百度 STI2 赛题二-基于向量交集的 TopK 搜索 优化学习笔记
百度 STI2 赛题二-基于向量交集的 TopK 搜索 优化学习笔记
- 注: 本文主要是对参赛冠军团队"晨曦"的 xiatwhu/baidu_topk 代码的学习整理, 下文中的"代码作者"即指的该仓库的作者.
赛题信息
给定850万条规模的数据文件,每条数据是最大128维度的整型id向量 (称为doc),id取值范围是0-50000,给定一个最大128维的整型id向量(称为query),求query与doc全集内各数据的交集个数topk(k=100)
- 赛题主页: 第2届·百度搜索创新大赛——基于向量交集的TopK搜索_飞桨大赛-飞桨AI Studio星河社区
- 赛题 Baseline 及数据集: 第2届·百度搜索创新大赛——基于向量交集的TopK搜索数据集_数据集-飞桨AI Studio星河社区
优化实现
Version 0: Baseline
topk_v0_base.cu 为赛题的 Baseline 实现.
该实现整体思路比较简单, 首先是主机端内存分配等预处理, 然后在 GPU 上进行求交集, 最后在主机端根据求交集的分数降序排序得到最终结果.
这个 Baseline 主要值得一提的是其 docs 的 swizzle 操作以及 kernel 中的向量化读取.
uint16_t *h_docs = new uint16_t[MAX_DOC_SIZE * n_docs];
memset(h_docs, 0, sizeof(uint16_t) * MAX_DOC_SIZE * n_docs);
std::vector<int> h_doc_lens_vec(n_docs);
auto group_sz = sizeof(group_t) / sizeof(uint16_t);
auto layer_0_stride = n_docs * group_sz;
auto layer_1_stride = group_sz;
for (int i = 0; i < docs.size(); i++) {
auto layer_1_offset = i;
auto layer_1_offset_val = layer_1_offset * layer_1_stride;
for (int j = 0; j < docs[i].size(); j++) {
auto layer_0_offset = j / group_sz;
auto layer_2_offset = j % group_sz;
auto final_offset = layer_0_offset * layer_0_stride + layer_1_offset_val + layer_2_offset;
h_docs[final_offset] = docs[i][j];
}
h_doc_lens_vec[i] = docs[i].size();
}
该部分代码是将最长 128 的每个 doc 按照 sizeof(group_t) / sizeof(uint16_t)的数目(为 8)进行了交错存储, 具体来说就是先连续存储所有 docs 的元素 0~7 , 再连续存储元素 8~15, 以此类推 (参考图片). 这样做的目的是结合后续 kernel 的向量化读取, 使得每个线程读取的 docs 数据在显存上是连续的.
register group_t loaded = ((group_t *)docs)[i * n_docs + doc_id]; // tid
register uint16_t *doc_segment = (uint16_t*)(&loaded);
在求向量交集的 kernel docQueryScoringCoalescedMemoryAccessSampleKernel() 中使用了向量化读取, 每个线程一次读取 group_t 大小(128 比特)的数据加载到寄存器中, 在逐个与 query 匹配. 一方面对应了前面 swizzle 操作, 使得线程访存连续, 另一方面向量化读取到寄存器中减少了对全局内存的读取, 利用性能提升.
通过 Nsight System 对 Baseline 进行检测, 如下图所示, 比较突出的问题有两点, 一是整个程序是单线程串行处理, CPU 整体利用率都很低, cudaMalloc 与 cudaMemcpy 中间的 docs memset 和 swizzle 操作占据了很大一部分时间; 二是 GPU 执行时也是完全串行的, 计算操作和内存操作没有 overlap, 而且 GPU 也没有重复利用.
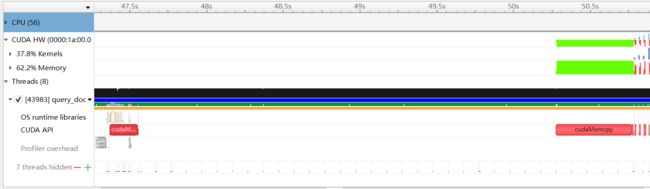
![]()
| 实现版本 | 性能(ms) | 加速比 |
|---|---|---|
| v0: baseline | 63540 |
- 注: 性能测试是均为笔者在 NVIDIA V100 上对比赛提供的 docs 数据集和随机生成的 2000 条 query 的测试结果. 实际比赛是在 A100 上测试, 且测试数据集比赛未予提供.
Version 1: 多线程多流并行
结合 Baseline 检测出来的问题, Version 1 topk_v1_multi_threads.cu 主要是利用了多线程以及多 CUDA 流进行并行处理.
docs 有数百万条数据, 其预处理部分实际上完全可以由多个线程并行处理. 而 query 在实际测试时也有上千条, 每个 query 计算结果的过程也是相互独立的, 也可以在 CPU 和 GPU 上并行, 从而提高 CPU 和 GPU 的利用率.
代码作者在 thread_pool.h 文件中实现了一个简单的线程池, 用于多线程时线程的回收利用.
在主函数 doc_query_scoring_gpu_function(), 代码作者将整个计算过程主要分为了 MemsetTask(h_docs初始化 0)、HostCopyTask(h_docs swizzle 操作) 以及 TopkTask(向量求交集+TopK 排序) 三个任务, 由线程池中 num_threads 个子线程分别处理, 主线程负责等待.
对于前两个任务主要是主机端对 docs 的预处理, 每个子线程负责一部分 docs 的预处理; 第三个任务是对每个 query 的向量求交集和 TopK 计算, 每个子线程还绑定一个 CUDA 流, 这样可以在 GPU 端进行并行执行 kernel, 每个子线程和 CUDA 流负责一部分 query 的求交集 TopK 计算. 此外, 代码对于一些显存操作使用了 cudaMallocAsync(), cudaMemcpyAsync() 等异步函数, 提高了 GPU 上的数据传输并行性.
