机器学习之逻辑回归,一文掌握逻辑回归算法知识文集

作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。
多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。
欢迎 点赞✍评论⭐收藏
文章目录
- 人工智能(逻辑回归算法)
-
- 一、逻辑回归算法知识
-
- 01. 梯度下降法(Gradient Descent)
-
- 1.1 什么是梯度下降法?
- 1.2 梯度下降法的具体步骤和算法公式?
- 1.3 梯度下降法的算法公式实现?
- 02. 牛顿法(Newton's Method)和拟牛顿法(Quasi-Newton Methods)
-
- 2.1 什么是牛顿法和拟牛顿法?
- 2.2 牛顿法和拟牛顿法的具体步骤和算法公式?
- 2.3 牛顿法和拟牛顿法的算法公式实现?
- 03. 共轭梯度法(Conjugate Gradient)
-
- 3.1 什么是共轭梯度法?
- 3.2 共轭梯度法的具体步骤和算法公式?
- 3.3 共轭梯度法的算法公式实现?
- 04. 改进的随机梯度下降法(Improved Stochastic Gradient Descent)
-
- 4.1 什么是改进的随机梯度下降法?
- 05. Adagrad(自适应梯度算法)
-
- 5.1 什么是 Adagrad?
- 5.2 RMSprop(均方根传播)的具体步骤和算法公式?
- 5.3 RMSprop(均方根传播)的算法公式实现?
- 06. RMSprop(均方根传播)
-
- 6.1 什么是RMSprop?
- 6.2 Adam(自适应矩估计)的具体步骤和算法公式?
- 6.3 Adam(自适应矩估计)的算法公式实现?
- 07. Adam(自适应矩估计)
-
- 7.1 什么是 Adam?
- 7.2 Adam的具体步骤和算法公式?
- 7.3 Adam的算法公式实现?
- 08. LBFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)
-
- 8.1 什么是 LBFGS?
- 8.2 LBFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)的具体步骤和算法公式?
- 8.3 LBFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)的算法公式实现?
- 09. Adamax
-
- 9.1 什么是 Adamax ?
- 9.2 Adamax的具体步骤和算法公式?
- 9.3 Nadam的算法公式实现?
- 10. Nadam
-
- 10.1 什么是**Nadam ?
- 10.2 Nadam的具体步骤和算法公式?
- 10.3 Nadam的算法公式实现?
人工智能(逻辑回归算法)
一、逻辑回归算法知识
01. 梯度下降法(Gradient Descent)
1.1 什么是梯度下降法?
梯度下降法是最常用的优化算法之一。它通过迭代更新模型参数,沿着损失函数梯度的反方向逐步进行参数调整。包括批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)和小批量梯度下降(Mini-batch Gradient Descent)等变种。
1.2 梯度下降法的具体步骤和算法公式?
梯度下降法是一种常用的优化算法,用于最小化一个函数的值。该算法通常用于机器学习中的模型训练过程,例如逻辑回归、线性回归等。下面是梯度下降法的具体步骤和算法公式:
算法输入:学习率(learning rate) α \alpha α、迭代次数 T T T、损失函数 J ( θ ) J(\theta) J(θ)
-
初始化参数 θ = [ θ 1 , θ 2 , . . . , θ n ] \theta = [\theta_1, \theta_2, ..., \theta_n] θ=[θ1,θ2,...,θn],其中 n n n 表示模型参数的个数。
-
将迭代次数设置为 t = 0 t = 0 t=0。
-
如果 t > T t > T t>T,则停止迭代,否则继续下面的步骤。
-
计算损失函数 J ( θ ) J(\theta) J(θ) 对参数 θ \theta θ 的梯度 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ)。
-
根据学习率 α \alpha α,更新参数 θ \theta θ:
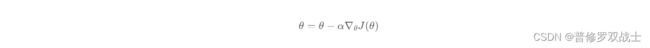
-
将迭代次数 t t t 加 1。
-
返回步骤 3。

1.3 梯度下降法的算法公式实现?
梯度下降法的算法公式可以很简单地实现。下面是一个基本的梯度下降算法的伪代码:
输入: 学习率 α \alpha α,迭代次数 T T T,初始参数 θ \theta θ
Repeat T T T 次: 计算损失函数 J ( θ ) J(\theta) J(θ) 对参数 θ \theta θ 的梯度 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ) 更新参数 θ = θ − α ∇ θ J ( θ ) \theta = \theta - \alpha \nabla_\theta J(\theta) θ=θ−α∇θJ(θ)
返回参数 θ \theta θ
以下是一个简化的 Python 实现代码示例:
def gradient_descent(X, y, learning_rate, iterations):
# 初始化参数
theta = np.zeros(X.shape[1])
m = len(y)
for i in range(iterations):
# 计算模型预测值
h = np.dot(X, theta)
# 计算损失函数对参数的偏导数
gradient = (1 / m) * np.dot(X.T, (h - y))
# 更新参数
theta = theta - learning_rate * gradient
return theta
在这个代码中,X 是特征矩阵,y 是目标向量,learning_rate 是学习率,iterations 是迭代次数。通过计算参数梯度和更新参数,最终返回训练得到的参数 θ \theta θ。
请注意,该代码示例假设使用线性回归进行梯度下降,因此对应的损失函数为均方误差。对于不同的模型和损失函数,需要根据具体情况进行相应的修改。
02. 牛顿法(Newton’s Method)和拟牛顿法(Quasi-Newton Methods)
2.1 什么是牛顿法和拟牛顿法?
牛顿法和拟牛顿法是一类基于二阶导数信息的优化算法。牛顿法使用二阶导数(海森矩阵)来更新参数,可以更快地收敛,但计算代价较高。拟牛顿法通过近似海森矩阵来降低计算复杂度,并在一定程度上保持收敛性能。
2.2 牛顿法和拟牛顿法的具体步骤和算法公式?
