计算机图形学的魔法的概述篇(四)
| 基于图像的方法 在先前计算机图形学的魔法的概述篇系列文章中,我们 introduce 基于光传输的物理原理再现了物体的外观。在20世纪90年代,一种新的逼真的渲染被提出,它试图直接从图形中恢复物体的外观,他被称为一种基于图像的渲染方法。 大概的意思为:"由于照片已经包含了真实世界的光交互所产生的效果,从照片中提取的信息可以代替基于物理的计算" 。 基于图像的渲染 In the broadest sense(最广泛的意义上),Image-based rendering(IBR)是指任何依赖于现有的图像渲染的方法,而近些年,这个术语(Image based Rendering)指的是所获得图像集合从任意的角度恢复物体或环境的外观的特殊问题。这些图像本身可能是渲染的图像,但他们通常来自于照片。 Stereo 从照片中恢复三维模型是摄影测量的一种形式。这是从照片中确定几何形状的一般做法。摄影测量学早于计算机图形学;事实上,它几乎和摄影本身一样古老。从不同视角拍摄的照片组合中获得一个物体的三维坐标的过程被称为 stereophotogrammetry 。1913年,[E. Kruppa]证明了立体摄影测量的一个基本结果:五个不同点的两个不同的视角图像足以确定两个视点的相对位置和方向,以及五个点的三维坐标(在某些任意坐标系中)。然而,这个定理假设图像来自一个理想的透视投影,而真正的相机无法提供。摄影测量学在其他学科中也被积极地研究过,如计算机视觉。立体摄影测量的过程包括以下三个步骤:1 camera calibration 2 stereo correspondence, and 3 stereo reconstruction. 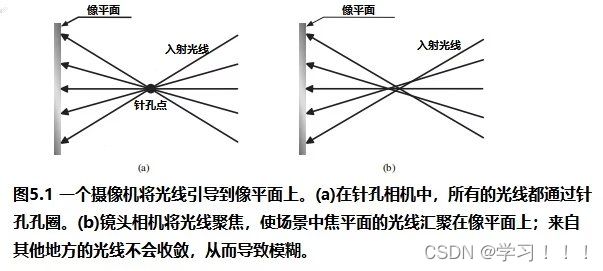

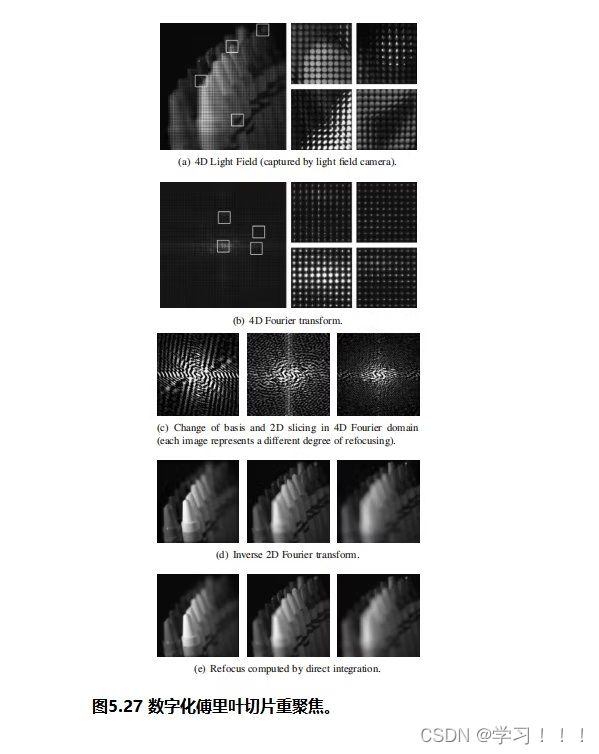
假设I0是从一个视点捕获的数字化图像,而I1是从附近的视点捕获的二次图像。从主图像I0(x,y)处的像素对应于I2中图像莫一个点处。一种简单的方法是通过在I2中搜索与I0中(x,y)处具有相同颜色的像素。但问题是由于光照变化,噪声,模糊等成像问题,对应点的像素颜色不太可能相同。此外,在I0中的像素也有可能在I1中被遮挡。解决方案: 基于一种局部平均的搜索,它工作在假设I0中(x,y)附近的像素领域对应于被一个I1中的一个像素偏移向量(dx,dy)所替代,当像素差的平方和最小时,最匹配。 邻域是一个宽为2wx +1和2wy +1的矩形区域,中心为I0的(x,y)和I1的(x + dx,y + dy)。在搜索点停留在图像I1内的限制下,最小值将接管所有的(dx,dy)。这个邻域搜索假设图像的尺度和方向本质上是相同的。如果一幅图像相对于另一幅图像旋转,搜索也必须包括邻域的旋转。  Optical Flow(光流) Optical Flow(光流)当电影或者动画中播放连续帧的时候,主图像和次图像可能足够的相似,以实现自动立体对应。然而图像的差异可能来自物体在帧之间的运动以及相机的运动,所以上面的方法不一定适用。跟踪帧间对应点的一般问题称为光流。 光流在计算机视觉中得到了广泛的研究;Beauchemin和Barron提出了一个光流算法的调查[Beauchemin and Barron 95].基本问题是在主图像i0上构造一个向量场,其中每个点上的向量指向二次图像i1中的对应点。这个矢量场被称为二维运动场,光流有时被称为图像速度的计算。实际的运动场可能非常复杂;事实上,它甚至没有定义那些在图像之间可见或不可见的点。一般的光流问题是寻找真实运动场的近似值。 对于一个光栅画的图像,运动场变成了一个离散的向量场,每个像素的向量函数d(x,y):如果d(x,y)=(dx,dy),I0中的像素(x,y)近似对应于I1中的像素(x+dx,y+dy)(下图)。定义光流矢量d(x,y)的一种方法是在一个固定大小的邻域中最小化像素差的平方,如式(5.1)所示。也就是说,选择一个特定像素(x,y)的dx和dy的值,从而使E(dx,dy)最小化。 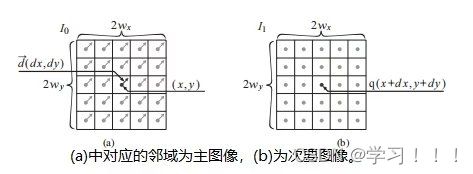 修正向量的计算因此简化为一个可以用标准方法来解决的最小二乘问题。其他方法则使用图像梯度或高阶近似值来判断像素的实际变化方式。 修正向量的计算因此简化为一个可以用标准方法来解决的最小二乘问题。其他方法则使用图像梯度或高阶近似值来判断像素的实际变化方式。图像金字塔法可以改进光流计算。原始图像被重复降采样,以创建一系列尺寸减小的图像,可以被认为是一种金字塔(下图)。就像mip映射的构造(计算机图形学中的魔法(二))一样,每个像素都是上一层上四个像素块的平均值。因此,该序列中的每个图像的分辨率都是前一幅图像的一半。为图像I0和I1构造了一个金字塔。偏移向量场的计算应用于从顶部开始的金字塔的每个层次。在顶层,图像已经被减少到只有几个像素,偏移向量是直接计算。在下一个更精细的级别上,每个像素的计算向量被复制到更精细的级别上的相应的四个像素的块中(下图最左边的)。在更精细的层次上的向量场,然后是一个更新这些偏移量的问题。该过程停止在最佳级别,这对应于原始图像。当帧之间的运动相对较大时,图像金字塔特别有效。然而,无论采用何种方法,遮挡的存在都会造成困难,因为像素会滑移。一般来说,不连续是由不连续的运动还是照明的不连续的变化引起的,都是光流计算的一个严重问题。 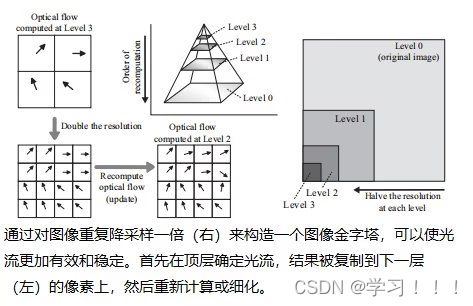 光流测定有许多应用。视频压缩就是其中之一。如果光流在几个连续帧之间变化很小,则可以通过从相邻帧的偏移向量中插值像素来重建中间帧,因此不需要存储中间帧。一些当代的高端数字电视系统也做了类似的事情,采用了一种与这种方法相反的方法来创造更平滑的运动。这些电视能够以比交付的视频帧更高的速度显示帧。通过插值运动场,可以构造出真实帧之间的近似帧。插入这样的帧可以使运动看起来更流畅,尽管这种技术的有效性取决于视频的性质。 Refined Version of Stereo Correspondence(完善版本的立体对应)   立体对应的方法传统上假设图像是相似的。由Peter Sand 和 Seth Teller撰写的题为“Video Matching”的论文介绍了一种技术,它适用于具有本质上不同外观的图像[Sand and Teller 04]。本文所描述的研究的目的是如何获得分别捕获的两个相似的视频序列之间的对应关系,尽管是从相似的观点。在不同时间捕获的两个相似环境的序列可能有不同的原因:光照条件可能不同,场景可能有一些微小的变化,如添加或删除元素,相机位置不太可能相同。图5.6顶部的两个图像提供了一个示例。