值得一提的是, 代码作者使用 cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking) 创建了非阻塞的 CUDA 流, 相比于默认由 cudaStreamCreate(&stream) 创建的 CUDA 流而言, 前者的创建的流可以与 CUDA 默认的 0 号流并行, 后者创建的流是会和 0 号流串行. 但实际上在该实现中, 默认的 0 号流并不执行计算, 所以此处二种方式并没有太大区别.
通过 Nsight System 对 Version 1 进行检测, 如下图所示, 可以看到, 主机端对 docs 的预处理从 Baseline 的约 3s 的时间通过多线程降到了 0.6s 左右; 而通过多 CUDA 流, 计算和内存操作也有了 overlap, GPU 空闲的时间间隔也明显变小, GPU 的利用率也明显提升.
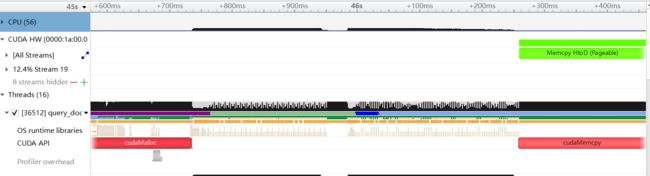

| 实现版本 | 性能(ms) | 加速比 |
|---|---|---|
| v0: baseline | 63540 | |
| v1: multi_threads | 23530 | 2.70 |
Version 2: bitset 求向量交集个数
在原 kernel 中, 使用的是基于双指针的向量求交集方法, 如下所示. 这样做的很明显的一个问题是, GPU 不同线程所处理的 doc 各不相同, 因此其双指针的移动部分彼此不同, 很容易导致 warp divergence, 效率很差.
while (query_idx < query_len && query_on_shm[query_idx] < doc_segment[j]) {
++query_idx;
}
if (query_idx < query_len) {
tmp_score += (query_on_shm[query_idx] == doc_segment[j]);
}
由于 doc 和 query 中数据的范围是 0~50000, 相对而言不是一个特别大的数字, 在 Version 2 topk_v2_bitset.cu 中便使用 bitset 的方式来求交集, 即将 query 的向量数组转换为 bitset 存储, 这样对于 doc 的每个元素, 可以 1 次确定是否在 query 中.
(在实际分析时, 可能还会想到使用 doc 对 query 的二分搜索等方法, 但比较而言, 二分等方法 warp divergence 和 bank conflict 问题都更严重, bitset 的方法性能相对最好.)
void __global__ docQueryScoringCoalescedMemoryAccessSampleKernel(
const uint16_t *docs,
const int *doc_lens,
const size_t n_docs,
uint32_t *query, // bitmap存储
const uint16_t max_query_token, // query中最大数字
const int query_len,
float *scores) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int threadid = threadIdx.x;
__shared__ uint32_t query_mask[query_mask_size];
#pragma unroll
for (int l = threadid; l < query_mask_size; l += N_THREADS_IN_ONE_BLOCK) {
// 加载全局内存数据 与直接加载相比,__ldg()在读取频繁只读数据时会稍快
query_mask[l] = __ldg(query + l);
}
__syncthreads();
// 去掉了 for doc_id 循环,因为根据grid的计算,实际上只会循环1次
if (tid >= n_docs) {
return;
}
int doc_id = tid;
int doc_len = doc_lens[doc_id];
int loop = (doc_len + 7) / 8; // 根据doc长度决定外层循环次数
uint16_t tmp_score = 0;
for (int i = 0; i < loop; ++i) {
group_t loaded = ((group_t*)docs)[i * n_docs + doc_id];
uint16_t* token = (uint16_t*)(&loaded); // i.e. doc_segment
#pragma unroll
for (auto j = 0; j < 8; ++j) { // sizeof(group_t)/sizeof(uint16_t)
uint16_t tindex = token[j] >> 5;
uint16_t tpos = token[j] & 31;
// 使用bitset求交集
tmp_score += (query_mask[tindex] >> tpos) & 0x01;
}
// 提前退出
if (token[7] >= max_query_token) {
break;
}
}
scores[doc_id] = 1.f * tmp_score / max(query_len, doc_len);
}
代码作者的 kernel 实现如上所示.
除了使用 bitset 的代码 tmp_score += (query_mask[tindex] >> tpos) & 0x01; 外; 代码作者对循环逻辑进行了简化, 先前的 kernel 在求交集时会对内外两层循环都会进行提取退出的判断. 而这里, 内存循环不处理 break 逻辑; 外层循环一方面通过 doc 长度计算的 loop 决定循环次数, 一方面通过 token[7] 与 query 中元素的最大值 max_query_token 比较来提前退出循环. 相比于原实现, 这样可以有效减少 warp divergence.
此外, 还有一个值得注意的地方是, 对于 query 从全局内存加载到共享内存, 这里使用了 __ldg() 函数, 参考 CUDA C 编程指南, 该函数同样是对全局内存进行读取, 但是针对只读数据, 且会将数据缓存到"统一 L1/纹理缓存", 从而提高读取性能.
| 实现版本 | 性能(ms) | 加速比 |
|---|---|---|
| v0: baseline | 63540 | |
| v1: multi_threads | 23530 | 2.70 |
| v2: bitset | 22256 | 2.85 |
Version 3: 优化 TopK 计算
对于先前版本的实现, kernel 求出每个 doc 与 query 向量交集的分数之后, 使用的是 std::partial_sort() 对 docs 的分数进行降序排序, 得到最终的 TopK 个结果. 而这个排序的数据量为 docs 的数量, 即上百万个, 容易想到 GPU 版本排序性能应该更好.
在实际分析时, 容易想到 thrust::stable_sort_by_key(), cub::DeviceRadixSort::SortPairsDescending() 等 GPU 排序函数 (GPU 上没有部分排序函数), 以及 Pytorch 库中还有一个 torch::topk() 函数.
thrust::stable_sort_by_key() 排序本身就是通过底层调用 cub::DeviceRadixSort::SortPairsDescending() 实现的, 而且内部会自动分配所需的临时显存; 但由于有多个 query 要多次调用排序, 因此这个显存分配实际上只需要 1 次就够了, 因此可以通过手动调用 cub::DeviceRadixSort::SortPairsDescending() 进行优化. 而根据代码作者 PPT 中的测试 可以看到, torch::topk() 函数的性能是最好的.
