【基础论文笔记二】Transfer Learning with Dynamic AdversarialAdaptation Network(2019 ICDM)动态对抗适应网络的迁移学习论文笔记
背景
现有的对抗性领域自适应方法要么学习单个领域鉴别器来对齐全局源和目标分布,要么关注基于多个鉴别器的子域对齐。然而,在实际应用中,域之间的边际(全局)分布和条件(局部)分布对适应的贡献往往不同。在本文中,作者提出了一种新的动态对抗性自适应网络(DAAN)来动态学习域不变表示,同时定量评估全局和局部域分布的相对重要性。
DAAN架构
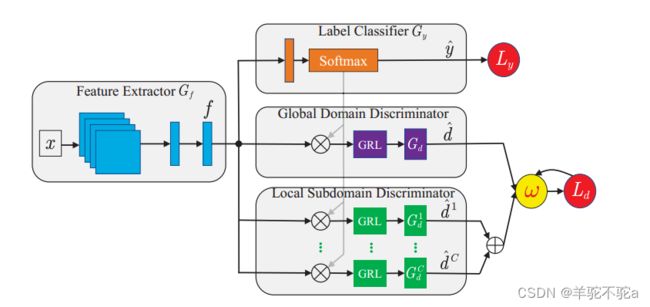
在DAAN中,高级特征f由特征提取器(Gf,蓝色部分)提取。然后,分别通过全局域鉴别器(Gd,紫色部分)和局部域鉴别剂(Gc-d,绿色部分)来实现边缘分布和条件分布的自适应。 加号运算符,而⊗是乘积运算符。f是提取的深度特征,
加号运算符,而⊗是乘积运算符。f是提取的深度特征, 是预测的标签,
是预测的标签,![]() 和
和 是分类损失和领域损失。
是分类损失和领域损失。 和
和![]() 是预测的域标签。GRL代表梯度反转层。最重要的是,DAAN提出了一种新的动态对抗因子(ω,黄色部分)来对这两种分布进行简单、动态和定量的评估。与标签分类器(Gy,橙色部分)一起,可以使用梯度反转层(GRL)有效地训练DAAN的参数。
是预测的域标签。GRL代表梯度反转层。最重要的是,DAAN提出了一种新的动态对抗因子(ω,黄色部分)来对这两种分布进行简单、动态和定量的评估。与标签分类器(Gy,橙色部分)一起,可以使用梯度反转层(GRL)有效地训练DAAN的参数。
对比MEDA方法:一种流形嵌入分布对齐(MEDA)方法来计算边际分布和条件分布的权重,旨在自适应对齐两种分布,但具有以下问题:
1)需要训练c+1个额外线性分类器,这既昂贵又耗时。
2)它只能适应小的数据集
3)且由于每次都要计算所有样本的伪逆,所以无法在线部署。
因此,在系统仍然可以扩展到大规模数据的同时,如何轻松、动态和定量地评估这两种分布的相对重要性是必要的,由此提出本文的DAAN结构。
损失函数
标签分类器:

训练目标是交叉熵损失函数,其中C是类的数量,Pxi→c是xi属于c类的概率,Gy是标记分类器,Gf是特征提取器。
全局域鉴别器

其中,Ld是域鉴别器损失(交叉熵),Gf是特征提取器,di是输入样本xi的域标签。
局部域鉴别器
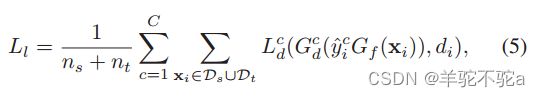
域鉴别器![]() 可以分为C类域鉴别符
可以分为C类域鉴别符![]() ,每个
,每个![]() 负责匹配与C类相关联的源域和目标域数据。标签预测器
负责匹配与C类相关联的源域和目标域数据。标签预测器![]() 到每个数据点
到每个数据点 的输出可以用于指示C域鉴别器
的输出可以用于指示C域鉴别器![]() 、C=1、…C。其中
、C=1、…C。其中![]() 和
和![]() 分别是域鉴别符及其与C类相关的交叉熵损失。
分别是域鉴别符及其与C类相关的交叉熵损失。![]() 是输入样本的c类上的预测概率分布,
是输入样本的c类上的预测概率分布, 是输入采样的域标记。
是输入采样的域标记。
动态对抗因子ω
在DAAN中,我们将全局域鉴别器的全局A-distance 表示为:
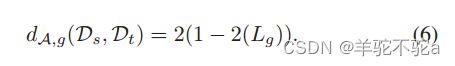
局部A-distance :

其中![]() 和
和![]() 表示来自类c的样本,
表示来自类c的样本,![]() 是类c上的局部子域鉴别器损失。最终,动态对抗因子ω可以估计为:
是类c上的局部子域鉴别器损失。最终,动态对抗因子ω可以估计为:
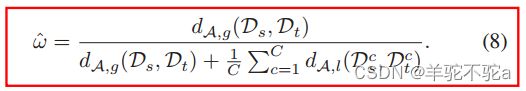
不需要显式地构建额外的分类器来计算局部距离。ω在第一个epoch中被初始化为1。在每个epoch之后,可以获得目标域的伪标签。然后,类c的局部距离可以很容易地计算为:
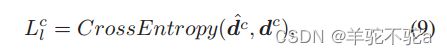
其中,![]() =[
=[![]() ;
;![]() 是第c个域鉴别器
是第c个域鉴别器![]() 输出的预测的级联,并且
输出的预测的级联,并且![]() =[0;1],其中0∈
=[0;1],其中0∈![]() ×1和1∈
×1和1∈![]() 是真实域标签的级联(假设源域具有标签0,目标域具有标签1)。类似地,可以获得全局距离。动态对抗因子的计算可以在每次迭代历元之后执行。最终,随着训练的收敛,DAAN将学习到一个相当强大的动态对抗因素。
是真实域标签的级联(假设源域具有标签0,目标域具有标签1)。类似地,可以获得全局距离。动态对抗因子的计算可以在每次迭代历元之后执行。最终,随着训练的收敛,DAAN将学习到一个相当强大的动态对抗因素。
总的目标函数
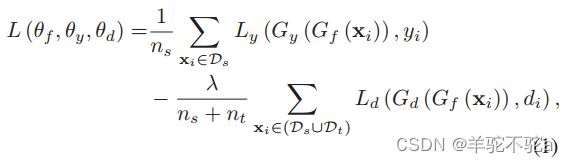
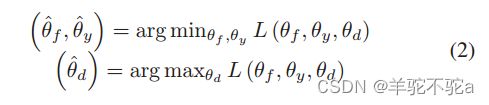
其中参数:
特征提取器Gf的参数θf和标签分类器Gy的参数θy,是通过最大化域鉴别器Gd的损失来学习的(最小化L,即最大化),而Gd的参数θd是通过最小化域鉴别器的损失来训练的(最大化L,即最小化)。
最后总的目标函数
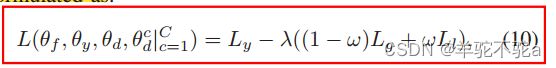
当ω→ 0,这意味着全局分布对齐更重要,DAAN将退化为DANN。当ω→ 1,这意味着两个域之间的全局分布相对较小,因此每个类的局部子域分布占主导地位,DAAN将退化为MADA。
对ω,只需要运行整个网络一次,并且DAAN不需要训练额外的线性分类器。
代码部分
import torch.nn as nn
from torch.nn import init
from torch.autograd import Variable
from functions import ReverseLayerF
from IPython import embed