左侧图像中的茶壶在右侧图像中缺失;此外,图像之间的相机位置略有变化。人类观察者可能会看到这些图像非常相似,但单个像素的变化显著到足以给自动像素对应带来麻烦。 立体对应的方法传统上假设图像是相似的。由Peter Sand 和 Seth Teller撰写的题为“Video Matching”的论文介绍了一种技术,它适用于具有本质上不同外观的图像[Sand and Teller 04]。本文所描述的研究的目的是如何获得分别捕获的两个相似的视频序列之间的对应关系,尽管是从相似的观点。在不同时间捕获的两个相似环境的序列可能有不同的原因:光照条件可能不同,场景可能有一些微小的变化,如添加或删除元素,相机位置不太可能相同。图5.6顶部的两个图像提供了一个示例。左侧图像中的茶壶在右侧图像中缺失;此外,图像之间的相机位置略有变化。人类观察者可能会看到这些图像非常相似,但单个像素的变化显著到足以给自动像素对应带来麻烦。Sand和Teller的图像对应方法考虑了两个独立的方面:像素匹配一致性的度量和运动一致性的度量。像素匹配的方式类似于基本立体关联,上述证明方法,除了不是比较邻域中对应的像素,而是将主图像中的像素与辅助图像中候选位置上的像素的3×3邻域进行比较。作者们使用了一个技巧来有效地做到这一点。3×3邻域的最小和最大像素值作为二次图像的一种滤波器;结果是包含预先计算的局部极大值和最小值的“最大”和“最小”图像。图5.7在图像的一个代表性切片上说明了这些问题。从这些图像中,得到的价值 任何像素匹配方法的一个问题都出现在图像中像素值之间变化很小的区域,即在颜色一致的区域。图5.6图像中右边的文件文件夹就是一个很好的例子;像素匹配在这个区域用处。这种区域可以通过使用一种特征提取的形式来避免:像素匹配仅限于图像中相邻像素有显著变化的部分,例如,在角和边缘。图5.6(c)显示了作者所使用的特征提取方法所得到的区域。将像素匹配限制在这些区域内有助于避免不匹配。图的第(d)部分显示了相应的偏移向量,用概率着色。浅灰色显示的向量具有较低的像素匹配概率。 算法的第二部分,运动一致性估计,考虑了偏移向量在相邻像素之间的匹配程度。该信息用于构造一个光滑的最终对应向量场。当偏移向量在一个区域的像素之间匹配良好时,可以预期平均偏移向量可以很好地表示一般的光流。可以做的一件事是将偏移向量拟合到两幅图像之间的全局投影变换中,这将对应于不同的相机位置。然而,这些图像并没有被假设为纠正相机失真,所以作者使用了一种更一般的技术。该方法使用一种称为局部加权线性回归的方法,将局部光滑函数拟合到偏移向量上。像素匹配概率作为偏移量的权重:对像素匹配概率最高的向量的权重最大。 作者采用了一种迭代的方法来计算最终的对应向量场。通过回归对初始匹配进行平滑,然后从这些平滑向量中重新计算像素匹配概率(在此过程中应用了计算机视觉的其他技术)。图5.6(e)显示了该结果。重复这个过程可以改进对应字段和消除不正确的偏移向量(图5.6(f)),所以这个过程就会被重复,直到没有更多的改进结果。此时,可以构造最终的对应字段(图5.6(g))。实际的二次图像与通过外推对应域计算出的估计图像之间的差异如图5.6所示。像素在它们匹配的地方是最暗的。如预期的那样,没有在茶壶上找到任何针对像素的匹配项。 stereo Reconstruction(立体重建)  如前所述,立体对应是图像之间的点匹配问题。一旦匹配了点,就可以使用它们位置的差异来近似它们所对应的场景中的点的3D位置。这就是立体重建的问题。基本问题是在投影到两个不同图像中的点x1和x2的环境中找到点x的3D坐标。图5.8说明;注意与核极几何的联系 如前所述,立体对应是图像之间的点匹配问题。一旦匹配了点,就可以使用它们位置的差异来近似它们所对应的场景中的点的3D位置。这就是立体重建的问题。基本问题是在投影到两个不同图像中的点x1和x2的环境中找到点x的3D坐标。图5.8说明;注意与核极几何的联系立体声重建需要外部的摄像机参数,即在拍摄图像时,摄像机的位置和方向。在图5.8中,c1和c2是每个摄像机的视点。图像平面的位置和方向用变换矩阵P1和P2表示,它们将二维图像坐标映射到环境中的三维坐标。点x满足 在实践中,立体重建应用于一组点的集合,如真实场景中的一组特征点。其目标是通过估计顶点坐标来重建(或创建)一个底层模型。这需要在所有点的估计中最小化误差,这可以表述为一个大的最小二乘系统。但根据特定问题的假设,它可能不是一个线性系统,在这种情况下,非线性优化技术必须应用。一般来说,恢复坐标的精度随着不同视点图像数量的增加而增加,但优化问题的大小也会增加。一种常用的安排是将相机沿着正交轴放置,放置在物体或模型的前、后、左、右和顶部。如果相机的焦距或相机位置之间的距离已知,则可以确定模型的尺度。 Image Based Modeling and Rendering 基于图像的建模和渲染 1996年,Paul E. Debevec, Camillo J. Taylor, and Jitendra Malik 出版了“Modeling and Rendering Architecture from Photographs: A Hybrid Geometry and Image-based Approach,”它将现有的基于图像的渲染技术系统化为基于图像的建模和渲染[Debevecet al. 96]. 。基于图像的建模和渲染的管道是直观和高效的,因此该技术迅速扩展到电影和音乐视频的制作中。Debevec本人也很兴奋地能将这项技术应用于电影制作中。 基于图像的建模和渲染的起源 Debevec 说,他在1996年发表这篇论文的动机是为了在加州大学伯克利分校创作一个绕着钟楼飞行的动画,他当时就在那里学习。因此,本文介绍了专门用于创建动画的工具。Debevec将这个动画包括在他执导的一部名为钟楼电影的短片中,这部短片被包括在电子剧院(钟楼是伯克利的钟楼的名字)。第二年,参与短片创作的学生们参与了将图像渲染应用到电影< 基于图像的建模与渲染的流水线 由Debevec,Taylor, and Malik在1996年的论文中提出的呈现方法的过程包括一个三个阶段的过程,或称为管线,描述如下。 Stage 1. 这一阶段的目标是从被捕获的照片中构建一个场景的近似建筑模型。这不是自动化的——它需要一个使用专门软件的人进行大量的试验和错误。该软件帮助用户构建模型并将其与图像进行匹配。本阶段的模型假设相当简单,由简单的几何原语组成。原语是参数化的多面体“块”,以一个由软件维护的层次结构排列。块的参数,如高度和宽度等值,是可以连接在一起并以便于将模型与捕获的图像匹配的方式进行约束的变量。  用户首先在捕获的图像中标记与边缘对应的粗糙模型中的边缘,然后创建模型并列出参数。然后,该软件进行立体重建工作,并将重建模型投影到图像上。