国际卫生信息互操作标准发展简史
原文在这里
卫生信息和其它信息化一样,经历了数码化、数字化到当今的数字化转型,卫生信息互操作一直伴随左右。
数码化(digitization):国内90年代开始,HIS全面铺开,卫生信息进入数码化时代。数码化初期业务集中在HIS上,互操作需求不高,点对点接口可以满足绝大多数需求。
数字化(digitalization):在2000年之后,各种专科系统、尤其是电子病历的诞生,医保和新农合的实施,要求卫生信息共享交换,以提高流程自动化水平。互操作需求爆发,2007年集成平台开始进入市场,卫生信息化进入数字化时代。
数字化转型(digital transformation):2014年,国内正式进入移动互联网时代;次年《全国医疗卫生服务体系规划纲要(2015—2020年)》发布,卫生信息化的服务对象(服务于医护技到服务于患者)和业务形态(临床管理到患者服务)都发生了翻天覆地的变化,开始步入数字化转型的时代。它对互操作提出了更高的要求 - 利用互操作,增强全员参与,为卫生服务创造新价值、发展新业务,推动医疗机构持续数字化转型。
可以说,卫生信息互操作在整个的卫生信息产业中愈发重要。
国际卫生信息互操作发展了30年,国内也发展了20年,但卫生信息互操作依然是一个挑战。
知史而明鉴,识古而知今。我们看看国际卫生信息互操作发展的历程,对未来的卫生信息互操作有什么借鉴。
卫生信息互操作标准的要素
HIMSS把信息互操作/集成定为4个不同的级别:
- 基础级别,仅仅打通了系统间进行数据通讯的通道
- 结构级别,在基础级别上,定义了数据交换的格式和语法
- 语义级别,建立在行业通用的基础模型和数据编码上,使用标准化的行业语义来定义数据元素,使用标准的值集。因此语义级别的互操作是全行业可以理解并有确定行业意义的互操作级别。或者说语义级别的互操做才是基于标准的互操作
- 组织级别,通常都是由国家、行业协和和行业标准开发组织开发的。它加入了政策、社区、法律等方面的考虑,分析了通用的业务流程和工作流,在此基础上设定了参与互操作各方的角色、权限,服务和知情同意策略等。我们的互联互通,就是组织级别的互操作
目前的卫生信息互操作项目多数停留在结构级别。只有达到语义级别的信息互操作/集成,才是标准化的信息互操作/集成,才能降低实施成本和提高实施效率。
做到语义级别的互操作标准并不容易,首先是消除语义歧义、其次行业普遍认可、再次是要覆盖行业用例并具有适应行业不断变化需求的弹性。

图片来源:EuroVulcan Conference 2023
先说消除语义歧义。要在信息交换时消除语义歧义,需要在语言、语法、词义、句法等多方面努力,而且涉及到数据的颗粒度。尤其在医疗行业,完整、消除歧义才能保障卫生信息准确和医疗行为安全!
HIMSS认为要消除语义歧义、达到语义级互操作性,需要基于五位一体的语义标准,包含:

- 词汇/术语标准:依靠结构化的词汇、术语、代码集和分类系统来表示健康概念。例如ICD-10、SNOMED-CT、LOINC、 RxNorm是行业里典型的词汇和术语标准。
- 内容标准:描述信息交换中,数据内容的结构和组织。而HL7 CDA、HL7 V2、C-CDA都是行业内容标准。
- 传输标准:定义了计算机系统、文档架构、临床模板、用户界面和患者数据链接之间交换的消息格式和传输方式。传输方式确定了卫生信息交换的“推”和“拉”方式。DICOM、IHE等都是传输标准。
- 隐私和安全标准:是确定谁、何时、出于何种目的、使用哪种个人健康信息的权利,以及如何护健康信息的机密性、可用性和完整性的标准。美国的HIPAA和欧洲的GDPR都是关于隐私和安全的标准。
- 标识符标准: 是用来唯一标识患者、机构、医护技、设备等实体的方法。例如咱们互联互通里用到的OID和美国的护士标识NCSBN ID …
并非消除了语义歧义的标准就能被广泛接受和认可,需要行业标准化组织的推动,实现厂商中立,毕竟互相竞争的厂商很难接受对方的企业标准。回顾一下行业里流行的标准,无论是术语标准、还是消息和文档标准,都是行业里标准化组织发布的,其中最有名的就是HL7。

从这个行业标准发展史可以看到,毫无例外的,标准先从术语标准开始,例如ICD、SNOMED,历史都非常久远。而我们常用的HL7 V2有30多年历史了,CDA和V3也20年左右了。从2014年,HL7推出了FHIR。这些标准是为何以及如何演进的?