import torch
import model.backbone as backbone
class DAANNet(nn.Module):
def __init__(self, num_classes=65, base_net='ResNet50'):
super(DAANNet, self).__init__()
'''提取source和target数据的特征,并将这些特征向量映射到更低维度的表示,这些表示通过两个线性层(self.source_fc)传递,以预测输入数据属于哪个类别。然后,通过softmax函数对输出的分类概率进行归一化处理,确保它们总和为1。
'''
self.sharedNet = backbone.network_dict[base_net]()
self.bottleneck = nn.Linear(2048, 256)
self.source_fc = nn.Linear(256, num_classes)
self.softmax = nn.Softmax(dim=1)
self.classes = num_classes
# global domain discriminator
self.domain_classifier = nn.Sequential()
self.domain_classifier.add_module('fc1', nn.Linear(256, 1024))
self.domain_classifier.add_module('relu1', nn.ReLU(True))
self.domain_classifier.add_module('dpt1', nn.Dropout())
self.domain_classifier.add_module('fc2', nn.Linear(1024, 1024))
self.domain_classifier.add_module('relu2', nn.ReLU(True))
self.domain_classifier.add_module('dpt2', nn.Dropout())
self.domain_classifier.add_module('fc3', nn.Linear(1024, 2))
# local domain discriminator
'''定义了一个名为"dcis"的序列化神经网络,由多个"dci"神经网络组成的,每个"dci"神经网络用于对一个类别进行域分类。这样,"dcis"神经网络可以同时对多个类别进行域分类'''
self.dcis = nn.Sequential()
self.dci = {}
for i in range(num_classes):
self.dci[i] = nn.Sequential()
self.dci[i].add_module('fc1', nn.Linear(256, 1024))
self.dci[i].add_module('relu1', nn.ReLU(True))
self.dci[i].add_module('dpt1', nn.Dropout())
self.dci[i].add_module('fc2', nn.Linear(1024, 1024))
self.dci[i].add_module('relu2', nn.ReLU(True))
self.dci[i].add_module('dpt2', nn.Dropout())
self.dci[i].add_module('fc3', nn.Linear(1024, 2))
self.dcis.add_module('dci_'+str(i), self.dci[i])
def forward(self, source, target, s_label, DEV, alpha=0.0):
source_share = self.sharedNet(source)
source_share = self.bottleneck(source_share)
source = self.source_fc(source_share)
p_source = self.softmax(source)
'''函数从target数据的预测标签(t_label)中获取最大值,并将其视为target数据的预测类别。最后,函数创建了两个空列表,s_out和t_out,以保存source和target数据在各自的域分类器中的预测结果'''
target = self.sharedNet(target)
target = self.bottleneck(target)
t_label = self.source_fc(target)
p_target = self.softmax(t_label)
t_label = t_label.data.max(1)[1]
s_out = []
t_out = []
if self.training == True:
# RevGrad
s_reverse_feature = ReverseLayerF.apply(source_share, alpha)
t_reverse_feature = ReverseLayerF.apply(target, alpha)
s_domain_output = self.domain_classifier(s_reverse_feature)
t_domain_output = self.domain_classifier(t_reverse_feature)
# p*feature-> classifier_i ->loss_i
'''函数使用每个类别的分类概率(p_source和p_target)来加权源域和目标域的共享特征,以获得类别特定的特征向量(fs和ft)。然后,它将这些特征向量输入到对应的类别的域分类器(self.dcis[i])中,并将输出结果(outsi和outti)添加到s_out和t_out列表中,以便计算多标签分类损失。'''
for i in range(self.classes):