然后,用户进行任何调整并执行另一个重建,并在必要时重复这个过程。图5.9说明了这个过程:(a)部分显示了用户标记的线,部分(b)显示了恢复的模型(c)显示了在图像上的投影。只有一个较低的尖塔被标记;模型几何确保它在其他三个角被正确复制。  本文所描述的重建算法是将模型边缘与用户手动选择的图像中相应的观测边缘进行匹配。图5.10(a)展示了投影到被捕获图像的图像平面上的三维场景边缘的投影。包含投影边缘的线是图像平面与摄像机视点的平面的交点。摄像机坐标系由旋转矩阵R和平移向量t表示;如果v为三维线的方向向量,d是线上的任意点,则该平面的法向量为 本文所描述的重建算法是将模型边缘与用户手动选择的图像中相应的观测边缘进行匹配。图5.10(a)展示了投影到被捕获图像的图像平面上的三维场景边缘的投影。包含投影边缘的线是图像平面与摄像机视点的平面的交点。摄像机坐标系由旋转矩阵R和平移向量t表示;如果v为三维线的方向向量,d是线上的任意点,则该平面的法向量为 水平边和垂直边有一个已知的方向v。如果有足够多的这些模型,就像在任何真实的建筑模型中一样,在所有这些边缘上的公式(5.4)的最小二乘最小化可以提供对所有相机旋转的良好估计。一旦计算出这些,就通过最小化公式(5.5)来估计相机平移和剩余参数。这些估计可以作为数字优化器的初始猜测。非线性优化并不容易,而且参数越多就会变得越困难。因此,在这个阶段的模型要相当简单是很重要的。几何细节在最后阶段添加到初始粗糙模型中。 水平边和垂直边有一个已知的方向v。如果有足够多的这些模型,就像在任何真实的建筑模型中一样,在所有这些边缘上的公式(5.4)的最小二乘最小化可以提供对所有相机旋转的良好估计。一旦计算出这些,就通过最小化公式(5.5)来估计相机平移和剩余参数。这些估计可以作为数字优化器的初始猜测。非线性优化并不容易,而且参数越多就会变得越困难。因此,在这个阶段的模型要相当简单是很重要的。几何细节在最后阶段添加到初始粗糙模型中。 Stage 2.视图相关的纹理映射(VDTM):将捕获的图像映射到恢复的模型。最终的目标是从一个任意的观点重新呈现模型。假设这些图像是在大致相同的光照条件下被捕获的。然而,被建模的物体的表面不太可能表现出纯粹的兰伯式反射率,所以它们的外观取决于视图的方向。作者应用了一种与视图相关的纹理映射方法来解释这一点。图5.11说明了这个概念。虚拟相机所看到的像素值从附近捕获的图像中相应的像素中插值作为加权平均值。这些权重与虚拟视图方向和相应的捕获视图方向之间的角度成反比。图5.9(d)显示了应用与视图相关的纹理渲染的模型;从这个高视点捕获图像是非常困难的。 Stage 2.视图相关的纹理映射(VDTM):将捕获的图像映射到恢复的模型。最终的目标是从一个任意的观点重新呈现模型。假设这些图像是在大致相同的光照条件下被捕获的。然而,被建模的物体的表面不太可能表现出纯粹的兰伯式反射率,所以它们的外观取决于视图的方向。作者应用了一种与视图相关的纹理映射方法来解释这一点。图5.11说明了这个概念。虚拟相机所看到的像素值从附近捕获的图像中相应的像素中插值作为加权平均值。这些权重与虚拟视图方向和相应的捕获视图方向之间的角度成反比。图5.9(d)显示了应用与视图相关的纹理渲染的模型;从这个高视点捕获图像是非常困难的。Stage 3.在第一阶段构建的基本模型只是对底层架构模型的一个粗略的近似。如上所述,这简化了参数的拟合。然而,模型的精细细节很重要——不能期望使用粗糙的模型进行渲染是正确的。例如,钟楼的粗糙模型在包含钟的部分中使用了一个单一的砌块:拱门和柱子以及内部元素不包括在粗糙模型中。  添加细节是基本立体重建的一个应用。如前所述,立体重建使用关键(主)图像和辅助图像之间的视差(像素偏移)。如果图像非常不同,可能不太可能在两幅图像之间找到像素偏移。建筑对象的图像通常是从相距很远的视点捕获的,这意味着这些图像对于立体重建的基本方法不太可能不够相似。作者通过处理原始获得的关键图像和虚拟二次图像之间的差异来解决这个问题。该二次图像与关键图像具有相同的视点,但是通过将从不同视点捕获的图像,称为“偏移图像”,从关键图像的粗糙模型投影来构建的(见图5.12)。从立体技术的深度可以应用于关键图像和这个虚拟二次图像之间的视差。在本例中,“深度”实际上是细节与模型表面的偏移量。作者称这种方法为基于模型的立体声。 添加细节是基本立体重建的一个应用。如前所述,立体重建使用关键(主)图像和辅助图像之间的视差(像素偏移)。如果图像非常不同,可能不太可能在两幅图像之间找到像素偏移。建筑对象的图像通常是从相距很远的视点捕获的,这意味着这些图像对于立体重建的基本方法不太可能不够相似。作者通过处理原始获得的关键图像和虚拟二次图像之间的差异来解决这个问题。该二次图像与关键图像具有相同的视点,但是通过将从不同视点捕获的图像,称为“偏移图像”,从关键图像的粗糙模型投影来构建的(见图5.12)。从立体技术的深度可以应用于关键图像和这个虚拟二次图像之间的视差。在本例中,“深度”实际上是细节与模型表面的偏移量。作者称这种方法为基于模型的立体声。 图5.13说明了基于模型的立体声技术的基本几何形状。应用了外极性几何形状;这两个视点是照相机的位置用于关键图像,并用于偏移图像。场景中的一个点P通过两个视点包含在一个独特的外极平面中。假设pk是P对应的关键图像中的像素,通常沿着极线(P通过的极平面与偏移图像的交点)搜索偏移图像中pk对应的像素po。然而,在基于模型的立体图像中,相应的像素包含在扭曲偏移图像中,其通过将偏移图像从偏移相机的位置投影到模型上(图5.13中P投影到Q上),然后将图像投影回关键图像的图像平面。因此,对应于pk的像素qk位于扭曲偏移图像的上极线上,这与关键图像的像素qk相同。 图5.13说明了基于模型的立体声技术的基本几何形状。应用了外极性几何形状;这两个视点是照相机的位置用于关键图像,并用于偏移图像。场景中的一个点P通过两个视点包含在一个独特的外极平面中。假设pk是P对应的关键图像中的像素,通常沿着极线(P通过的极平面与偏移图像的交点)搜索偏移图像中pk对应的像素po。然而,在基于模型的立体图像中,相应的像素包含在扭曲偏移图像中,其通过将偏移图像从偏移相机的位置投影到模型上(图5.13中P投影到Q上),然后将图像投影回关键图像的图像平面。因此,对应于pk的像素qk位于扭曲偏移图像的上极线上,这与关键图像的像素qk相同。最终的渲染是通过Image Warping 来完成的。为了提高渲染的精度和效率,在最终渲染之前先恢复完整的三维模型和与视图相关的纹理映射。然而,有人指出,这些过程本身并不足以创建一个看起来准确的图像。可能正因为如此,从照片中恢复3D模型,然后在映射捕获的图像后进行渲染的过程,用于恢复,成为了基于图像的建模和渲染的定义。 