互操作标准发展要满足不断变化的行业需求和用例
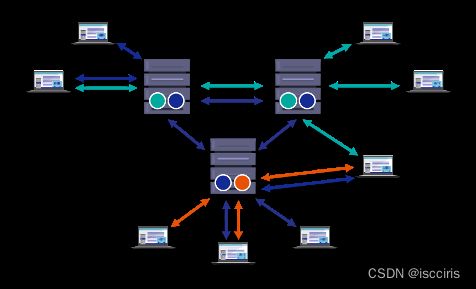
先看看90年代初的互操作的业务环境,就像下图那么简单:医疗机构还处在数码化向数字化转换的时代 - HIS等业务系统开始大规模部署以实现流程和数据的数码化,同时产生了非常有限的跨业务系统的流程自动化 – 信息集成需求。实时卫生信息交换的需求基本都在医疗机构内部(局域网,那时候WWW刚诞生),而院内的业务系统数量非常有限、且系统边界清晰,使用的用户基本就是医护技和管理人员,需要的互操作流量规模可以准确预测。而且系统互操作的技术手段非常有限,基本就是文件传输、串并口、socket,而SOAP(2000年)、RESTful(2000年)、甚至HTTP(1996年)等协议都还没有产生。
HL7 V2
这就是HL7 V2消息交换标准产生的时代,和所面临的互操作业务需求:它将业务事件和业务事件的上下文封装在消息结构中,在系统边界中传递这些消息。
业务系统边界清晰,一般用消息引擎来路由和转发这些消息,从而不打破系统边界。各个业务系统只要能接收/发送并处理这些标准化的消息即可。
近距离看一个HL7 V2消息示例,它是一个由多种分隔符分割的字符串,由区段和字段构成:区段是一组分类的数据,例如PID是患者信息区段;而字段是每个数据项,例如患者标识(在PID区段里)是“1182594^^系联医院&1^系联医院&1”,它本身也是一个结构,用于放标识符(1182594)和标识分配机构(系联医院)等信息。
而事件就是消息头区段里的ORM^O01,其中ORM代表业务域”通用医嘱消息”,O01代表事件“医嘱请求”。
消息头区段 MSH|^~\&|HIS|系联医院|系联实验室|系联医院|202302160002||ORM^O01|demo22903||2.5|382|||||UTF8
患者区段 PID||1182594^^^系联医院&1^^系联医院&1|||李小明||19570320|M|||北京市朝阳区建国门外大街乙12号2702
就诊区段 PV1|22903|O|心内科||||35030099^唐^南|||MED|||||||35019964^郑^顾樽||22903|||||||||||||||||||||||||202302160002^M
保险区段 IN1|1|65110116^城镇职工医保|
医嘱区段 ORC|NW|MS:1182594:1|||SC||||202302160002^M||||||||||||||||||||LAB
医嘱明细区段 OBR|1|MS:1182594:1||4548-4^糖化血红蛋白^loinc
为什么HL7 V2会是这种难读的格式?因为它是窄带时代的产物,当时通讯带宽有限,数据格式需要紧凑,通常仅用分隔符分割,以减少传输的数据量(相较与XML,通常能减少80%以上的数据),如今在一些检验检查设备的通讯协议中还能看到类似的设计。同时,从早期直到现在,多数HL7 V2消息是通过socket交换的。这些特征都是90年代互操作的历史印记。
HL7 V2是按模式复用的角度设计的颗粒度,也就是说它的颗粒度是信息区段。但并不是所有的信息区段都有独立的含义和复用的价值,例如区段TQ1、TQ2定义服药时间和用药途径,没有单独存在的可能和直接复用的价值。