(注: 有关 GPU 上的 TopK 问题, 可以查阅相关论文, 还有其他的一些性能更高的算法. 比如, 笔者在请教参赛的 “TensorRT_Tutorial” 团队时了解到的 anilshanbhag/gpu-topk ZhangJingrong/gpu_topK_benchmark 等一些开源的 TopK 高效算法.)
最终在 Version 3 topk_v3_faster_topk.cu 中, 代码作者使用了 torch::topk() 函数进行 GPU 端的 TopK 计算, 在代码中, 头文件 fast_topk.cuh 即为 Pytorch 的 TopK 源码的拷贝, 代码作者根据赛题实际情况进行了一点简化.
// 调用torch::topk求TopK
launch_gather_topk_kernel(
d_scores, d_topk, (int8_t*)d_temp_storage, TOPK, 1, n_docs, stream);
std::vector<Pair> h_topk(TOPK);
// cudaDeviceSynchronize();
cudaMemcpyAsync(h_topk.data(), d_topk, sizeof(Pair) * TOPK, cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
// torch::topk返回的结果不保证顺序,因此需要排序
std::sort(h_topk.begin(), h_topk.end(),
[](const Pair& a, const Pair& b) {
if (a.score != b.score) {
return a.score > b.score;
}
return a.index < b.index;
});
std::vector<int> s_ans(TOPK);
for (int k = 0; k < TOPK; ++k) {
s_ans[k] = h_topk[k].index;
}
indices[index] = std::move(s_ans);
由于 torch::topk() 返回的 TopK 个结果是无序的, 因此这里代码作者又使用 std::sort() 对 TopK 个结果进行排序, TopK 此时仅 100 个, 因此 CPU 的排序是最佳选择.
此外, 代码作者将原本 scores[doc_id] = tmp_score / max(query_len, doc_lens[doc_id]) 计算得到的 float 类型的交集分数通过 scores[doc_id] = static_cast 转换为了 int16_t 类型. 这样做的好处有两点: 一是在保证精度的同时压缩数据大小从 4 字节到 2 字节, 使得求交集 kernel 写显存的数据量减半, 能提高 kernel 性能; 二是, torch::topk() 函数处理 int16_t 比 float 类型的性能更好, 因此可以提高后续 TopK 的计算速度.
| 实现版本 | 性能(ms) | 加速比 |
|---|---|---|
| v0: baseline | 63540 | |
| v1: multi_threads | 23530 | 2.70 |
| v2: bitset | 22256 | 2.85 |
| v3: faster_topk | 4417 | 14.39 |
可以看到, 结合 GPU 上的 TopK 计算, 整体性能提升了很多.
Version 4: batch 计算多个 query
由于需要对多个 query 与 docs 求向量交集的 TopK. 容易想到, 可以将多个 query 组成 batch, 批量求交集.
Version 4 topk_v4_batch.cu 的代码中, 作者定义了 query 的 batch 大小(max_batch 变量)为 4. (一个使用 bitset 的 query 大小 7KB 左右, 结合共享内存每线程块 48KB 设定.)
对于向量求交集的 kernel docQueryScoringCoalescedMemoryAccessSampleKernel(), 代码作者将 query 的 batch 大小设置为模板参数 N, 并在实际调用时根据当前 batch 的大小 cur_batch 启动不同的 kernel 实例.
这里使用模板参数的原因是将 batch 大小变为编译期的常数而非运行时的变量, 进而提高性能. 因为除最后一批次外, batch 大小都是 4.
constexpr static const int max_batch = 4;
template<int N=4>
#if __CUDA_ARCH__ == 860
__launch_bounds__(N_THREADS_IN_ONE_BLOCK, 3)
#elif __CUDA_ARCH__ == 800
__launch_bounds__(N_THREADS_IN_ONE_BLOCK, 4)
#endif
void __global__ docQueryScoringCoalescedMemoryAccessSampleKernel(
const uint16_t* docs,
const uint16_t* doc_lens,
const size_t n_docs,
const uint32_t* query,
const uint16_t* query_len,
const uint16_t max_query_token,
int16_t *scores) {
// ...
}
// 最后一批次实际的query数可能会<4,将cur_batch化为模板参数来加速
if (cur_batch == 4) {
docQueryScoringCoalescedMemoryAccessSampleKernel<4><<<grid, block, 0, stream>>>(
d_docs, d_doc_lens, n_docs_pad, d_query, d_query_len, max_query_token, d_scores);
CHECK_CUDA(cudaGetLastError());
} else if (cur_batch == 3) {
docQueryScoringCoalescedMemoryAccessSampleKernel<3><<<grid, block, 0, stream>>>(
d_docs, d_doc_lens, n_docs_pad, d_query, d_query_len, max_query_token, d_scores);
CHECK_CUDA(cudaGetLastError());
} else if (cur_batch == 2) {
docQueryScoringCoalescedMemoryAccessSampleKernel<2><<<grid, block, 0, stream>>>(
d_docs, d_doc_lens, n_docs_pad, d_query, d_query_len, max_query_token, d_scores);
CHECK_CUDA(cudaGetLastError());
} else if (cur_batch == 1) {
docQueryScoringCoalescedMemoryAccessSampleKernel<1><<<grid, block, 0, stream>>>(
d_docs, d_doc_lens, n_docs_pad, d_query, d_query_len, max_query_token, d_scores);
CHECK_CUDA(cudaGetLastError());
}
Version 4 除了 batch query 外, 代码作者对数据的预处理部分进行了更进一步的优化.