IBR in Movie 如前所述,在电影制作中基于图像渲染的早期应用是在电影 <  在<  在《Like a Rolling Stone》之后,BUF利用IBR技术在好莱坞电影中创造了各种艺术效果。BUF将他们的IBR工具集扩展到由 Luc Besson执导的电影《Arthur and the Minimoys》中的性能捕捉问题。尽管这是一部CG动画电影, Luc Besson还是想用真正的演员来做导演。当时,将演员的表演转换为3D动画数据通常是使用光学运动捕捉系统来完成的。然而,BUF使用了一种不同的方法。他们使用一套精心放置的校准摄像机,从许多不同的角度捕捉到了现场演员的表演(图5.15)。因此,每一帧都会捕捉到一组“多视图”的照片。在多视图序列的每一帧中都可以恢复演员的三维姿态。这种捕捉方法后来被称为“视频动作捕捉”。视频动作捕捉的一个巨大优点是增加了演员和周围环境的自由度。自2008年以来,它在好莱坞主要电影制作中的应用迅速传播。 在《Like a Rolling Stone》之后,BUF利用IBR技术在好莱坞电影中创造了各种艺术效果。BUF将他们的IBR工具集扩展到由 Luc Besson执导的电影《Arthur and the Minimoys》中的性能捕捉问题。尽管这是一部CG动画电影, Luc Besson还是想用真正的演员来做导演。当时,将演员的表演转换为3D动画数据通常是使用光学运动捕捉系统来完成的。然而,BUF使用了一种不同的方法。他们使用一套精心放置的校准摄像机,从许多不同的角度捕捉到了现场演员的表演(图5.15)。因此,每一帧都会捕捉到一组“多视图”的照片。在多视图序列的每一帧中都可以恢复演员的三维姿态。这种捕捉方法后来被称为“视频动作捕捉”。视频动作捕捉的一个巨大优点是增加了演员和周围环境的自由度。自2008年以来,它在好莱坞主要电影制作中的应用迅速传播。The Light Field 光场 在SIGGRAPH 1996上发表的两篇论文介绍了一种基于图像渲染的新方法:Steven J.Gortler、Radek Grzeszczuk、Richard Szeliski和Michael F.Cohen撰写的《The Lumigraph》[Gortler et al. 96] 以及Marc Levoy和Pat Hanrahan撰写的“Light Field Rendering”(Light Field Rendering)[Levoy and Hanrahan 96]。在这些论文发表之前,IBR技术使用二维图像集合来存储采集的摄影图像。1996年发表的两篇论文都引入了基本相同的思想:将采集的图像转换为环境中位置和方向的辐射函数,即构建全光学函数。在没有参与介质的情况下,这简化为空间线上的4D函数。Gortler and his coauthors 把这个函数叫做lumigraph;Levoy and Hanrahan 把它叫做光场。 事实上,计算摄影的一个新的研究领域[Raskar and Tumbin 09]在很大程度上是受到了光场的启发。然而,光场的一个缺点是,它需要大量的空间——表示中等复杂度场景的光场可能需要gb的存储空间。为了缓解这种问题,在原始论文中研究了压缩方案。 Definition of the Light Field 光场的定义  如前所述,多光函数通过提供空间中的每个点、光的每个波长和每个瞬间的每个方向上的辐射来描述环境的光学特性。因此,该函数有7个参数;然而,假设一个静态场景并使用典型的三通道颜色表示,将其简化为一个5D函数P(x,y,z,s,t),其中s和t是观看方向参数(图5.16(a))。另一种降维方法是由于假设没有参与介质,这意味着在空间上的线段上的辐射是恒定的。因此,全光学函数简化为物体表面上的位置和方向的辐射函数,可以存储为几何模型的一部分。然而,作者想要一个独立于几何的表示,所以他们认为多视函数作为空间线上的函数。光场(发光图)正式上指的是这个函数,尽管这个术语也用于5D函数和其他变体。从任意角度拍摄的环境图像是该函数的二维切片。 如前所述,多光函数通过提供空间中的每个点、光的每个波长和每个瞬间的每个方向上的辐射来描述环境的光学特性。因此,该函数有7个参数;然而,假设一个静态场景并使用典型的三通道颜色表示,将其简化为一个5D函数P(x,y,z,s,t),其中s和t是观看方向参数(图5.16(a))。另一种降维方法是由于假设没有参与介质,这意味着在空间上的线段上的辐射是恒定的。因此,全光学函数简化为物体表面上的位置和方向的辐射函数,可以存储为几何模型的一部分。然而,作者想要一个独立于几何的表示,所以他们认为多视函数作为空间线上的函数。光场(发光图)正式上指的是这个函数,尽管这个术语也用于5D函数和其他变体。从任意角度拍摄的环境图像是该函数的二维切片。光场表示为空间中线上的大量样本。如何表示这些行对表示的成功至关重要。这两篇论文都使用了相同的一般方法来参数化线:给定两个固定的平面,一条线由一个平面上的坐标(u,v)唯一表示,而由另一个平面上的坐标(s,t)唯一表示(图5.16(b))。直观地说,u和v可以看作是位置参数,s和t可以看作是每个(u,v)的方向参数,但视图位置可以是任意的,这两个平面都不一定是“图像”平面。Levoy和汉拉汉指的是这两个平面之间的线的集合,限制为0≤u,v,s,t≤1,作为一个slab。因此,光板是空间中两个矩形(或一般的四边形)中的点之间的所有线的集合。一个Light Slab 的光场被表示为一个二维图像的集合,每个离散的(u,v)参数都有一个图像。 Construction of a Light Field 光场的构造 构建虚拟环境的光场相对简单:light slab的样品可以通过沿着相应的线追踪光线来计算。然而,光场必须在四维线空间中进行预过滤,以避免混叠。这种过滤的副作用是引入深度模糊,但实际发生的是,这最终是可取的。从数字化的照片中构建光场要困难得多,因为它需要大量的照片、相机校准、对相机位置的精确知识,以及一种重新采样图像以匹配光板参数化的方法。 对于特定的对象或环境,构造光场首先选择light slab来构建光场。一个light slab不能捕捉从一个物体发出的所有方向的光,因此可能需要多个light slab来充分代表光场。但是,如果单个slab的视图集对特定应用足够,那么它的光场可能就足够了。Gortler and his collaborators提议使用基于立方体的表面的light slab。其他的安排也是可能的,而且实际上也可能是必要的。其中一个或两个平面甚至可以放置在“无限大”,以方便渲染正交法 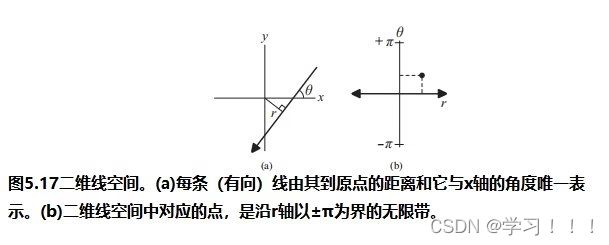 slab的方向分布最好用二维简化来说明;“光场渲染”的论文包括几个这样的插图。