另外,V2消息的字段随意性很大,相同内容可以放在不同的字段甚至区段里面;用户还被鼓励创建自定义的Z区段进行消息体扩展。也就是说它标准化程度不高,需要实施的双方事先约定好数据具体怎么放才能实现信息交换。同时V2术语约束机制很弱。
HL7 V3 和 CDA
世纪之交,卫生信息化发展提速,电子病历和各种专科系统崛起,更极大推动了卫生信息的交换和流程自动化的需求,同时对交换的语义标准化程度有了更高的要求。这需要更严谨的互操作业务抽象和术语约束。卫生信息正式进入数字化时代,也正是在这一时期,诞生了包括IHE、CDA、HL7 V3在内的众多互操作标准。
从模型抽象的角度看,应该全面包含用例模型、信息模型和交互模型,但V2的关注点基本在交互层面,对其它层面的抽象很弱。
由此,携着其著名的参考信息模型(RIM)方法论,V3在2005年横空出世,对业务场景进行分析,抽象交互逻辑,从参考信息模型到领域信息模型,再到精细化消息信息模型,最终产生需要的消息模型。模型以XML进行序列化,相较于V2,进步了许多。

这套方法论产生的V3消息标准化程度很高。但为了覆盖所有业务需求,RIM是高度抽象的(难于理解的);同时V3方法论是“按约束设计”(design by constraint),试图涵盖所有应用场景,避免自定义扩展,这使其越来越复杂、越来越庞大,而且用户没有RIM基础很难自己对其扩展,从一个极端走向另一个极端。
V3的高复杂性和高使用门槛,造成了它事实上的失败,没有成为V2的替代者,就像一些专家评论的 – “RIM创建了语义互操作性,但没有创建临床互操作性“。
注意,国内有一些实践中,甚至没有严格遵循V3发布的XML schema,直接用代码拼出XML字符串,也不做消息校验,这不算标准的V3。
同样在世纪之交,很多业务需要即时性不那么强、但数据更完整的交换 - 小结性质的临床文档交换。在这个领域,最主流的是CDA临床文档架构标准。CDA源于 1996 年就开始的临床文档中结构化标记工作,并在1997年并入HL7,随后使用V3参考信息模型来完善和发展。大家可能注意到前面的图上CDA早于V3发布,就是这个原因。
CDA临床文档架构,用于描述结构化文档,同时允许插入供人类解读的非结构化部分。它产生的文档具有上下文完整、可持久保存、可管理、可认证等特性。CDA文档和衍生的CCD文档广泛用于医疗机构边界间和医疗系统边界间的文档交换,或作为具有法律效力的临床文档依据保存在文档仓库。
CDA是成功的,可能是V3基础上唯一成功的部分,但它不能解决细数据颗粒度访问的需求。
IHE
虽然RIM基于业务场景、角色、触发事件等分析,但它的交付物 – 消息模型并无法执行流程与角色的约束。
服务用于业务场景里流程、角色的表达,功能内聚,可以通过企业服务总线(ESB)来协同,比消息路由规则更直观、更灵活,更适合实现业务流程的自动化。通常服务是比较大尺度的业务表达,服务标准广泛采纳的难度在于它实际上是规范业务流程和业务方法,而实际上多数机构的业务并不那么一致。
