An Overview of Cross-media Retrieval: Concepts, Methodologies, Benchmarks and Challenges 笔记
文章目录
- 1. 论文简介
- 2. 跨模态检索系统的定义
-
- 数学定义:
- 跨模态检索和其他方法的区别:
- Common Space Learning
-
- 1. 传统的统计相关分析方法
-
- 统计相关分析方法具体介绍
- 统计相关分析方法优缺点
- 2. 基于深度学习DNN的方法
-
- 基于 DNN 的方法摘要
- 基于 DNN 的方法总结以及优缺点
- 3. 跨模态图正则化的方法
-
- 图正则化的相关方法
- 图正则化的优缺点
- 4. 度量学习的方法
-
- 基于度量学习相关方法
- 度量学习的优缺点:
- 5. 排序学习的方法
-
- 基于排序学习的相关方法
- 排序学习方法的优缺点
- 6. 字典学习的方法
-
- 基于字典学习的相关方法
- 基于字典学习的优缺点
- 7. 跨模态哈希模型
-
- 跨模态哈希具体方法
- 跨模态哈希优缺点
- 其他方法
- Cross-media Similarity Measurement
-
- Graph-based Methods
-
- 基于图的具体方法
- 基于图的优缺点
- Neighbor Analysis Methods
-
- 基于近邻的具体方法
- 基于近邻方法的优缺点
- 其他方法
-
- Relevant feedback analysis
- Multimodal topic model
- Cross-Media Retrieval Dataset
-
- Wikipedia Dataset
- XMedia Dataset
- NUS-WIDE Dataset
- Pascal VOC 2007 Dataset
- Clickture Dataset
- 实验部分
-
- 特征提取和数据集划分
- 评价指标和对比模型
- 实验结果
- 挑战和未解决的问题
-
- 1. 数据集构建和基准标准化
- 2. 提高精确度和效率
- 3. 深度神经网络的应用
- 4. 语义关联信息的开发
- 5. 跨媒体检索的实际应用
- 总结
这是一篇发布于 2018 年的文章,重点探讨如何解决跨模态检索中的 “media gap”。本文将现有的跨模态检索方法划分成两大类:公共空间学习和跨媒体相似度测量,进行了详细的介绍。同时还介绍了数据集,评价指标,并且通过实验对比了现有方法的结果。最后提出了未来的挑战和未解决的问题。
我对这篇文章进行了翻译和阅读,总结了其中的重点内容,并且附上了引用文献的链接。
| 论文名称 | An Overview of Cross-media Retrieval: Concepts, Methodologies, Benchmarks and Challenges |
|---|---|
| 作者 | Yuxin Peng, Xin Huang, and Yunzhen Zhao |
| 会议/出版社 | IEEE Trans. Circuits Syst. Video Technol. 28(9): |
| 在线pdf readpaper | |
| 其他 | 实验室主页 |
1. 论文简介
跨模态检索算法主要的挑战是“media gap”,不同媒体类型的表示是不一样的使得难以进行度量。
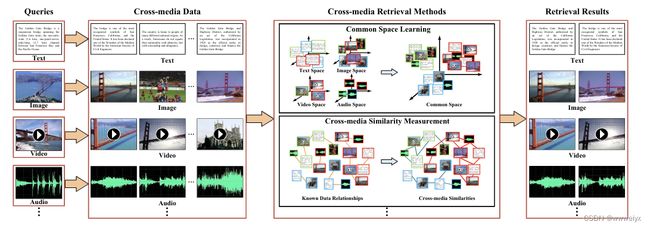
如上图所示,解决这一问题的方法可以分为两大类:
- common space learning methods:目前主流的方法,将不同模态的特征映射到公共空间中,在公共空间中进行度量
- cross-media similarity measurement:根据数据关系,直接计算跨模态相似度
2. 跨模态检索系统的定义
数学定义:
本文使用 X X X 和 Y Y Y 来表示两种模态的数据。