光场是在线的空间上的一个函数。平面上的二维线可以用两个参数唯一表示:到原点的距离r和线与x轴形成的角度θ(图5.17(a))。因此,二维线与rθ平面无限带上的点一一对应,与−π<θ≤π对应(图5.17(b))。这是一个二维的“线空间”。在二维情况下,光板的一对平面减少为一对线段;二维光板由通过这对中每一段的所有线组成。  图5.18(a)显示了由一个二维光板中离散数量的参数样本所产生的一组线。二维中这些线对应的线空间点(rθ平面)如图5.18(b).所示这个分布不是很均匀。图5.18(c)和(d)显示了四个不同的二维light slab的集合,排列为覆盖一个正方形,以及在线空间中相应的样本分布。在Levoy and Hanrahan的论文中,这种安排的3D版本被用来代表一个小玩具狮子的光场。 图5.18(a)显示了由一个二维光板中离散数量的参数样本所产生的一组线。二维中这些线对应的线空间点(rθ平面)如图5.18(b).所示这个分布不是很均匀。图5.18(c)和(d)显示了四个不同的二维light slab的集合,排列为覆盖一个正方形,以及在线空间中相应的样本分布。在Levoy and Hanrahan的论文中,这种安排的3D版本被用来代表一个小玩具狮子的光场。Light Field Rendering 光场渲染 光场渲染是创建从任意视点出现的由光场所表示的场景图像的过程。从概念上讲,从光场渲染图像相当于获取4D数据的二维切片,但在实际应用中,它更为复杂。给定一个虚拟摄像机,图像平面上的像素值(x,y)是沿着直线穿过该像素到视点的亮度。这条线在适当的light slab的线空间中具有坐标(u、v、s、t),因此可以简单地在光场中查找该值。这需要确定合适的light slab,如果有多个。如果没有适当的slab,则无法渲染像素。 当然,与任何表查找一样,精确参数集(u、v、s、t)的值不太可能存在于表中。因此,该值必须从附近的值中进行插值。插值的方法对结果图像的质量是至关重要的,因为较差的插值会导致混叠伪影。各种插值方案都是可能的。Levoy and Hanrahan对几种参数进行了实验,得出在所有四个参数的四线性(同时)插值得到最好的结果。然而,他们注意到,仅在u和v中采用更快的双线性插值方法有时是足够的。 Light Field Mapping 光场映射 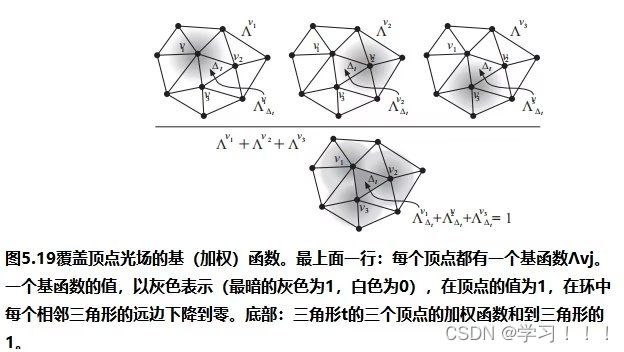 光场的几何独立性在理论上很有趣,但有充分的理由将view-dependent radiance表示为表面函数。效率就是其中之一。Wei ChaoChen、Jean-Yves Bouguet、Michael H.Chu和Radek Grzeszczuk的论文“Light Field Mapping” [Chen et al. 02] 提出了一种非常适合图形硬件管道的基于表面的光场表示。每个曲面都被分割成三角形。作者提出了一种使用三角形顶点处的采样光场值的表示法,而不是在每个三角形上单独构造光场函数,这可能会导致三角形边界处的不连续性。 光场的几何独立性在理论上很有趣,但有充分的理由将view-dependent radiance表示为表面函数。效率就是其中之一。Wei ChaoChen、Jean-Yves Bouguet、Michael H.Chu和Radek Grzeszczuk的论文“Light Field Mapping” [Chen et al. 02] 提出了一种非常适合图形硬件管道的基于表面的光场表示。每个曲面都被分割成三角形。作者提出了一种使用三角形顶点处的采样光场值的表示法,而不是在每个三角形上单独构造光场函数,这可能会导致三角形边界处的不连续性。顶点光场函数使用双线性插值法在曲面三角形上展开,也称为重心插值法,以同样的方式插入顶点颜色一样。因此,表面三角形光场是顶点函数的加权平均值。权值可以表示为三角形上的位置函数:函数Λvj是顶点vj的质心权值;它的值在vj处为1,在与vj相邻的三角形环上下降到0。在一个给定的三角形(三角形顶点的加权函数)的内部,恰好有三个这样的函数是非零的,它们在三角形上的和为1。图5.19说明了这一点。由此得到的插值是连续的,但在一阶导数中有不连续的。 当“Light Field Mapping”论文发表时,重心插值并不新鲜,尽管它以前没有应用于表面光场的划分。表面光场是四个参数的函数:f(r、s、θ、φ),其中r和s提供了它在表面上的位置;θ和φ,方向。顶点vj的光场函数通过公式从f中“分割” 作者实际上提出了两种近似方法,它们都使用矩阵分解应用于每个顶点光场函数的样本集合。一种方法采用principal component analysis(PCA),以某种方式,找到矩阵的最佳基础。结果是一系列的样本,在贡献减少的意义上近似于函数,因此有限数量的项提供了一个有用的近似。然而,所得到的样本值可以是负的。作者指出,这使硬件实现复杂化了。相比之下, nonnegative matrix factorization(NMF)要求使用所有的术语,但样本值都是非负的。在任何一种情况下,三角形t上的光场函数ft都是该形式的离散近似 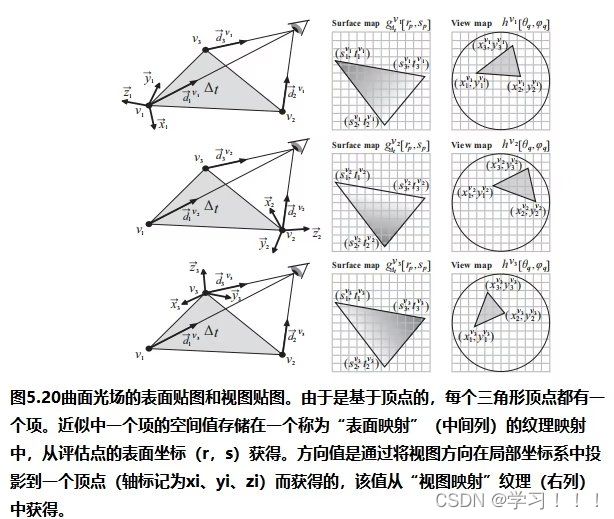 通过查找曲面中的值和查看三角形顶点的映射,在每个三角形上渲染曲面光场,如图5.20所示。此图的左列显示了(与视图相关的)渲染几何图形;曲面和视图贴图分别显示在中间列和右列中,它们分别对应于左列中的特定顶点。曲面贴图是一个简单的纹理贴图查找:在三角形上的位置被转换为纹理坐标,g的值从匹配的纹理中获得。在视图地图中的查找要稍微复杂一些。与表面映射直接将g的值存储为位置的函数不同,视图映射给出了顶点处的h的值。此时,将计算出顶点处的视图方向在顶点的局部坐标系中,并通过正交投影投影到纹理坐标平面上(图5.20中的圆是该投影的边界)。曲面映射和视图映射值直接相乘;曲面映射包含权重函数的值(在图5.20中显示为坡度),因此结果可以直接添加到三角形的累计和中。这些计算都可以在GPU上有效地完成。 通过查找曲面中的值和查看三角形顶点的映射,在每个三角形上渲染曲面光场,如图5.20所示。此图的左列显示了(与视图相关的)渲染几何图形;曲面和视图贴图分别显示在中间列和右列中,它们分别对应于左列中的特定顶点。曲面贴图是一个简单的纹理贴图查找:在三角形上的位置被转换为纹理坐标,g的值从匹配的纹理中获得。在视图地图中的查找要稍微复杂一些。与表面映射直接将g的值存储为位置的函数不同,视图映射给出了顶点处的h的值。此时,将计算出顶点处的视图方向在顶点的局部坐标系中,并通过正交投影投影到纹理坐标平面上(图5.20中的圆是该投影的边界)。