机器学习之特征提取 TF-IDF

一、概念
“词频-逆向文件频率”(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。
词语由t表示,文档由d表示,语料库由D表示。词频TF(t,d)是词语t在文档d中出现的次数。文件频率DF(t,D)是包含词语的文档的个数。如果我们只使用词频来衡量重要性,很容易过度强调在文档中经常出现,却没有太多实际信息的词语,比如“a”,“the”以及“of”。如果一个词语经常出现在语料库中,意味着它并不能很好的对文档进行区分。TF-IDF就是在数值化文档信息,衡量词语能提供多少信息以区分文档。其定义如下:

此处|D| 是语料库中总的文档数。公式中使用log函数,当词出现在所有文档中时,它的IDF值变为0。加1是为了避免分母为0的情况。TF-IDF 度量值表示如下:
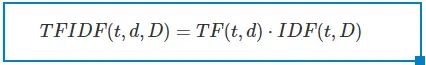
在Spark ML库中,TF-IDF被分成两部分:TF (+hashing) 和 IDF。
TF: HashingTF 是一个Transformer,在文本处理中,接收词条的集合然后把这些集合转化成固定长度的特征向量。这个算法在哈希的同时会统计各个词条的词频。
IDF: IDF是一个Estimator,在一个数据集上应用它的fit()方法,产生一个IDFModel。 该IDFModel 接收特征向量(由HashingTF产生),然后计算每一个词在文档中出现的频次。IDF会减少那些在语料库中出现频率较高的词的权重。
Spark.mllib 中实现词频率统计使用特征hash的方式,原始特征通过hash函数,映射到一个索引值。后面只需要统计这些索引值的频率,就可以知道对应词的频率。这种方式避免设计一个全局1对1的词到索引的映射,这个映射在映射大量语料库时需要花费更长的时间。但需要注意,通过hash的方式可能会映射到同一个值的情况,即不同的原始特征通过Hash映射后是同一个值。为了降低这种情况出现的概率,我们只能对特征向量升维。i.e., 提高hash表的桶数,默认特征维度是 2^20 = 1,048,576.
在下面的代码段中,我们以一组句子开始。首先使用分解器Tokenizer把句子划分为单个词语。对每一个句子(词袋),我们使用HashingTF将句子转换为特征向量,最后使用IDF重新调整特征向量。这种转换通常可以提高使用文本特征的性能。
二、代码实现
2.1、构造文档集合
导入TFIDF所需要的包,创建一个简单的DataFrame,每一个句子代表一个文档。
import java.util.Arrays;
import java.util.List;
import org.apache.spark.ml.feature.HashingTF;
import org.apache.spark.ml.feature.IDF;
import org.apache.spark.ml.feature.IDFModel;
import org.apache.spark.ml.feature.Tokenizer;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
//获取spark
SparkSession spark = SparkSession.builder().appName("FeatureExtractors").master("local").getOrCreate();
//构造数据
List<Row> rawData = Arrays.asList(RowFactory.create(0, "I heard about Spark and I love Spark"),
RowFactory.create(0, "I wish Java could use case classes"),
RowFactory.create(1, "Logistic regression models are neat")
);
StructType schema = new StructType(new StructField[] {
new StructField("label",DataTypes.IntegerType,false,Metadata.empty()),
new StructField("sentence",DataTypes.StringType,false,Metadata.empty())
});
Dataset<Row> sentenceData = spark.createDataFrame(rawData,schema);
sentenceData.show(false);
输出结果:
+-----+-------------------------------------+
|label|sentence |
+-----+-------------------------------------+
|0 |I heard about Spark and I love Spark|
|0 |I wish Java could use case classes |
|1 |Logistic regression models are neat |
+-----+-------------------------------------+
2.2、tokenizer对句子进行分词
得到文档集合后,即可用tokenizer对句子进行分词。
Tokenizer tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words");
Dataset<Row> wordsData = tokenizer.transform(sentenceData);
wordsData.show(false);
输出结果:
+-----+------------------------------------+---------------------------------------------+
|label|sentence |words |
+-----+------------------------------------+---------------------------------------------+
|0 |I heard about Spark and I love Spark|[i, heard, about, spark, and, i, love, spark]|
|0 |I wish Java could use case classes |[i, wish, java, could, use, case, classes] |
|1 |Logistic regression models are neat |[logistic, regression, models, are, neat] |
+-----+------------------------------------+---------------------------------------------+
2.3、TF把句子哈希成特征向量
得到分词后的文档序列后,即可使用HashingTF的transform()方法把句子哈希成特征向量,这里设置哈希表的桶数为2000。
HashingTF hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(2000);
Dataset<Row> featurizedData = hashingTF.transform(wordsData);
featurizedData.show(false);
输出结果:
+-----+------------------------------------+---------------------------------------------+---------------------------------------------------------------------+
|label|sentence |words |rawFeatures |
