80x86汇编—指令系统
顺序是按照我们老师教的顺序,仅仅作为复习笔记。
汇编入门真的简单,深入难,毕竟学过计组CPU都只寄组的难处,指令系统不在话下了。
MOV
下图说明了一个MOV指令能够从哪里传到哪里,总结成一句话就是:立即数不允许直接存到段寄存器,除了寄存器可以寄存器与寄存器相互存之外其他都不允许,比如内存与内存之间(当然你不可能傻到用立即数存到立即数里面,这很傻OK?)
- 需要注意的一个点就是:MOV AX, BX中,AX这边的内存或者其他寄存器叫做目的操作数,最右边的叫做源操作数。像我们编程中的顺序一样,也是右边赋值给左边,应该是说C语言像汇编语法

简单举几个不明所以不知道干嘛的例子:
MOV AX, 6
MOV CS:[IP + 6], AX
MOV AX, CS:[IP + 6]
MOV DX, DS:[BX + 6]
MOV DS:[BX + 6], DX
MOV DX, [BX + 6]
MOV DX, CS
MOV AX, BX
MOV byte ptr DS:[BX + 6], 6
MOV word ptr DS:[BX + 6], 6
等等
- 解释:中括号内表示的是偏移地址
- 细节:如果你不写CS:或者DS:的话,就会默认DS数据段,所以有时候
也会有MOV DX, [BX + 6]这种写法,[BX + 6]就相当于DS : [BX + 6]
下面这种是看取的单位是多少,
MOV byte ptr DS:[BX + 6], 6
MOV word ptr DS:[BX + 6], 6
比如byte,那就会将6当作8位二进制数看待,然后存进DS:[BX + 6]这个内存空间中,他只是指明了一个单位,源操作数和目的操作数规则还是上面那张图片的传输规则,源操作数是6, 目的是内存单元,但是具体存的内存单元多大就是看你指明的单位了,如果不指明的话就按照目的操作数的单位进行存放,比如MOV AX,6的话肯定6进去AX就变成了16位二进制的6,同理内存也是,没有指明的话就是看你操作数大小,操作数能够用8086中单位存的下的话,单位是一个字节,也就是8位bit能够放得下的话就是一个B单元,大于8bit即大于1B的话我们就用一个word几一个字单元,也就是16bit存,有点内存对齐的意思,反正这是汇编器翻译的。

非法传送
- 首当其冲会出错的就是,内存与内存之间直接传输
- 单位不匹配,即mov byte类型, word类型这种错误写法,意思是word字空间要硬塞进byte字节空间,大了一倍还要硬塞你说行不行~(邪恶狗头),但是反过来就可以 ~
但是我观察到了一个很奇怪的现象,我在debug过程中,发现mov byte ptr ds:[0], ax这种竟然也可以,并且是将ax整个数据传输过去了,如下图所示,这其实间接在说明,如果不是立即数的话,会按照这个存储器或者寄存器的位数进行传输,但是存储器哪有位数,你存一个dword也存的下, 除非你内存空间连dword也不够了,否则你指定单位也没用,总结的话就是:源是寄存器的话,并且目的空间位数足够,就看源寄存器的位数多少就传多少,到底是不是这样呢?
接着来看这里,当我们使用寄存器作为目的操作数的时候会报错并且同时在指明了byte后mov依旧报错,那也就证明了我们确实是按照目的寄存器位数传输的,
再继续看下图,很明显我们已经证明出来了,说明了 我们的源位置是立即数的时候就只能够跟着指明什么单位,源操作数就只能写什么单位大小之内的操作数。
是否可以下结论了?
还不能下结论,如果还能知道当我们不指明单位的时候,能不能将小的源的数传到大的目的空间(很显然可以,也许是我不知道抽了哪一根筋觉得还需要这个证明),但不管怎么说,终于证明出来了。
debug 我希望知道在传输0034h指明了只传输34到底是不是正确的,也就是说我的00是不希望传进去的。截图中明显看到,我们只改变了CD部分,所以是正确的,并没有因为多写了00而将00传输进去(需要注意的是:1234h这种不可以传入指定byte比他位数小的,因为我们无法像00那样忽视掉12)