牛顿法(Newton’s Method)和拟牛顿法(Quasi-Newton Method)都是一种迭代优化算法,用于求解无约束优化问题。它们通过逐步逼近目标函数的最小值点,并更新参数的方法不同。下面分别介绍牛顿法和拟牛顿法的具体步骤和算法公式:
-
牛顿法: 牛顿法利用目标函数的二阶导数(海森矩阵)来逼近目标函数的局部形状,并通过更新参数来逼近最小值点。
输入:目标函数 f ( x ) f(x) f(x), 初始点 x 0 x_0 x0,迭代停止准则(例如,梯度大小或迭代次数)
- 初始化 x = x 0 x = x_0 x=x0,设置迭代次数 k = 0 k = 0 k=0。
- 计算目标函数的一阶导数(梯度)和二阶导数(海森矩阵): g k = ∇ f ( x k ) g_k = \nabla f(x_k) gk=∇f(xk), H k = ∇ 2 f ( x k ) H_k = \nabla^2 f(x_k) Hk=∇2f(xk)。
- 求解方程 H k Δ x = − g k H_k \Delta x = -g_k HkΔx=−gk,得到搜索方向 Δ x \Delta x Δx。
- 选择合适的步长 α \alpha α,更新参数: x k + 1 = x k + α Δ x x_{k+1} = x_k + \alpha \Delta x xk+1=xk+αΔx。
- 若满足停止准则(如梯度的大小是否小于某个阈值),则停止迭代;否则,令 k = k + 1 k = k + 1 k=k+1,返回步骤 2。
在每次迭代中,牛顿法使用搜索方向和步长来更新参数,并在每一步中计算目标函数的一阶和二阶导数。相比于梯度下降法,牛顿法可以更快地收敛到最小值附近。
-
拟牛顿法: 拟牛顿法是对牛顿法的改进,因为计算精确的海森矩阵较为困难,拟牛顿法使用近似的方法来构造参数更新规则。
输入:目标函数 f ( x ) f(x) f(x),初始点 x 0 x_0 x0,迭代停止准则,初始的近似海森矩阵 B 0 B_0 B0。
- 初始化 x = x 0 x = x_0 x=x0,设置迭代次数 k = 0 k = 0 k=0。
- 计算目标函数的一阶导数(梯度): g k = ∇ f ( x k ) g_k = \nabla f(x_k) gk=∇f(xk)。
- 求解方程 B k Δ x = − g k B_k \Delta x = -g_k BkΔx=−gk,得到搜索方向 Δ x \Delta x Δx。
- 选择合适的步长 α \alpha α,更新参数: x k + 1 = x k + α Δ x x_{k+1} = x_k + \alpha \Delta x xk+1=xk+αΔx。
- 计算新迭代点的梯度 g k + 1 = ∇ f ( x k + 1 ) g_{k+1} = \nabla f(x_{k+1}) gk+1=∇f(xk+1)。
- 使用近似的方法更新近似海森矩阵 B k B_k Bk。
- 若满足停止准则(如梯度的大小是否小于某个阈值),则停止迭代;否则,令 k = k + 1 k = k + 1 k=k+1,返回步骤 3。
拟牛顿法中,迭代过程中的海森矩阵 B k B_k Bk 是通过历史的一阶导数和参数更新值来逼近目标函数的海森矩阵。常用的拟牛顿法包括DFP(Davidon-Fletcher-Powell)方法和BFGS(Broyden-Fletcher-Goldfarb-Shanno)方法等。
2.3 牛顿法和拟牛顿法的算法公式实现?
牛顿法和拟牛顿法的具体算法公式可以通过数学推导得到,下面是它们的算法公式实现:
-
牛顿法的算法公式:
输入: 目标函数 f ( x ) f(x) f(x),梯度函数 g ( x ) g(x) g(x),海森矩阵函数 H ( x ) H(x) H(x),初始点 x 0 x_0 x0,迭代停止准则(如梯度大小或迭代次数)
Repeat 直到满足停止准则:
- 计算梯度: g k = g ( x k ) g_k = g(x_k) gk=g(xk)
- 计算海森矩阵: H k = H ( x k ) H_k = H(x_k) Hk=H(xk)
- 求解线性方程组: H k Δ x = − g k H_k \Delta x = -g_k HkΔx=−gk,找到搜索方向 Δ x \Delta x Δx
- 选择合适的步长 α \alpha α,更新参数: x k + 1 = x k + α Δ x x_{k+1} = x_k + \alpha \Delta x xk+1=xk+αΔx
返回参数 x ∗ x^* x∗
在实现中需要注意,解线性方程组的方法可以选择使用直接求解方法(如LU分解、Cholesky分解)或迭代方法(如共轭梯度法)。
-
拟牛顿法的算法公式:
输入: 目标函数 f ( x ) f(x) f(x),梯度函数 g ( x ) g(x) g(x),初始点 x 0 x_0 x0,迭代停止准则,初始的近似海森矩阵 B 0 B_0 B0
Repeat 直到满足停止准则:
- 计算梯度: g k = g ( x k ) g_k = g(x_k) gk=g(xk)
- 求解线性方程组: B k Δ x = − g k B_k \Delta x = -g_k BkΔx=−gk,找到搜索方向 Δ x \Delta x Δx
- 选择合适的步长 α \alpha α,更新参数: x k + 1 = x k + α Δ x x_{k+1} = x_k + \alpha \Delta x xk+1=xk+αΔx
- 计算新迭代点的梯度: g k + 1 = g ( x k + 1 ) g_{k+1} = g(x_{k+1}) gk+1=g(xk+1)
- 更新近似海森矩阵 B k B_k Bk 的方法(如DFP、BFGS等)
返回参数 x ∗ x^* x∗
在实现拟牛顿法时,需要选择合适的近似海森矩阵更新方法,常用的方法有DFP、BFGS、SR1(Symmetric Rank-One)等。
下面是使用Python实现牛顿法和拟牛顿法的示例代码:
-
牛顿法的Python实现:
import numpy as np def newton_method(f, df, d2f, x0, epsilon=1e-6, max_iter=100): x = x0 for _ in range(max_iter): g = df(x) H = d2f(x) dx = -np.linalg.solve(H, g) x += dx if np.linalg.norm(dx) < epsilon: break return x # 示例函数 def f(x): return x**2 + 2*x + 1 # 示例函数的一阶导数 def df(x): return 2*x + 2 # 示例函数的二阶导数 def d2f(x): return 2 # 使用牛顿法求解最小值点 x0 = 0 # 初始点 x_min = newton_method(f, df, d2f, x0) print("最小值点:", x_min) print("最小值:", f(x_min)) -
拟牛顿法的Python实现(以BFGS方法为例):
import numpy as np def bfgs_method(f, df, x0, epsilon=1e-6, max_iter=100): n = x0.shape[0] B = np.eye(n) # 初始的近似海森矩阵 x = x0 for _ in range(max_iter): g = df(x) dx = -np.linalg.solve(B, g) # 求解搜索方向 alpha = line_search(f, df, x, dx) # 步长选择方法(这里假设有个line_search函数) x_new = x + alpha*dx g_new = df(x_new) s = x_new - x y = g_new - g rho = 1 / np.dot(y, s) B = (np.eye(n) - rho * np.outer(s, y)) @ B @ (np.eye(n) - rho * np.outer(y, s)) + rho*np.outer(s, s) x = x_new if np.linalg.norm(alpha*dx) < epsilon: break return x # 示例函数和一阶导函数同上 # 使用BFGS拟牛顿法求解最小值点 x0 = np.array([0, 0]) # 初始点 x_min = bfgs_method(f, df, x0) print("最小值点:", x_min) print("最小值:", f(x_min))
这两个示例代码是简化的实现,仅适用于特定的目标函数和问题。在实际应用中,需要根据具体问题进行调整和改进,例如适当修改迭代停止准则、步长选择方法等。同时,可以使用更高效的数值计算库(如NumPy)和线性方程组求解方法(如SciPy库的scipy.linalg.solve)来提高计算效率。
03. 共轭梯度法(Conjugate Gradient)
3.1 什么是共轭梯度法?