ps = p_source[:, i].reshape((target.shape[0],1))
fs = ps * s_reverse_feature
pt = p_target[:, i].reshape((target.shape[0],1))
ft = pt * t_reverse_feature
outsi = self.dcis[i](fs)
s_out.append(outsi)
outti = self.dcis[i](ft)
t_out.append(outti)
else:
s_domain_output = 0
t_domain_output = 0
s_out = [0]*self.classes
t_out = [0]*self.classes
return source, s_domain_output, t_domain_output, s_out, t_out损失函数
from loss_funcs.adv import *
class DAANLoss(AdversarialLoss, LambdaSheduler):
def __init__(self, num_class, gamma=1.0, max_iter=1000, **kwargs):
super(DAANLoss, self).__init__(gamma=gamma, max_iter=max_iter, **kwargs)
self.num_class = num_class
'''局部判别器'''
self.local_classifiers = torch.nn.ModuleList()
for _ in range(num_class):
self.local_classifiers.append(Discriminator())
self.d_g, self.d_l = 0, 0
self.dynamic_factor = 0.5
'''需要源域和目标域经过分类器预测的source_logits和target_logits作为BCELOSS的输入求出源域的全局损失和local 损失,目标域也是如此。最后计算得出源域和目标域的全局损失和local损失。'''
def forward(self, source, target, source_logits, target_logits):
lamb = self.lamb()
self.step()
source_loss_g = self.get_adversarial_result(source, True, lamb)
target_loss_g = self.get_adversarial_result(target, False, lamb)
source_loss_l = self.get_local_adversarial_result(source, source_logits, True, lamb)
target_loss_l = self.get_local_adversarial_result(target, target_logits, False, lamb)
global_loss = 0.5 * (source_loss_g + target_loss_g) * 0.05
local_loss = 0.5 * (source_loss_l + target_loss_l) * 0.01 #得到的值是所有类的总和,最后要除类总数,得到一个子类loss的平均值
#定义全局和局部A距离
self.d_g = self.d_g + 2 * (1 - 2 * global_loss.cpu().item())
self.d_l = self.d_l + 2 * (1 - 2 * (local_loss / self.num_class).cpu().item())
adv_loss = (1 - self.dynamic_factor) * global_loss + self.dynamic_factor * local_loss
return adv_loss
def get_local_adversarial_result(self, x, logits, c, source=True, lamb=1.0):
loss_fn = nn.BCELoss()
x = ReverseLayerF.apply(x, lamb)
loss_adv = 0.0
for c in range(self.num_class):
logits_c = logits[:, c].reshape((logits.shape[0],1)) # (B, 1)
features_c = logits_c * x
domain_pred = self.local_classifiers[c](features_c) #类分类器使用对应类的数据
device = domain_pred.device
if source:
domain_label = torch.ones(len(x), 1).long()
else:
domain_label = torch.zeros(len(x), 1).long()
loss_adv = loss_adv + loss_fn(domain_pred, domain_label.float().to(device))
return loss_adv
#更新dynamic_factor动态对抗因子w
def update_dynamic_factor(self, epoch_length):
if self.d_g == 0 and self.d_l == 0:
self.dynamic_factor = 0.5
else:
self.d_g = self.d_g / epoch_length
self.d_l = self.d_l / epoch_length
self.dynamic_factor = 1 - self.d_g / (self.d_g + self.d_l)
self.d_g, self.d_l = 0, 0