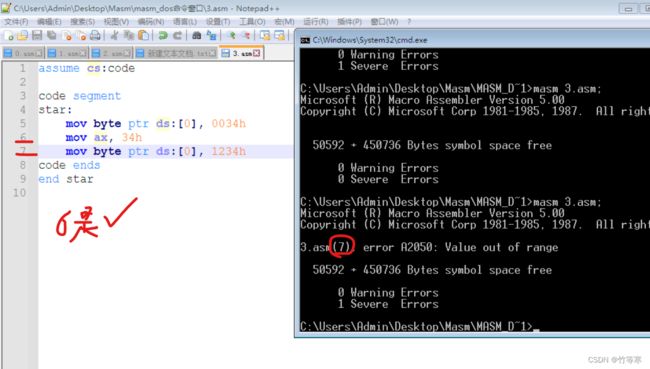

因此可以下结论了:当源是立即数的时候,需要指明传输大小,并且立即数只能够写在指明单位内的范围大小(即位数不能超过指明的单位位数,当然前面提到了0可以不计)
PS:说这么多其实只需要没必要纠结,指明的时候指明单位就行,只不过时鄙人的一些莫名其妙的Question罢辽。
- 段地址不能够直接传输立即数,需要通过寄存器转移,虽然图上面写着,但是貌似在汇编代码中行不通,都是需要先把段地址数值存到寄存器中然后才将寄存器转移到段寄存器中。段寄存器想要修改就一句话:你先将数据传到一个寄存器中打包好再传输给我的段地址,就是这么的矜贵!
段地址寄存器不可以互相传输,如下图验证

XCHG
交换指令,就像我们C语言中希望交换两个变量的值
交换也相当于传输指令一样,有如下注意事项
- 寄存器与寄存器之间可以进行交换
- 寄存器与存储器之间可以进行交换
- 存储器与存储器之间不可以直接交换
真的很哇塞了,不愧是高级语言的妈妈,MOV中也是存储器与存储器不能够直接交换,其原因我大胆猜测是因为我们的总线,访问都需要先通过数据总线的传输,数据总线只能够传输一份数据,所以我们必须是先调出内存存在寄存器中暂存着,才能够与目的存储器或者寄存器数据进行交换,交换过程原理肯定是和我们高级语言中做法一样,需要temp一个临时空间暂存,先将其中一方交过去,再将temp空间存过去。(如果不是麻烦请告诉我,这只是我一个大胆猜测)
XLAT
- XLAT = MOV AL, DS:[BX + AL]
很怪,他就是这么个意思,也就是说我们使用XLAT之前需要指明AL和BX,因为他的意识就是将DS段里面的BX作为基地址,然后AL是基于BX基地址继续偏移的地址,然后取出该单元放到AL中。
非常好,这里出现了内存空间 转移到 AL中,这里好像我们在证明MOV非法传送的时候没有特地去debug只是说了一下这是OK的,因为存储器的位数可以是8可以是16等等,很明显这是正确的。我为何说漏掉呢?是因为我们内存空间好像不知道是传输多少位,但是我们al是固定的8位,同时我们又没有指明单位,所以debug结果告诉我们,内存空间也就是存储器大小不用管大小,我们甚至可以理解为,存储器大小随着需求随意变换,这里我们目的需要al8位,那我们存储器中的内存空间传过去的就是8位。

堆栈指令 push 和 pop
都是基于8086架构介绍的 push 和 pop
栈顶是低地址,栈低是高地址(这里需要写汇编代码的时候才有深切体会,比如我们定义一个栈空间,那我们需要手动指明SP指向栈低,那栈低就是高地址,即SP指向我们定义的栈空间的最高地址,还需要我们手动操作,不是说你定义了栈就完事了,汇编都是颗粒性的操作)
-
push 操作数/寄存器/内存
指令执行过程中,会默认执行: SP = SP - 2

-
pop 寄存器/内存
指令执行过程中,会默认执行: SP = SP + 2

解释为什么我们SP栈低要指向高地址呢,其实可以强行通过push或者pop解释:因为push指令执行后SP就会默认自动执行一个操作(在8086中):
SP = SP - 2
具体减2还是减多少是看你的一个数据项占多少字节,我们8086中数据项就占一个字,又因为我们8086中的单位是byte即一个字节,所以push后也就是进栈一个字就是进栈两个字节,所以是sp-2。
之所以是因为我们栈低是高地址,就可以解释为因为push出栈是减法操作,那就间接说明了我们的栈底必须是高地址,假设是低地址,一用push的话你的SP指针就飞出栈了。
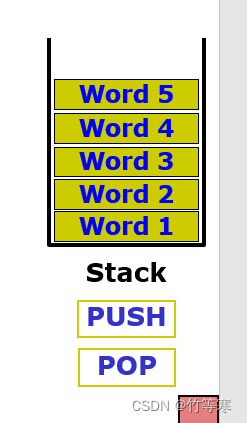
栈的出现真的是喜忧参半,喜是因为栈段十分有用,先进后出这种,所以我们可以通过一个栈段,push保存我们的地址数据或者寄存器,然后就可以随意地跳到其他子程序中,也就是函数调用的做法,当我们执行完后需要返回原来的地址继续执行往后的指令,那这时候直接pop出来我们保存的地址数据或者其他寄存器数据即可,同时我们也可以通过这个栈段在调用子程序的时候需要传参数也可以通过这个形式,这就是之前8086架构介绍过的传参问题,C语言中右边的参数先进栈后出栈,左边的后进栈那就先出栈。
↓↓
push ax
push bx
调用函数/子程序 (参数ax, 参数bx)
pop ax
pop bx
↑↑
这种在pop出参数的时候就很符合我们人类的思维,ax本来就是我们调用函数或者子程序的时候作为第一个参数传进来,那利用了先进后出的特点,我们就能够在函数内部子程序内部使用参数的时候就正常的从左到右使用参数。(强行解释)
注意:栈保存寄存的数据后,即push寄存器后,pop出来记得要将push进来的寄存器顺序颠倒一下,因为先push的是最后pop出去的,这种操作叫做保护现场

