python中sorted和sort的key
目录
sort与sorted区别
1、调用方式:
2、返回值:
3、操作对象是否变化:
什么对象可以排序
sort:
sorted:
排序的key
函数:
方法:
自己造:
有趣的排序题:
多级排序
sort与sorted区别
1、调用方式:
sort是方法(需要对象来调用)
sorted是函数(入参是对象)
2、返回值:
sort无返回值
sorted返回排序好的对象,不设置key参数,返回的一定是list类型对象
3、操作对象是否变化:
sort后,对象变为有序的对象
sorted函数不会改变对象
什么对象可以排序
能不能排序主要看要排序的对象之间是否能比较的大小,对象内部是否能比较要看是否有__lt__这个内置方法
下图有dict字典之间不能比较大小所以报错的


sort:
list(元素要一样)

不支持的场景列举
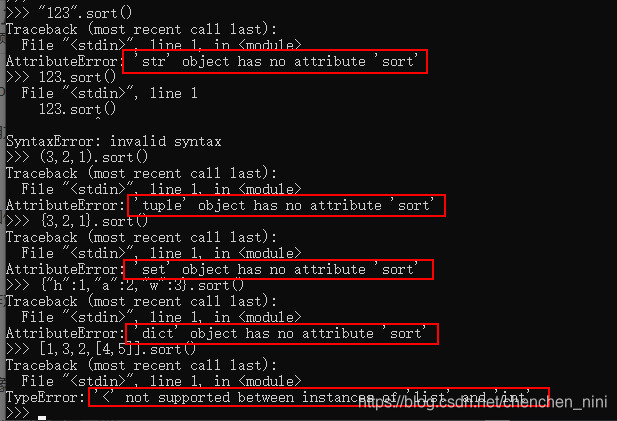
sorted:
比较博爱,只有list元素不一致,或者int对象不可以

