大数据技术4:Lambda和Kappa架构区别
前言:在大数据处理领域,两种突出的数据架构已成为处理大量数据的流行选择:Lambda 架构和 Kappa 架构。这些架构为实时处理和批处理提供了强大的技术解决方案,使组织能够从其数据中获得有价值的见解。随着互联网时代来临,数据量暴增,开始使用大数据工具来替代经典数仓中的传统工具。此时仅仅是工具的取代,架构上并没有根本的区别,可以把这个架构叫做离线大数据架构。后来随着业务实时性要求的不断提高,人们开始在离线大数据架构 基础上加了一个加速层,使用流处理技术直接完成那些实时性要求较高的指标计算,这便是 Lambda 架构。再后来,实时的业务越来越多,事件化的数据源也越来越多,实时处理从次要部分变成了主要部分,架构也做了相应调整,出现了以实时事件处理为核心的 Kappa 架构。
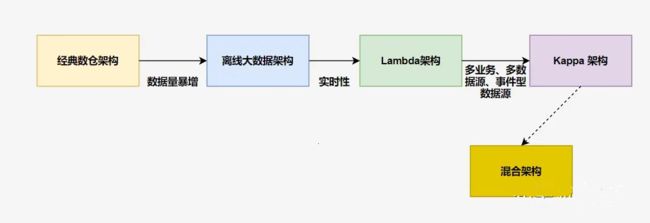
1 、Lambda 架构(融合批处理和实时处理)
Lambda 架构解决了将实时处理和批处理相结合以有效处理大数据工作负载的挑战。它采用混合方法,利用批处理和流处理来提供准确和最新的见解。Lambda 架构的核心是不可变数据的概念。所有传入的数据都以仅追加的方式捕获和存储,从而创建未更改的历史记录。
随着大数据应用的发展,人们逐渐对系统的实时性提出了要求,为了计算一些实时指标,就在原来离线数仓的基础上增加了一个实时计算的链路,并对数据源做流式改造(即把数据发送到消息队列),实时计算去订阅消息队列,直接完成指标增量的计算,推送到下游的数据服务中去,由数据服务层完成离线&实时结果的合并。
Lambda 架构(Lambda Architecture)是由 Twitter 工程师南森·马茨(Nathan Marz)提出的大数据处理架构。这一架构的提出基于马茨在 BackType 和 Twitter 上的分布式数据处理系统的经验。
Lambda 架构使开发人员能够构建大规模分布式数据处理系统。它具有很好的灵活性和可扩展性,也对硬件故障和人为失误有很好的容错性。

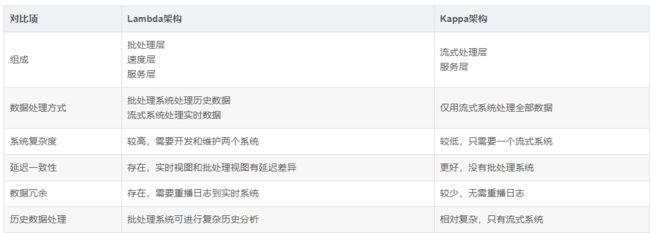
Lambda 架构总共由三层系统组成:批处理层(Batch Layer),速度处理层(Speed Layer),以及用于响应查询的服务层(Serving Layer)。
-
批处理层 :在批处理层中,以面向批处理的方式处理大量历史数据。数据从数据源引入、转换并存储在批处理系统(如 Apache Hadoop 或 Apache Spark)中。然后,转换后的数据将存储在批处理服务层中,在该图层中对其进行索引并使其可查询。
-
速度处理层 :速度层处理实时数据处理。它近乎实时地处理传入的数据流并生成增量更新。然后将这些更新与批处理图层的结果合并,以提供统一的数据视图。速度层通常利用流处理框架,如Apache Storm或Apache Flink。速度层 通过提供最新数据的实时视图来最小化延迟。速度层所生成的数据视图可能不如批处理层最终生成的视图那样准确或完整,但它们几乎在收到数据后立即可用。而当同样的数据在批处理层处理完成后,在速度层的数据就可以被替代掉了。
-
服务层:服务层用作查询和可视化数据的访问点。它结合了批处理层和速度层的结果,并提供一致的数据视图。像Apache HBase或Apache Cassandra这样的技术通常用于存储和提供该层中的数据。服务层:服务层用作查询和可视化数据的访问点。它结合了批处理层和速度层的结果,并提供一致的数据视图。像Apache HBase或Apache Cassandra这样的技术通常用于存储和提供该层中的数据。
