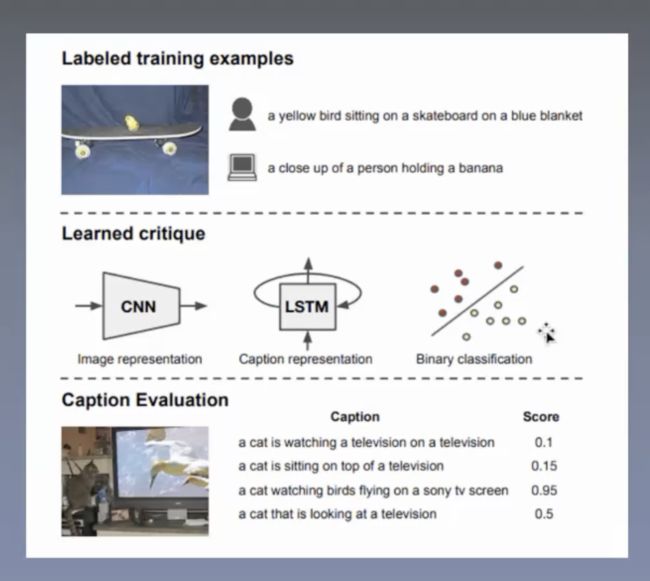
image caption 必看论文,模型整理
基础模型
transformers- attention is all you need
细节笔记
论文笔记
几个重点
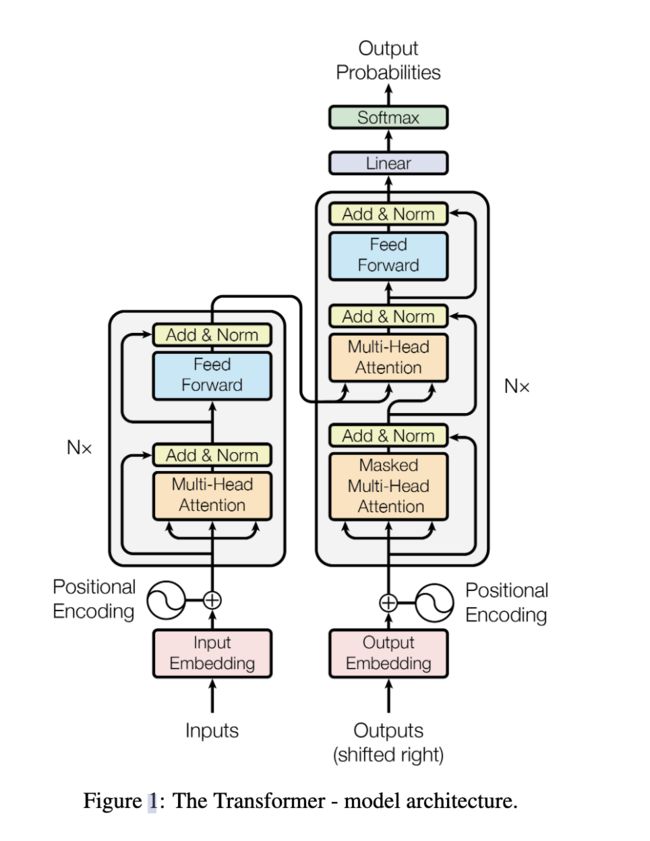
1. 架构图
2. attention 原理

attention机制中的query,key,value的概念解释

3. 为什么self-attention?为什么multi-head attention?
rnn 是ht的结果是根据ht-1的结果计算得到,无法并行的计算,这也是推出transfomers最根本的理由。

根据这个图,Self Attention就是让Attention中的q、k、v相等,所以self attention其实得到的是输入序列中每个部分与整个序列其他部分的关系,注意q、k、v来自于同一个向量但是经过了不同的投影矩阵,因此q、k、v是不一样的。
我们直接来看transformer中的Self Attention结构图,可以看到transformer是使用的Dot-Product Attention的变体(多除了个根号d,d是输入序列的通道数,目的是为了防止Q与K转置的内积过大或过小导致梯度较小),但因为d是设置好的超参数(常数),因此两者其实没有太大差别。