共轭梯度法是一种迭代方法,它可以更快地收敛于二次型损失函数。如果逻辑回归的损失函数是二次型,共轭梯度法是一种高效且可行的优化算法。
3.2 共轭梯度法的具体步骤和算法公式?
共轭梯度法(Conjugate Gradient Method)是一种用于解决线性方程组的迭代方法,它也可以被用于求解无约束最优化问题。这里给出共轭梯度法在求解无约束最优化问题时的步骤和算法公式:
假设我们要求解无约束最优化问题 min f ( x ) \min \, f(x) minf(x),其中 f ( x ) f(x) f(x) 是目标函数。令 x ∗ x^* x∗ 是最小值点。
-
初始化:选择初始点 x 0 x_0 x0,计算梯度 g 0 = ∇ f ( x 0 ) g_0 = \nabla f(x_0) g0=∇f(x0),初始化搜索方向 d 0 = − g 0 d_0 = -g_0 d0=−g0,迭代初始点索引 k = 0 k = 0 k=0。
-
搜索步长:选择一个合适的步长 α k \alpha_k αk,例如通过线搜索方法(比如Armijo线搜索、Wolfe线搜索等)。
-
更新参数:更新参数 x k + 1 = x k + α k d k x_{k+1} = x_k + \alpha_k d_k xk+1=xk+αkdk。
-
计算梯度:计算新的梯度 g k + 1 = ∇ f ( x k + 1 ) g_{k+1} = \nabla f(x_{k+1}) gk+1=∇f(xk+1)。
-
检查终止准则:如果满足终止准则(如梯度大小小于给定的阈值或达到最大迭代次数),则终止迭代,返回最小值点 x ∗ x^* x∗。否则,继续下面的步骤。
-
计算步长系数 β k \beta_k βk: β k = ∥ g k + 1 ∥ 2 ∥ g k ∥ 2 \beta_k = \frac{{\|g_{k+1}\|^2}}{{\|g_{k}\|^2}} βk=∥gk∥2∥gk+1∥2。
-
更新搜索方向:更新搜索方向 d k + 1 = − g k + 1 + β k d k d_{k+1} = -g_{k+1} + \beta_k d_k dk+1=−gk+1+βkdk。
-
增加迭代次数: k = k + 1 k = k + 1 k=k+1。
-
转到步骤 2。
在每次迭代中,共轭梯度法利用之前的搜索方向的信息,以更高效地搜索最小值点。在第 k k k 步迭代中, d k d_k dk 是在 k k k-1 步迭代后找到的收敛共轭搜索方向。
需要注意的是,共轭梯度法通常用于求解大规模线性方程组或凸二次规划问题,其中线性方程组的系数矩阵是对称正定的。对于一般的非线性最优化问题,可以采用共轭梯度法的变种(如共轭梯度法和拟牛顿法的结合)来加速收敛。
请注意,共轭梯度法的具体实现可能会因应用和问题的不同而有所调整和改进,例如使用合适的线搜索方法和收敛准则。同时,可以使用高效的数值计算库(如NumPy)和线性方程组求解方法(如SciPy库的scipy.linalg.solve)来提高计算效率。
3.3 共轭梯度法的算法公式实现?
以下是共轭梯度法的算法公式实现,以求解线性方程组为例:
输入: 对称正定矩阵 A A A,向量 b b b 输出: 近似解 x x x
-
初始化:选择初始点 x 0 x_0 x0,计算初始残差 r 0 = b − A x 0 r_0 = b - A x_0 r0=b−Ax0,初始化搜索方向 d 0 = r 0 d_0 = r_0 d0=r0,设定迭代初始点索引 k = 0 k = 0 k=0。
-
迭代更新:对于 k = 0 , 1 , 2 , … k = 0, 1, 2, \dots k=0,1,2,…,执行以下步骤:
2.1. 计算步长: α k = r k T r k d k T A d k \alpha_k = \frac{{r_k^T r_k}}{{d_k^T A d_k}} αk=dkTAdkrkTrk。
2.2. 更新参数: x k + 1 = x k + α k d k x_{k+1} = x_k + \alpha_k d_k xk+1=xk+αkdk。
2.3. 计算残差: r k + 1 = b − A x k + 1 r_{k+1} = b - A x_{k+1} rk+1=b−Axk+1。
2.4. 检查终止准则:若满足终止准则(如残差大小小于给定的阈值或达到最大迭代次数),则终止迭代,返回近似解 x x x。
2.5. 计算步长系数: β k = r k + 1 T r k + 1 r k T r k \beta_k = \frac{{r_{k+1}^T r_{k+1}}}{{r_k^T r_k}} βk=rkTrkrk+1Trk+1。
2.6. 更新搜索方向: d k + 1 = r k + 1 + β k d k d_{k+1} = r_{k+1} + \beta_k d_k dk+1=rk+1+βkdk。
2.7. 增加迭代次数: k = k + 1 k = k + 1 k=k+1。
2.8. 转到步骤 2.1。
在每次迭代中,共轭梯度法利用了之前的搜索方向的信息,以更高效地搜索最小值点。在第 k k k 步迭代中, d k d_k dk 是在 k k k-1 步迭代后找到的收敛共轭搜索方向。
需要注意的是,共轭梯度法的实现还需要考虑一些细节,例如选择合适的初始点、终止准则的选择、计算过程中的数值稳定性等。此外,在实际应用中,通常会使用数值计算库提供的高效线性方程组求解方法(如Cholesky分解、共轭梯度法等)来加速计算过程。
以上提供的是共轭梯度法的基本算法公式实现,具体的实现方式可以根据不同的编程语言和数值计算库进行相应的调整和优化。
下面是使用 Python 实现共轭梯度法求解线性方程组的示例代码:
import numpy as np
def conjugate_gradient(A, b, x0, max_iter=1000, tol=1e-6):
"""
使用共轭梯度法求解线性方程组 Ax = b,其中 A 是对称正定矩阵。
:param A: 对称正定矩阵
:param b: 右侧向量
:param x0: 初始点
:param max_iter: 最大迭代次数
:param tol: 迭代终止的残差阈值
:return: 近似解 x
"""
x = x0
r = b - np.dot(A, x)
d = r
delta = np.dot(r, r)
for i in range(max_iter):
q = np.dot(A, d)
alpha = delta / np.dot(d, q)
x = x + alpha * d
r_new = r - alpha * q
delta_new = np.dot(r_new, r_new)
if np.sqrt(delta_new) < tol:
break
beta = delta_new / delta
d = r_new + beta * d
r = r_new
delta = delta_new
return x
其中,输入参数 A 和 b 分别为线性方程组的系数矩阵和右侧向量,x0 为初始点,max_iter 为最大迭代次数,tol 为迭代终止的残差阈值。对于大规模的线性方程组,可以采用稀疏矩阵进行存储和计算,以提高计算效率。
下面给出一个示例用例:
# 构造一个对称正定矩阵 A 和右侧向量 b
n = 100
A = np.random.randn(n, n)
A = np.dot(A.T, A)
b = np.random.randn(n)
# 使用初始化为零的向量作为初始点
x0 = np.zeros(n)
# 调用共轭梯度法函数求解线性方程组 Ax = b
x = conjugate_gradient(A, b, x0)
# 输出近似解 x
print("近似解 x =", x)
注意,对于一般的非线性最优化问题,需要结合共轭梯度法和其他优化方法,例如牛顿法、拟牛顿法、共轭梯度法和拟牛顿法的结合等。此外,在实际应用中需要对算法进行调整和优化,例如选择合适的终止条件、计算过程中的数值稳定性等。
04. 改进的随机梯度下降法(Improved Stochastic Gradient Descent)
4.1 什么是改进的随机梯度下降法?