曲面映射和视图映射值直接相乘;曲面映射包含权重函数的值(在图5.20中显示为坡度),因此结果可以直接添加到三角形的累计和中。这些计算都可以在GPU上有效地完成。在2002年的“Light Field Mapping” 论文中提出的光场的表面表示在具有复杂的表面几何细节的物体上表现得特别好,但确实有一些缺点。曲面和视图映射的构造,即顶点函数近似的构造,需要大量的辐射样本。此外,地图的表示比空间光场需要更少的存储空间,但它仍然占用了大量的空间。 Light Field Photography 光场摄影 2005年,任宁宁和他在斯坦福大学的同事们发表了两篇论文,介绍了光场与摄影的新联系。由Ng, Levoy, and Hanrahan along with Mathieu Br´edif, Gene Duval, and Mark Horowitz,撰写的  入射到相机主透镜表面的光是一个光场:在透镜上的每一点上,来自一组射线方向的辐射进入透镜。该方向集进一步受到孔径的限制,并且光线被透镜系统中的光学器件所折射,但传感器平面上的每个点最终接收到来自一组方向的辐射。到达传感器平面的一组光线被称为相机内的光场。图5.21说明了这个概念。传感器平面上的一个点(x,y)接收来自主透镜上由(u,v)参数化的一组点的辐射,尽管这种对应关系取决于相机的光学和聚焦状态。如果F是从透镜平面到传感器平面的距离,则从点(u、v)到(x、y)处的亮度用LF(x、y、u、v)表示。由于其他光学元件,包括孔径停止,可能没有光从透镜上的任意点(u,v)到任意点(x,y)的路径,在这种情况下,Lf(x,y,u,v)=0。 入射到相机主透镜表面的光是一个光场:在透镜上的每一点上,来自一组射线方向的辐射进入透镜。该方向集进一步受到孔径的限制,并且光线被透镜系统中的光学器件所折射,但传感器平面上的每个点最终接收到来自一组方向的辐射。到达传感器平面的一组光线被称为相机内的光场。图5.21说明了这个概念。传感器平面上的一个点(x,y)接收来自主透镜上由(u,v)参数化的一组点的辐射,尽管这种对应关系取决于相机的光学和聚焦状态。如果F是从透镜平面到传感器平面的距离,则从点(u、v)到(x、y)处的亮度用LF(x、y、u、v)表示。由于其他光学元件,包括孔径停止,可能没有光从透镜上的任意点(u,v)到任意点(x,y)的路径,在这种情况下,Lf(x,y,u,v)=0。在传感器光点的数码相机内形成的图像的像素值理想地与穿过像素光点的时间积分通量成正比。对于足够小的像素,通量本质上只是辐照度,这是通过积分入射辐照度来计算的。辐照度是通过对方向半球上的入射辐射进行积分得到的。在相机计算中,跨透镜积分更明智,这需要改变透镜参数u和v的变量,类似于在渲染方程(见(计算机图形学的魔法的概述篇(一) 公式2.4))中应用的表面积分变换。 实际的积分依赖于一些内在的相机参数,以及一些额外的几何项。然而,在适当的假设下,光位点的辐照度可以近似为 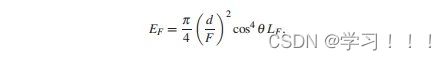 其中d是相机光圈的直径。值LF被称为像素的场景亮度。 其中d是相机光圈的直径。值LF被称为像素的场景亮度。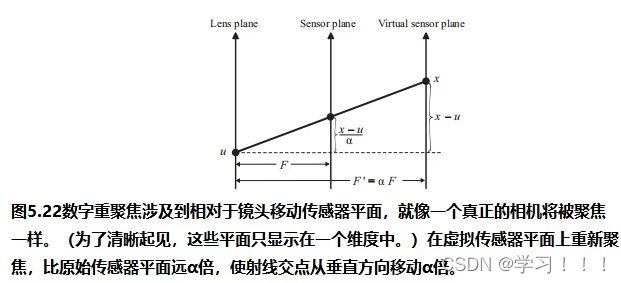 余弦因子有时被吸收到LF中,或者,在一个表面上很小的视场的情况下,被视为常数,然后从积分中分解出来。孔径函数同样可以被吸收到LF中,在这种情况下,方程(5.6)简化为仅 余弦因子有时被吸收到LF中,或者,在一个表面上很小的视场的情况下,被视为常数,然后从积分中分解出来。孔径函数同样可以被吸收到LF中,在这种情况下,方程(5.6)简化为仅现在假设相机的焦距改变了,这相当于改变了镜头与传感器平面之间的距离F,如图5.22所示。传感器平面的新位置,在图5.22中称为“virtual sensor plane”,放置在距离为F'= αF。在F'的传感器平面上的新光场LF'成为原始传感器平面光场的“剪切”版本:  然后,通过将公式(5.8)代入公式(5.7),给出光位点辐照度(像素值): 然后,通过将公式(5.8)代入公式(5.7),给出光位点辐照度(像素值): 因此,数字重聚焦是一个评估这个积分的问题,给定了相机内光场LF。 因此,数字重聚焦是一个评估这个积分的问题,给定了相机内光场LF。使用多光照相机进行的光场摄影。为了捕捉相机内光场,Ng等构建了一个设备,他们称之为“光场相机”基于相机提出“单镜头立体相机”发表于1992年由Adelson and Wang [Adelson and Wang 92]. 一个普通相机从遥远的聚焦平面聚焦光,使这个平面的光线汇聚在传感器阵列(或胶片平面)的相应点上。假设将阵列针孔放置在传感器阵列的前面,图像聚焦在这个表面上。每个针孔以盘状图像的形式将收敛的光扩散到传感器平面上,这代表了通过针孔可以看到的东西。然后,传感器平面图像将这些图像记录成一个图像,看起来像一组场景的小图像,每个图像都从一个稍微不同的视角捕获。明智地放置针孔表面,使这些图像的大小最大化,这样它们就可以相互接触。 Ng和他的合作者所描述的光场相机使用了这一原理,除了使用了一组微透镜来代替针孔表面。在光场相机中,图像聚焦在微透镜阵列上,每个微透镜创建一个通过传感器阵列上的镜头看到的小清晰图像。这幅图像被称为“微透镜图像”,它由一组与微透镜相对应的像素记录下来。因此,光场相机捕捉到的图像似乎是一组物体的小图像,每个图像的视场比原始像素组对应的视场大几倍(图5.23)。  每张微图像包含一个小的相机内光场切片。针孔模型有助于说明原因。微透镜阵列放置在传感器阵列的位置,因此(x,y)参数对应于微透镜表面点。考虑以at(xm,ym)为中心的微透镜。对应微透镜图像上的点传感器像素(u',v')记录了连接像素中心和微透镜中心的线的辐射。因此,参数(u',v')对应于透镜参数(u、v),因此微透镜图像记录了LF的样本(xm、ym、u、v)。因此,每张微图像中的像素数对应于定向采样密度;微透镜的数量,与位置采样密度有关。作者描述的原型有一个296×296微透镜阵列,每个微透镜对应一个大约13像素宽的微图像(透镜和像素之间的对应不需要精确)。数字重聚焦可以应用使用公式(5.9)与LF插值和重采样适当。 每张微图像包含一个小的相机内光场切片。针孔模型有助于说明原因。微透镜阵列放置在传感器阵列的位置,因此(x,y)参数对应于微透镜表面点。考虑以at(xm,ym)为中心的微透镜。对应微透镜图像上的点传感器像素(u',v')记录了连接像素中心和微透镜中心的线的辐射。因此,参数(u',v')对应于透镜参数(u、v),因此微透镜图像记录了LF的样本(xm、ym、u、v)。因此,每张微图像中的像素数对应于定向采样密度;微透镜的数量,与位置采样密度有关。