标志寄存器指令

标志位指令有一个规律,那就是希望将某个标志位置0就用CL打头,比如我希望将CF标志位清零,那就是CLC,我猜测CL是clear的意思,那反过来就是需要设置为1,对应的是不是就为STC,ST就是set的意思,那接下去基本就不用学习要怎么特地去记住将某个标志位设置0或者设置1
- CLC:将CF设置0
- STC:将CF设置1
- 特殊:CMC
意思是标志位CF求反,0的时候变1,1的时候变0- CLD:将DF设置0
- STD:将DF设置1
- CLI : 将IF 设置0
- STI : 将IF 设置1
解释常用标志位的用途
- CF
CF = 1, debug中显示为 CY
CF = 0, debug中显示为 NC
进位or借位标志,发生最高位进位的时候为1,最高位减法不够减的时候发生借位为1
CF只有在无符号数运算中会变化,有符号数没有进位或者借位,因为有符号涉及到补码,补码减法不够减或者加法结果超过能存储的位数大小叫做溢出,后面会介绍OF溢出标志
容易忽略的是能影响CF标志位的一定是运算操作,而不是转移类指令,比如mov是不会影响CF的
经过本人实验,CF会在下一条指令执行时候不会复原,也就是说当前CF为1,如果接下来好多条指令使用mov不影响CF的话,CF标志位是不会变回0之类的或者说不会复原的意思(这仅仅是我个人的疑惑而已) - OF
溢出标志,溢出只有在有符号数运算中会变化,因为无符号数中的上面提到过叫做进位不是溢出。
OF = 1, debug中显示为OV
OF = 0, debug中显示为NV
CF和OF的对比与区别,首先CF进位可能不会造成运算错误,因为我们可以用CF的标志位作为进位或者借位一同放进下一步的运算操作中,比如就有一条指令ADC就是运算加法的同时把CF标志位加上。然而OF表示溢出,发生溢出的话运算结果是不正确的。
- ZF
意思就是看运算后的结果是否为0
ZF = 1, debug中显示为ZR
ZF = 0, debug中显示为NZ - SF
符号标志位
SF = 1, debug中显示为NG, 表示负数
SF = 0, debug中显示为PL, 表示为正数 - PF
PF = 1, debug中显示为PE
PF = 0, debug中显示为PO
意思就是看一个数据里面低8位的1的个数是偶数还是奇数,奇数为0,偶数为1
细节:PF标志仅反映最低8位中“1”的个数是偶或奇,即使是进行16位字操作
运算指令
- ADD、ADC
加法运算, 最终结果放到目的操作数中,即左边的操作数
ADD 内存,寄存器/立即数
;↑↑结果存到内存中,因为左边的操作数是内存
ADD 寄存器,寄存器/立即数/内存
; ↑↑结果存到寄存器中,因为左边的操作数是寄存器
ADD就是不允许内存与内存直接触碰互相相加,这个原因上面提到了,内存与内存必须要出来总线才能接触到另一个内存…
ADC: 假设有进位,我们就需要用到ADC,ADC也是和ADD一样,只不过还加了一个CF标志位
即:ADC ax, bx 等于 ax = ax + bx + CF
通过ADC这个指令其实可以完成一个32位进位的加法问题,低位先进行ADD加法,然后高位就是用ADC加法,这样就能够享受到低位的进位,不管是否有进位,总之高位的使用ADC就是加上CF标志位总没错。 - INC
寄存器用来自增的,就好像 i++ , 这种也是会影响CF这种标志位,
用法就是只能够接寄存器或者内存,INC ax / INC byte ptr [bx] - SUB、SBB
减法运算, 最终结果放到目的操作数中,即左边的操作数
SUB 内存,寄存器/立即数
;↑↑结果存到内存中,因为左边的操作数是内存
SUB 寄存器,寄存器/立即数/内存
; ↑↑结果存到寄存器中,因为左边的操作数是寄存器
SBB: 既然加法有ADC顺便加上CF标志位,那么减法肯定也需要这么一个指令对CF标志位借位一同参与运算,那就是SBB(不是傻b),他也可以进行连续借位的运算,比如低位的sub al, bl后,进行了一次借位,ah 和 bh进行减法的时候就可以用sbb指令,也要将借位一起算进去。