IHE(Integrating the Healthcare Enterprise)是国际上比较流行而成功的卫生信息交换服务规范。它是1998年,由HIMSS 和RSNA(北美放射学协会)发起,由一帮放射学和IT技术专家创建的。它最初为放射影像信息共享提供技术框架,以解决即便有了DICOM后在不同厂商系统间放射影像信息交换的标准和流程上的困难,后面逐步涵盖了越来越多的业务场景。IHE使用已经发布的卫生信息内容标准和术语标准,例如DICOM、HL7、LOINC等,来构建自己的服务框架,利用企业服务总线来协同这些服务,可以实现比消息交互更功能内聚的互操作架构:
- 服务本身封装了事件、上下文
- 服务针对于场景定义了流程和角色
- 适合跨清晰的业务系统边界间信息交换
- 服务有多种互操作模式:
– Web 服务本身是可互操作的,这意味着任何客户端都可以直接调用 Web 服务
– 服务可以通过企业服务总线(ESB)来协同,比消息路由规则更直观、更灵活
IHE分析每个业务场景(Profile),将业务场景中参与方定义为角色(Actors),场景中角色的交互定义为事务(Transactions)。例如跨机构的文档共享业务场景中,有4个不同的角色:文档源、文档注册器、文档使用者和文档仓库。而交互事务有注册、查询、获取等

IHE能在服务标准上取得成功,在于它先在参与的用户基础上规范业务,然后再基于规范的业务发布相应的服务,也就是说,使用IHE需要先认同它的规范出的业务。
IHE一直随着业务、技术和互操作标准的发展而不断演进,从最初使用DICOM + HL7 V2,到最新基于FHIR;从最初的影像信息交换到最近的患者穿戴设备的数据交换。例如在2007年,IHE创建了基于HL7 V3的跨机构档案共享的Profile – XDS.b,之后又推出了基于FHIR的诸多移动端服务。
卫生信息数字化转型对卫生信息互操作标准的挑战
2014年是分水岭的一年:两年前的2012年,IBM提出数字化转型概念; 2014年,移动互联网用户超过了桌面互联网用户,正式进入移动互联网时代;次年中国政府工作报告中首次提出“互联网+”行动计划。

图片来源:HL7 国际
在卫生信息领域, 2013年HL7绘制了这张图,总结10年前发生在我们身边的重大技术革命、生物信息学进步和社会经济变革和对卫生信息互操作的挑战。
而2013年之后的最近10年,我们面临了更多的机会与挑战 – 云计算、虚拟现实、5G、AIGC、医保异地实时结算、新冠全球大流行…
简单梳理一下在数字化转型时代下,卫生信息行业面临的挑战:
挑战1 – 卫生信息互操作的范围扩大
移动互联网时代的患者服务,突破了卫生信息化的传统边界:不再是院内的、不再仅是临床数据、不再局限于医护技用户。一旦面向患者服务,传统的互操作模式和架构 - 消息引擎、企业服务总线都受限于其有限的业务弹性,难于满足患者服务的需求。其性能压力挑战就像12306面临的一样,而卫生信息却远比火车订票信息复杂的多。

卫生信息互操作需要数据覆盖面更广、更灵活扩展、更具有弹性的标准。
挑战2 – 快速的业务迭代进化
传统信息化系统建设是这种烟囱模式 – 从底层数据模型建模、业务逻辑开发到用户界面展现,自成一体,对语义标准化和互操作要求不高,同时数据和逻辑在非标准语义的情况下也难于复用。
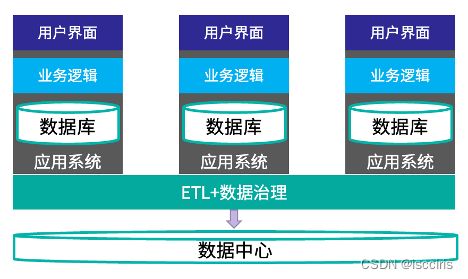
数码化时代和数字化时代,面向医护技的应用可以3-5年升级换代一次,烟囱模式问题不大。但数字化转型时代,面向患者服务的应用可能每周都在升级!