针对随机梯度下降法的一些缺点,如收敛速度较慢、参数更新不稳定等问题,已经提出了很多改进的随机梯度下降算法。例如,AdaGrad、RMSprop、Adam等算法可以自适应地调整学习率。
05. Adagrad(自适应梯度算法)
5.1 什么是 Adagrad?
Adagrad是一种自适应学习率算法,它根据参数的历史梯度进行自适应的学习率调整。它对于稀疏特征的处理效果较好,能够有效地进行模型训练。
5.2 RMSprop(均方根传播)的具体步骤和算法公式?
RMSProp(均方根传播)是一种基于梯度的自适应学习率算法,它可以根据每个参数的历史梯度大小来自适应地调整学习率。以下是RMSProp算法的具体步骤和算法公式:
输入:学习率 α \alpha α,初始参数 w w w,目标函数的梯度函数 ∇ f ( w ) \nabla f(w) ∇f(w),衰减因子 ρ \rho ρ,常数 ϵ \epsilon ϵ。 输出:参数的最优解 w ⋆ w^\star w⋆。
-
初始化:初始参数 w w w,初始平方梯度和 r = 0 r = 0 r=0,迭代次数 t = 0 t = 0 t=0。
-
迭代更新:对于每个迭代 t t t,执行以下步骤:
2.1. 计算当前迭代的梯度 ∇ t = ∇ f ( w t ) \nabla_t = \nabla f(w_t) ∇t=∇f(wt)。
2.2. 计算平方梯度和的衰减平均: r = ρ r + ( 1 − ρ ) ∇ t ⊙ ∇ t r = \rho r + (1 - \rho) \nabla_t \odot \nabla_t r=ρr+(1−ρ)∇t⊙∇t ( ⊙ \odot ⊙ 表示按元素相乘)。
2.3. 调整学习率: η t = α r + ϵ \eta_t = \frac{\alpha}{\sqrt{r + \epsilon}} ηt=r+ϵα。
2.4. 更新参数: w t + 1 = w t − η t ⊙ ∇ t w_{t+1} = w_t - \eta_t \odot \nabla_t wt+1=wt−ηt⊙∇t。
2.5. 增加迭代次数: t = t + 1 t = t + 1 t=t+1。
-
终止准则:根据预设的终止准则(如达到最大迭代次数或梯度变化小于阈值)决定是否停止迭代。若终止迭代,则输出最优解 w ⋆ w^\star w⋆;否则,返回步骤 2。
RMSProp算法与Adagrad算法都是自适应学习率算法,但是RMSProp算法引入了衰减平均的概念,可以缓解学习率急剧下降的问题。在RMSProp算法中,参数的梯度平方和会通过衰减平均进行平滑,以消除梯度信息的噪声影响,同时计算出的学习率也会相应地变得更加平滑和稳定,提高了优化的性能。
需要注意的是,RMSProp算法和Adagrad算法类似,都需要对目标函数进行偏导数求解,并根据求解结果生成梯度函数。在实践应用中,还需要对RMSProp算法进行调参和优化,例如选择合适的学习率和衰减因子,常数 ϵ \epsilon ϵ 的取值,初始参数,终止条件等,以提高算法的效率和鲁棒性。
5.3 RMSprop(均方根传播)的算法公式实现?
下面是使用 Python 实现 RMSProp 算法的示例代码:
import numpy as np
def rmsprop(grad_func, init_theta, alpha=0.01, rho=0.9, eps=1e-8, max_iters=1000, tol=1e-6):
"""
使用 RMSProp 算法求解无约束优化问题:min f(theta),其中 grad_func 是目标函数的梯度函数。
:param grad_func: 目标函数的梯度函数
:param init_theta: 参数的初始值
:param alpha: 初始学习率
:param rho: 平方梯度和的衰减因子
:param eps: 避免除零错误的小常数
:param max_iters: 最大迭代次数
:param tol: 最小收敛差
:return: 近似最优解 theta
"""
theta = init_theta
grad_squared_sum = np.zeros_like(init_theta)
for i in range(max_iters):
grad = grad_func(theta)
grad_squared_sum = rho * grad_squared_sum + (1 - rho) * grad ** 2
learning_rate = alpha / (np.sqrt(grad_squared_sum) + eps)
theta_new = theta - learning_rate * grad
if np.linalg.norm(theta_new - theta) < tol:
break
theta = theta_new
return theta
其中,输入参数 grad_func 是目标函数的梯度函数(形如 grad_func(theta),返回 theta 点处的梯度),init_theta 是参数的初始值,alpha 是初始学习率,rho 是平方梯度和的衰减因子,eps 是避免除零错误的小常数,max_iters 是最大迭代次数,tol 是最小收敛差。输出参数为近似最优解 theta。
需要注意的是,目标函数的梯度函数应满足一定的可导性和连续性条件,否则求解过程可能出现问题。此外,在实践应用中,需要对 RMSProp 算法进行调参和优化,例如选择合适的学习率、衰减因子、常数 ϵ \epsilon ϵ 的取值、初始参数、终止条件等,以提高算法的表现和效率。
06. RMSprop(均方根传播)
6.1 什么是RMSprop?