如果减法结果为0,就会影响到ZF = 1 - DEC
既然有自增指令,那就有自减指令,相当于 i–,这种也是会影响CF这种标志位,
用法就是只能够接寄存器或者内存,DEC ax / DEC byte ptr [bx]
假设自减为0了同样会影响ZF = 1 - NEG
NEG ax
求补码指令,对操作数进行求补码
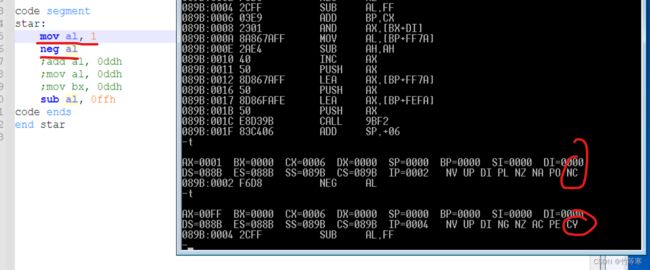
这个操作很有意思:将操作数按位取反后加1,那么由此可知道,我们必然会引起进位,因为取反这个操作将会颠倒你原本的数值,所以从根本上就算你执行了我下面的汇编语句也会影响了CF标志位,按照我们思维来说mov al, 1 , neg al, 也就是对1进行8位的取反加一的时候是不会进位的,但是这种想法只是思考到了加一的那一步会不会影响到CF,但其实取反的这一步的时候已经影响了CF标志位了。因此无论我们是什么操作数,只要执行了NEG指令就会将CF标志位变为1。
-
CMP
这个指令就厉害了,比较是否相等,相等就会将ZF置为1。
CMP ax, bx
原理是:sub ax , bx 但是CMP中不会将结果交给ax,也就是说CMP只是为了影响ZF标志位,如果相等就会相减为0,运算结果为0就会将ZF标志位变为1。正是因为有了这个操作,我们实现条件跳转就很方便了,也就是说我们后面要学习的JMP跳转都是围绕ZF标志位的状态设计出来的。
-
MUL
无符号乘法指令- MUL 8位寄存器/8位内存
这个操作指令会完成:AX = AL × 8位寄存器/8位内存 (记得使用MUL之前修改AL)
没错,在汇编中有时候就是固定了某些指令一定要用到的寄存器,这里就是我们MUL 操作数后,乘法需要两个数字,那么我们给出的操作数需要和AL相乘,然后结果存到AX中,换句话说我们在做乘法指令之前需要写一个指令将另一个乘法数字交到AL中,然后MUL在执行的时候就会默认执行了取出AL数值然后与MUL后面的操作数相乘,将结果存到AX中。为啥是存到AX?因为8位寄存器相乘的结果可能会超出8位,然后两个8位操作数相乘必然不会超过16位,所以用AX来存
为啥一定是AX来存,没有为啥,规定的,这个可能得问写出汇编的的大佬。 - MUL 16位寄存器/16位内存
这个操作指令会完成:DX AX = AX × 16位寄存器/8位内存 (记得使用MUL之前修改AX)
这里固定了AX是另一个乘数,当你使用16位寄存器做乘法的时候就会默认切换到你是使用AX寄存器作为另一个操作数,这时候会发现16位相乘的话最大不会超过32位,所以我们就将高16位存到DX中,低16位存到AX中,使用MUL进行16位乘法的时候这些都不用我们手动操作,执行MUL就会把高16存到DX,低16存到AX。
乘法细节: 乘法对于标志位CF和OF都会影响到,并且OF=CF,这很怪异,我查了很多资料都不知道为什么,最后问了文言一心给出的答案我勉强能够接受:对于无符号乘法,只有CF标志位会被设置,因为无符号数没有溢出的问题。然而,在某些情况下,即使OF和CF的符号不一致,它们也会关联起来。这是因为在某些实现中,OF和CF标志位可能被组合在一起,形成一个统一的溢出/进位标志位。这种设计是为了简化处理流程和提高效率。此外,OF=CF的情况也可能出现在一些特定的硬件实现中。这可能是由于硬件设计者为了优化性能而采取的特定策略。在这种情况下,OF和CF标志位被视为一个整体,它们的值会被综合考虑以确定是否发生溢出或进位。
- MUL 8位寄存器/8位内存
-
DIV
无符号除法指令- DIV 8位寄存器/8位内存
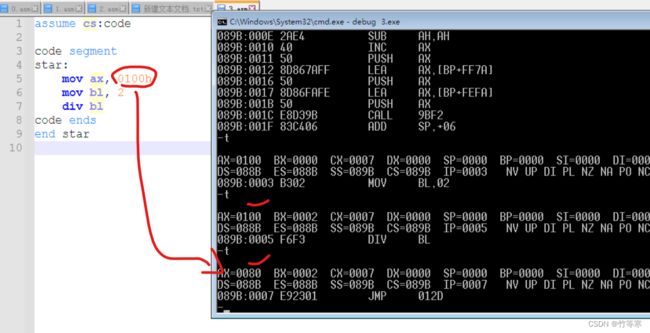
这个操作指令会完成:AL = AX ÷ 8位寄存器/8位内存 ,商会存在AL中,余数会存在AH中。疑惑:万一我的AX是FFFF,那我除以2的话,按照这个说法我商的高8位怎么办,因为我的AL存商,肯定不够存FFFF除以2这个商,这个商是16位的结果,下图我进行了验证,发现这样做溢出,那也就是说我们实质上是:需要保证被除数处完后的结果需要能够存在AH的8位寄存器中,就是说我们进行运算之前还需要考虑结果与位数是否能够存的下才进行除法操作,真的是操心,不过这也很符合汇编的颗粒度。
AX高8位的AH会存我们的余数。

