Self-correcting LLM-controlled Diffusion Models
题目:自校正的LLM控制的扩散模型
摘要
随着扩散模型的出现,文本到图像的生成取得了重大进展。尽管能够生成逼真的图像,但当前的文本到图像扩散模型仍然常常难以准确解释和遵循复杂的输入文本提示。与旨在尽最大努力生成图像的现有模型相比,我们引入了自校正 LLM 控制扩散(SLD)。 SLD 是一个框架,它根据输入提示生成图像,评估其与提示的对齐情况,并对生成图像中的不准确之处进行自我纠正。在 LLM 控制器的控制下,SLD 将文本到图像的生成转变为迭代闭环过程,确保生成图像的正确性。 SLD 不仅无需训练,还可以与 API 访问背后的扩散模型(例如 DALL-E 3)无缝集成,以进一步提升最先进的扩散模型的性能。实验结果表明,我们的方法可以纠正大多数不正确的生成,特别是在生成计算、属性绑定和空间关系方面。此外,通过简单地调整 LLM 的指令,SLD 就可以执行图像编辑任务,从而弥合文本到图像生成和图像编辑pipeline之间的差距。
总结:本文想解决的问题是文本-图像的扩散模型难以准确的解释和遵循复杂的文本提示。本文提出了SLD框架,它可以根据输入提示生成图像,评估其与提示的对齐情况,并对生成图像中的不准确之处进行自我纠正。同时,通过简单地调整 LLM 的指令,SLD 就可以执行图像编辑任务,从而弥合文本到图像生成和图像编辑pipeline之间的差距。
介绍
文本到图像的生成已经取得了显着的进步,特别是随着扩散模型的出现。然而,这些模型通常难以解释复杂的输入文本提示,特别是那些需要理解计算概念、空间关系以及与多个对象的属性绑定等技能的模型。尽管模型大小和训练数据规模惊人,但这些挑战(如图 1 所示)仍然存在于最先进的开源和专有扩散模型中。
图1:现有的基于扩散的文本到图像生成器(例如,DALL-E 3 [18])通常难以精确生成与复杂输入提示正确对齐的图像,特别是对于需要计算能力和空间关系的图像。我们的自校正 LLM 控制扩散 (SLD) 框架使这些扩散模型能够通过应用一组潜在空间操作(添加、删除、重新定位等)自动迭代地纠正错误,从而增强文本到图像的对齐。
多项研究和工程工作旨在克服这些限制。例如,DALL-E 3 [18] 等方法专注于扩散训练过程,并将高质量的字幕大规模地纳入训练数据中。然而,这种方法不仅会产生大量成本,而且经常无法根据复杂的用户提示生成准确的图像,如图 1 所示。其他工作利用外部模型的力量来更好地理解实际图像生成之前的推理过程中的提示。例如,利用大型语言模型 (LLM) 将文本提示预处理为结构化图像布局,从而确保初步设计符合用户的指令(可以做成类似于driving diffusion里边的3D布局那那样的类型?)。然而,这种集成并不能解决下游扩散模型产生的不准确性,特别是在具有复杂场景(如多个对象、杂乱排列或详细属性)的图像中。
从人类绘画的过程和生成图像的扩散模型中汲取灵感,我们观察到他们创作方法的一个关键区别。假设一位人类艺术家的任务是绘制一个有两只猫的场景。在整个绘画过程中,艺术家始终意识到这一要求,确保两只猫确实存在,然后才考虑作品完成。如果艺术家发现只描绘了一只猫,则会添加另一只猫以满足提示的标准。这与当前在开环基础上运行的文本到图像扩散模型形成鲜明对比。这些模型通过预定数量的扩散步骤生成图像,并将输出呈现给用户,无论其与初始用户提示是否一致。无论缩放训练数据或 LLM 预生成条件,这样的过程都缺乏可靠的机制来确保最终图像符合用户的期望。