RMSprop是一种自适应学习率算法,它通过利用参数梯度的移动平均值来调整学习率。它可以自动调整学习率的大小,从而在不同特征上进行合理的更新。
6.2 Adam(自适应矩估计)的具体步骤和算法公式?
Adam(自适应矩估计)是一种基于梯度的自适应学习率算法,它采用梯度的一阶矩估计和二阶矩估计自适应地调整学习率。以下是Adam算法的具体步骤和算法公式:
输入:学习率 α \alpha α,初始参数 w w w,目标函数的梯度函数 ∇ f ( w ) \nabla f(w) ∇f(w),一阶矩估计的衰减因子 β 1 \beta_1 β1,二阶矩估计的衰减因子 β 2 \beta_2 β2,常数 ϵ \epsilon ϵ。 输出:参数的最优解 w ⋆ w^\star w⋆。
-
初始化:初始参数 w w w,一阶矩估计 m 0 = 0 \mathbf{m}_0 = 0 m0=0,二阶矩估计 v 0 = 0 \mathbf{v}_0 = 0 v0=0,迭代次数 t = 0 t = 0 t=0。
-
迭代更新:对于每个迭代 t t t,执行以下步骤:
2.1. 计算当前迭代的梯度 ∇ t = ∇ f ( w t ) \nabla_t = \nabla f(w_t) ∇t=∇f(wt)。
2.2. 更新一阶矩估计: m t = β 1 m t − 1 + ( 1 − β 1 ) ∇ t \mathbf{m}_t = \beta_1 \mathbf{m}_{t-1} + (1 - \beta_1) \nabla_t mt=β1mt−1+(1−β1)∇t。
2.3. 更新二阶矩估计: v t = β 2 v t − 1 + ( 1 − β 2 ) ∇ t 2 \mathbf{v}_t = \beta_2 \mathbf{v}_{t-1} + (1 - \beta_2) \nabla_t^2 vt=β2vt−1+(1−β2)∇t2。
2.4. 校正一阶矩估计的偏差: m ^ t = m t 1 − β 1 t \hat{\mathbf{m}}_t = \frac{\mathbf{m}_t}{1 - \beta_1^t} m^t=1−β1tmt。
2.5. 校正二阶矩估计的偏差: v ^ t = v t 1 − β 2 t \hat{\mathbf{v}}_t = \frac{\mathbf{v}_t}{1 - \beta_2^t} v^t=1−β2tvt。
2.6. 计算学习率调整量: Δ w t = α m ^ t v ^ t + ϵ \Delta w_t = \frac{\alpha \hat{\mathbf{m}}_t}{\sqrt{\hat{\mathbf{v}}_t} + \epsilon} Δwt=v^t+ϵαm^t。
2.7. 更新参数: w t + 1 = w t − Δ w t w_{t+1} = w_t - \Delta w_t wt+1=wt−Δwt。
2.8. 增加迭代次数: t = t + 1 t = t + 1 t=t+1。
-
终止准则:根据预设的终止准则(如达到最大迭代次数或梯度变化小于阈值)决定是否停止迭代。若终止迭代,则输出最优解 w ⋆ w^\star w⋆;否则,返回步骤 2。
Adam算法的核心思想在于利用梯度的一阶矩估计和二阶矩估计对学习率进行自适应调整,同时通过校正偏差来提高精度。具体来说,Adam算法使用一阶矩估计 m t \mathbf{m}_t mt 来估计梯度的均值,用二阶矩估计 v t \mathbf{v}_t vt 来估计梯度的方差(即均方差) ,然后结合这两个估计量来自适应地调整学习率。在实践应用中,还需要对Adam算法进行调参和优化,例如选择合适的衰减因子 β 1 \beta_1 β1 和 β 2 \beta_2 β2,常数 ϵ \epsilon ϵ 的取值,初始参数,终止条件等,以提高算法的效率和鲁棒性。
需要注意的是,和RMSProp算法、Adagrad算法一样,Adam算法都需要对目标函数进行偏导数求解,并根据求解
6.3 Adam(自适应矩估计)的算法公式实现?
下面是Adam算法的具体实现,包括算法公式和伪代码:
算法公式:
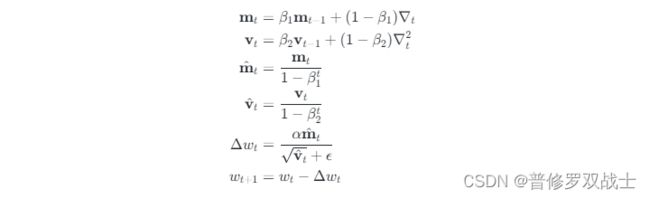
伪代码:
输入:学习率 alpha, 初始参数 w, 目标函数的梯度函数 grad_f(w), 一阶矩估计的衰减因子 beta1, 二阶矩估计的衰减因子 beta2, 常数 epsilon
输出:参数的最优解 w_star
初始化:初始参数 w, 一阶矩估计 m_0 = 0, 二阶矩估计 v_0 = 0, 迭代次数 t = 0
while 没有达到终止准则 do
t = t + 1
当前迭代的梯度 grad_t = grad_f(w)
更新一阶矩估计:m_t = beta1 * m_{t-1} + (1 - beta1) * grad_t
更新二阶矩估计:v_t = beta2 * v_{t-1} + (1 - beta2) * grad_t^2
校正一阶矩估计的偏差:m_hat_t = m_t / (1 - beta1^t)
校正二阶矩估计的偏差:v_hat_t = v_t / (1 - beta2^t)
计算学习率调整量:delta_w_t = alpha * m_hat_t / (sqrt(v_hat_t) + epsilon)
更新参数:w = w - delta_w_t
返回参数的最优解 w_star
希望这个实现可以帮助到你!请注意,这只是一个粗略的伪代码示例,具体的实现可能会因编程语言和应用环境而有所不同。在实际使用Adam算法时,还需要进行一些调参和优化来提高算法的性能和收敛速度。
07. Adam(自适应矩估计)
7.1 什么是 Adam?