这种烟囱模式不仅应用开发周期长,还阻碍了我们利用已有建设成果快速进化业务的能力,显然满足不了当今业务快速迭代进化的需要。
我们不能从零开始,需要统一语义、统一服务,复用已有的数据和服务/API,并基于此快速构建和迭代新的业务 – 这正是数字化转型的核心。信息互操作不仅解决数字化问题,也是解决数字化转型的钥匙。这当然也需要更广泛统一语义的互操作标准。
挑战3 – 基于知识库和机器学习的自动临床决策
生物信息学进步让我们认识到更底层致病和治病的机理,获得了更多类型的决策数据;信息化建设让我们积累了大量的数据;医疗物联网带来了更多的院外数据。但人类大脑决策受制于能同时处理的5-10个信息量的极限,难于在医疗决策过程中利用爆炸的数据规模和数据类型。
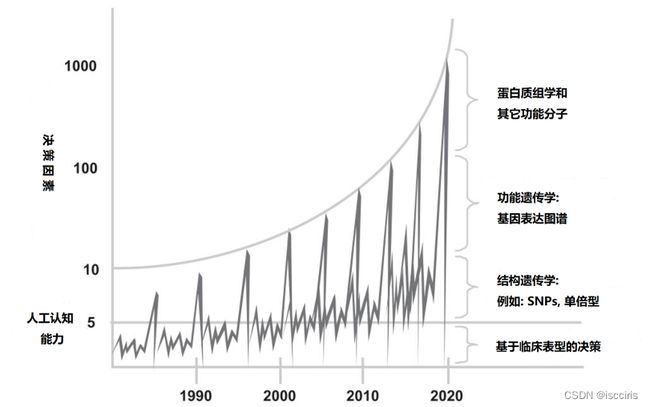
信息来源:Evidence-Based Medicine and the Changing Nature of Healthcare: 2007 IOM Annual Meeting Summary
知识库和机器学习的进步可以帮助医生突破人工认知能力的限制,并提供更智能的服务。但同时这对行业语义和语义的颗粒度提出了挑战 – 知识库和机器学习都需要结构化、干净、完整、无歧义的数据,而决策逻辑和质量指标更需要细颗粒度的行业统一的语义,以避免医疗差错、实现大范围和低成本的复用。例如,由于行业整体缺乏统一语义,当前的数据中心项目建设中的80%的工作都用于源数据分析、处理,成本巨大、数据的准确率和实效性仍很差。
将这些辅助决策集成到医生的诊疗流程是另一个面临的挑战,对决策的实时性要求很高,需要集成方式上的创新。

挑战4 – 数据资产要素流通
2022年底国家提出了数据资产要素流通的指导意见 -《中共中央 国务院关于构建数据基础制度更好发挥数据要素作用的意见》,而各地的大数据局也应运而生。
当数据继人、财、物、知识产权之后,成为资产要素并且可以流通时,它显然能创造更大的价值。而卫生信息作为非常重要且高度敏感的数据资产,如何安全、可靠地流通?我们面临着建设广泛认同和开放的行业语义模型、可追溯数据来源、提供多样化数据资产流通形态等挑战。
与其它资产要素不同,数据资产需要更复杂的确权 – 数据到底是谁产生的?谁具有有拥有权、加工权和使用权? 这些需要可追溯数据来源。
而不同于知识产权,数据资产不能一给了之,否则很难保证数据不被盗用与滥用。这需要对数据资产提供多样化的流通形态 – 除了原始数据和简单脱敏后数据、还应该有加工后的数据、甚至产生的数据模型,例如特定人群的特定疾病风险,对于保险公司是非常重要的数据,这样的数据大可不必以原始数据的形态流通给保险公司,而是基于机器学习,在原始数据集上运算和学习,并返回简单结果或预测模型给保险公司。
卫生信息互操作的新篇章 – FHIR
在2014年,为应对各种时代挑战,同时正视V3的失败,HL7发布了其新一代的卫生信息互操作标准FHIR (Fast Healthcare Interoperability Resources)。
发布近10年后,FHIR如今已经接近HL7 V2的采纳度。我们看到越来越多国家采纳FHIR标准,甚至作为卫生信息数字化转型的支柱,例如英国的NHS和最近印度尼西亚的SATUSEHAT国家卫生信息交换平台采用FHIR作为基础。

从名字看,FHIR只是HL7发布的新一代卫生信息互操作标准,它如何应对这么多挑战,甚至成为卫生信息数字化转型的支柱?