- DIV 8位寄存器/8位内存
-
DIV 16位寄存器/16位内存
这个操作指令会完成: AX = (DX.AX) ÷ 16位寄存器/16位内存 ,商会存在AX中,余数会存在DX中。,(DX.AX)的意思是,DX是余数,但是我们通常被除数是没有余数的,最好是先将DX清零,然后直接将被除数存在AX中即可,这里跟乘法还是有点出入的。
也是余数存在高位,商存在低位,我们将余数存的是DX,商存的是AX。这里和除数是8位的DIV一样,需要考虑除完后的结果是否能够装进AX16位,当然余数不可能在装不下,余数本来就是小于除数才余下来的数。
-
IMUL
IMUL是有符号数的乘法,做法是和MUL一样一样的,只不过有一些细节需要补充,那就是影响的标志位的情况不一样,IMUL中是的标志位是这样表示的:若乘积的高一半是低一半的符号扩展,则表示没有溢出,即CF=OF=0,否则则为1。- 符号扩展:看最高位,最高位是1就往前面补1,补的位数和数字原本的位数一样,比如:原本的数字是0011,扩展后是0000 0011,。再比如:1000 扩展后就是1111 1000,然后,之所以是这样,是因为我们负数是采用补码的形式存储的,为了保证取反加一这个操作能够在符号扩展后不改变必须跟着最高位0还是1来进行扩展。对于符号位扩展解释我给出我的汇编老师课上的PPT解释内容:符号扩展是指用一个操作数的符号位(即最高位)形成另一个操作数,后一个操作数的各位是全0(正数)或全1(负数)。符号扩展不改变数据大小。符号扩展不会改变数值的大小。
回到正题讨论就是当我们的高一半是跟着低一半的最高位的状态的时候就是表示没有溢出进位,是正常的,不然的话就是发生溢出进位,因为符号扩展不会改变数值的大小。
有符号乘法用法同样和无符号一样, 不仅有8位乘法和16位的乘法。
- 操作数为8位的就是:AL × 8位操作数,结果存在AX中
- 操作数为16位的就是:AX × 16位操作数,结果存在DX . AX中,高位是DX,低位是AX
-
IDIV
有符号除法
将被除数
IDIV是有符号数的除法,做法是和DIV一样一样的,只不过有一些细节需要像IMUL一样进行补充,就比如IDIV中涉及到的就是和IMUL一样:标志位是这样表示的:若乘积的高一半是低一半的符号扩展,则表示没有溢出,即CF=OF=0,否则则为1。有符号除法,用法和DIV也一样,
- 操作数为8位的时候:AX ÷ 8位操作数,商存在AL中,余数存在AH中。
- 操作数为16位的时候:(DX . AX) ÷ 16位操作数,商存在AX中,余数存在DX中。同样的,这里的DX是余数,但是作为被除数的他一般都是0,所以可以先进行清零操作,然后将被除数存在AX中。
只不过在IDIV中,因为是有符号的,对于8位操作数除法的时候需要注意结果是否处于-128 ~ +127之间,因为还有一部分是负数的补码形式,使用IDIV之前要考虑到AL是否能装得下你的商,
同理16位操作数除法也是,216 - 1= 65535,切开一半,也就是说考虑有符号的补码范围那就变成了在 -32768 ~ +32765之间。
-
符号指令扩展
我学习的时候甚至想都没想过居然还有这种指令,压根不知道是干嘛的。最神奇的是,他不用操作数,只需要写出这个指令即可,仅仅针对DX/AX/AH/AL/寄存器
按照指令的意思就是:当进行符号扩展后,原本的数字大小值不变。目前好像没啥头绪,等会学完的时候看看能不能总结点什么东西出来…
- CBW
将AL的最高位扩展到AH中,也就是说当AL最高位为1,那么你的AH全是1,按照AL最高位将其扩展到了最高位。同理当AL为0时,那么扩展到AH中的就是AH全为0。- CWD
将AX的最高位扩展到DX中
有何作用?我老师的PPT写出了结论:
解释一下就是:有符号数除法中我们经常需要考虑8位操作数除完后的商是否能够存到AL中,这很麻烦,那么我们就可以利用符号位扩展将其直接扩展8个位,数值不会改变,然后才可以进行DIV AX的操作。
为啥数值不会改变呢?
首先对于有符号的,假设是负数,那他的补码形式最高位是1,所以扩展的时候最高位扩展到AH中都是1,这样就算取反加一获得负数的绝对值的时候数值没有改变,比如1111假设是-1,那么+1就是0001,所以就算我们队1111进行符号扩展到8位的1111 1111 最后取反加一还是等于 0000 0001等于1是不会变的,当然我这里为了方便使用4位扩展到8位,8086最少也要8位。
最后就是对于无符号数除法的作用,无符号的话直接就是将高位扩展为0,而不是根据最高位扩展,这个有点混淆,我个人感觉老师PPT没有讲明白,首先给出一个代码片段
mov al, 11111111b cbw ; 将AL的值进行符号扩展到AX
这里同一个片段可以将al看作有符号也可看做无符号,但是最后结果肯定和你怎么看al有关,无符号高位就用0填充,有符号就看你最高位,不过有符号数的话最高位一般都是1。(我们老师应该是这样理解的:因为计算机都是用补码形式进行,所以最高位是1的基本都是负数有符号,所以在对于有符号中不用担心有没有可能最高位是0,其实根本不用担心,补码中最高位肯定是1)总的来说,在二进制补码中,对于负整数,最高位通常是1,对于非负整数,最高位通常是0。这是因为最高位是符号位,用于表示整数的正负。如果最高位是1,那么这个数就是一个负整数。
解释了这么多,其实回到老师的PPT中解释其实是算是正确的,他抛弃了最底层的原因,而是直接告诉我么结论这么东西。
-
总结:说了这么多废话,其实还是直接用老师的PPT总结是最好不过的,不要太折腾根本原因为好。再次放一遍这张图。