有鉴于此,我们提出了自我校正 LLM 控制扩散 (SLD) 方法,该方法执行自我检查,以自信地为用户提供提示与生成图像之间对齐的保证。与传统的单轮生成方法不同,SLD 是一种新颖的闭环方法,使扩散模型具有迭代识别和纠正错误的能力。我们的 SLD 框架如图 2 所示,包含两个主要组件:LLM 驱动的对象检测以及 LLM 控制的评估和校正。
SLD pipeline遵循标准的文本到图像生成设置。给定概述所需图像的文本提示,SLD 首先调用图像生成模块(例如前面提到的开环文本到图像扩散模型)以尽力而为的方式生成图像。鉴于这些开环生成器不能保证输出与提示完全一致,SLD 然后根据提示对生成的图像进行彻底评估,并使用 LLM 解析关键短语以供开放词汇检测器检查。随后,LLM控制器将检测到的边界框和初始提示作为输入,检查检测结果和提示要求之间是否存在潜在的不匹配,并建议适当的自校正操作,例如添加、移动和删除对象。最后,利用基础扩散模型(例如稳定扩散[22]),SLD采用潜在空间合成来实现这些调整,从而确保最终图像准确地反映用户的初始文本提示。
值得注意的是,我们的pipeline对初始生成的来源没有限制,因此适用于由专有模型(例如 DALLE 3 [18])通过 API 生成的图像,如图 1 所示。 校正操作需要对我们的基础扩散模型[22]进行任何额外的训练,这使得我们的方法可以轻松地应用于各种扩散模型,而无需外部人工注释或训练的成本。
我们证明,我们的 SLD 框架可以通过 LMD 基准 [10] 在复杂提示上实现比当前基于扩散的方法的显着改进。结果表明,我们的方法能够超越 LMD+ 9.0%,LMD+ 是一个强大的基线,已经在图像处理生成中利用了 LLM。更重要的是,使用 DALL-E 3 进行初始生成,与自校正之前的图像相比,我们的方法生成的图像实现了 26.5% 的性能提升。
最后,由于 SLD pipeline与最初生成的图像无关,因此只需更改 LLM 的提示即可轻松将其转换为图像编辑pipeline。虽然文本到图像生成和图像编辑通常被生成建模社区视为不同的任务,但我们的 SLD 能够通过统一的pipeline执行这两项任务。我们在下面列出了我们的主要贡献:
1. SLD 是第一个集成检测器和 LLM 来自我校正生成模型的模型,确保无需额外训练或外部数据即可准确生成。
2. SLD 为图像生成和编辑提供统一的解决方案,支持任何图像生成器(例如 DALL-E 3)的增强文本到图像对齐以及对任何图像的对象级编辑。
3.实验结果表明,我们的方法可以纠正大多数错误的生成,特别是在计算能力、属性绑定和空间关系方面。
自纠正的LLM控制扩散模型
LLM驱动的物体检测
我们的 SLD 框架从 LLM 驱动的对象检测开始,它提取下游评估和校正所需的信息。如图2中绿色箭头所示,LLM驱动的目标检测包括两个步骤:
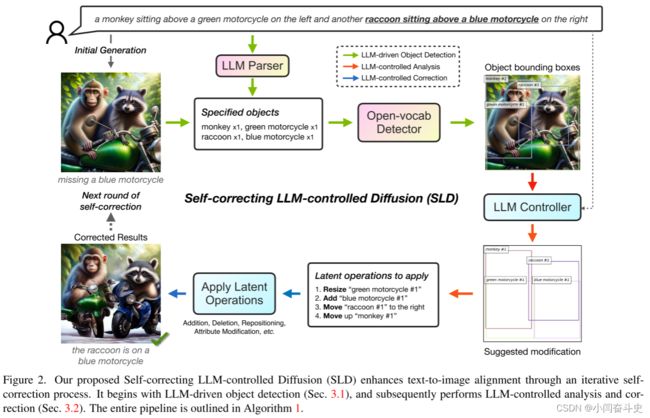
1)我们利用 LLM 作为解析器,解析用户提示并输出可能与图像评估相关的关键短语。 2) 然后将短语传递到开放词汇对象检测器中。检测到的框应该包含支持评估图像是否符合用户提示中的规范的信息。
在初始步骤中,LLM 解析器被引导从用户提供的文本提示 P 中提取关键对象详细信息列表,表示为 S。该解析器在文本指令和上下文示例的帮助下,可以轻松完成此任务,如下所示图3(a)。对于包含“绿色摩托车”和“蓝色摩托车”等短语的用户提示,LLM应识别并输出“绿色”和“蓝色”作为与“摩托车”相关的属性。当提示引用没有特定数量或属性的对象时,例如“猴子”和“浣熊”,这些描述符适当地留空。重要的是,LLM的作用不仅限于识别对象名词;它还需要识别任何相关的数量或属性。