HL7总结了之前发布的互操作标准,使FHIR主要在这些方面做了创新:
- 更细颗粒度和更广业务范围的行业语义
- 更灵活的语义扩展和再约束机制
- 成熟度机制,标准随大范围使用与反馈获得版本升级和成熟
- 更多样的互操作模式
- 更广泛的生态建设, 利用生态解决远远超过单一互操作标准能解决的问题
FHIR采用的CC0许可协议,也叫“知识共享”,是指知识产权“不保留任何权利”。这与之前的标准不同,促进了FHIR生态的高速建设。而丰满的FHIR生态是其能在持续应对各种挑战时保持韧性的保障。
我们仔细看看FHIR是如何应对挑战的
应对卫生信息互操作的范围扩大
FHIR不试图通过发布的标准资源去涵盖所有业务需求,而是按80/20原则将最常用的那80%的用例总结归纳为数量最少的资源模型,降低了采纳门槛。对剩下的20%不常见的用例,它提供了一套标准的扩展/再约束机制(profile、implementation guide),并且这套机制产生的扩展/再约束是计算机可读(可理解)的,从而保障了更高的适用度。
FHIR的资源模型是对象模型,通过资源引用表达模型间的关系,避免明文上下文的传递所带来的潜在数据冗余与冲突。
FHIR的资源模型是细颗粒度的,并且业务覆盖范围广。
FHIR的成熟度模型,保证了FHIR资源和其它工件是随大范围使用与反馈获得版本升级和成熟。同时让用户明确知道资源的成熟度,并自己决定是否采用。
支持多种互操作模式,尤其是RESTful API,可以实现对资源细颗粒度操作,避免发布“大服务”,而是让用户自己组合“微服务” – API。也因此,FHIR可以摆脱消息引擎、ESB等中心化、缺乏弹性扩展能力的组件,再加上数据的JSON序列化方式,满足移动互联网时代的互操作所需的轻量化和弹性。
FHIR API:

应对快速的业务迭代进化
FHIR是怎么应对快速的业务迭代进化需求的?先看看SMART on FHIR这个应用架构:
在注意到电子健康档案系统(EHR)架构不灵活、并影响到应用快速创新后,2010年哈佛医学院和波士顿儿童医院发起了名为SMART(Substitutable Medical Applications and Reusable Technologies, 可替代的医学应用和可复用技术) 的项目,目的是构建一个应用平台架构,让医学应用可以在上面被开发,并无需修改地运行在跨不同的医疗IT系统间 – 就像苹果和安卓移动应用那样即插即用。但与移动应用不同的是,在医疗应用架构上采用通用、可互操作的数据规范将是这一生态系统的关键要求。
为实现这个目标,它开发了一套绑定术语的、用RDF表达的标准临床数据模型 - SMART Classic、基于RESTful API开发了一套操作数据的标准API、使用Oauth2作为标准认证机制、HTML5作为标准界面开发技术。理想很好,但当时并没有多少厂商愿意支持,因为它并不是业内广泛采纳的互操作标准,SMART Classic仅覆盖临床,且RDF并不流行。
SMART早期就参与了FHIR前身 - Fresh Look Task Force的讨论。在2013年,SMART注意到尚未发布的FHIR可以帮助解决标准数据模型、标准API等,且数据模型的覆盖面更广,于是在FHIR发布的2014年,迅速成为FHIR生态的一员,变成了SMART on FHIR。
如今,SMART 应用市场已经有大量免费或收费的应用,例如心血管病风险评估、新生儿胆红素管理、患者360视图… 作为用户,你喜欢的应用下载部署在相应版本要求的FHIR服务器上即可,实现了即插即用。作为SMART应用的开发者,只需要专注于业务本身,无需设计底层数据模型和API,加速了应用开发,从而支撑业务快速迭代进化。
SMART on FHIR只是基于FHIR加速应用创新的一个例子, Apple Health也是基于FHIR的,而Epic的用法也极具启发性:Epic在2022年底将其应用市场升级为Connection Hub,通过开放55个FHIR资源和相应API,让开发者基于FHIR标准开发应用且这些应用都可以运行在所有Epic 电子病历/电子健康档案系统上。短短不到一年,已经有众多开发商和开发者贡献了近500个不同类型的应用,而Epic借助FHIR和FHIR生态,快速构建了自己的应用生态并让其用户直接受益 ,也让它的电子病历/电子健康档案系统成为一个应用平台!