Adam是一种融合了Momentum和RMSprop的自适应学习率算法。Adam算法具有较好的适应性和鲁棒性,能够在训练过程中自动调整学习率和动量。
7.2 Adam的具体步骤和算法公式?
Adam是一种自适应学习率方法,可以用于优化神经网络的权重,在深度学习领域被广泛使用。它结合了RMSProp和Momentum的优点,能够在不同维度自适应地调整学习率,并对梯度的历史信息进行加权平均,从而更加准确地更新模型参数。Adam是一种基于梯度的优化算法,可以通过计算梯度的一阶矩和二阶矩估计来更新模型的参数,其具体步骤如下:
- 初始化参数:学习率 α \alpha α,动量参数 β 1 \beta_1 β1,二阶动量衰减率 β 2 \beta_2 β2,初始一阶矩和二阶矩 m 0 m_0 m0 和 v 0 v_0 v0,一般情况下, m 0 m_0 m0, v 0 v_0 v0 初始化为0。
- 在每次迭代中,通过反向传播计算损失函数的梯度 g t g_t gt。
- 计算梯度的一阶矩 m t m_t mt 和二阶矩 v t v_t vt:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1-\beta_1)g_t mt=β1mt−1+(1−β1)gt
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1-\beta_2)g_t^2 vt=β2vt−1+(1−β2)gt2 - 对一阶和二阶矩进行偏差修正,从而减轻因初始化而引入的偏差:
m ^ t = m t 1 − β 1 t \hat{m}_t = \frac{m_t}{1-\beta_1^t} m^t=1−β1tmt
v ^ t = v t 1 − β 2 t \hat{v}_t = \frac{v_t}{1-\beta_2^t} v^t=1−β2tvt - 使用修正后的 m t m_t mt 和 v t v_t vt,以及超参数 α \alpha α 和 ϵ \epsilon ϵ 更新参数:
Δ θ t = − α v ^ t + ϵ m ^ t \Delta\theta_t = -\frac{\alpha}{\sqrt{\hat{v}_t}+\epsilon} \hat{m}_t Δθt=−v^t+ϵαm^t
θ t = θ t − 1 + Δ θ t \theta_t = \theta_{t-1} + \Delta\theta_t θt=θt−1+Δθt
其中, t t t 表示迭代的次数, θ \theta θ 是需要进行优化的参数, α \alpha α 是学习率, β 1 \beta_1 β1 和 β 2 \beta_2 β2 是动量系数, ϵ \epsilon ϵ 是一个很小的数,以防分母过小。
需要注意的是,Adam算法的偏差校正非常重要,可以提高算法的性能和收敛速度。在Adam算法中, m ^ t \hat{m}_t m^t 和 v ^ t \hat{v}_t v^t 是在更新权重时对动量和缩放系数进行校正的项。
上述公式中 Δ θ \Delta\theta Δθ 表示需要更新的参数变化量,即实现时需要将 θ \theta θ 增加 Δ θ \Delta\theta Δθ 才能更新参数。
下面是Adam算法的数学公式表示:
-
初始化:
m 0 = 0 m_0 = 0 m0=0
v 0 = 0 v_0 = 0 v0=0
β 1 = 0.9 \beta_1 = 0.9 β1=0.9
β 2 = 0.999 \beta_2 = 0.999 β2=0.999
α = 0.001 \alpha = 0.001 α=0.001
ϵ = 1 0 − 8 \epsilon = 10^{-8} ϵ=10−8 -
对于 t = 1, 2, …,执行以下更新:
计算损失函数关于模型参数的梯度: g t = ∇ θ J ( θ t − 1 ) g_t = \nabla_{\theta} J(\theta_{t-1}) gt=∇θJ(θt−1)
更新梯度一阶矩估计: m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1-\beta_1)g_t mt=β1mt−1+(1−β1)gt
更新梯度二阶矩估计: v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1-\beta_2)g_t^2 vt=β2vt−1+(1−β2)gt2
偏差校正后的一阶矩估计: m ^ t = m t 1 − β 1 t \hat{m}_t = \frac{m_t}{1-\beta_1^t} m^t=1−β1tmt
偏差校正后的二阶矩估计
7.3 Adam的算法公式实现?
以下是使用Python实现Adam算法的代码示例:
import numpy as np
def adam_optimizer(grad, m, v, beta1, beta2, alpha, epsilon, t):
# 更新梯度一阶矩估计
m = beta1 * m + (1 - beta1) * grad
# 更新梯度二阶矩估计
v = beta2 * v + (1 - beta2) * (grad ** 2)
# 偏差校正后的一阶矩估计
m_hat = m / (1 - beta1**t)
# 偏差校正后的二阶矩估计
v_hat = v / (1 - beta2**t)
# 更新参数
param = - alpha * m_hat / (np.sqrt(v_hat) + epsilon)
return param, m, v
# 初始化参数
alpha = 0.001 # 学习率
beta1 = 0.9 # 一阶矩估计衰减率
beta2 = 0.999 # 二阶矩估计衰减率
epsilon = 1e-8 # 平滑项
t = 0 # 迭代次数
m = np.zeros_like(params) # 梯度一阶矩估计
v = np.zeros_like(params) # 梯度二阶矩估计
# 在每个迭代步骤中使用Adam算法更新参数
while stopping_criteria:
t += 1
# 计算损失函数关于模型参数的梯度
grad = compute_gradient(params)
# 更新参数
param_update, m, v = adam_optimizer(grad, m, v, beta1, beta2, alpha, epsilon, t)
params += param_update
上述代码中,grad表示损失函数对模型参数的梯度,m表示梯度一阶矩估计,v表示梯度二阶矩估计,beta1表示一阶矩估计衰减率,beta2表示二阶矩估计衰减率,alpha表示学习率,epsilon表示平滑项,t表示当前的迭代次数,param表示更新后的模型参数。
需要注意的是,根据具体的优化问题,可能需要根据经验来调整学习率和各个衰减率的取值,以获得更好的优化性能。
08. LBFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)
8.1 什么是 LBFGS?
LBFGS是一种拟牛顿法的变种,它使用有限内存来近似计算海森矩阵的逆。LBFGS方法在逻辑回归中通常用于处理大规模数据集。
8.2 LBFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)的具体步骤和算法公式?
LBFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)是一种常用的无约束优化算法,包含近似Hessian矩阵的求解过程。下面是LBFGS的具体步骤和算法公式:
步骤:
-
初始化参数:选择初始参数 x 0 x_0 x0、初始Hessian估计 H 0 H_0 H0、初始步长 α 0 \alpha_0 α0,设定迭代次数上限等。
-
进入迭代循环:
-
计算梯度:计算当前参数点处的梯度 g k = ∇ f ( x k ) g_k = \nabla f(x_k) gk=∇f(xk)。
-
更新搜索方向:根据BFGS公式更新搜索方向 d k = − H k ⋅ g k d_k = -H_k \cdot g_k dk=−Hk⋅gk。
-
线搜索:在搜索方向上寻找合适的步长 α k \alpha_k αk,满足强Wolfe条件或Armijo条件。
-
更新参数和梯度差:计算参数的更新量 δ x k = α k ⋅ d k \delta x_k = \alpha_k \cdot d_k δxk=αk⋅dk,更新参数 x k + 1 = x k + δ x k x_{k+1} = x_k + \delta x_k xk+1=xk+δxk。
-
计算梯度差:计算参数的梯度差 δ g k = ∇ f ( x k + 1 ) − ∇ f ( x k ) \delta g_k = \nabla f(x_{k+1}) - \nabla f(x_k) δgk=∇f(xk+1)−∇f(xk)。
-
更新Hessian估计:根据LBFGS公式更新Hessian估计 H k + 1 = H k + δ x k δ x k ⊤ δ x k ⊤ δ g k − H k δ g k δ g k ⊤ H k δ g k ⊤ H k δ g k H_{k+1} = H_k + \frac{\delta x_k \delta x_k^\top}{\delta x_k^\top \delta g_k} - \frac{H_k \delta g_k \delta g_k^\top H_k}{\delta g_k^\top H_k \delta g_k} Hk+1=Hk+δxk⊤δgkδxkδxk⊤−δgk⊤HkδgkHkδgkδgk⊤Hk。
-
如果满足终止准则(如梯度收敛),则停止迭代。否则,返回第二步。
-
算法公式:

LBFGS算法通过维护Hessian矩阵的近似来实现无约束优化的迭代过程,并利用近似Hessian矩阵来计算搜索方向。这种方法在大规模优化问题中非常高效,因为它不需要显式地存储和计算完整的Hessian矩阵。同时,LBFGS算法还具有全局收敛性和几何收敛速度等优点。