作者描述的原型有一个296×296微透镜阵列,每个微透镜对应一个大约13像素宽的微图像(透镜和像素之间的对应不需要精确)。数字重聚焦可以应用使用公式(5.9)与LF插值和重采样适当。然而,有一种更好的方法来执行数字重新聚焦,采用对光场相机图像的替代解释。微图像中的一个像素对应于一个小光锥,可以看作是来自镜头上的一个小虚拟光圈——就像镜头上的针孔。根据投影的本质,每个微图像中相应的像素从几乎相同的虚拟光圈获得光。将所有这些像素(每个微透镜都有一个像素)收集到一个单独的图像中,将生成一个子光圈图像(图5.24)。每个微图像像素都有一个子光圈图像,每个子图像都从略微不同的角度显示物体。由于有效孔径很小,每个子孔径图像都显得清晰,即基本上具有无限的景深。这种锐化能力是光场相机的一个重要特征,尽管亚光圈图像只有微透镜阵列的分辨率。碰巧,式(5.9)被积函中的LF值只是子光圈图像的缩放和移放版本,所以重新聚焦等于对整个镜头上移放和缩放的子光圈图像求和。 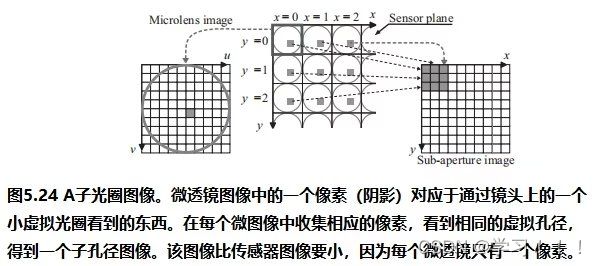 “Light Field Camera” 论文介绍了捕获和重聚焦技术的实验验证,并验证了再聚焦性能的有效性这取决于光场的采样率。特别是重新聚焦的锐度和可能的重新聚焦深度的范围与方向分辨率成线性正比。然而,该方法依赖于一些近似假设,由于缺乏参考解决方案,使得很难量化光场的精度和渲染图像的误差。 “Light Field Camera” 论文介绍了捕获和重聚焦技术的实验验证,并验证了再聚焦性能的有效性这取决于光场的采样率。特别是重新聚焦的锐度和可能的重新聚焦深度的范围与方向分辨率成线性正比。然而,该方法依赖于一些近似假设,由于缺乏参考解决方案,使得很难量化光场的精度和渲染图像的误差。Fourier slice photography(傅里叶切片摄影)。Ng在论文“Fourier slice photography”中提出了一个光场的数学框架,为光场成像提供了理论基础[Ng 05]。本文的主要结果是一个被称为傅里叶切片摄影定理,它提供了一种从傅里叶域的光场创建图像的方法。该定理是基于一个已知定理的推广,即涉及两种函数降维的傅里叶切片定理。为了更精确地说,假设F是n个实变量的实值函数。通过积分F的一些变量,得到了对F的积分投影,得到了m个变量的函数。例如,公式(5.7)中确定传感器像素处的辐照度的积分是一个积分投影: 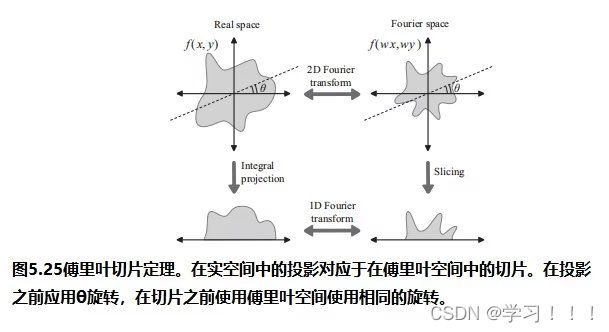 积分投影和切片可以推广到包括变量的线性变换,这也被称为基的变化。这并不影响傅里叶切片定理的有效性,因为傅里叶变换本身是线性的,这意味着它“通过”线性变换。图5.25说明了在这个更一般的背景下的傅里叶切片定理:投影和切片都在坐标旋转θ后应用。方程(5.9)中隐含的重聚焦变换实际上是光场参数的线性变换: 积分投影和切片可以推广到包括变量的线性变换,这也被称为基的变化。这并不影响傅里叶切片定理的有效性,因为傅里叶变换本身是线性的,这意味着它“通过”线性变换。图5.25说明了在这个更一般的背景下的傅里叶切片定理:投影和切片都在坐标旋转θ后应用。方程(5.9)中隐含的重聚焦变换实际上是光场参数的线性变换: 因此,从相机内光场重新聚焦图像的过程可以表示为经过参数的线性变换(方程(5.11))后的光场的积分投影(方程(5.10))。根据傅里叶切片定理,重聚焦图像的傅里叶变换是相机内光场的四维傅里叶变换的二维切片。这一点,结合所涉及的特定变换,就是傅里叶切片摄影定理。 因此,从相机内光场重新聚焦图像的过程可以表示为经过参数的线性变换(方程(5.11))后的光场的积分投影(方程(5.10))。根据傅里叶切片定理,重聚焦图像的傅里叶变换是相机内光场的四维傅里叶变换的二维切片。这一点,结合所涉及的特定变换,就是傅里叶切片摄影定理。在傅里叶域中,采样和图像质量的分析在数学上更简单。“Fourier Slice Photography”该论文的数学框架允许对“Light Field Photography ”论文中的一些实验结果进行理论证明。特别地,它对精确重聚焦的可用范围设置了限制,并证明了锐度随方向采样率的线性增加。分析还表明,“数字重新聚焦的照片是精确照片的2D(低通)过滤版本”,这为重新聚焦的照片的噪音提供了证据。总之,本文回答了获得光场的重聚焦图像质量的问题。 傅里叶切片摄影定理导致了一种更有效的数字重聚焦算法(在更快和更少依赖于光场的采样率的意义上),称为傅里叶切片数字重聚焦。如图5.26所示,首先计算一个四维光场的傅里叶变换,然后在傅里叶域内进行重新聚焦的操作(剪切和二维切片的应用)。结果的逆变换是最终的图像。这种方法的另一个特点是,四维光场的傅里叶变换,这是最昂贵的部分,只需要根据需要对许多不同的重新聚焦计算一次。 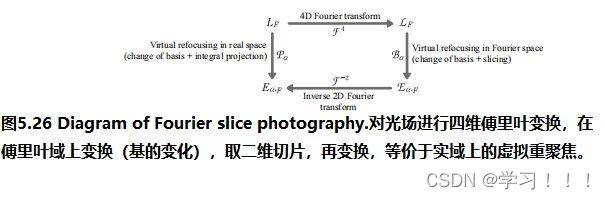 图5.27包含了使用傅里叶变换的数字重聚焦过程的图像。第一行显示由光场相机捕获的光场。特写镜头包括在右边。第二行显示了光场的傅里叶变换,排列成一个二维图像,类似于光场在二维光场图像中的存储方式。第三行包含四维变换数据的切片,在对三种重聚焦排列分别应用剪切变换后;从左到右,α > 1,α = 1,α < 1。(注意,傅里叶变换图像与实际图像不是很好,尽管它们看起来很有趣。)最下面的两行显示了重新聚焦的图像。第二最低行的图像是上面图像中所示的二维傅里叶变换切片的逆变换。在底部的图片由方程(5.9)的直接积分呈现,并提供以供比较。 图5.27包含了使用傅里叶变换的数字重聚焦过程的图像。第一行显示由光场相机捕获的光场。特写镜头包括在右边。第二行显示了光场的傅里叶变换,排列成一个二维图像,类似于光场在二维光场图像中的存储方式。第三行包含四维变换数据的切片,在对三种重聚焦排列分别应用剪切变换后;从左到右,α > 1,α = 1,α < 1。(注意,傅里叶变换图像与实际图像不是很好,尽管它们看起来很有趣。)最下面的两行显示了重新聚焦的图像。第二最低行的图像是上面图像中所示的二维傅里叶变换切片的逆变换。在底部的图片由方程(5.9)的直接积分呈现,并提供以供比较。
Refrenece: [E. Kruppa] Translation of “Zur Ermittlung eines Objektes aus zwei Perspektivenmit innerer Orientierung” by Erwin Kruppa (1913)∗.