对于 HostCopyTask 任务中主机端对 docs 的 swizzle 操作, 作者使用了 Intel SSE 2 指令 _mm_loadu_si128() 和 _mm_store_si128(), 分别进行 CPU 上 128 比特粒度的读和写. 这个与 GPU 上的向量化读写是相似的, 一方面能够简化代码, 更重要的是能提高读写速度. 同时, 作者移除了原本的 MemsetTask, 而是对 doc 最后 8 个数据的末尾无效数据填充 0, 从而避免了对整个 h_docs 的初始化置零操作.
for (int i = start; i < end; i++) {
auto layer_1_offset = i;
int doc_len = docs[i].size();
max_len = std::max(doc_len, max_len);
int n = doc_len / 8;
int leftover = doc_len % 8;
uint16_t * ptr = docs[i].data();
int offset = layer_1_offset * layer_1_stride;
for (int j = 0; j < n; ++j) {
// Intel SSE指令(CPU 向量化指令)加速
// 128比特读取
__m128i a = _mm_loadu_si128((__m128i*)(ptr));
// 128比特写入
_mm_store_si128((__m128i*)(h_docs + offset), a);
ptr += 8;
offset += layer_0_stride;
}
if (leftover) {
// 此处补 0 避免了对整个 h_docs 进行置 0 操作
alignas(16) int16_t data[8] = {0, 0, 0, 0, 0, 0, 0, 0};
for (int j = 0; j < leftover; ++j) {
data[j] = ptr[j];
}
__m128i a = _mm_load_si128((__m128i*)(data));
_mm_store_si128((__m128i*)(h_docs + offset), a);
}
}
此外, HostCopyTask 现在也负责异步将处理的部分 h_docs 拷贝到显存中, 与之前主线程完成整个 h_docs 的拷贝相比, 进一步提高了并行性.
// [16, n_docs_pad, 8]
uint16_t* d_docs = ctx.d_docs;
cudaStream_t stream = ctx.thread_contexts[id].stream;
// 并不需要拷贝所有的 16 个 group 的数据, 可以只拷贝有效的数值, 在 kernel 中也只会读取有效的部分数据
int loop = (max_len + 7) / 8;
// 拷贝对应的分块
for (int i = 0; i < loop; ++i) {
CHECK_CUDA(cudaMemcpyAsync(d_docs + i * n_docs_pad * 8 + start * 8,
h_docs + i * n_docs_pad * 8 + start * 8,
(end - start) * 8 * sizeof(uint16_t),
cudaMemcpyHostToDevice, stream));
}
值得一提的是, 这里的 n_docs_pad 是将 docs 的数量 n_docs 进行了 4096 字节对齐, 4096 字节为主机内存页面的大小, 这样使得每个 swizzle 的 h_docs 块相对而言是内存页对齐的, 更利于提高拷贝性能.
Version 8 作者还引入了 Context 类, 其 init() 方法负责所有显存的分配和 h_docs 的内存分配, 其 init_cuda() 方法负责 query 的锁页内存(pinned memory)的分配. 在主函数中, 启动了线程池的 HostCopyTask 任务后, 主线程调用 ctx.init_pinned() 等负责其他耗时的操作, 进一步提高了并行性.
std::vector<Task*> tasks(num_threads, nullptr);
size_t n_docs_per_threads = (n_docs_pad + num_threads - 1) / num_threads;
int offset = 0;
for (int i = 0; i < num_threads; ++i) {
int size = min(n_docs_per_threads, n_docs_pad - offset);
int end = offset + size;
tasks[i] = new HostCopyTask(ctx, i, num_threads, offset, end, n_docs_pad, h_docs, docs);
offset += n_docs_per_threads;
}
pool.run_task(tasks);
ctx.init_pinned(n_docs_pad, num_threads);
// 线程池在处理 d_docs 时, 主线程处理其他耗时的操作
t.stop("pre_init_cuda");
cudaStream_t stream = ctx.stream;
uint16_t* d_docs = ctx.d_docs;
uint16_t* d_doc_lens = ctx.d_doc_lens;
CHECK_CUDA(cudaMemcpyAsync(d_doc_lens, lens.data(), sizeof(uint16_t) * n_docs,
cudaMemcpyHostToDevice, stream));
// 将docs填充的部分长度置0
if (n_docs != n_docs_pad) {
CHECK_CUDA(cudaMemsetAsync(d_doc_lens + n_docs, 0,
(n_docs_pad - n_docs) * sizeof(uint16_t), stream));
}
CHECK_CUDA(cudaStreamSynchronize(stream));
indices.resize(querys.size());
t.stop("pre_memcpy_device");
// 等待线程池完成 docs-> h_docs -> d_docs 的任务
pool.wait();
额外一提, 在 ctx.init() 和 ctx.init_pinned() 函数中, 作者通过预先计算, 仅分别使用 1 次 cudaMalloc() 和 cudaMallocHost() 就完成了相应内存的分配. 因为内存分配函数的开销相对而言比较大, 而且并不像内存拷贝函数一样并发调用能够提高性能, 反而多次调用会影响性能, 最好尽可能减少其调用次数.
此外, 代码作者使用了 align_bytes() 对内存地址进行了 256 字节的对齐. 这里笔者向代码作者进行了请教, 对于一些内存指针而言这不是必要的, 作者这样写主要是避免一些隐性错误, 因为代码中使用了 SSE 指令以及向量交集的 kernel 中的向量化读取, 这些对地址都是有对齐要求的(不过都是 128 字节). 应该养成注意地址内存对齐的习惯!
| 实现版本 | 性能(ms) | 加速比 |
|---|---|---|
| v0: baseline | 63540 | |
| v1: multi_threads | 23530 | 2.70 |
| v2: bitset | 22256 | 2.85 |
| v3: faster_topk | 4417 | 14.39 |
| v4: batch | 1893 | 33.57 |
Version 5: 优化 shared memory 访问
Version 5 topk_v5_shared_memory.cu 主要是对求向量交集 kernel docQueryScoringCoalescedMemoryAccessSampleKernel() 中共享内存中 query 的排布进行了调整. 将 Version 4 中 query 按照 [batch_size, query_bitset_size] 的排布变成了 [query_bitset_size, batch_size] 的排布方式. 在代码作者 PPT 16 页的示意图很直观的显示了两种排布方式的不同.