8.3 LBFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)的算法公式实现?
LBFGS算法的具体实现依赖于编程语言和库的实现,下面是一份Python实现的参考代码。这里假设优化目标是凸函数,并使用Wolfe准则进行线搜索。
import numpy as np
from scipy.optimize import line_search
def lbfgs(fun, grad, x0, max_iter=500, m=10, eps=1e-5):
# 初始化参数
x = x0
f, g = fun(x), grad(x)
H = np.eye(len(x))
s_list = []
y_list = []
alpha_list = []
g_norm = np.linalg.norm(g)
for k in range(max_iter):
# 终止准则:如果梯度小于阈值,终止迭代
if g_norm < eps:
print(f'LBFGS converges in {k} iterations')
break
# 计算搜索方向
d = -np.linalg.solve(H, g)
# 线搜索
alpha = line_search(fun, grad, x, d, g, f, c1=1e-4, c2=0.9)
alpha_list.append(alpha[0])
x = x + alpha[0] * d
# 计算参数和梯度差
f_new, g_new = fun(x), grad(x)
s, y = x - s_list[-m], g_new - y_list[-m]
rho = 1 / (y @ s)
s_list.append(x)
y_list.append(g_new)
alpha_list.append(alpha[0])
# 更新Hessian估计
H_s = H @ s.reshape(-1, 1)
H = H - rho * H_s @ y.reshape(1, -1) + rho * (s @ H_s) * np.outer(y, y)
g = g_new
g_norm = np.linalg.norm(g)
# 保持s和y列表长度为m
if len(s_list) > m:
s_list.pop(0)
y_list.pop(0)
return x, f_new
值得注意的是,这份代码使用了以下几个重要的优化技巧:
- 利用线性代数库Numpy中的
np.linalg.solve()函数求解线性方程组,而不是通过矩阵求逆和矩阵乘法的方式计算搜索方向; - 使用Wolfe准则进行线搜索,确保每次搜索都朝着下降的方向;
- 维护s、y和alpha列表的长度为m,避免列表过长导致内存消耗过大。
当然,LBFGS算法的实现还可以进一步优化,比如实现各种不同的线搜索准则、动态调整m等方法来提升求解的速度和精度。
09. Adamax
9.1 什么是 Adamax ?
这是Adam算法的一种变体,它使用L∞范数替代了Adam中的L2范数,在一些具有稀疏梯度的问题上,Adamax的表现比Adam更好。
9.2 Adamax的具体步骤和算法公式?
Adamax是一种用于优化神经网络的自适应学习率算法,它在Adam算法的基础上,将二阶动量指数衰减率 β2替换为无穷范数动量指数衰减率,即使得 v 变为 L2 范数的衰减率 β2 和 L∞ 范数的衰减率 β∞ 之间的最大值。它不仅克服了Adam在高维优化中的性能下降问题,还可以显著提高高维优化的性能。
Adamax算法的具体步骤如下:
- 初始化学习率α、一阶动量指数衰减率β1、β∞和一个很小的数ε来增强数值的稳定性。初始化一阶矩估计 m 和 v。
- 在每个迭代中,计算梯度g,然后使用如下公式更新m和v:
m = β1 * m + (1 - β1) * g
v = max(β∞ * v, abs(g)) - 在更新m后对其进行偏差纠正和清零,并计算出校正后的m和v:
mt = m / (1 - β1^t)
vt = v - 使用Adamax更新参数θ:
θ = θ - (α / (1 - β1^t)) * mt / (vt + ε)
公式中,t是迭代次数,Θ是模型参数。
下面是Adamax算法的数学公式表示:
-
初始化:
m_0 = 0 # 初始化一阶矩估计为0
v_0 = 0 # 初始化v为0
β1 = 0.9 # 一阶动量指数衰减率
β∞ = 0.999 # 无穷范数动量指数衰减率
α = 0.001 # 初始学习率
ε = 10e-8 # 用于数值稳定性,通常设置为很小的值 -
对于 t = 1, 2, …,执行以下更新:
计算梯度:g_t = ▽_θ L(Θ_t)
更新一阶矩估计:m_t = β1 * m_t-1 + (1 - β1) * g_t
更新二阶动量估计:v_t = max(β∞ * v_t-1, |g_t|)
根据偏差校正计算校正后的一阶矩估计:m_hat_t = m_t / (1 - β1^t)
计算更新参数:Θ_t+1 = Θ_t - α / (1 - β1^t) * m_hat_t / (v_t + ε)
Adamax算法与Adam算法非常相似,但将二阶动量 v 替换为无穷范数动量 v∞,并不需要其偏差校正。公式中,|g|表示给定梯度g的所有元素的绝对值的向量。
9.3 Nadam的算法公式实现?
以下是使用Python实现Adamax算法的代码示例:
import numpy as np
def adamax_optimizer(grad, m, v, beta1, beta_inf, alpha, epsilon, t):
# 更新梯度一阶矩估计
m = beta1 * m + (1 - beta1) * grad
# 更新梯度二阶动量指数
v = np.maximum(beta_inf * v, np.abs(grad))
# 偏差校正后的一阶矩估计
m_hat = m / (1 - beta1**t)
# 更新参数
param = - alpha * m_hat / (v + epsilon)
return param, m, v
# 初始化参数
alpha = 0.001 # 学习率
beta1 = 0.9 # 一阶动量指数衰减率
beta_inf = 0.999 # 无穷范数动量指数衰减率
epsilon = 1e-8 # 平滑项
t = 0 # 迭代次数
m = np.zeros_like(params) # 梯度一阶矩估计
v = np.zeros_like(params) # 无穷范数动量指数
# 在每个迭代步骤中使用Adamax算法更新参数
while stopping_criteria:
t += 1
# 计算损失函数关于模型参数的梯度
grad = compute_gradient(params)
# 更新参数
param_update, m, v = adamax_optimizer(grad, m, v, beta1, beta_inf, alpha, epsilon, t)
params += param_update
上述代码中,grad表示损失函数对模型参数的梯度,m表示梯度一阶矩估计,v表示无穷范数动量指数,beta1表示一阶动量指数衰减率,beta_inf表示无穷范数动量指数衰减率,alpha表示学习率,epsilon表示平滑项,t表示当前的迭代次数,param表示更新后的模型参数。
需要注意的是,根据具体的优化问题,可能需要根据经验来调整学习率和各个衰减率的取值,以获得更好的优化性能。
10. Nadam
10.1 什么是**Nadam ?