训练数据集可以表示为 D t r = { X t r , Y t r } \mathcal{D}_{t r}=\left\{X_{t r}, Y_{t r}\right\} Dtr={Xtr,Ytr} 。模态类型一: X t r = { x p } p = 1 n t r X_{t r}=\left\{\boldsymbol{x}_p\right\}_{p=1}^{n_{t r}} Xtr={xp}p=1ntr(其中 n t r n_{t r} ntr 代表该模态样本的个数 x p x_p xp 代表第 p p p 个实例),模态类型二: Y t r = { y p } p = 1 n t r Y_{t r}=\left\{\boldsymbol{y}_p\right\}_{p=1}^{n_{t r}} Ytr={yp}p=1ntr(数学的表示同上)。
两种模态数据 x p x_p xp 和 y p y_p yp 间存在着相同的关系。他们的语义类别标签分别表示为 { c p X } p = 1 n t r \left\{c_p^X\right\}_{p=1}^{n_{t r}} {cpX}p=1ntr 和 { c p Y } p = 1 n t r \left\{c_p^Y\right\}_{p=1}^{n_{t r}} {cpY}p=1ntr。其中包含了无监督,半监督和有监督的方法,决定在训练过程中是否使用标签。
目标是在测试集 D t e = { X t e , Y t e } \mathcal{D}_{t e}=\left\{X_{t e}, Y_{t e}\right\} Dte={Xte,Yte}, X t e = { x q } q = 1 n t e X_{t e}=\left\{\boldsymbol{x}_q\right\}_{q=1}^{n_{t e}} Xte={xq}q=1nte, Y t e = { y q } q = 1 n t e Y_{t e}=\left\{\boldsymbol{y}_q\right\}_{q=1}^{n_{t e}} Yte={yq}q=1nte上计算跨模态的相似性, sim ( x a , y b ) \operatorname{sim}\left(\boldsymbol{x}_a, \boldsymbol{y}_b\right) sim(xa,yb)
跨模态检索和其他方法的区别:
- 与图像标注的区别:跨模态检索的文本是指句子和段落描述,而不是图像标示的概率
- 与 image/video caption 的区别:跨模态检索是搜索已经存在的数据而不是生成数据。更关注多种模态间的联系。
- 与迁移学习的区别:不存在源域和目标域,所有模态类型都被平等对待
Common Space Learning
本章重点介绍了基于公共空间的跨模态检索算法,这是当前跨模态检索的主流。遵循的理念是,共享语义的数据存在着潜在的相关性,使得构建一个公共空间成为可能。
作者将现有的方法划分成了七大类,分别是:
- 传统的统计相关分析方法:使用统计相关分析方法学习投影矩阵,将不同模态数据映射到公共空间中。
- 基于深度学习DNN的方法:结合深度学习提取不同模态特征,并通过不同方式进行对齐。
- 跨模态图正则化的方法:引入图正则化,更好地表示不同模态数据间的关系。
- 度量学习的方法:通过度量学习,保持不同模态特征的在公共空间中的空姐结构
- 排序学习的方法:通过优化排序损失,直接提升检索的精度
- 字典学习的方法:通过构建字典,不同媒体类型的稀疏系数中获取跨模态的相关性
- 跨模态哈希模型:通过哈希量化,提升大规模数据数据集的检索速度
1. 传统的统计相关分析方法
传统的统计相关分析方法是常用空间学习方法的基本范式和基础,主要是通过优化统计值来学习线性投影矩阵。
统计相关分析方法具体介绍
具体方法包括:
CCA 典型相关分析(canonical correlation analysis)是最具有代表性的方法。将不同模态的数据分别看做两个数据集,学习到一个子空间,使两组异构数据间的相关性最大化。