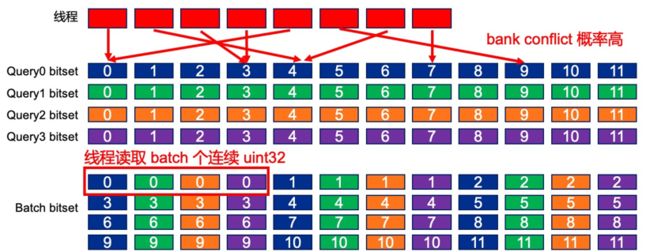
/// @brief 用于query_bitmap合并读取的数据结构
/// @tparam N 合并读取的数据个数
template <int N>
struct PackData {};
template <>
struct PackData<1> {
using dtype = uint32_t;
};
template <>
struct PackData<2> {
using dtype = uint2;
};
template <>
struct PackData<3> {
using dtype = uint3;
};
template <>
struct PackData<4> {
using dtype = uint4;
};
template<int N=4>
#if __CUDA_ARCH__ == 860
__launch_bounds__(N_THREADS_IN_ONE_BLOCK, 3)
#elif __CUDA_ARCH__ == 800
__launch_bounds__(N_THREADS_IN_ONE_BLOCK, 4)
#endif
void __global__ docQueryScoringCoalescedMemoryAccessSampleKernel(
const uint16_t* docs,
const uint16_t* doc_lens,
const size_t n_docs,
const uint32_t* query,
const uint16_t* query_len,
const uint16_t max_query_token,
int16_t *scores) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gridDim.x * blockDim.x;
__shared__ uint32_t query_mask[N * query_mask_size];
int threadid = threadIdx.x;
#pragma unroll
for (int l = threadid; l < N * query_mask_size; l += N_THREADS_IN_ONE_BLOCK) {
query_mask[l] = __ldg(query + l);
}
__syncthreads();
for (int doc_id = tid; doc_id < n_docs; doc_id += stride) {
int doc_len = doc_lens[doc_id];
int loop = (doc_len + 7) / 8;
int tmp_score[N] = {0};
for (int i = 0; i < loop; ++i) {
group_t loaded = ((group_t*)docs)[i * n_docs + doc_id];
uint16_t* token = (uint16_t*)(&loaded);
#pragma unroll
for (auto j = 0; j < 8; ++j) {
uint16_t tindex = token[j] >> 5;
uint16_t tpos = token[j] & 31;
// 合并读取该批次query的bitmap到寄存器
using pack = typename PackData<N>::dtype;
pack mask = ((pack*)(query_mask))[tindex];
uint32_t* mask_ptr = (uint32_t*)(&mask);
#pragma unroll
for (auto k = 0; k < N; ++k) {
tmp_score[k] += (mask_ptr[k] >> tpos) & 0x01;
}
}
if (token[7] >= max_query_token) {
break;
}
}
for (auto i = 0; i < N; ++i) {
scores[i * n_docs + doc_id] = static_cast<int16_t>(
1.f * 128 * 128 * tmp_score[i] / max(query_len[i], doc_len));
}
}
}
在代码层面, 由于不同 query 相同索引的 bitset 排布在了一起, 因此可以在比较时一次性合并读取, 代码作者这里通过定义了 PackData 结构体用来指定合并读取时的数据的大小, 这样就和读取 doc 类似, 合并读取当前 batch 的多个 query 的相同位置的索引数据到线程的寄存器中, 然后再循环展开进行比较.
相比与之前的方式, 正如作者 PPT 17 页所示, 合并读取一方面能够减少读取共享内存的次数, 转为读取寄存器, 从而提高读写效率; 另一方面随着读取次数的减少, 发生 bank conflict 的概率也会下降, 同样利于提高读写效率.
| 实现版本 | 性能(ms) | 加速比 |
|---|---|---|
| v0: baseline | 63540 | |
| v1: multi_threads | 23530 | 2.70 |
| v2: bitset | 22256 | 2.85 |
| v3: faster_topk | 4417 | 14.39 |
| v4: batch | 1893 | 33.57 |
| v5: shared_memory | 1785 | 35.60 |
Version 6: 对 query 排序
Version 6 topk_v6_query_sort.cu 主要是对 query 的顺序进行了优化, 让 query 按照最大的元素(即最后一个元素)进行排序, 这样让一个 batch 中的 query 最大元素大小接近. 向量交集 kernel docQueryScoringCoalescedMemoryAccessSampleKernel() 的循环中, 有以下条件语句进行提前退出, 即当前 doc 的元素值已经比 query 中最大元素 max_query_token 还要大了, 此时后续的元素也就无需进行比较了. 在引入 query batch 后, max_query_token 表示的是当前 batch 中 query 的最大元素中的最大者, 因此若 batch 中的 query 的最大元素差距较大时, 对于最大元素较小的 query, 其会发生很多与 doc 不必要的匹配而不能提前退出. 经过上述说明的 query 排序后, 便可以缓解此问题.
if (token[7] >= max_query_token) {
break;
}
在代码层面上, 作者使用了 query_idx 数组记录排序后的 query 对应的原索引, 在生成 query 的 bitset 时拷贝至显存和最后计算出 TopK 结果后写回结果数组 indices 时均按照 query_idx 中记录的排序后的顺序. 这样, 对于求向量交集和计算 TopK 的 kernel 则无需发生改动.
std::vector<int> query_idx(querys.size());
std::iota(query_idx.begin(), query_idx.end(), 0);
std::sort(query_idx.begin(), query_idx.end(),
[&querys](int a, int b) {
return querys[a].back() < querys[b].back();
});
uint16_t max_query_token = 0;
for (int j = 0; j < cur_batch; ++j) {
// 按照排序后的顺序加载query
auto& query = querys[query_idx[start + j]];
h_query_len[j] = query.size();
for (auto& q : query) {
uint16_t index = q >> 5;
uint16_t postion = q & 31;
h_query[cur_batch * index + j] |= ((1u) << postion);
}
max_query_token = std::max(max_query_token, query.back());
}
CHECK_CUDA(cudaMemcpyAsync(d_query, h_query,
cur_batch * query_mask_size * sizeof(uint32_t),
cudaMemcpyHostToDevice, stream));
// ...