[Levoy and Hanrahan 96] Marc Levoy and Pat Hanrahan. “Light Field Rendering.” In Proceedings of SIGGRAPH ’96: Computer Graphics Proceedings, Annual Conference Series, edited by Holly Rushmeier, pp. 31–42. Reading, MA: AddisonWesley,1996. [Gortler et al. 96] Steven J. Gortler, Radek Grzeszczuk, Richard Szeliski, and Michael F.Cohen. “The lumigraph.” In Proceedings of SIGGRAPH 96, Computer Graphics Proceedings, Annual Conference Series, edited by Holly Rushmeier, pp. 43–54,Reading, MA: Addison-Wesley, 1996. [Raskar and Tumbin 09] Ramesh Raskar and Jack Tumbin. Computational Photography:Mastering New Techniques for Lenses, Lighting, and Sensors. Natick, MA: A K Peters Ltd., 2009. [Chen et al. 02] Wei-Chao Chen, Jean-Yves Bouguet, Michael H. Chu, and RadekGrzeszczuk. “Light Field Mapping: Efficient Representation and Hardware Rendering of Surface Light Fields.” Proc. SIGGRAPH ’02, Transactions on Graphics 21:3 (2002), 447–456. [Fournier 95] Alan Fournier. “Separating Reflectance Functions for Linear Radiosity.” In Rendering Techniques ’95: Proceedings of the Eurographics Workshop in Dublin,Ireland, June 12–14, 1995, edited by P. Hanrahan and W. Purgathofer, pp 296–305.Wien: Springer-Verlag, 1995. [Ng 05] Ren Ng. “Fourier Slice Photography.” Proc. SIGGRAPH ’05, Transactions on Graphics 24:3 (2005), 735–744. [Georgeiv et al. 06] T. Georgeiv, K.C. Zheng, B. Curless, D. Salesin, S. Nayar, and C. Intwala. “Spatio-angular Resolution Tradeoff in Integral Photography.” In Rendering Techniques 2006: Eurographics Symposium on Rendering, Nicosta, Cyprus, June 26–29, 2006, edited by Tomas Akenine-M¨oller and Wolfgang Heidrich, pp. 263–272. Aire-La-Ville, Switzerland: Eurographics Association, 2006 [Veeraraghavan et al. 07] Ashok Veeraraghavan, Ramesh Raskar, Amit Agrawal, Ankit Mohan, and Jack Tumblin. “Dappled Photography: Mask Enhanced Cameras for Heterodyned Light Fields and Coded Aperture Refocusing.” Proc. SIGGRAPH ’07,Transactions on Graphics 26:3 (2007), 69. [Adelson and Wang 92] Edward H. Adelson and John Y. A. Wang. “Single Lens Stereo with a Plenoptic Camera.” IEEE Trans. Pattern Anal. Mach. Intell. 14:2 (1992), 99–106. [Ng 05] Ren Ng. “Fourier Slice Photography.” Proc. SIGGRAPH ’05, Transactions on Graphics 24:3 (2005), 735–744. [Raskar et al. 08] Ramesh Raskar, Amit Agrawal, Cyrus A. Wilson, and Ashok Veeraraghavan. “Glare Aware Photography: 4D Ray Sampling for Reducing Glare Effects of Camera Lenses.” Proc. SIGGRAPH ’08, Transactions on Graphics 27:3 (2008), 1–10. [Liang et al. 08] Chia-Kai Liang, Tai-Hsu Lin, Bing-Yi Wong, Chi Liu, and Homer H. Chen. “Programmable Aperture Photography: Multiplexed Light Field Acquisition.”Proc. SIGGRAPH ’08, Transactions on Graphics 27:3 (2008), 1–10. [Hirsch et al. 09] Matthew Hirsch, Douglas Lanman, Henry Holtzman, and Ramesh Raskar. “BiDi Screen: A Thin, Depth-Sensing LCD for 3D Interaction Using Light Fields.” Proc. SIGGRAPH Asia ’09, Transactions on Graphics 28:5 (2009), 1–9. |