Lambda 架构优点:
它通过跨多个层使用复制的数据来提供容错能力,从而确保数据可用性和弹性。该体系结构还支持可扩展的处理,因为每一层都可以独立扩展以处理不断增加的工作负载。此外,批处理和实时处理的分离允许有效的资源利用,因为批处理计算可以在更大的时间窗口上执行。
Lambda 架构缺点:
虽然 Lambda 架构使用起来十分灵活,并且可以适用于很多的应用场景,但在实际应用的时候,Lambda 架构也存在着一些不足,主要表现在它的维护很复杂。
(1)同样的需求需要开发两套一样的代码:这是 Lambda 架构最大的问题,两套代码不仅仅意味着开发困难(同样的需求,一个在批处理引擎上实现,一个在流处理引擎上实现,还要分别构造数据测试保证两者结果一致),后期维护更加困难,比如需求变更后需要分别更改两套代码,独立测试结果,且两个作业需要同步上线。
(2)资源占用增多:同样的逻辑计算两次,整体资源占用会增多(多出实时计算这部分)
2 、Kappa 架构(简化实时处理)
Kappa 架构通过专注于流处理,提供了 Lambda 架构的简化替代方案。它包含不可变数据流的概念,无需维护单独的批处理层。Kappa流行的主要原因在于Kafka和Flink的兴起。Kafka不仅起到消息队列的作用,也可以保存更长时间的历史数据,以替代Lambda架构中批处理层数据仓库部分。
Lambda 架构虽然满足了实时的需求,但带来了更多的开发与运维工作,其架构背景是流处理引擎还不完善,流处理的结果只作为临时的、近似的值提供参考。后来随着 Flink 等流处理引擎的出现,流处理技术很成熟了,这时为了解决两套代码的问题,LickedIn 的 Jay Kreps 提出了 Kappa 架构。Kappa 架构可以认为是 Lambda 架构的简化版(只要移除 lambda 架构中的批处理部分即可)。在 Kappa 架构中,需求修改或历史数据重新处理都通过上游重放完成。Kappa 架构最大的问题是流式重新处理历史的吞吐能力会低于批处理,但这个可以通过增加计算资源来弥补。


在 Kappa 架构中,所有数据都作为无限的事件流引入和处理。数据流经系统并进行实时处理,从而实现近乎即时的洞察力。Kappa 架构的核心组件包括:
-
流引入:从各种源连续引入数据并存储在事件日志中,例如 Apache Kafka。事件日志充当持久、容错的存储机制,可保留事件的完整历史记录。
-
流处理:流处理层使用事件日志中的数据,应用实时计算,并生成所需的输出。像Apache Kafka Streams或Apache Flink这样的技术可用于处理和分析。
-
输出服务:处理后的数据可通过各种输出通道访问,例如实时仪表板、API 或数据接收器,以供进一步分析或使用。
Kappa架构有几个优点。通过专注于流处理,它简化了整体系统设计并降低了操作复杂性。该架构提供低延迟处理,因为数据近乎实时地处理,无需批量计算。它还在数据一致性方面提供了简单性,因为不需要同步和合并来自不同层的数据。
但是,在采用 Kappa 架构时需要牢记一些注意事项。由于所有数据都是实时处理的,因此如果没有额外的组件或流程,就没有对批处理或历史分析的固有支持。在处理某些需要分析大型历史数据集的用例时,此限制可能会带来挑战。此外,对连续流处理的依赖引入了对流处理框架的性能和可伸缩性的依赖。
Kappa 架构的重新处理过程:
重新处理是人们对 Kappa 架构最担心的点,但实际上并不复杂:
(1)选择一个具有重放功能的、能够保存历史数据并支持多消费者的消息队列,根据需求设置历史数据保存的时长,比如 Kafka,可以保存全部历史数据。
(2)当某个或某些指标有重新处理的需求时,按照新逻辑写一个新作业,然后从上游消息队列的最开始重新消费,把结果写到一个新的下游表中。
(3)当新作业赶上进度后,应用切换数据源,读取 2 中产生的新结果表。
(4)停止老的作业,删除老的结果表。
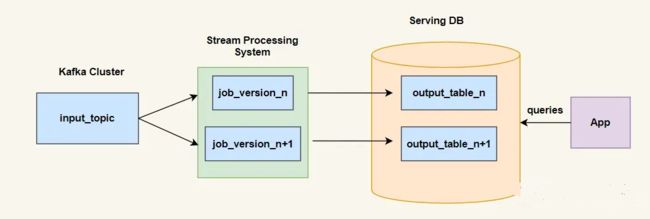
3、Lambda 架构与 Kappa 架构的对比
(1)在真实的场景中,很多时候并不是完全规范的 Lambda 架构或 Kappa 架构,可以是两者的混合,比如大部分实时指标使用 Kappa 架构完成计算,少量关键指标(比如金额相关)使用 Lambda 架构用批处理重新计算,增加一次校对过程。
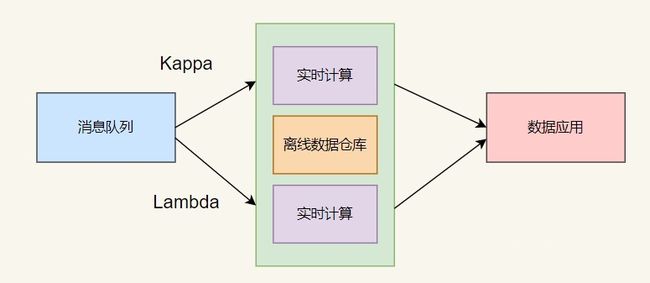
(2)Kappa 架构并不是中间结果完全不落地,现在很多大数据系统都需要支持机器学习(离线训练),所以实时中间结果需要落地对应的存储引擎供机器学习使用,另外有时候还需要对明细数据查询,这种场景也需要把实时明细层写出到对应的引擎中。

总结:
Lambda架构通过批处理层和速度层的组合,兼顾了低延迟和复杂分析,但系统较复杂,存在数据冗余和延迟不一致问题。
Kappa架构只通过流式系统实现所有处理,简化了架构,但历史数据分析相对复杂,需要流式系统保证精确一次语义。
两者都有各自的优缺点,需要根据具体场景进行技术选型和设计权衡。
4、Lambda 架构与 Kappa 架构的技术选型
在 Lambda 和 Kappa 架构之间做出决定时,应考虑以下几个因素:
-
数据特征:考虑数据的性质和处理要求。如果应用案例需要实时和历史分析,则 Lambda 架构可能更适合。另一方面,如果主要关注实时处理和低延迟见解,那么 Kappa 架构可能更合适。
-
系统复杂性:评估与在 Lambda 架构中管理多个处理管道相关的复杂性与 Kappa 架构中单个流处理管道的简单性。考虑组织的资源、专业知识以及实施和维护所需的工作量级别。
-
可伸缩性和性能:评估系统的可伸缩性要求。这两种体系结构都可以水平扩展,但特定的技术选择和实现细节可能会影响性能。考虑希望处理的数据量、速度和种类,并选择能够满足可扩展性需求的体系结构。
-
数据一致性:检查应用程序的一致性要求。Lambda 架构提供了用于处理批处理层和速度层之间数据一致性的内置机制。在 Kappa 架构中,由于没有批处理层,因此简化了数据一致性,但在处理无序事件或延迟到达时可能需要额外的考虑因素。
-
操作注意事项:评估每个体系结构的操作方面,例如部署、监视和容错。考虑所选体系结构的工具、库和社区支持的可用性。
总之,Lambda 和 Kappa 架构都为处理大数据工作负载提供了强大的解决方案。Lambda 架构结合了批处理和实时处理的优势,提供了一段时间内数据的全面视图。另一方面,Kappa 架构通过专注于实时处理来简化系统设计,提供低延迟的洞察力。通过仔细考虑数据和应用程序的特定要求和特征,可以选择最适合您的需求的体系结构,并使组织能够从大数据中获得有意义的见解。
参考链接:
一文读懂Kappa和Lambda架构-36氪
实时数仓之 Kappa 架构与 Lambda 架构(建议收藏!) - 知乎
Lambda 架构 vs Kappa 架构-CSDN博客