CHECK_CUDA(cudaStreamSynchronize(stream));
for (int j = 0; j < cur_batch; ++j) {
// ...
// 按照排序query对应的原索引记录结果
indices[query_idx[start + j]] = std::move(s_ans);
}
| 实现版本 | 性能(ms) | 加速比 |
|---|---|---|
| v0: baseline | 63540 | |
| v1: multi_threads | 23530 | 2.70 |
| v2: bitset | 22256 | 2.85 |
| v3: faster_topk | 4417 | 14.39 |
| v4: batch | 1893 | 33.57 |
| v5: shared_memory | 1785 | 35.60 |
| v6: query_sort | 1697 | 37.44 |
可以看到, Version 6 相比与 Version 5 有了一定的性能提升, 但值得一提的是, 该优化主要对输入的 query 最大元素相差较大的情况优化比较明显, 因此对于不同的 query 数据集, 可能优化效果有大有小.
Version 7: 使用 __popc() 函数
Version 7 topk_v7_popc.cu 的优化主要在 doc 的每个元素在 query 的 bitset 中匹配元素的方法上.
笔者在此处结合 Nsight Compute 分析, 如下图所示, 在整个求向量交集的 kernel 中, 该操作是最核心也是最为频繁的操作, 且相关指令的 warp 停滞占比页比较明显, 因此从优化思路上讲, 这一部分也是值得考虑优化的.
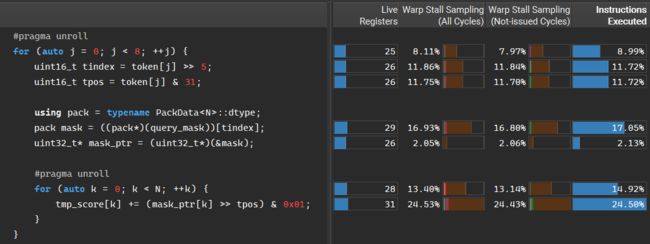
先前的方法如下所示, 是最为直观的一种位运算的方法, 根据 doc 的 token[j] 确定 query bitset 的读取 32 位元素索引 tindex 和对应的比特位 tpos, 在匹配时将 query 的元素 mask_ptr[k] 右移 tpos 位, 让目标比特位落到最低位, 在与 0x01 与运算.
uint16_t tindex = token[j] >> 5;
uint16_t tpos = token[j] & 31;
using pack = typename PackData<N>::dtype;
pack mask = ((pack*)(query_mask))[tindex];
uint32_t* mask_ptr = (uint32_t*)(&mask);
tmp_score[k] += (mask_ptr[k] >> tpos) & 0x01;
在 Version 7, 代码作者利于了 CUDA 库中的 __popc() 函数, 该函数可以统计 32 位整数中, 置一的比特位个数. 因此, 这里通过 tmask 把对 mask_ptr[k] 的右移变为了对 0x1 的左移, 再利用 __popc() 获取目标位的值, 与之前的做法逻辑上是等价的. 但经代码作者测试, 该方法的性能要比前者更好.
uint16_t tindex = token[j] >> 5;
uint16_t tpos = token[j] & 31;
uint32_t tmask = (1u) << tpos;
// ...
tmp_score[k] += __popc(mask_ptr[k] & tmask);
除了使用 __popc() 函数外, 代码作者还尝试了利用 CUDA PTX 指令 bfe.32 的方法. 该指令被封装于函数 getBitfield(), 用于获取 32 位整数指定位置和指定长度的位字段对应的数值. 在匹配时, 可以理解为求 query 对应索引元素 mask_ptr[k] 的 tpos 位开始长度为 1 的位字段的数值大小. 经过代码作者比较, 该方法仍然不如 __popc() 的性能更好.
/// @brief 提取32位数的位字段
/// @param val 32位数
/// @param pos 位字段的起始位置
/// @param len 位字段长度
/// @return 位字段代表的整数
__device__ __forceinline__
uint32_t getBitfield(uint32_t val, int pos, int len) {
uint32_t ret;
asm("bfe.u32 %0, %1, %2, %3;" : "=r"(ret) : "r"(val), "r"(pos), "r"(len));
return ret;
}
tmp_score[k] += getBitfield(mask_ptr[k], tpos, 1);
| 实现版本 | 性能(ms) | 加速比 |
|---|---|---|
| v0: baseline | 63540 | |
| v1: multi_threads | 23530 | 2.70 |
| v2: bitset | 22256 | 2.85 |
| v3: faster_topk | 4417 | 14.39 |
| v4: batch | 1893 | 33.57 |
| v5: shared_memory | 1785 | 35.60 |
| v6: query_sort | 1697 | 37.44 |
| v7: popc | 1650 | 38.51 |
对于 __popc() 函数的优化, 在笔者使用的 V100 上, 性能有一定提升, 具体性能提升效果可能会与实际 GPU 架构有关系.
Version 8: 基于 thresh 的提前退出策略
赛题中, TopK 的大小为 100, 相对于数百万的 docs 数量, 是一个即为小的数字, 因此有一种想法是, 如果我在对部分 docs 匹配后已经得到了 TopK 的结果了, 那么后续的 docs 就没必要再进行匹配了.
在 Version 8 中, 代码作者就是基于类似的想法提出了一种减少对 docs 访问量的提前退出策略, 如 PPT 20 页所述.
