jsoup爬虫 + android(java)使用详解(入门)+疑难杂症解决
因为公司业务需要,自己是做android开发的,在网上观望了半天爬虫工具,后面选择了jsoup,想问为什么选择它吗?不想问?那好我告诉你,因为简单啊。好了正题开始。
第一步:去官网下载jsoup.jar包https://jsoup.org/,也可以选择在我这儿下载支持一下博主的积分xxxx
第二步:因博主用的okhttputils网络请求工具(张鸿洋大神作品),如果大家用的其他的自己随意。下载地址:
第二步:将两个jar包导入到android项目的libs目录里面,然后记得将他们两个加入到依赖库中,在项目中右键jar包,然后点击add as library,
第三步:找个地址请求一下看看效果,然后再给大家继续讲解用法,那先用百度祭天吧。
这是请求代码
OkHttpUtils.get()
.url("https://www.baidu.com")
.build()
.execute(new StringCallback() {
@Override
public void onError(Call call, Exception e, int i) {
}
@Override
public void onResponse(String s, int i) {
Document doc = Jsoup.parse(s);
Elements el=doc.select("div[id=u1]");
String map=doc.select("a[name=tj_trmap]").text();
Log.d(TAG, "onResponse: "+map);
for (Element li : el) {
String xw=li.select("a[name=tj_trnews]").text();
String all=li.select("a[class=mnav]").text();
Log.d(TAG, "onResponse: "+xw);
Log.d(TAG, "onResponse: "+all);
}
}
});这是打印的日志

这是百度的代码
 从上面可以看到,用了3个方式爬了这些数据,第一是 地图,第二是 新闻,第三是那一排内容。
从上面可以看到,用了3个方式爬了这些数据,第一是 地图,第二是 新闻,第三是那一排内容。
每一行代码的作用:
Document doc = Jsoup.parse(s);//这是爬虫的开始,s是整个网站返回的html代码。
后面可以做两种选择,1.是拿去单独的一个字段就好了。2是拿去一个列表的每一条数据。
1.String map=doc.select("a[name=tj_trmap]").text();
select里面的参数就是你需要拿去字段的标签,如图:![]()
可以依次对应 [ ] 中括号的作用就是标签的属性。就这样你就拿去到了,该网站中a标签的 name属性是tj_trmap的所有字段。
2.拿取列表每一条数据,自己百度。
疑难杂症:
爬出来的网站的html代码居然和网页上查看的代码不一样。
1. 有时候发现部分看的见,部分看不见,那么你需要看看网站是不是有iframe标签,有的话里面的内容可能真的看不到,还必须重新请求一下iframe里面的地址。
![]()
2.请求的地址也有问题,比如说https://stockpage.10jqka.com.cn/realHead_v2.html#hs_000625
网页上打开正常显示数据,而自己请求又是一回事了,因为#后面的东西是不带的,服务器是不认#后面的内容,除非用webview打开,听我师傅说必须拿到json数据才行,后面发现很多网站都这样,那只有自己想解决方法。
解决办法如下:
先地址http://stockpage.10jqka.com.cn/realHead_v2.html#hs_000625,然后用google浏览器打开,打开开发者工具选择Sources,发现last.js返回的就是json数据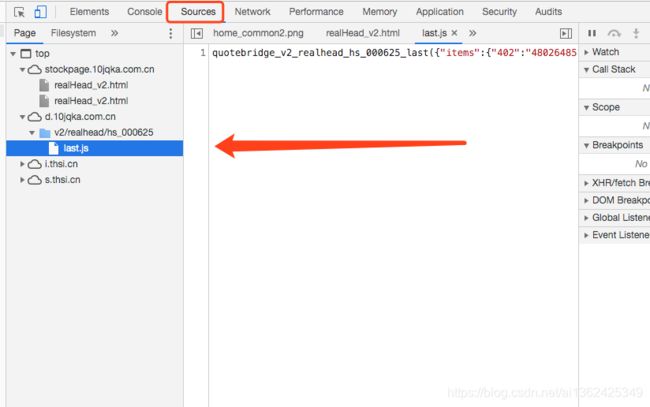
然后就是把它拼装成一个链接https://d.10jqka.com.cn/v2/realhead/hs_002540/last.js。值得注意的是它是https,不然会报错。然后数据就拿到了。然后对其进行json数据解析,数据都拿到了,然后在分配到自己app里面。