的结果就是Q和K的相似度,经过softmax使其变为0到1的数值后作为V的权重。
可以看到上述过程其实就是一系列的矩阵运算,并不包含任何参数,只有上图右侧中的Linear层是可学习的,而Linear层的作用是将Q、K、V投影到高维语义空间(也就是multi-head attention的作用)。所以上述的Self Attention操作实际上是在计算高维语义空间的Q和K的相似度作为V的权重进行了特征融合以获取全局信息。那么说明我们其实是通过喂数据给模型,指导其学会投影出这么一个语义空间——在此空间中我们期望相似的Q与K具有很高的相似度。
举个句子生成的例子来说,我们以Hello作为模型的输入,World作为下一个词的ground truth,只有当Hello和Word在投影出来的空间中具有较高的相似度,我们的attention机制才会给World较高的权重从而让模型输出World,那么通过自注意力的计算和梯度下降,我们就能让Linear学会让两个词投影到相近的位置
4. 为什么position encoding?
对于序列的seq / rnn 是有时序信息的。而对于Transformer来说,由于句子中的词语都是同时进入网络进行处理,顺序信息在输入网络时就已丢失。一句话概括,Positional Encoding就是句子中词语相对位置的编码,让Transformer保留词语的位置信息。
CV领域
vision transformer的笔记
DETR: End-to-End Object Detection with Transformers
clip 论文
笔记
论文笔记
多模态鸿沟
数据集:四亿的图文对,进行对比学习。
对比学习,就是需要正样本和负样本的定义。在这里的正样本就是已经配对好的,反之就是负样本。所以有N个正样本,有N2 -N个负样本
clip 做目标检测
Open-Vocabulary Object Detection
clip 做图像分割
CLIPSeg
Image Caption 领域
李飞飞经典
Deep Visual-Semantic Alignments for Generating Image Descriptions
文章目标:
- We develop a deep neural network model that infers the latent alignment between segments of sentences and the region of the image that they describe.
- 提出了一种深度神经网路模型,该模型用来将训练样本中图片中的一些重点部分与生成句中的词组相对应。 部分图片和词组做对应(1 图像分割 2. 句子分割 3. 目标对应 4. 解码) 匹配来做。


- We introduce a multimodal Recurrent Neural Network architecture that takes an input image and generates its description in text.
- 提出一种多通道RNN框架来描述一张图片。生成

解读
show and tell 入门
Show and Tell: A Neural Image Caption Generator 2015
Show and Tell: A Neural Image Caption Generator 2015
这个模型的意思呢就是参考机器翻译那样,把图像编码成一种可以用来表示主要特征的机器语言,然后再讲该语言像中英文翻译的那种方法来“翻译”出来,从而形成图像描述。我们可以通过以下公式最大化生成单词的概率
创新点:
- deep cnn - 把googlenet拿来做预训练,把网络往深了挖。
- 这篇论文则首次提出用一个模型来解决所有的问题,俗称一步到位(狗头)
与上篇方法的对比,问题在于:这种方法训练会有一个问题,图像在转序列化时会丢失很多的信息。loss为生成的单词和groud truth的对比,关键点在于能否把文本生成的越来越好。


Show, Attend and Tell 引入注意力机制
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention

生成的文本应该关注到生成的单词是来自于图像 还是来自于文本,所以引入了注意力机制。

解读
这篇论文更多关注的是图像的attention,把很多图像的具体信息,比如说颜色,背景 个数,但是也会有很多问题。在下面的论文也有提到,不应该单纯的依赖纯图像注意力。
引入语义的attention
Image Captioning with Semantic Attention