-
细节补充:为啥叫做CBW?为啥叫做CWD?
允许我强行解释一下
C意思是Change
B是byte
W是word
D是dword
所以CBW就是byte扩展到word
而CWD就是word扩展到dword用法就是直接使用CBD或者直接使用CDW,不用加操作数,因为寄存器已经固定好操作哪几个了,所以在此之前是你已经规划好AXAHALDX这些寄存器你才用CBD/CDW这种0操作数指令。
-
逻辑运算指令
- AND
AND 目的操作数,源操作数
首先AND指令会直接将OF = CF = 0
其次,根据结果影响SF,ZF,PF
对于无符号数,即使两个操作数都是无符号数,AND 操作的结果最高位为1时,SF 会被设置为1,如下图所示。然后ZF和PF也是根据结果来影响,这两个就很好理解,只是SF有点疑惑。
- AND
-
OR
或运算,没啥好说的,和AND影响的标志位一样,同样的指令会直接将OF = CF = 0
其次,根据结果影响SF,ZF,PF,SF影响的解释和AND一样。 -
XOR(异或,异为1,同为0)
也没啥好说,和AND影响的标志位一样,同样的指令会直接将OF = CF = 0
其次,根据结果影响SF,ZF,PF,SF影响的解释和AND一样。 -
NOT
这个就搞特殊了,非指令,
NOT指令是一个单操作数指令
NOT指令不影响标志位 -
TEST
我个人认为最好的指令,TEST指令。
对两个操作数执行逻辑与运算,结果不回送到目的操作数
他的做法和CMP一样,不把结果送回目的操作数,只不过CMP做的事情是减法,TEST是逻辑与运算,他也是和AND影响的标志位一样,同样的指令会直接将OF = CF = 0
其次,根据结果影响SF,ZF,PF,SF影响的解释和AND也一样。
为啥我认为是最好的指令呢,首先他也能够TEST方法比较,比如TEST ax, 0001h,这种能够测试最低位是否为1,如果为1那就ZF不等于0,否则就等于0,当然不是只能够测试最低位,你可以按照需求测试,这是TEST中最有用的一个用法,不过我觉得肯定不止这一种用法,不过TEST指令通常用于检测一些条件是否满足,但又不希望改变原操作数的情况 -
移位个数为1的话可以直接写1,超过1就要将移位个数存到CL寄存器中才可以。
- SHL:左移
SHL 目的操作数,CL左移位个数 / 1 - SHR:右移,针对无符号数,移位时候直接补0即可
SHR 目的操作数,CL右移位个数 / 1 - SAL == SHL
- SAR:算术右移,按照最高位是什么就补什么
所有的移位都是:按照移入的位设置进位标志CF。
不影响SF、ZF、PF、AF
如果进行一位移动,则按照操作数的最高符号位是否改变,相应设置溢出标志OF:如果移位前的操作数最高位与移位后操作数的最高位不同(有变化),则OF = 1;否则OF = 0。当移位次数大于1时,OF不确定。(这个不确定就很灵性,我验证了好几个例子,他真的是不确定的,我找不到规律…或许有一天我知道答案了再回来补吧)
顺便解释一下为啥叫做这个名字:SH是shitf转移的意思,加上方向L是left,R是right。 - SHL:左移
-
循环移位(rotate )
- ROL:循环左移,将移出的位压进CF中,然后同时将移除的位压进这个数的最低位,同时这个字很关键,用来区分后面的RCL。
- ROR:循环右移,将移出的位压进CF中,然后同时将移除的位压进这个数的最高位,,同时这个字很关键,用来区分后面的RCR。