在第二步中,开放词汇检测器处理在第一步中解析的关键对象信息 S 列表,以检测并定位图像内的对象。我们使用格式化为 [属性] [对象名称] 图像的查询来提示开放词汇对象检测器,其中“属性”和“对象名称”源自解析器的输出。然后将生成的边界框 Bcurr 组织成列表格式,例如 [("[attribute] [object name] [#object ID]", [x, y, w, h])] 以进行进一步处理。一种特殊情况是提示对对象数量提出限制。对于属性对象(例如“蓝狗”)与所需数量相比不足的情况,提供非属性对象(例如“狗”)的补充计数,为后续的 LLM 控制器决定是否添加提供上下文更多“蓝色狗”或干脆将现有狗的颜色更改为蓝色。我们将在第 2 节中更详细地解释这些操作,包括对象添加和属性修改。
LLM控制的分析和修正
我们使用 LLM 控制器进行图像分析和后续校正。给定用户提示 P 和检测到的框 Bcurr,控制器被要求分析由对象边界框表示的图像是否与用户提示的描述一致,并提供校正后的边界框 Bnext 的列表,如图3(b)所示。

然后SLD以编程方式分析精炼后的边界框与原始边界框之间的不一致,以输出一组编辑操作Ops,其中包括添加、删除、重新定位和属性修改。然而,简单的框集表示不携带对应信息,当多个框共享相同的对象名称时,这不允许以简单的方式比较LLM控制器的输入和输出布局。例如,当模型输入和模型输出中都有两个猫框时,一个猫框是否对应于输出布局中的哪一个猫框是不清楚的。我们建议通过一个非常简单的编辑让 LLM 输出对应关系,而不是引入另一种算法来猜测对应关系:我们为每个边界框提供一个对象 ID,每个对象类型中的数字会增加,作为在对象后面添加的后缀姓名。在上下文示例中,在建议更正之前和之后,对象应具有相同的名称和对象 ID。
免训练图像校正的潜在操作
LLM 控制器输出要应用的校正操作的列表。对于每个操作,我们首先将原始图像转换为潜在特征。然后,我们的方法执行一系列应用于这些潜在层的操作 Ops,例如添加、删除、重新定位和属性修改。下面我们将解释每个操作是如何执行的。
添加
受[10]的启发,添加过程需要两个阶段:预生成对象并将其潜在表示集成到原始图像的潜在空间中。最初,我们使用扩散模型在指定的边界框中创建对象,然后使用模型(例如 SAM [8])进行精确分割。然后使用我们的基础扩散模型通过后向扩散序列处理该对象,产生与该对象相对应的屏蔽潜在层,随后将其与原始画布合并。
删除
删除操作从 SAM 细化对象在其边界框内的边界开始。然后,与这些指定区域相关的潜在层被移除并用高斯噪声重置。这需要在接下来的前向扩散过程中完全再生这些区域。
Repositioning
重新定位涉及修改原始图像以将对象与新的边界框对齐,并注意保留其原始纵横比。初始步骤包括在图像空间中移动边界框并调整其大小。此后,SAM 细化对象边界,然后通过后向扩散过程生成其相关的潜在层,类似于加法运算中的方法。与切除部分相对应的潜在层被高斯噪声替换,而新添加的部分则被集成到最终的图像合成中。重新定位时的一个重要考虑因素是在图像空间而不是潜在空间中调整对象大小,以保持高质量的结果。
属性修改
属性修改从 SAM 细化边界框内的对象边界开始,然后应用属性修改,例如 DiffEdit [4]。然后,基础扩散模型反转图像,生成一系列蒙版潜在层,为最终合成做好准备。
对每个对象进行编辑操作后,我们进入重组阶段,如图 4 所示。在此阶段,当使用高斯噪声重新初始化已删除或重新定位区域的潜在变量时,添加或修改的潜在变量的潜在变量也会相应更新。对于具有多个重叠对象的区域,我们首先放置较大的蒙版,以确保较小对象的可见性。