具体来讲, 向量交集的 TopK 是按照交集个数对应的分数 s c o r e = n u m _ m a t c h e d / max ( q u e r y _ l e n , d o c _ l e n s [ d o c _ i d ] ) score=num\_matched/\max(query\_len,\ doc\_lens[doc\_id]) score=num_matched/max(query_len, doc_lens[doc_id]) 计算出来的. 如果事先知道结果 TopK 中末尾 doc 对应的分数 t h r e s h thresh thresh, 那么在 query 长度 L L L 一定的情况下, 根据上述公式就可以反推出需要进行匹配的 docs 的最大长度范围(即搜索范围)为 [ L ∗ t h r e s h , L / t h r e s h ] [L*thresh, L/thresh] [L∗thresh,L/thresh] (这里的"最大范围"是指的 { n u m _ m a t c h e d = = d o c _ l e n s [ d o c _ i d ] , d o c _ l e n s [ d o c _ i d ] < = L n u m _ m a t c h e d = = L , d o c _ l e n s [ d o c _ i d ] > L \begin{cases} num\_matched==doc\_lens[doc\_id],\ doc\_lens[doc\_id] <= L\\ num\_matched == L,\ doc\_lens[doc\_id] > L \end{cases} {num_matched==doc_lens[doc_id], doc_lens[doc_id]<=Lnum_matched==L, doc_lens[doc_id]>L 即全匹配的情况下). 例如, 一条长度为 20 的 query , TopK 中最低分为 0.5, 实际只需要计算长度在 [10,40] 之间的 docs. 在这里, TopK 中末尾 doc 对应的分数(即最低分)被称之为阈值 thresh.
算法逻辑如代码作者 PPT 21 页所述, 对应 Version 8 topk_v8_thresh.cu 中 search_topk() 函数 query 处理后的部分.
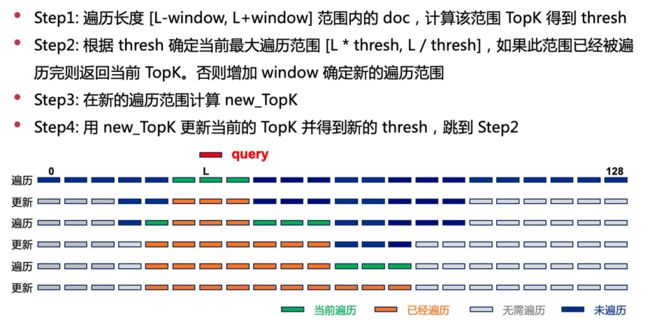
在代码层面, 预处理时, 会统计全部 docs 的长度 doc_stat, 并转换为偏移量数组 doc_stat_offset, 用于确定后续搜索的 docs. (注: 这里默认了数据集 docs.txt 中 docs 按照长度升序排列的.)
// 统计docs的长度分布
int doc_stat[129] = {0};
for (int i = 0; i < lens.size(); ++i) {
doc_stat[lens[i]]++;
}
// docs长度偏移
std::vector<int> doc_stat_offset(130, 0);
for (int i = 0; i < 129; ++i) {
doc_stat_offset[i + 1] = doc_stat_offset[i] + doc_stat[i];
}
在实际的搜索阶段, 作者还设置了一个窗口 window 的概念, 先从 query 长度 L 的前后 [L-window, L+window] 开始第一次搜索. 选择以 query 长度为中心开始搜索的原因也很简单, 因为按照分数的计算公式, 在匹配个数相同的情况下, 与 query 长度约接近, 得到的分数更高. 第一次搜索对应求向量交集的 kernel docFirstKernel(), 它与先前 docQueryScoringCoalescedMemoryAccessSampleKernel() 区别仅在只计算 doc_offset 开始 doc_num 个 doc 的交集分数.
完成第一次搜索(求向量交集+TopK计算)后, 这时便得到了 thresh.
后续迭代则是从第一次迭代的范围开始, 向前后两个方向扩大搜索范围进行搜索. 在后续搜索时, 窗口大小 window 会指数增大, 结合窗口大小 window 和 thresh 计算的范围最终确定下一次迭代的搜索范围. 后续搜索对应求交集 kernel docIterKernel(), 它是对 docs 中前后两段进行求交集计算. 在后续每次迭代时, 都会把当前结果与之前记录的 TopK 结果进行合并, 作为当前的 TopK 结果.
最终, 在达到搜索范围后, 返回最后合并的 TopK 结果.
在求向量交集的 kernel docIterKernel() 中, 代码作者结合 thresh 做了一点优化. 即在已知先前迭代 thresh 时, 计算出一个 tmp_score_thresh, 表示达到先前 thresh 该 doc 至少要与 query 匹配的元素个数. 循环判断时, 在当前匹配个数的前提下, 即使 doc 的后续全部元素都匹配也小于 tmp_score_thresh 时, 便可以提前退出循环.
// 当前doc匹配个数下限阈值 即要达到thresh该doc至少要与query匹配的元素个数
uint32_t tmp_score_thresh = static_cast<uint32_t>(max(doc_len, query_len) * thresh);
// ...
if (token[7] > max_query_token
// 当前匹配个数的前提下,即使后续全部元素都匹配也小于当前doc要满足的匹配下限时,退出计算
|| tmp_score + (doc_len - (i + 1) * 8) < tmp_score_thresh) {
break;
}
Version 8 代码作者是实现了一个单 query 的版本, 即没有使用 Version 4 中的 query batch 优化, 在 PPT 22 页 作者是对比了单 query 下, 使用 thresh 算法前(batch1)后(thresh)的性能, 直方图表示的是两种方法对于随机生成的 2000 条 query 的处理时间排序.
总体而言, Version 8 的提前退出策略的优化效果是与数据集中的 query 和 docs 的特点是相关的. 当 query 比较短或者得到的 thresh 比较小时, 确定的搜索范围 [L-window, L+window] 就较小, 从而能够减少 docs 的计算量, 从而提高整体性能. 反之, 可能最后 thresh 算法的搜索范围仍然是全部的 docs , 并不会减少计算量. 比如, query 长度是 64, thresh 是 0.5, 那实际需要遍历的范围是 [32, 128],基本相当于遍历全部的 docs 了.
| 实现版本 | 性能(ms) | 加速比 |
|---|---|---|
| v0: baseline | 63540 | |
| v1: multi_threads | 23530 | 2.70 |
| v2: bitset | 22256 | 2.85 |
| v3: faster_topk | 4417 | 14.39 |
| v4: batch | 1893 | 33.57 |
| v5: shared_memory | 1785 | 35.60 |
| v6: query_sort | 1697 | 37.44 |
| v7: popc | 1650 | 38.51 |
| v8: thresh | 3724 | 17.06 |
Version 8 的比较对象应该是 Version 3 版本, 可以看到性能上有一点提高.