- RCL:带位循环左移,首先将上一条指令不管是否影响了的CF的值压进最低位,然后才是将移出的位压进CF,如此循环。
- RCR:带位循环右移,首先将上一条指令不管是否影响了的CF的值压进最高位,,然后才是将移出的位压进CF,如此循环。
解释为啥叫做这个名字:RO是rotate的意思,后面加上移位方向,ROL left,ROR right,那RC是rotate + CF ,后面加上移位方向,RCL left,RCR right。
控制转移类指令(重点)
这里我认为最重要的不是记住,而是当你看到他指令的长什么样子能够通过自己稀巴烂的英文水平看出他是干嘛的,或者可以反过来运用,当你忘记某个转移指令的时候可以通过英文组合来尝试用一下是不是这么写。(特别是到了条件转移指令那里,只要掌握了规律一看就知道这跳转是根据什么来跳转的了。)
控制转移类指令通过改变IP(和CS)值,实现程序执行顺序的改变
-
JMP r16/ m16( r 是寄存器, m 是内存)
JMP改变的是CS或者IP,IP是十六位寄存器所以肯定是使用16位的操作数。- 段内转移 near/short :在没有使用short关键字的情况下,默认的jmp指令通常是近跳转,这是相对于当前代码段的绝对跳转。我们近转移可以不用写出near,这一点很重要
但是我们转移希望不混淆的话还是需要指明:
JMP short r16/m16,JMP near的写法不要忘记了,可以是不写默认的
near是附近转移即段内,near 近转移是表示可以在整个段内范围(只需要知道段内范围都可以转移)
short是短转移,短到只可以在-128~+127内转移- 内存的段内转移:JMP word ptr 内存
- 段间转移:需要使用far,即类似JMP far ptr 标号
- 内存的段间转移:JMP dword ptr 内存
- 段内转移 near/short :在没有使用short关键字的情况下,默认的jmp指令通常是近跳转,这是相对于当前代码段的绝对跳转。我们近转移可以不用写出near,这一点很重要
-
最后:告诉你其实上面都是扯蛋,可以不写,JMP在MASM编译过程中会自动帮你选好跳转范围,也就是说你不用特定指明直接使用JMP的话编译中会帮你生成对应的转移方式。
总结:实际编程时,MASM汇编程序会根据目标地址的距离,自动处理成短转移、近转移或远转移
但是你非得这样做也是可以的,根据你需求来写明白short还是far强制指明。
所以我们以后编程都是使用JMP即可,不用折腾自己还特地去指明范围跳转。(你是写内核的大佬的话也不会来看我这烂文章了)
条件转移指令
条件转移不会影响标志位,因为他是利用标志位进行转移的。
- 根据一个标志位进行转移的。
寻找规律:JZ中,我们J就是JMP,JMP条件是看Z,Z是ZF,那也就是说当ZF等于1的时候,即运算结果为0的时候JZ r16/m16就会跳转到你指定的位置去。
同理JE,E是equal的意思,相等的意思,相等就是比较,CMP比较是影响ZF的,所以换句话说当相等的时候结果为0,即ZF为0,所以说JZ等于JE
下面的JNZ意思是not ZF ,就是和JZ相反,以后看到N字眼一般都可以往not方向猜测,所以JNZ意思就是当ZF不是等于1的时候转移,就是ZF等于0跳转
JS,S是SF标志位,所以他会在SF等于1的时候跳转,JNS同上解释,not SF
JP,PF标志位
等等,下图其实你知道规律后来看基本都知道通过什么条件跳转了。