排序的key
1、常用函数、方法
注意点:函数写法key=len,因为函数不需要对象来调用
方法写法key=str.lower,因为方法需要对象来调用 等价于 key=lambda x:x.lower()
函数:
len,str .............................
方法:
str.lower 、str.upper,str.capitalize、my_dict.get(my_dict是一个字典对象) ....................
#按照长度排序(len函数)##############################################################
>>> w = ['9', '3', '5', '009', '22030', '034', '900']
>>> w.sort(key=len)
>>> w
['9', '3', '5', '009', '034', '900', '22030']
>>> w = ['9', '3', '5', '009', '22030', '034', '900']
>>> sorted(w,key=len)
['9', '3', '5', '009', '034', '900', '22030']
>>> sorted(c,key=len)
[[1], [2, 3], [1, 2, 3], [4, 5, 6, 7]]
#按照字符串处理排序####################################################################
>>> a = [3,30,33,40,9]
>>> sorted(a,key=str)
[3, 30, 33, 40, 9]
#按照大写字母顺序(lower、upper是方法)################################################
>>> f= ["abc","WS","wew","Dp","yY","qq"]
>>> sorted(f,key=str.lower)
['abc', 'Dp', 'qq', 'wew', 'WS', 'yY']
>>> sorted(f,key=str.upper)
['abc', 'Dp', 'qq', 'wew', 'WS', 'yY']
#str.capitalize按照字符串首字母大写排序################################################
>>> sorted(f,key=str.capitalize)
['abc', 'Dp', 'qq', 'wew', 'WS', 'yY']
#j举例lambda方式#####################################################################
>>> a
[3, 30, 33, 40, 9]
>>> sorted(a,key=lambda x:math.pow(x,2))
[3, 9, 30, 33, 40]
#lambda#####################################
>>> f #对f按照第二个字母的小写排序
['abc', 'Dp', 'qq', 'wew', 'WS', 'yY']
>>> sorted(f,key=lambda x:x[1].lower())
['abc', 'wew', 'Dp', 'qq', 'WS', 'yY']
#字典排序#############################
>>> d
{1: 'DE', 2: 'DDDB', 3: 'A', 4: 'QPOIE', 5: 'WWB'}
#字段默认按照key值排序,只返回了key的list
>>> sorted(d)
[1, 2, 3, 4, 5]
#按照value的长度排序,只返回了key的list
>>> sorted(d,key=lambda x:len(d[x]))
[3, 1, 5, 2, 4]
#按照value排序,只返回了key的list
>>> sorted(d,key=lambda x:d[x])
[3, 2, 1, 4, 5]
#按照value的长度排序,只返回了key,value构成元组的list
>>> sorted(d.items(),key=lambda x:len(x[1]))
[(3, 'A'), (1, 'DE'), (5, 'WWB'), (2, 'DDDB'), (4, 'QPOIE')]
#按照value的长度排序,返回排序好的dict的
>>> dict(sorted(d.items(),key=lambda x:len(x[1])))
{3: 'A', 1: 'DE', 5: 'WWB', 2: 'DDDB', 4: 'QPOIE'}
#字典排序按照value
my_dict = {'a':5, 'b':4, 'c':6, 'd':3, 'e':2}
sorted(my_dict, key=my_dict.get)
d = {1: 'DE', 2: 'DDDB', 3: 'A', 4: 'QPOIE', 5: 'WWB'}
sorted(d, key=lambda x: len(my_dict.get(x)))自己造:
lambda、函数、类方法__lt__
#自定义方法
#使用元素中数字部分排序
>>> l=["dog1","cat3","swan4","bird7"]
>>> sorted(l)
['bird7', 'cat3', 'dog1', 'swan4']
>>> def sort_str(str):
... if str:
... try:
... c=int(re.findall('\d+',str))
... except:
... c=-1
... return int(c)
...
>>> sorted(l,key=sort_str)
['dog1', 'cat3', 'swan4', 'bird7']
#这个数字出现部分不连续是按照第一次出现的位置
#来一个其他效果:数字部分链接起来后比较 0<1<3<4<5<7<23
>>> def sort_str(str):
... if str:
... try:
... c=int("".join(re.findall('\d+',str)))
... except:
... c=-1
... return int(c)
...
>>> l=["2pig3","dog1","cat3","swan4","bird7","pi5g","han"]
>>> sorted(l,key=sort_str)
['han', 'dog1', 'cat3', 'swan4', 'pi5g', 'bird7', '2pig3']
leetcode中题目:求一个数字组成的数组,能得到的最大数或者最小数
https://leetcode-cn.com/problems/ba-shu-zu-pai-cheng-zui-xiao-de-shu-lcof/
https://leetcode-cn.com/problems/largest-number/
# 先说组成的最小数吧
# 第一种办法:冒泡排序----时间复杂度高点
# 关键点:判断条件是nums[j] + nums[j + 1] > nums[j + 1] + nums[j],意思就是前后组合# # 后要要尽量小,大的往后放
def minNumber(nums):
nums = [str(x) for x in nums]
for i in range(len(nums) - 1):
if_change = False
for j in range(len(nums) - 1 - i):
if nums[j] + nums[j + 1] > nums[j + 1] + nums[j]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
if_change = True
if not if_change:
break
return "".join(nums)
minNumber([3,30,34,5,9]) #测试结果:'3033459'
# 第二种办法:sorted排序
# 难点:这里sort的key使用了functools的cmp_to_key方法(文档最后赘述使用方法)
def minNumber(nums):
import functools
def sort_rule(x, y):
a, b = x + y, y + x
if a > b:
return 1
elif a < b:
return -1
else:
return 0
strs = [str(num) for num in nums]
strs.sort(key=functools.cmp_to_key(sort_rule))
return ''.join(strs)
# 第三种:使用快排思想---效率也不好
def minNumber(nums):
def my_quick_sort(left, right):
if left >= right:
return
i, j = left, right
while i < j:
while strs[j] + strs[left] >= strs[left] + strs[j] and i < j:
j -= 1
while strs[i] + strs[left] <= strs[left] + strs[i] and i < j:
i += 1
strs[i], strs[j] = strs[j], strs[i]
strs[i], strs[left] = strs[left], strs[i]
my_quick_sort(left, i - 1)
my_quick_sort(i + 1, right)
strs = [str(num) for num in nums]
my_quick_sort(0, len(strs) - 1)
return ''.join(strs)
#第四种:使用__lt__的类方法
class A(str):
def __lt__(x,y):
return x+y < y+x
def minNumber(nums):
largest_num = ''.join(sorted(map(str, nums), key=A))
return largest_num
类的__lt__方式排序
#自定义类的对象间比较大小
#这里的__lt__方法就是sort使用的依据吧,没有就会报错,其实比较类的内置方法都有这个作用,还可以用
# __ge__等
class Cat:
def __init__(self, name, age, weight):
self.name = name
self.age = age
self.weight = weight
def __repr__(self):
return repr((self.name, self.age, self.weight))
def __str__(self):
return "Cat({}, {}, {})".format(self.name, self.age, self.weight)
def __lt__(self, other):
if self.age > other.age:
return True
else:
return False
if __name__ == '__main__':
c_list = [Cat("nini", 5, 54),Cat("lele", 8, 4),Cat("guai", 3, 15)]
print(sorted(c_list))
# 如果不想重写__lt__方法就用sorted的key参数指定比较值
print(sorted(c_list, key=lambda x: x.age))报错的样子

