多数遗留的32位软件,(2)64位模式是的64为操作系统可以运行访问64bit地址空间的程序
64-bit模式下,应用程序可能访问:
- 64bit线性地址空间
- 附加的8个通用寄存器(GPRs)
- 附加的8个SIMD(SSE,SSE2,SSE3,SSSE3)相关寄存器
- 64位宽的GPRs和指令指针
- 统一字节寄存器寻址
- 快速中断优先级机制
- 一种新的指令指针相对寻址模式
Intel 64体系结构处理器支持现有的IA-32软件,因为它能够运行所有非64位的遗留软件IA-32体系结构支持的模式,大多数现有的IA-32应用程序也以兼容模式运行。
2.2.11 Intel虚拟化技术
Intel 64和IA-32架构的Intel虚拟化技术提供了一种虚拟化的扩展,称为虚拟机扩展(VMX)。一个支持VMX的Intel 64或IA-32平台可以像多个虚拟系统/虚拟机一样工作。每个虚拟机可以独立的运行操作系统和应用。
VMX还为用于管理虚拟机操作的新系统软件层(虚拟机监视器VMM)提供编程接口,参见 Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3C
Intel酷睿i7处理器为Intel虚拟化技术提供了以下增强:
- 虚拟处理器ID以减少VMM管理转换(transition)的开销
- 扩展的页表以减少VMM管理内存虚拟化的转换次数
- 减少虚拟机转换的延迟
2.3 Intel 64及IA-32处理器发展迭代
参见手册
2.4 建议从即将上市的产品中一处的指令集和功能
无
2.5 已经移除的Intel指令集架构和功能

HLE还保留了编程接口,可以继续使用,但是实际使用的是HTM。