- 根据两个操作数比较大小来判断
了解了上面的规律后,在这里依旧可以使用
JB(咳咳,不是那个JB),B就是below意思是小于的意思,CF=1的话就表示借位了,所以就是小于的意思,通过CF=1就可以知道是below,JB,这时候有人就会说:哎呀,那万一我是进位怎么办?这时候我会一脚踹过去,你都用JB了,你上一条指令不是比较指令的话你用JB干嘛,JB本来就是因为你上条指令用了CMP导致CF等于1或者不等于1,你需要用这个来判断的时候采用的JB,而不是你做了加法操作还在这用JB指令,所以别再问这种JB问题了,汇编就是通过各种指令组合搭配使用的。
大于的话就是JA,不大于就是JNA,A就是above,但是这个是针对无符号数的。
以此类推下面的都是一样的。

下面两张图我都圈出符合人类思维的指令,不要为难自己去记忆那几个长得恶心的指令。
- 无符号比较的转移指令(A = Above高于 B = Below低于)
- 下面是有符号数的比较转移指令。(G= Greater大于 L = Less小于)


- 我对于为什么区分有符号和无符号跳转指令的理解:
首先是无符号不需要看OF标志位,有符号需要看,基本没啥疑义。
应该如何记忆或者说我怎么知道哪个是有符号用的无符号用的呢?
只能强行理解了,在无符号转移指令中,我们通过英文字符可以知道Above 是高于的意思,也就是说无符号数可以理解为一高一低,因为没有符号的话就是只有更大没有最大,所以使用了Above,反义词就是Below了,反观有符号数转移指令的话,英文字母是Greater是大于意思,是否大于这个词就是从小学到大的,所以只能强行理解为是用在有符号中,负数大于正数,反义词就是Less小于,这个确实没办法。
总结口诀就是:高低是无符号,大小是有符号。
提问:JCXZ xxxx是什么意思?
↓
↓
↓
↓
答案:当CX=0的时候跳转到xxxx位置
-
循环指令(最简单的:LOOP)
汇编代码:S: xxx LOOP S- LOOP:当CX不为0的时候循环,上面的例子就是当CX不为0的时候跳到S标志中
- LOOPZ:Z不用说了,脑海里第一时间猜的肯定是ZF,当然就是ZF,LOOPZ意思是CX不等于0的同时,当ZF=1的时候跳转到指定标签处。
- LOOPNZ:not ZF ,意思是CX不等于0的同时,当ZF不等于1的时候跳转到指定标签处。
-
子程序指令(我喊他叫做:函数调用指令)
-
CALL
CALL的细节:在使用CALL后,分为两种
第一种:段内只需要改变IP,CALL完后默认执行下面的命令
PUSH IP
JMP near 标号(简单理解即可,还有很多格式不止near标号,我要吐了)
第二种:段间需要改变CSIP
PUSH CS
PUSH IP
JMP far ptr 标号

-
RET/RETF
RET是返回,其实是和CALL搭配使用的,既然CALL将地址PUSH进来了,那RET工作就是POP出地址进行原路返回。
RET的使用场景和使用细节:
第一种:RET执行了后,会默认执行下面的指令:
POP IP
这里不用JMP了,是因为我们直接将IP修改了,CALL是保存IP,所以修改完IP后,下一条指令就会根据IP跳转。
第二种:RETF,用于段间远返回,其实就是需要pop出CS而已,执行完该指令会默认执行下面的指令:
POP IP
POP CS
同理不用JMP跳转,修改完CSIP下一条就直接返回去了。
-
CALL和RET/RETF的搭配使用,这里应该很明显了
因为CALL完后保存了当前指令的下一条指令地址PUSH进去了栈,所以在返回的时候只需要POP出来即可,所以一般使用RET/RETF进行返回。当然也可以自己保存CSIP然后手动JMP,调用完后记得POP出CSIP即可。
人生苦短,用指令不好过自己写?
补充:
- NOP空操作
- LOCK ;封锁总线(这个老师PPT教的,涨芝士了)
这是一个指令前缀,可放在任何指令前
这个前缀使得在这个指令执行时间内,8086 处理器的封锁输出引脚有效,即把总线封锁,使别的控制器不能控制总线;直到该指令执行完后,总线封锁解除。
指令系统能和计组的指令系统有的一拼了,
虽然不是一个东西,但都是这么恶心。。。。
果然所有编程语言都是需要实战才记得住。
:
END.