CCA 是早期最流行的 baseline,因此产生了许多相关的变体。CCA 本身是无监督算法,不适用语义标签。Rasiwasia et al^(A new approach to cross-modal multimedia retrieval)^,Costa et al^(On the Role of Correlation and Abstraction in Cross-Modal Multimedia Retrieval)^ 和 GMA^(Generalized Multiview Analysis: A discriminative latent space)^ 算法尝试了语义标签的引入,提升了算法精度,是 CCA 算法的有监督扩展。Multi-view CCA ^(A Multi-View Embedding Space for Modeling Internet Images, Tags, and their Semantics)^将高级语义作为 CCA 的第三视图,multi-label CCA^(Multi-label Cross-Modal Retrieval)^ 应用于多标签场景。
此外传统的统计相关算法还有 CFA 最小化公共空间中的 Frobenius 范数。
统计相关分析方法优缺点
传统方法优缺点:
- 优点:训练效率高,易于实施。
- 缺点:线性投影的方法很难模拟现实数据的复杂性。大部分方法只能模拟两种数据类型,但跨模态检索通常涉及两种以上的媒体数据。
2. 基于深度学习DNN的方法
基于 DNN 的方法摘要
本节主要介绍 DNN 在跨模态检索上的应用方法,重点摘要其中几种方法:
-
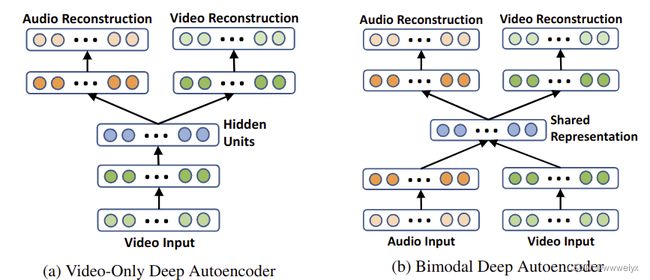
Ngiam et al:将受限玻尔兹曼机(RBM)的扩展应用于公共空间学习,并提出了双模深度自动编码器,其中两种不同媒体类型的输入通过共享代码层,以学习跨媒体相关性并保存重建信息。
-
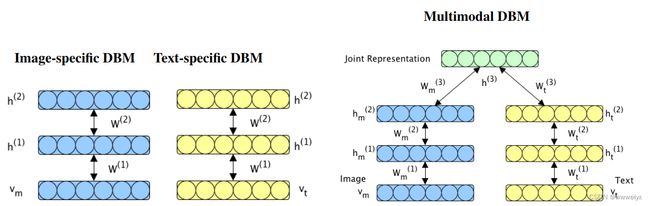
Srivastava et al:采用两个独立的深度玻尔兹曼机(DBM)对不同媒体类型特征分布进行建模,并在两个模型的顶部附加一层作为联合表示层,该层可以通过计算联合分布来学习公共空间。
-
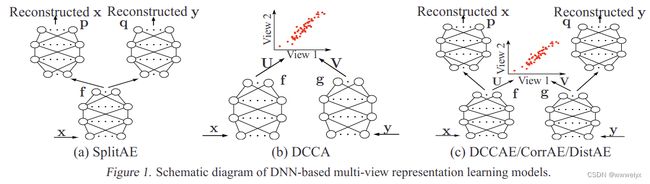
DCCA:将 DNN 和 CCA 方法结合起来。和 CCA 不同的是,DCCA 先通过两个神经网络进行编码,再通过编码层之间的相关约束使总相关性最大化。

-
DCCAE:在 DCCA 上进行改进,使用自编码器的 code 层输出进行相关性分析,最大化不同模态间特征的相关性。
-
Corr-AE:提出了 Corr-AE 算法,使用自编码器来解决跨模态检索的问题。两个自编码器分别对图像特征和文本特征进行重建,并且在 code 层最小化不同模态编码的关联误差,学习到模态间的联系。
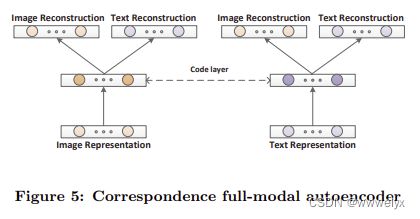
-
CMDN:将同一模态的信息生成两种互补的独立表示,分别是模态内的表示和模态间的表示。然后使用分层学习的方式进行学习,提高了检索的精度。
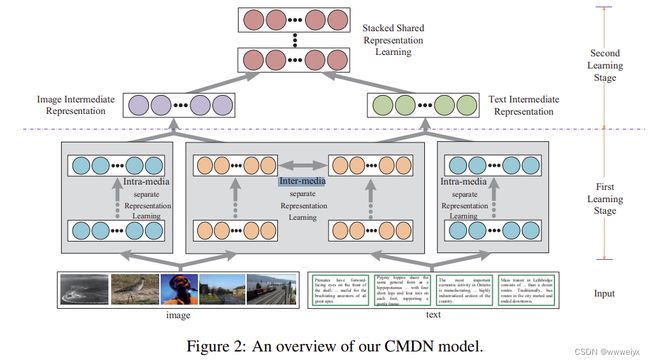
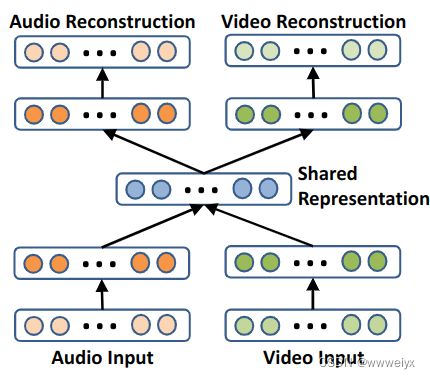
基于 DNN 的方法总结以及优缺点
这些跨模态检索的方法的结构可以分成两种:
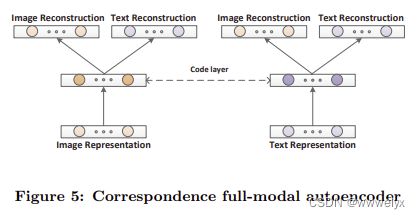
- 第一种方法可以看成一个网络,不同的模态通过一个共享层进行映射。
- 第二中方法可以看成两个子网络,在两个子网络的编码层是互相耦合的。
上述方法的输入的多媒体类型基本只有两类,而更多输入类型的方法是未来研究挑战的重点
除了 DNN 外,还有 RNN,LSTM,GAN 等网络结构,它们的设计思想对跨模态检索有一定的参考价值