Version 9: 结合 thresh 与 batch 方案
Version 9 topk_v9_batch_thresh.cu 即将 Version 8 的 thresh 策略与先前的 batch query 结合.
在实现上, 每个 batch 的搜索范围是 batch 内每个 query 的搜索范围的并集, 即最大范围, 从而能包含每个 query 的搜索范围.
与 Version 8 通过一个 while 循环利用 window 和 thresh 两个条件来确定后续搜索范围不同, Version 9 去掉了 while 循环, 而后续直接利用 thresh 确定的 [L-window, L+window] 搜索范围一次性完成了搜索. 这里笔者与代码作者请教, 这么做的原因是为了简化代码.
| 实现版本 | 性能(ms) | 加速比 |
|---|---|---|
| v0: baseline | 63540 | |
| v1: multi_threads | 23530 | 2.70 |
| v2: bitset | 22256 | 2.85 |
| v3: faster_topk | 4417 | 14.39 |
| v4: batch | 1893 | 33.57 |
| v5: shared_memory | 1785 | 35.60 |
| v6: query_sort | 1697 | 37.44 |
| v7: popc | 1650 | 38.51 |
| v8: thresh | 3724 | 17.06 |
| v9: batch_thresh | 1731 | 36.71 |
可以看到, Version 9 的性能相对于 Version 7 并没有明显提升, 但在代码作者 PPT 24 页中记录是由一定性能提升的. 正如 Version 8 结尾所说, 该算法实际情况下可能与数据集特征有关, 比如这里可能就是笔者与代码作者的 query 数据集有不同.
此外, 根据笔者与代码作者交流得知, 最后他的参赛最高分可能是 Version 7 版本下得到的, 实际测试集中可能较长或者较短的 query 很少.
Version 10: cuda init
Version 10 与 Version 7 的实现基本一致, 两个版本的区别主要是在中 Context 的方法中.
Version 10 是使用 ctx.init() 和 ctx.init_cuda() 进行初始化. 其中 init() 方法完成 h_docs 的主机端内存分配; init_cuda() 方法完成其他内存分配操作, 包括全部的显存以及 pinned 内存.
而 Version 7 是使用 ctx.init() 和 ctx.init_pinned() 进行初始化. 其中 init() 方法完成全部的显存分配以及 h_docs 的主机端内存分配; init_pinned() 方法完成全部的 pinned 内存分配.
二者的主要区别就是分配显存的时机, Version 7 的显存是在主线程中独立分配的, 此时线程池中的子线程并没有工作; 而 Version 10 将显存分配是在子线程开始 HostCopyTask 任务后, 主线程开始分配的, 这样子线程处理 docs 的 swizzle 操作能与主线程的显存分配有一定的 overlap. 但这样也引入了 ctx.cuda_inited 原子变量, 用于主线程显存分配完成后通知子线程进行 docs 数据拷贝.
| 实现版本 | 性能(ms) | 加速比 |
|---|---|---|
| v0: baseline | 63540 | |
| v1: multi_threads | 23530 | 2.70 |
| v2: bitset | 22256 | 2.85 |
| v3: faster_topk | 4417 | 14.39 |
| v4: batch | 1893 | 33.57 |
| v5: shared_memory | 1785 | 35.60 |
| v6: query_sort | 1697 | 37.44 |
| v7: popc | 1650 | 38.51 |
| v8: thresh | 3724 | 17.06 |
| v9: batch_thresh | 1731 | 36.71 |
| v10: cuda_init | 1825 | 34.82 |
笔者这里实际测试发现, Version 10 的性能并没有优于 Version 7. 笔者猜测可能是引入的 ctx.cuda_inited 原子变量对性能有一定的副作用.
总结和感受
以上是笔者对参赛冠军团队"晨曦"的 xiatwhu/baidu_topk 代码的学习整理. 此外, 笔者 fork 了该仓库, 并在 note 分支中增加了对代码的一些注释, 以及对不同版本代码的编译运行脚本.
比赛笔者自己也参加了, 折腾了半天最后并没有进入复赛. 在看了别人的实现和优化后, 其实觉得这些优化也没有那么深奥, 其实都是比较好理解的一些方法, 无奈自己当时对赛题理解不透彻, 功夫都用错了方向.
通过学习我也感受了一些方面:
首先很重要的一点是, 赛题是一个完整的程序执行过程, 不单单是一个对 GPU kernel 的优化, 笔者花了很长时间在考虑 kernel 的优化, 比如求交集时 query bitset 的 warp stall 问题如何解决之类的. 但实际上, 对于最初的程序而言, 预处理开销和 GPU 利用率低才是影响性能很关键的地方, 因此 Version 1 多线程和多流等并行的预处理操作就能很大程度上提升程序性能, 甚至可能就进复赛了. 这样的系统方面的优化同样不能忽视.
当然, 在 GPU kernel 优化上, 需要注意的就是简化程序逻辑, 对比 Baseline 和代码作者的 kernel 就能发现, 作者优化了最外层的 for doc_id 的 GPU 网格跨度的循环(这个是需要结合输入的 grid_size 和 block_size, 不具有普适性); 很重要的是简化了循环退出的逻辑, 从原本两层循环的逐元素粒度, 简化为了外层循环的 8 元素粒度, 这对于 GPU 线程减少 warp divergence 是很有必要的. 而对于求交集的方法, query bitset 基本上就是最合适的方法了, 最后 warp stall 的问题仍然存在, 回过头来再看, 像这种情况应该转而去考虑别的方面的优化.
最后, 作为第一次参加此类型的比赛, 就算一次宝贵经验吧, 希望自己今后继续加油吧!
参考资料
- xiatwhu/baidu_topk - GitHub