应用——leetcode上排序的题:https://leetcode-cn.com/problems/largest-number/
# 数组的数字组成一个最大的数字
#难点理解“30” + “3”< "3"+ "30"
class A(str):
def __lt__(x, y):
return x+y > y+x #是不是就是下面冒泡排序中交换的条件,神奇的点
nums = [3,30,34,5,9]
sorted(map(str, nums), key=A)
#结果为['9', '5', '34', '3', '30'],join之后就是9534330
#套用在冒泡排序上:
nums = map(lambda x: str(x), nums)
for i in range(len(nums) - 1):
if_change = False
for j in range(len(nums) - 1 - i):
if nums[j] + nums[j + 1] < nums[j + 1] + nums[j]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
if_change = True
if not if_change:
break
print(nums)
应用——leetcode : https://leetcode-cn.com/problems/longest-word-in-dictionary-through-deleting/
class Word(str):
def __lt__(x, y):
return len(x) < len(y) or (len(x) == len(y) and x > y)
class Solution:
def findLongestWord(self, s: str, dictionary: List[str]) -> str:
dictionary.sort(key=Word,reverse=1)
for i in dictionary:
index_i, index_s = 0, 0
while index_i < len(i) and index_s < len(s):
if i[index_i] == s[index_s]:
index_i += 1
index_s += 1
if index_i == len(i):
return i
return ""有趣的排序题:
1、按照奇偶排序,奇数放在偶数前面,但是奇数原有的顺序不变,偶数原有的顺序不变
真是1,假是0
>>> o=[True,False,True,False,False]
>>> sorted(o)
[False, False, False, True, True]
>>> t = "1234567890"
>>> sorted(t,key=lambda x: int(x) % 2 == 0)
['1', '3', '5', '7', '9', '2', '4', '6', '8', '0']2、一个字符按照先大写字母、再数字,在小写字母的顺序排序,大写字母原有顺序不变
截图思路

#原理:
v = [[True,False,False],[False,True,False],[False,False,True]]
>>> sorted(v)
[[False, False, True], [False, True, False], [True, False, False]]
f = "23eQt4Wjt6E90"
>>> sorted(f,key=lambda x:[x.isdigit(),x.islower(),x.isupper()])
['Q', 'W', 'E', 'e', 't', 'j', 't', '2', '3', '4', '6', '9', '0']
#优化
>>> sorted([[False,False],[False,True],[True,False]])
[[False, False], [False, True], [True, False]]
sorted(f,key=lambda x:[x.isdigit(),x.islower()])多级排序
1、一个都是字符串的list:按照长度排序,如果长度一样按照字符字典顺序最小到最大(例如:apple的字典顺序差距是a到p的距离ord("p") - ord("a"))
重点就是:(1)比较点转化为tuple,在itemgetter多个比较
(2)利用字典比较不返回value,比较value(value是tuple,tuple大小比较特性)
(3)利用类的__lt__方法
>>> d = ["ale","apple","monkey","plea","abcd","cccd"]
>>> sorted(d,key=len)
['ale', 'plea', 'abcd', 'cccd', 'apple', 'monkey']
>>> sorted(d,key=lambda x: ord(sorted(x)[-1])-ord(sorted(x)[0]))
['cccd', 'abcd', 'ale', 'apple', 'plea', 'monkey']
# 多级排序,构造需要排序的字段使用-----利用itemgetter抓取tuple指定字段
>>> d_temp = [(i,len(i),ord(sorted(i)[0])-ord(sorted(i)[-1])) for i in d]
>>> sorted(d_temp,key=itemgetter(1,2), reverse=1)
[('monkey', 6, -20), ('apple', 5, -15), ('cccd', 4, -1), ('abcd', 4, -3), ('plea', 4, -15), ('ale', 3, -11)]
# 为了返回好看---利用字典按照value排序,value有利用了tuple的排序
>>> sorted(d_temp,key=d_temp.get, reverse=1)
['monkey', 'apple', 'cccd', 'abcd', 'plea', 'ale']
#利用__lt__方式在上面有000000
2、上面的小猫排序,用age排序,如果age一样用体重排序
class Cat:
def __init__(self, name, age, weight):
self.name = name
self.age = age
self.weight = weight
def __repr__(self):
return repr((self.name, self.age, self.weight))
def __str__(self):
return "Cat({}, {}, {})".format(self.name, self.age, self.weight)
def __lt__(self, other):
"""这个内置方法是Cat之间排序使用"""
if self.age < other.age:
return True
else:
return False
def __getitem__(self, item):
"""itermgetter调用的就是这个内置方法"""
return self.__repr__()[item]
def __getattr__(self, item):
"""attrgetter调用的就是这个内置方法"""
cat_dict = {
"name": self.name,
"age": self.age,
"weight": self.weight
}
return cat_dict[item]
if __name__ == '__main__':
c_list = [Cat("nini", 5, 54), Cat("lele", 5, 4), Cat("guai", 3, 15), Cat("dand", 3, 3)]
print sorted(c_list)
# 没有__lt__内置方法,使用key方式指定比较的字段
print sorted(c_list, key=lambda x: x.age)
# itemgetter方式---按照age排序
print sorted(c_list, key=itemgetter(1))
# attrgetter方式---按照age排序
print sorted(c_list, key=attrgetter("age"))
# 多级排序,按照age排序,如果age相同,按照weight排序
print sorted(c_list, key=itemgetter(1, 2))