3. 跨模态图正则化的方法
图正则化广泛应用于半监督学习中,它从部分标记的图的角度考虑半监督学习问题。
边权重表示图中数据之间的相似性,目标是预测未标记顶点的标签。图正则化可以丰富训练集并使解决方案更加平滑。
图正则化的相关方法
Zhai等人提出 JGRHML 联合图正则化异构度量学习。他们将图正则化纳入跨媒体检索问题中,使用学习到的度量空间中的数据构建联合图正则化项。然后他们提出了联合表示学习(JRL)方法,能够在一个统一的框架中共同考虑相关性和语义信息,支持多达五种媒体类型。具体而言,他们为每种媒体类型构建一个单独的图,其中边权重表示同一媒体类型的标记和未标记数据的相似性。通过图正则化,JRL丰富了训练集,并联合学习每种媒体类型的投影矩阵。由于JRL为不同的媒体类型分别构建了不同的图,Peng等人进一步提出在公共空间中构建统一的超图,从而不同的媒体类型可以相互促进。该做法的另一个重要改进是利用媒体实例分割的细粒度信息,有助于利用跨媒体数据的多级相关性。
图正则化的优缺点
- 优点:图正则化可以描述跨媒体数据的各种相关性,如语义相关性、媒介内相似性和媒介间相似性。图正则化可以在一个统一的框架中自然地建模两种以上的媒体类型
- 缺点:图的构建过程通常会导致较高的时间和空间复杂性,特别是在具有大规模跨媒体数据的现实场景中。
4. 度量学习的方法
度量学习可以使用数据之间的相似/不相似信息优化特征的表示。将跨模态数据视为单一模态数据的扩展,引入度量学习,让相似的实例特征靠近,不相似的实例特征原理,优化检索的效果。
基于度量学习相关方法
JGRHML 就是将度量学习引入跨模态检索代表,除了构建图正则化之外,JGRHML 还引入了跨模态的度量损失。
注:除了本文提到的 JGRHML 之外,后面还有很多跨模态检索的工作都使用了度量学习的方法。如 DSCMR,cross-model center loss 等。我也做过将度量学习应用与跨模态检索的工作,具体论文还在 under review。
度量学习的优缺点:
- 优点:度量学习在跨模态的共同空间中保留了语义的相似性/不相似性,这对于跨媒体数据的语义检索非常重要。
- 缺点:基于度量学习的方法依赖于监督信息,在监督信息不可用时不适用。
5. 排序学习的方法
**排序学习方法将排序信息作为训练数据,直接优化排序的结果而不是学习两两数据之间的相似性。**早期的排名学习研究主要集中在单媒体检索上,但是一些研究如表明它们可以扩展到跨模态检索中。
基于排序学习的相关方法
在 David 的工作中,提出了一个判别模型来学习从图像空间到文本空间的映射,但只涉及单向排序(文本→图像)。
Bi-CMSRM 是双向排序方法,即文本→图像和图像→文本排序方法。通过双向跨媒体语义表示模型来优化双向列表排序损失。
Jiang 首先将视觉对象和文本单词投射到局部公共空间,然后再以组合的方式投射到全局公共空间,并带有排序信息。
Wu et al 采用条件随机场进行共享主题学习,然后利用排序函数进行潜在的联合表示学习。
排序学习方法的优缺点
- 优点:使用排序函数目标明确,直接提升检索的性能
- 缺点:目前的方法都只使用了两种模态信息,多种模态数据仍不适用
6. 字典学习的方法
关于字典学习:字典学习的目标,就是提取事物最本质的特征(类似于字典当中的字或词语)。如果我们能都获取这本包括最本质的特征的字典,那我们就掌握了这个事物的最本质的内涵。在字典学习中,输入数据通过稀疏编码算法表示为字典中的若干个基的线性组合。
字典学习方法认为数据由两部分组成:字典和稀疏系数。该想法也可以应用于跨模态检索之中,将数据分解为每个媒体的媒体特定部分和跨模态相关性的公共部分。
基于字典学习的相关方法
Jia 等人提出为每种模态学习一个字典,而这些字典的权重相同。在这项工作中,数据明确分解为两部分:私有字典和共享系数。Zhu 等人提出了跨模态子模块化字典学习(CmSDL),该方法学习适应模态的字典对和用于跨媒体表示的同构空间。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DBrYfUCt-1678421761632)(assets/image-20230309184928-uxh73y4.png)]