+-----+------------------------------------+---------------------------------------------+---------------------------------------------------------------------+
|0 |I heard about Spark and I love Spark|[i, heard, about, spark, and, i, love, spark]|(2000,[240,333,1105,1329,1357,1777],[1.0,1.0,2.0,2.0,1.0,1.0]) |
|0 |I wish Java could use case classes |[i, wish, java, could, use, case, classes] |(2000,[213,342,489,495,1329,1809,1967],[1.0,1.0,1.0,1.0,1.0,1.0,1.0])|
|1 |Logistic regression models are neat |[logistic, regression, models, are, neat] |(2000,[286,695,1138,1193,1604],[1.0,1.0,1.0,1.0,1.0]) |
+-----+------------------------------------+---------------------------------------------+---------------------------------------------------------------------+
每一个单词被哈希成了一个不同的索引值。以”I heard about Spark and I love Spark”为例,输出结果中2000代表哈希表的桶数,“[240,333,1105,1329,1357,1777]”分别代表着“heard, about, i, spark, and, love”的哈希值,“[1.0,1.0,2.0,2.0,1.0,1.0]”为对应单词的出现次数,无序。
2.4、IDF修正词频特征向量
可以看到,分词序列被变换成一个稀疏特征向量,其中每个单词都被散列成了一个不同的索引值,特征向量在某一维度上的值即该词汇在文档中出现的次数。
最后,使用IDF来对单纯的词频特征向量进行修正,使其更能体现不同词汇对文本的区别能力,IDF是一个Estimator,调用fit()方法并将词频向量传入,即产生一个IDFModel。
IDF idf = new IDF().setInputCol("rawFeatures").setOutputCol("features");
IDFModel idfModel = idf.fit(featurizedData);
2.5、得到单词对应的TF-IDF度量值
很显然,IDFModel是一个Transformer,调用它的transform()方法,即可得到每一个单词对应的TF-IDF度量值。
Dataset<Row> rescaledData = idfModel.transform(featurizedData);
rescaledData.show(false);
输出结果:
+-----+------------------------------------+---------------------------------------------+---------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|label|sentence |words |rawFeatures |features |
+-----+------------------------------------+---------------------------------------------+---------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|0 |I heard about Spark and I love Spark|[i, heard, about, spark, and, i, love, spark]|(2000,[240,333,1105,1329,1357,1777],[1.0,1.0,2.0,2.0,1.0,1.0]) |(2000,[240,333,1105,1329,1357,1777],[0.6931471805599453,0.6931471805599453,1.3862943611198906,0.5753641449035617,0.6931471805599453,0.6931471805599453]) |
|0 |I wish Java could use case classes |[i, wish, java, could, use, case, classes] |(2000,[213,342,489,495,1329,1809,1967],[1.0,1.0,1.0,1.0,1.0,1.0,1.0])|(2000,[213,342,489,495,1329,1809,1967],[0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.28768207245178085,0.6931471805599453,0.6931471805599453])|
|1 |Logistic regression models are neat |[logistic, regression, models, are, neat] |(2000,[286,695,1138,1193,1604],[1.0,1.0,1.0,1.0,1.0]) |(2000,[286,695,1138,1193,1604],[0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453]) |
+-----+------------------------------------+---------------------------------------------+---------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
Dataset<Row> data = rescaledData.select("features","label");
data.show(false);
输出结果:
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----+
|features |label|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----+
|(2000,[240,333,1105,1329,1357,1777],[0.6931471805599453,0.6931471805599453,1.3862943611198906,0.5753641449035617,0.6931471805599453,0.6931471805599453]) |0 |
|(2000,[213,342,489,495,1329,1809,1967],[0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.28768207245178085,0.6931471805599453,0.6931471805599453]) |0 |
|(2000,[286,695,1138,1193,1604],[0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453]) |1 |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----+
可以看到,特征向量已经被其在语料库中出现的总次数进行了修正,通过TF-IDF得到的特征向量,在接下来可以被应用到相关的机器学习方法中。
参考资料:http://spark.apache.org/docs/latest/ml-features.html#tf-idf