应对基于知识库和机器学习的自动临床决策
无论是基于知识库规则还是基于机器学习的决策,统一语义和数据的可访问性都是关键。FHIR首先为决策提供了统一语义和对细颗粒度的决策数据的简单访问API。而有了统一语义的细颗粒度数据模型和标准API,生态里应该很容易设计出决策支持架构。
的确如此,SMART团队在2015年启动了CDS Hooks项目,基于FHIR构建了决策服务和决策架构,从而让决策自动集成到业务流程之中,并提供多种决策方式 – 信息提示、建议和启动SMART 应用。它的功能示意如下:
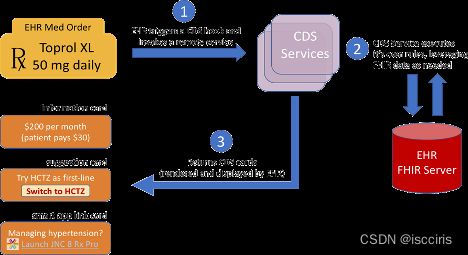
而FHIR也在R5中扩展了自己的互操作范式,增加了订阅模式,使决策系统和业务流程可以基于发布/订阅的松耦合架构进行集成。
应对数据资产要素流通(数据20条)
2020年12月,发改委、网信办等四部门发布《关于加快构建全国一体化大数据中心协同创新体系的指导意见》,提出要完善覆盖原始数据、脱敏处理数据、模型化数据和人工智能化数据等不同数据开发层级的新型大数据综合交易机制,确定了数据交易的四种产品形态。
FHIR的统一语义首先保证了卫生信息数据资产的统一可量化,基于FHIR的profile可以进一步基于不同用途对数据质量进行约束检查和过滤。
另一方面,FHIR提供多形态的数据流通与利用能力,包括
- 对细颗粒度的数据操作 – FHIR API (CRUD)
- 对数据的共享和交换
– FHIR API、服务
– FHIR 消息、文档 - 对大规模数据检索 – 基于查询参数的FHIR API
– 例如: GET http://fhirsvr.com/Observation?code-value-quantity=loinc|1234-1$lt9.2 - 对大规模的数据分析
– 临床质量指标与决策支持 – CQL on FHIR
– 数据分析 – SQL on FHIR
– 科研数据分析 – OMOP on FHIR
这其中FHIR生态下的几个项目尤其令人侧目:
CQL(Clinical Quality Language, 临床质量语言) 也是HL7组织下的一个标准, 用于定义和编写质量指标逻辑 - 那些用于决策的指标。起初它以QDM(Quality Data Model)作为基础数据模型,其语法“隐藏”了大部分定义质量指标逻辑的复杂性从而简化实施。而今它利用FHIR,从而让质量指标逻辑更易于阅读和理解、执行更加便捷,并融入到大的FHIR生态。
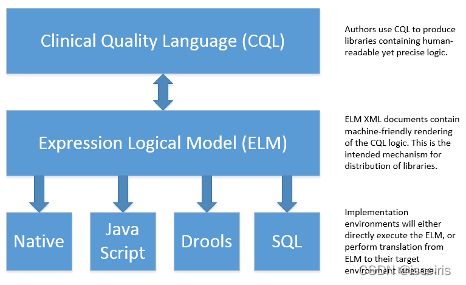
使用CQL,可以设计需要的数据逻辑,让CQL引擎在后台利用FHIR数据进行运算,而客户端只拿到结果,让数据可用而不可见。
不止如此,另一个生态项目SQL on FHIR的初衷是让统计分析和机器学习的客户端可以使用SQL无缝地访问FHIR数据。作为最成熟和通用的数据操作方式,SQL也可以让FHIR生态和隐私计算生态打通,实现更多样的“数据可用不可见”。
这里总结了FHIR特点与数据资产要素流通要求之间的匹配:
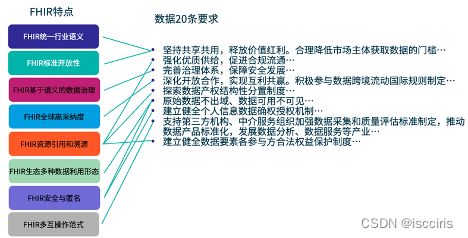
从国际卫生信息互操作标准发展史、对当今各种互操作挑战的应对、以及它日益成熟壮大的生态,能看到FHIR强大的生命力和广泛的适应性。随着FHIR的成熟,FHIR的生态正快速填补卫生信息蓝图的每一块拼图。
相信借鉴FHIR和其生态,我们也能设计和实现更好的卫生信息互操作。