Coupled dictionary learning 耦合字典学习是联合构建两个视图私有字典的有效方法。Zhuang 等人提出将单媒体耦合字典学习扩展到跨媒体检索,假设不同媒体类型的稀疏系数之间存在线性映射。通过这些稀疏系数映射,可以将一种媒体类型的数据映射到另一种媒体类型的空间中。字典学习方法采用因式分解方法对跨媒体检索问题进行建模,公共空间为稀疏系数。
基于字典学习的优缺点
- 优点:容易从不同媒体类型的稀疏系数中获取跨模态的相关性
- 缺点:如何在大规模跨媒体数据上解决字典学习的海量计算优化问题是一个挑战。
7. 跨模态哈希模型
多媒体数据的数量急剧增长,这对检索系统的效率提出了更高的要求。哈希法是一种为了加速检索过程而设计的方法,在各种检索应用中得到了广泛的应用。
跨模态哈希具体方法
注:在本文的之后还出现了很多基于哈希的跨模态检索方法。如 DCMH,SSAH 等方法。
Zhang 等人提出了多信息源的复合哈希(CHMIS),其思想是既保留原始空间中的相似性,又保留多个信息源之间的相关性。
Wu et al 首先应用图来建模模态内和模态间的相似性,然后学习用于生成哈希码的多模态字典。同时还考虑了哈希码的判别能力,这有助于在监督条件下学习哈希码。
此外还有很多种跨媒体哈希,跨媒体哈希方法主要考虑了模态间的相似度、模态内的相似度和语义辨别能力等。值得注意的是,跨媒体哈希方法是基于成对相关性学习的,可以弥合“媒体鸿沟”问题。
跨模态哈希优缺点
- 优点:由于二进制哈希代码较短,在检索效率上具有优势,有利于现实世界中大规模数据集的检索。
- 缺点:哈希的效率优势无法在小规模数据集上得到有效验证。
其他方法
除了上述七种方法之外,作者还讨论了一些不易分类的方法:
- 高维空间投影法:该方法由Zhang等人提出。首先将数据投影到高维公共空间,然后再根据类内距离和类间距离将数据从高维空间映射到低维公共空间。
- 非配对数据处理法:Kang等人提出了局部群一致特征学习(LGCFL),用于处理非配对数据。该方法通过语义类别标签学习公共空间,并不像CCA方法那样要求严格的配对数据。
- 多投影矩阵法:目前大多数方法仅针对每种媒体类型学习一个投影矩阵。然而,Hua等人提出了学习一组本地投影矩阵的方法,通过分析数据标签的层次结构来利用语义相关性。同时,Wei等人提出了分别为图像→文本检索和文本→图像检索学习不同投影矩阵的方法。然而,这种方法存在一个限制,就是随着检索任务的增加,需要学习的投影矩阵的数量也会增加。
- 流形对齐法:该方法扩展了流形对齐的思想,通过发现提供不同高维数据集共同低维表示的子空间和流形结构来实现跨媒体检索。这些方法利用高维数据具有低维流形结构的直觉,通过对齐不同媒体类型的基础流形表示来寻找公共空间投影。
Cross-media Similarity Measurement
上面介绍了基于公共空间的检索方法,本节介绍跨媒体相似度测量方法。这种方法无需将媒体实例从单独的空间显式投影到公共空间由于没有公共空间,不能直接进行距离度量或直接分类。一种直观的方法是使用已知的多媒体实例和在数据集中的相关作为基础,弥合“媒体鸿沟”。
通常使用图的边表示媒体实例和多媒体文档 multimedia documents (MMD)之间的关系,根据方法不同重点可以划分成两类:
- 基于图的方法:主要关注图的构建
- 近邻分析方法:主要关注如何利用近邻关系进行相似度量
这两种方法存在着较强的关联
Graph-based Methods
基于图的方法的基本思想是将跨媒体数据看作一个或多个图中的顶点,边由跨媒体数据的相关性构成。单媒体内容相似度、共存关系和语义类别标签可以联合用于图的构建。通过相似度传播和约束融合等处理,可以获得检索结果。