这篇论文更关注了语义的attention 比如说 on _ table 让文本来做,很容易预测是 on the table ,但是对于cv来说,生成冠词 会浪费很多计算量等等。词表的生成是出现五次以上的词才有。
所以会以此有很多attention的paper:
- channel attention
- 个数的attention
- location 的attention
- 冠词的 attention
例子:
Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning [Paper] [Review]
相关代码:
GitHub - yufengm/Adaptive: Pytorch Implementation of Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning
GitHub - jiasenlu/AdaptiveAttention: Implementation of "Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning"
架构图
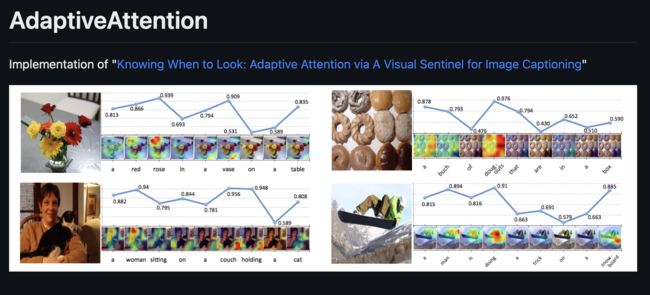
结果:
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering 2018

多任务辅助合作
多任务辅助合作
检索和生成
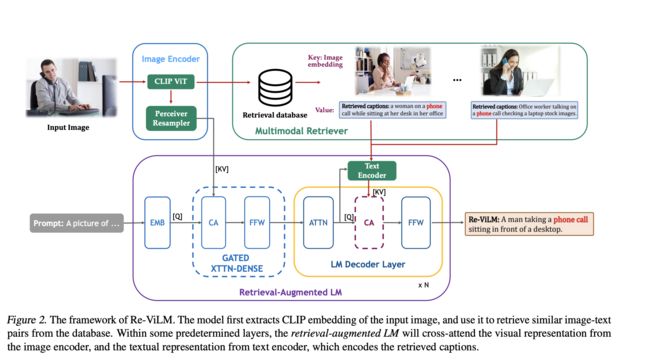
Re-ViLM: Retrieval-Augmented Visual Language Model for Zero and Few-Shot Image Captioning
检索增强的
细粒度可控
淘宝对于此做了很多的工作
对于淘宝的搜索,比如说品牌的细粒度。
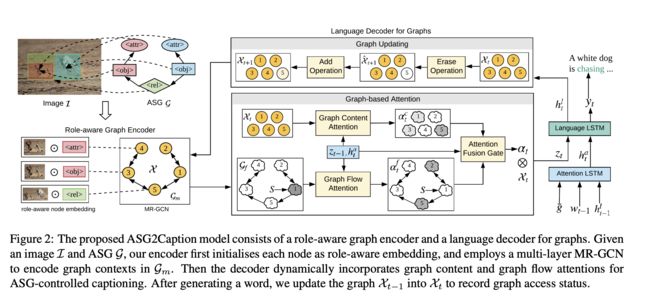
论文
代码
clip 对于细粒度的捕获并不足,这篇论文的关注点在于提高的细粒度的信息。
提出了一个三元组的概念,其中某个单词的是可以影响最后一句话的输出的。
比如说clip 能否 检测到一些位置信息,然后根据位置信息,区域的细粒度,文本的细粒度,生成更多的描述。
vqa的

论文
nlp的结构化信息 表格 三元组 把这些信息利用好。
DenseCap: Fully Convolutional Localization Networks for Dense Captioning

论文
预训练模型结合
与clip结合
论文
代码

llm和clip都有着超强的knowledge。都能够把open domain的领域进行一个表达。记忆力机制。
MemCan: Memorizing Style Knowledge for Image Captioning
一些问题的思考
Image caption = NLG?
1. 跟图像相关性判断?
2. 文本风格自由度?
3. 预训练词汇的相似度? 有一个paper是根据template来做,比如说第一个为冠词,这样的计算量速度。比如说gpt出现低频词的时候 概率是比较低的
4. 因果推理的源头?不应该是简单的encode-decode。是应该有一些reason的过程。而整个过程是应该有个推理链的。用途是vqa。需要更多统计学习的。