然后,修改后的潜在变量堆栈经历最终的前向扩散过程,该过程从冻结未用高斯噪声重新初始化的区域的步骤开始(即,强制在同一步骤与未修改的潜在变量对齐)。这对于准确形成更新对象同时保持背景一致性至关重要。该过程以几个步骤结束,其中所有内容都可以改变,从而产生视觉上连贯且正确的图像。
自我修正过程的终止(主要指迭代的过程)
尽管我们观察到一轮生成通常足以满足我们遇到的大多数情况,但后续几轮仍然可以进一步提高正确性方面的性能,使我们的自我纠正成为一个迭代过程。
确定最佳的自校正轮数对于平衡效率和准确性至关重要。如算法 1 中所述,我们的方法设置了修正轮次的最大尝试次数,以确保该过程在合理的时间内完成。

当LLM输出与输入相同的布局时(即,如果LLM控制器(Bnext)建议的边界框与当前检测到的边界框(Bcurr)对齐),或者达到最大生成轮数时,该过程完成,这表明该方法无法正确生成提示。这个迭代过程保证了图像的正确性,直至检测器和 LLM 控制器的准确性,确保其与初始文本提示紧密结合。
统一的文本到图像生成和编辑
除了自我校正图像生成模型之外,我们的 SLD 框架还可以轻松适应图像编辑应用程序,只需要很少的修改。一个关键的区别在于用户输入提示的格式。与用户提供场景描述的图像生成不同,图像编辑要求用户详细说明原始图像和所需的更改。例如,要通过用橙子替换香蕉来编辑包含两个苹果和一个香蕉的图像,提示可能是:“用橙子替换香蕉,同时保持两个苹果不变。”
编辑过程类似于我们的自我修正机制。 LLM 解析器从用户提示中提取关键对象。然后,开放词汇检测器识别这些对象,建立当前边界框的列表。以编辑为中心的LLM控制器配备了特定的任务目标、指南和上下文示例,可以分析这些输入。它提出了更新的边界框和相应的潜在空间操作,以进行精确的图像处理。
SLD 执行详细的对象级编辑的能力使其有别于现有的基于扩散的方法,例如 InstructPix2Pix [2] 和 Prompt2prompt [7],后者主要解决全局图像样式更改。此外,SLD 的性能优于 DiffEdit [4] 和 SDEdit [16] 等工具,这些工具仅限于对象替换或属性调整,可通过精确控制实现全面的对象重新定位、添加和删除。
讨论
多轮的自我修正
我们在表中的分析。图2强调了多轮自我修正的好处以及第一轮修正始终是最有效的并且具有边际效应的事实。第一轮修正大大缓解了稳定扩散中固有的问题[22]。然后,第二轮修正仍然在所有四项任务上产生了显着的改进。
限制和未来的工作
我们方法的局限性如图 8 所示,其中 SLD 无法准确去除人的毛发。在本例中,尽管成功地识别和定位了头发,但其形状的复杂性对用于区域选择的 SAM 模块提出了挑战,导致除了头发之外,还意外地去除了人脸。然而,由于人的衣服没有被移除,基础扩散模型无法生成自然的构图。这表明需要更好的区域选择方法来进一步提高生成和编辑质量。
结论
我们引入了自校正语言驱动 (SLD) 框架,这是一种开创性的自校正系统,使用检测器和 LLM 来显着增强文本到图像的对齐。该方法不仅在图像生成基准中树立了新的 SOTA,而且还与包括 DALL-E 3 在内的各种生成模型兼容。此外,SLD 将其实用性扩展到图像编辑应用程序,提供超越现有方法的细粒度对象级操作。
1、集成先进的 LMM 来简化图像生成和编辑的潜力仍然是未来研究和开发的一个引人注目且有前途的方向。
2、GPT-4 具有操纵边界框坐标的能力,这是一项涉及数学推理的任务。我们通过指导模型采用思想链推理 [25] 来实现改进的结果,其中模型在生成过程中解释了其推理过程。与未明确说明模型推理的情况相比,这种方法产生了更准确的建议。