MMDS 中数据的共存关系为桥接不同的媒体类型提供了重要提示。表示 MMD 相似性的图在[4]、[93]中起着重要作用,并且跨媒体检索基于该图中的 MMD 亲和度。
基于图的具体方法
Tong 等人为每种媒体类型构建一个独立的图。这些图通过线性融合或顺序融合进一步合并,然后进行跨媒体数据的相似性测量。
与 Tong 不同的是,Zhuang 等人构建了一个统一的跨媒体相关图,该图集成了所有媒体类型。边权重由单媒体数据的相似性和共存关系确定。此外还考虑了网页上MMD之间的链接关系。
Yang 等人提出了一种两级图构建策略。他们首先为每种媒体类型构建两种类型的图:一种是每种媒体类型的图,另一种是所有MMD的图。然后,媒体实例的特征沿着MMD语义图传播,构建MMD语义空间以执行跨媒体检索。
尽管现有方法大多仅考虑相似性传播中的正相关性,但 Zhai 等人提出在图中传播不同媒体类型数据之间的正负相关性,并提高了检索准确性。
基于图的优缺点
基于图的相似性度量方法的核心思想是构造一个或多个图,并在媒体实例或MMD的级别上表示跨媒体的相关性。
- 优点:图构造能将各种类型的关联信息结合起来
- 缺点:图的构造过程比较耗费时间和空间。相关性不可用时,很难执行跨媒体检索,特别是当查询不在数据集中时。实际应用中,MMDS之间的关系通常是噪声和不完备的。
Neighbor Analysis Methods
一般而言,近邻分析方法通常基于图的构造,因为邻域可以在给定的图中进行分析。在本文中,基于图的方法主要涉及图的构建过程,而近邻分析方法则侧重于利用邻域关系进行相似性度量。
基于近邻的具体方法
Clinchant 提出了一种名为跨媒体融合的多媒体融合策略,用于跨媒体检索。例如,存在一个包含图像/文本对的数据集,用户通过图像查询来检索相关的文本。给定一个图像查询,根据单媒体内容相似性将其最近邻进行检索,然后这些最近邻的文本描述被视为相关的文本。
Zai 提出通过分析每个媒体实例的同类最近邻计算两个媒体实例属于相同语义类别的概率来计算跨媒体相似性。
Ma 提出了一种以聚类为视角计算跨媒体相似性的方法。在他们的工作中,首先对每种媒体类型应用聚类算法,然后根据数据共存关系获得聚类之间的相似度。查询将根据单媒体内容相似性分配给不同权重的聚类,然后通过计算聚类之间的相似度获得检索结果。
基于近邻方法的优缺点
- 优点:这些方法不依赖于MMDS,因此它们是灵活的。
- 缺点:由于邻域分析方法实际上可能是基于图的构造,所以它们都存在时间和空间复杂度高的问题。也很难保证邻居的相关关系,所以性能不稳定。
其他方法
- Relevant feedback analysis:基于用户的反馈去提升检索性能
- Multimodal topic model:views cross-media data in the topic level,过计算条件概率来获得跨媒体相似度
Relevant feedback analysis
引入相关反馈(RF)来提供更准确的信息以促进检索准确性。RF包括两种类型:短期反馈和长期反馈。短期反馈只涉及当前用户提供的RF信息,而长期反馈考虑所有用户提供的RF信息。RF已被证明在跨媒体相似度计算中是有效的。短期反馈通过查询数据集中最接近的邻居,让用户标记正负样本以改善相似度。长期反馈通过将反馈信息转换为成对的相似/不相似约束来优化数据的向量表示。RF是一种提高交互式检索准确性的辅助技术,但需要付出人力成本。
Multimodal topic model
研究人员将主题模型扩展到了图像注释等应用中,提出了多种模型,如Corr-LDA和tr-mmLDA等。然而,这些方法通常对跨媒体主题的分布做出了强烈的假设,这些假设在现实应用中并不适用。为了解决这个问题,Jia等人提出了MDRF方法,并将其视为基于LDA主题模型的马尔可夫随机场。Wang等人提出了下游监督主题模型,并构建了一个联合的跨媒体概率图模型来发现相互一致的语义主题。总体而言,多模态主题模型的目标是在主题级别分析跨媒体之间的关联。
Cross-Media Retrieval Dataset
本节介绍了常用的跨模态检索的数据集