这是一种带无约束方法的Nesterov动量Adam算法,可以非常有效地控制"m"-方向和"v"-方向的耦合,并且通常可以提高Adam的收敛速度。
10.2 Nadam的具体步骤和算法公式?
Nadam是一种结合了Nesterov动量和Adam优化算法特性的优化算法。下面是Nadam的具体步骤和算法公式:
-
初始化参数:
- 学习率 α
- 手动动量参数 β1(建议为0.9)
- 二阶动量指数衰减率 β2(建议为0.999)
- 平滑项 ε(用于数值稳定性,通常设置为很小的值,比如1e-8)
-
初始化变量:
- 梯度的一阶矩估计 m (初始化为0向量)
- 梯度的二阶矩估计 v (初始化为0向量)
- 过去动量方向的指数衰减平均 mt (初始化为0向量)
- 过去二阶动量方向的指数衰减平均 vt (初始化为0向量)
-
在每次迭代中,执行以下步骤:
- 计算梯度 g,根据当前参数计算损失函数的导数
- 更新一阶矩估计:m = β1 * m + (1 - β1) * g
- 更新二阶矩估计:v = β2 * v + (1 - β2) * g²
- 偏差校正:m_hat = m / (1 - β1^t),v_hat = v / (1 - β2^t)
- 计算过去动量方向和过去二阶动量方向的指数加权平均: mt = β1 * mt + (1 - β1) * g vt = β2 * vt + (1 - β2) * g²
- 计算校正项:delta = (1 - β1^t) * mt / ((1 - β1^t) * vt + ε)
- 根据Nesterov动量公式,更新参数: θ = θ - α * (β1 * delta + (1 - β1) * g) / sqrt((1 - β2^t) * v + ε)
其中,t表示当前的迭代次数,θ表示模型参数。
通过结合Nesterov动量和Adam算法的思想,Nadam相对于传统的Adam算法可以更好地控制"m"-方向和"v"-方向的耦合,从而提高收敛速度和优化性能。
10.3 Nadam的算法公式实现?
Nadam算法的具体实现公式如下:
首先,初始化参数:
- 学习率 α
- 手动动量参数 β1(建议为0.9)
- 二阶动量指数衰减率 β2(建议为0.999)
- 平滑项 ε(用于数值稳定性,通常设置为很小的值,比如1e-8)
然后,初始化变量:
- 梯度的一阶矩估计 m (初始化为0向量)
- 梯度的二阶矩估计 v (初始化为0向量)
- 过去动量方向的指数衰减平均 mt (初始化为0向量)
- 过去二阶动量方向的指数衰减平均 vt (初始化为0向量)
在每次迭代中,执行以下步骤:
- 计算梯度 g,根据当前参数计算损失函数的导数
- 更新一阶矩估计:m = β1 * m + (1 - β1) * g
- 更新二阶矩估计:v = β2 * v + (1 - β2) * g²
- 偏差校正:m_hat = m / (1 - β1^t),v_hat = v / (1 - β2^t)
- 计算过去动量方向和过去二阶动量方向的指数加权平均: mt = β1 * mt + (1 - β1) * g vt = β2 * vt + (1 - β2) * g²
- 计算校正项:delta = (1 - β1^t) * mt / sqrt((1 - β2^t) * v + ε)
- 根据Nesterov动量公式,更新参数: θ = θ - α * (β1 * delta + (1 - β1) * g) / (sqrt(v_hat) + ε)
其中,t表示当前的迭代次数,θ表示模型参数。
这些步骤按照顺序执行,直到达到预定的迭代次数或达到其他停止条件。通过这种方式,Nadam算法在优化过程中会自适应地调整学习率和动量,并结合Nesterov动量的思想来加速收敛并获得更好的优化性能。
以下是用Python实现Nadam算法的代码示例:
import numpy as np
def nadam_optimizer(grad, m, v, mt, vt, alpha, beta1, beta2, epsilon, t):
# 更新梯度一阶矩估计
m = beta1 * m + (1 - beta1) * grad
# 更新梯度二阶矩估计
v = beta2 * v + (1 - beta2) * grad**2
# 计算偏差校正后的一阶和二阶矩估计
m_hat = m / (1 - beta1**t)
v_hat = v / (1 - beta2**t)
# 更新过去动量方向和过去二阶动量方向的指数加权平均
mt = beta1 * mt + (1 - beta1) * grad
vt = beta2 * vt + (1 - beta2) * grad**2
# 计算校正项delta
delta = (1 - beta1**t) * mt / (np.sqrt((1 - beta2**t) * v_hat) + epsilon)
# 计算更新后的参数
param = - alpha * (beta1 * delta + (1 - beta1) * grad) / (np.sqrt(v_hat) + epsilon)
return param, m, v, mt, vt
其中,grad表示损失函数对模型参数的梯度,m和v是梯度一阶和二阶矩估计,mt和vt是过去动量方向和过去二阶动量方向的指数加权平均,alpha是学习率,beta1和beta2是手动动量参数和二阶动量指数衰减率,epsilon是平滑项,t表示当前的迭代次数,param表示更新后的模型参数。这个函数将计算和返回Nadam算法中的参数更新公式。
使用上述代码源自的Nadam函数,只需要首先初始化所需的变量,然后按照迭代次数循环调用Nadam函数即可。
# 初始化参数
alpha = 0.001
beta1 = 0.9
beta2 = 0.999
epsilon = 1e-8
t = 0
m = np.zeros_like(params)
v = np.zeros_like(params)
mt = np.zeros_like(params)
vt = np.zeros_like(params)
# 在每个迭代步骤中使用Nadam算法更新参数
while stopping_criteria:
t += 1
# 计算损失函数关于模型参数的梯度
grad = compute_gradient(params)
# 更新参数
param_update, m, v, mt, vt = nadam_optimizer(grad, m, v, mt, vt, alpha, beta1, beta2, epsilon, t)
params += param_update
在使用Nadam的神经网络优化过程中,我们要根据网络的具体情况来具体设置这些参数的值,以充分发挥Nadam算法的特性。
