【计算机系统结构实验】实验4 向量扩展指令和编程
4.1 实验目的
- 理解向量的处理方法;掌握X86体系中MMX/SSE/AVX指令集进行编程的基本方法。
- 理解SIMD指令含义及原理,了解Kunpeng数学库的安装与使用
4.2 实验平台
- 需要x86计算机和微软编程工具Visual Studio 2012。
- Taishan服务器,安装openEuler系统,已安装gcc编译器和鲲鹏数学库KML
4.3 实验说明
- SSE、AVX 都是 x86 平台的 SIMD 指令,SIMD 是单指令多数据流的简称,可用来加快计算速度。鲲鹏平台也有自己的 SIMD 指令,名为 Neon。
- 鲲鹏数学库(Kunpeng Math Library,以下简称KML)提供了基于鲲鹏平台优化的高性能数学函数,所有接口由C/C++、汇编语言实现,部分接口提供Java语言封装的接口。向量数学库(Vector Mathematical Library),通过Neon指令优化、内联汇编等方法,对输入数据进行向量化处理,充分利用了鲲鹏架构下的寄存器特点,实现了在鲲鹏服务器上的性能提升。
(Kunpeng BoostKit 22.0.0 鲲鹏数学库 开发指南 01 - 华为)
4.4 实验内容
1. X86平台的向量扩展指令
x86处理器支持的向量扩展指令有:MMX/SSE/AVX指令集。在Visual Studio中可使用内联函数访问,使用时需要添加对应的头文件:
mmintrin.h------>MMX
xmmintrin.h------>SSE
emmintrin.h------>SSE2
pmmintrin.h------>SSE3
immintrin.h------>AVX
可使用CPU-Z的小工具查询自己的机器支持的MMX/SSE/AVX指令集情况。

下面以SSE指令集为例,做一个小实验。
SSE指令在运算时使用128位的SSE暂存器 (可看作是向量寄存器)。
使用SSE指令写代码的步骤为:使用load/set函数将数据从内存加载到SSE暂存器;使用相关SSE运算指令完成计算;使用store函数将结果从暂存器保存回内存。
1)Load系列函数:用于加载数据,将数据从内存加载到暂存器。
比如,使用_mm_load_ps(float const * _A)函数来实现加载4个float型的元素,组合成1个__m128类型的向量数据,放入暂存器。(注:__m128是 SSE指令采用的向量数据类型,是128位(16字节)的)。
在使用该函数时,输入数据需要先被指定为16字节对齐,用_declspec函数来实现对齐: __declspec(align(16)) float Input[4]={1.0,2.0,3.0,4.0}
2)Store系列函数:用于将SSE暂存器的数据保存回内存中。
用SSE指令运算后的数据一般以__m128的数据类型保存在暂存器里,可以使用以下store函数将其变回float类型再保存到内存中:
void _mm_store_ps(float* p, __m128 a);
3)运算指令
SSE提供了大量的向量浮点运算指令,包括加法、减法、乘法、除法、开方、最大值、最小值、近似求倒数、求开方的倒数等等。下面是一条向量加法指令。
__m128 _mm_add_ps (__m128 a, __m128 b)
新建一个空项目,添加项目中的cpp源文件,代码如下:
#include "xmmintrin.h"
#include
using namespace std;
void main()
{
__declspec(align(16)) float Input1[4] = {1.0,2.0,3.0,4.0};
__declspec(align(16)) float Input2[4] = {5.0,6.0,7.0,8.0};
__declspec(align(16)) float Result[4];
__m128 a = _mm_load_ps(Input1);
__m128 b = _mm_load_ps(Input2);
__m128 c = _mm_add_ps(a,b);
_mm_store_ps(Result,c);
cout<
运行结果:

这段代码主要使用了SSE指令集,其实现的功能如下:
1. 定义了两个16字节对齐(_declspec函数)的浮点数数组Input1、Input2和结果数组Result。
2. 使用_mm_load_ps函数从Input1和Input2数组(内存)中加载4个float型的元素,组合成1个__m128类型的向量数据,放入__m128类型(SSE指令采用的向量数据类型,是128位(16字节)的)的变量a和b(暂存器)中。
3.使用_mm_add_ps函数对a和b(暂存器)进行向量浮点加法操作,结果(数据类型为__m128)存储在c(暂存器)中。
4. 使用_mm_store_ps函数将c中的结果的数据类型由__m128变回float类型,并将其存储到Result数组(内存)中。
5. 代码打印了a, b, 和 c中的各个元素。
6. 代码打印了Result数组中的各个元素。
这段代码使用了SSE指令集进行运算操作,以及使用load/set与store函数进行内存与暂存器的数据传输,展示了向量扩展指令的运用。
2. OpenEuler平台的KML库
1)在实验机器上,使用学生账号通过SSH方式远程连接Taishan服务器 (用户名:stud001——stud140,密码:1)
![]()
2) 使用VIM编辑器,创建程序simd.c,使用sin函数作为耗时功能函数,并使用gcc编译该程序, 对-lm参数进行解释说明。
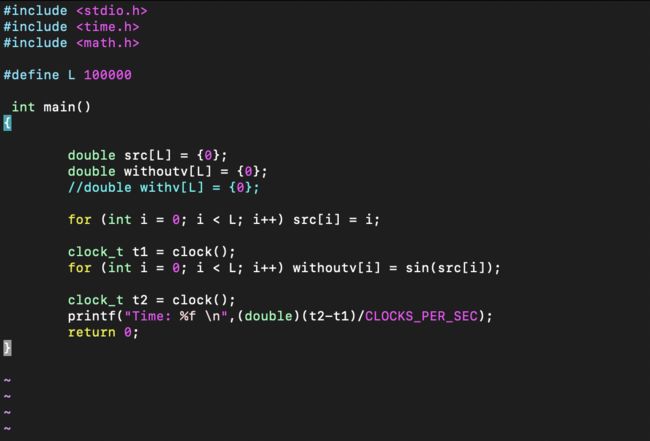
![]()
-l[library name],用来指定编译时候使用的库,-lm 为指定数学库。
3) 运行simd程序,查看并记录结果。
多次运行结果显示
Time: 0.002871
Time: 0.002772
Time: 0.002759
Time: 0.002765
这段代码主要操作如下:
- 用一个for循环将src数组中的每个元素赋值为它的索引值。
- 用另一个for循环将src数组中的每个元素的sin值计算出来,并存储到withoutv数组中。
- 打印出计算sin值所花费的时间。(double)(t2-t1)是计算两个时间点之间的时间差,CLOCKS_PER_SEC是每秒的时钟周期数,所以整个表达式的值就是时间差除以每秒的时钟周期数,即计算出的秒数。
4)使用KML库中的函数改写程序,新建程序simdv.c ,使用向量vdsin函数,其余保持不变,使用GCC编译程序,对“- L”“- I” 参数进行相应的解释说明

编译指令为:
![]()
-L [dir],制定编译的时候,指定库的搜索路径,告诉编译器在 dir 目录中查找库文件,例如可以指定搜索自定义库。
-I [dir],表示将 dir 目录添加到头文件搜索路径中,这样就可以直接使用 #include
5) 运行simdv程序,查看并记录结果。
多次运行结果显示
Time: 0.000778
Time: 0.000772
Time: 0.000799
Time: 0.000772
6) 修改上述simd及simdv代码中L参数,并使用tan功能,记录结果对比长度对时间的影响:
| L |
Time: Simd.c |
Time: Simdv.c |
| 1 |
0.000004 |
0.000006 |
| 10 |
0.000010 |
0.000004 |
| 100 |
0.000019 |
0.000004 |
| 1000 |
0.000078 |
0.000013 |
| 10000 |
0.000637 |
0.000102 |
| 100000 |
0.006211 |
0.000969 |
可以看到,当数组大小变大时,vdtan函数可以显著缩短程序的运行时间。
4.5 实验总结
通过本次实验,我了解了SIMD指令含义及原理与MMX/SSE/AVX指令集的功能与使用,并在电脑上使用SSE指令集进行了基本的运算操作,学习运用了向量扩展指令。同时也了解了鲲鹏数学库的功能与使用,并编译运行了包含sin函数、vdsin函数、tan函数、vdtan函数的程序,对比了数组长度与不同函数对程序运行时间的影响。
-------------------------------------------------------------------------------------------------------
最后一点碎碎念:如果各位有发现本文有哪处有误或理解不当的地方,敬请指正。