Wikipedia Dataset
Wikipedia dataset 数据集。
该数据集是跨媒体检索中最常用的数据集之一,其中包含了2,866对图像和文本。该数据集基于Wikipedia上的“特色文章”,由29个类别中的前10个最多的类别组成。
该数据集规模较小,只涉及图像和文本两种媒体类型。具有高级语义难以区分,例如战争和历史类别之间有些语义重叠,同时即使是同一类别的数据,语义也可能差异很大,这可能会导致检索评估的困难。
XMedia Dataset
XMedia Dataset 数据集
XMedia 有20个类别,如昆虫、鸟、风、狗、老虎、爆炸和大象等对象。对于每个类别,收集了五种媒体类型的数据:250个文本、250个图像、25个视频、50个音频片段和25个三维模型,因此每个类别有600个媒体实例,总媒体实例数为12,000个。
所有媒体实例均从著名网站:维基百科、Flickr、YouTube、3D Warehouse和普林斯顿3D模型搜索引擎中爬取。
NUS-WIDE Dataset
NUS-WIDE 数据集是一个网络图像数据集,包括图像及其关联标签。这些图像和标签都是通过Flickr的公共API随机爬取的。去除重复图像后,NUS-WIDE数据集包括81个概念的269,648个图像。最初,这些图像关联了425,059个独特标签。然而,为了进一步提高标签质量,该数据集删除了出现次数不超过100次且不存在于WordNet中的标签,最终仅包含5,018个独特标签。
Pascal VOC 2007 Dataset
Pascal VOC 2007是最受欢迎的Pascal VOC数据集,由20个类别的9,963张图像组成。图像注释用作跨媒体检索的文本,并在包含804个关键字的词汇表上定义。
Clickture Dataset
Clickture DataSet 是一个大规模的基于点击的图像数据集,它是从某商业图像搜索引擎一年的点击数据中收集的。
完整的Clickture数据集由4000万张图像和7360万条文本查询组成。它还有一个子集Clickture-Lite,包含100万张图片和1170万条文本查询。
训练集由2,310万个查询-图像-点击三元组组成,其中“点击”是表示图像与查询之间相关性的整数,测试集有从1,000个文本查询生成的79,926个查询-图像对。
实验部分
特征提取和数据集划分
具体参考原文
评价指标和对比模型
两种检索任务:
- Multi-modality cross-media retrieval:使用任意媒体类型作为查询,返回检索到的所有媒体类型。
- Bi-modality cross-media retrieval:使用任一媒体类型作为查询。返回其他媒体类型
评价指标:
- MAP
- PR 曲线
作者在网站上给出了本文实验 PR 曲线的文件
对比模型:
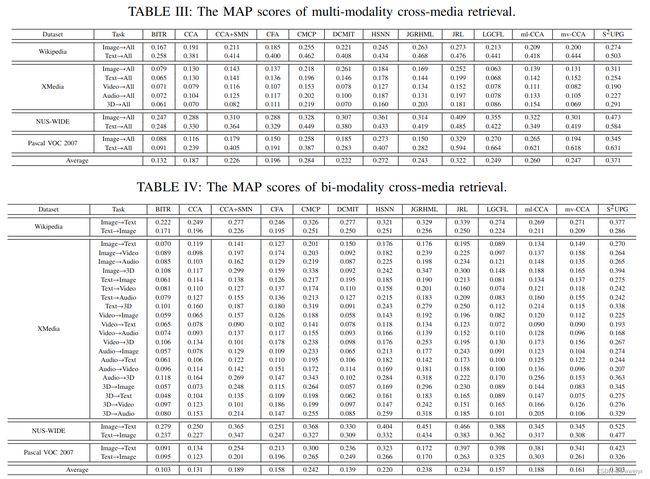
The compared methods in the experiments include: BITR [20], CCA [18], CCA+SMN [27], CFA [30], CMCP [6], DCMIT [35], HSNN [5], JGRHML [7], JRL [10], LGCFL [85], ml-CCA [26], mv-CCA [25] and S2UPG [11]. All these methods are evaluated on Wikipedia, XMedia, NUS-WIDE and Pascal VOC 2007 datasets. However, because Clickture dataset provides no category labels for supervised training, only unsupervised methods (BITR, CCA, CFA, DCMIT) are evaluated on this dataset.
实验结果
具体查看论文中的数据
挑战和未解决的问题
1. 数据集构建和基准标准化
本文谈到了数据集在交叉媒体检索实验评估中的重要性,目前公开的数据集数量很少,且存在一些缺陷,比如规模小、媒体类型不足、类别划分不合理等问题。为了解决这些问题,文章作者正在构建一个名为XMediaNet的新数据集,包括五种媒体类型(文本、图像、视频、音频和3D模型)
2. 提高精确度和效率
现有方法仍有改进的潜力去提高准确性。例如基于图的跨媒体相似度测量方法可能使用更多上下文信息进行有效的图构建。
因为大部分方法是基于特征训练的。单媒体特征的判别能力也很重要,当采用更具判别性的特征(如CNN特征用于图像)时,检索准确性将得到提高。
跨媒体检索数据集到目前为止仍然是小规模的,媒体类型的数量也有限。虽然已经有一些哈希方法用于跨媒体检索,但效率问题还没有得到足够的关注。
3. 深度神经网络的应用
尽管基于DNN的方法在跨媒体检索方面取得了相当大的进展,但仍有进一步改进的潜力。
现有方法主要将单媒体特征作为输入,因此它们严重依赖于特征的有效性。研究工作可以致力于设计端到端架构,将原始媒体实例作为输入,直接使用DNN获取检索结果。
一些针对特定媒体类型的特殊网络(例如,用于对象区域检测的R-CNN)也可以纳入跨媒体检索的统一框架中。
大多数现有方法仅设计用于两种媒体类型。在未来的工作中,研究人员可以集中分析超过两种媒体类型,这将使DNN在跨媒体检索中的应用更加灵活和有效。
4. 语义关联信息的开发
跨媒体检索的主要挑战仍然是不同媒体类型的异构形式。现有方法试图弥合“媒体差距”,但只取得了有限的改进,并且在处理真实世界的跨媒体数据时,检索结果并不准确。
跨媒体相关性通常与上下文信息有关。例如,如果图像和音频剪辑来自两个具有链接关系的网页,则它们可能与彼此相关。许多现有方法(例如CCA,CFA和JRL)仅将共存关系和语义类别标签视为训练信息,但忽略了丰富的上下文信息。实际上,互联网上的跨媒体数据通常不存在于单独的环境中,具有重要的上下文信息,如链接关系。这些上下文信息相对准确,并为提高跨媒体检索的准确性提供了重要的线索。
网络数据通常是分散的,因此利用上下文信息对于复杂的实际应用程序至关重要。我们相信,在未来的研究中,研究人员将更加注重丰富的上下文信息以提高跨媒体检索的性能。
5. 跨媒体检索的实际应用
随着效率和准确性的不断提高,跨媒体检索的实际应用将变得可行。这些应用可以提供更加灵活和方便的方式来从大规模跨媒体数据中检索,并且用户将愿意采用跨媒体搜索引擎,该搜索引擎能够使用任何媒体类型的查询,检索各种媒体类型,如文本、图像、视频、音频和3D模型。此外,其他可能的应用场景包括涉及跨媒体数据的企业,如电视台、媒体公司、数字图书馆和出版公司等。互联网和相关企业将有巨大的跨媒体检索需求。
总结
本文回顾了跨媒体检索这一重要研究主题,解决跨越不同媒体类型的“媒体差距”以进行检索。
本文回顾了100多个文献,以便建立评估基准,并促进相关研究。已有的方法主要包括共同空间学习和跨媒体相似度测量方法。共同空间学习方法明确地学习不同媒体类型的共同空间以进行检索,而跨媒体相似度测量方法则直接测量跨媒体相似性而无需共同空间。
同时介绍了广泛使用的跨媒体检索数据集,包括维基百科、XMedia、NUS-WIDE、Pascal VOC 2007和Clickture数据集。其中,本文构建的XMedia是第一个包含五种媒体类型的数据集,用于全面公正的评估。
文章还介绍了跨媒体基准测试,例如数据集、比较方法、评估指标和实验结果,并建立了一个持续更新的网站来呈现它们。
最后提出了未来的主要挑战和未解决的问题。