【数据库原理与应用】期末知识点总结——电子科技大学2023期末考试总复习
期末重点:
SQL编程–难度类似实验测评
关系模型—概念、关系运算
CDM设计–根据题目给出的需求,画出PD格式的CDM图
PDM设计—课件4-4
数据库规范化设计
ODBC—概念、分级、方法
JDBC—概念、分级、编程
存储过程、触发器—难度类似实验
第七章考核点: cap base 5v 四种nosql数据库类型和分类比较
考试题型:分析题,编程题,应用题,设计题
数据库系统基础
-
数据库定义:一种依照特定数据模型组织、存储和管理数据的文件集合。这些文件一般存放在外部存储器中,以便长久保存数据,并可快速访问。
-
数据库与普通数据文件的主要区别:
- 数据库可以支持不同应用对数据共享访问,普通数据文件难以支持。
- 数据库可实现复杂的数据管理,普通数据文件难以实现。
- 数据库可独立应用程序,普通数据文件与应用程序紧耦合。
- 数据库的操作访问与控制管理由数据库管理系统软件实现;普通数据文件的操作访问与控制管理,都必须由应用程序实现
-
DBMS一般具有的功能:
- 数据定义功能:创建数据库、数据库表以及其它对象
- 数据操纵功能:读写、修改、删除数据库表中数据
- 维护数据库结构
- 执行数据访问规则
- 提供数据库并发访问控制和安全控制
- 执行数据库备份和恢复
-
数据库系统的构成由数据库、数据库管理系统(创建、操纵和管理数据库的系统软件)、数据库应用系统(在DBMS支持下对数据库进行访问和处理的应用程序)和用户(分为最终用户和DBA用户两种)构成。

-
数据模型的构成要素:数据结构(用于描述事物对象的静态特征,包括事物对象的数据组成、数据类型、数据性质等),数据操作(用于描述事物对象的动态特征,包括数据的插入、修改、删除和查询等访问操作),数据约束(用于描述数据结构中数据之间的语义联系*、数据之间的制约和依存关系,数据动态变化的规则,*以及数据取值范围等规则,从而确保数据的完整性、一致性和有效性)注:斜体的内容PPT上有而书上没有
-
关系数据模型思想:采用“二维表”结构组织、存储和管理数据,并以关联列实现表之间的联系。
-
关系数据模型优点: 数据结构简单、操作灵活;支持关系与集合运算操作;支持广泛使用的SQL数据库操作语言标准;拥有众多的软件厂商产品与用户
-
关系数据模型局限: 只用于结构化数据的组织与存储管理;支持的数据类型较简单;难以支持互联网广泛应用的非结构化数据和复杂数据管理
-
数据管理技术发展:人工管理——文件系统管理——数据库系统管理
-
数据库技术发展经历时代:层次模型数据库技术和网状模型数据库技术——关系模型数据库技术——面向对象数据库技术和对象-关系数据模型数据库技术——本世纪初期出现的半结构化数据库技术,以及当今面向互联网应用的非结构化数据库技术、大规模分布式数据库技术
-
数据库应用系统的类型:业务处理系统(商业终端销售系统,航空机票订票系统),管理信息系统(人力资源管理系统,企业客户关系管理系统),决策支持系统(电信营销大数据决策支持系统,证券分析与辅助决策信息系统,法定传染病疫情预测系统)
-
数据库应用系统的结构:单用户结构(在单机用户结构系统中,整个数据库应用系统都装在一台计算机上,由一个用户进行访问操作),集中式结构(数据库系统的应用程序、DBMS、数据,都部署在同一服务器上运行,多个用户使用自己的计算机终端网络连接服务器,并可实现共享访问数据库),客户/服务器结构(数据库应用系统的数据集中在数据库服务器管理、应用分布客户机处理。客户端应用程序通过网络并发访问数据库服务器中的数据库),分布式结构(各服务器结点数据库在逻辑上是一个整体,但物理分布在计算机网络的不同服务器结点上运行)
-
数据库应用系统生命周期:
- 需求分析:系统分析人员与用户交流,利用软件工程方法获取系统数据需求信息,并采用需求模型定义系统数据组成,及其数据字典。
- 系统设计:系统设计人员根据系统功能和性能需求,对系统数据库进行设计,包括系统概念数据模型、系统逻辑数据模型和系统物理数据模型设计。
- 系统实现:按照系统设计方案进行数据库创建与应用编程实现,主要包括DBMS安装部署、数据库创建、数据对象创建、应用编程实现等方面的工作。
- 系统测试:系统测试人员将测试数据上载到数据库中,对数据库对象进行测试操作访问,实现数据库功能和性能测试。
- 系统运行和维护:系统运维人员在信息系统投入运行过程中,对数据库系统进行定期维护和优化,以保证数据库系统正常地、高效地运行。
-
讨论题:关系数据库是否适合大数据应用处理?
结合关系模型的局限作答。存储和性能成本;数据冗余和一致性;处理复杂性。
- 关系数据库通常使用结构化的数据模型,对于大量非结构化或半结构化数据,这可能变得非常困难和昂贵
- 关系数据库强调数据一致性和完整性,在大数据环境中,数据的结构和模式可能经常发生变化。这种灵活性要求在关系数据库中频繁地进行模式更改和数据迁移,导致一定的数据冗余和一致性的挑战
- 大数据应用通常涉及复杂的数据处理操作,如分布式计算、实时处理、图形处理等。关系数据库在这些方面可能缺乏一些先进的功能和技术,无法有效地应对大数据的处理复杂性。
- 也可以从其它角度作答,如:处理速度慢,关系数据库通常使用SQL查询语言进行数据检索和处理。当数据量很大时,复杂的SQL查询可能需要大量的时间来执行,从而导致性能下降。关系数据库在处理大规模并发请求时也可能面临性能瓶颈。扩展性限制,关系数据库通常基于固定的硬件设备,其扩展性受到硬件资源的限制。当数据量庞大时,关系数据库可能无法有效地扩展以处理大规模的数据。
-
讨论题:中国为什么要发展自主可控数据库?应该采取什么样的发展策略?
发展原因:维护数据主权和安全;提升技术创新和自主研发能力;提升产业竞争力,促进数字经济发展
策略:加强创新,建立规范体系,人才支持,国际交流合作
数据库关系模型
-
实体与关系的概念:实体是指包含有数据特征的事物对象在概念模型世界中的抽象名称。关系是指具有关系特征、用于存放实体数据的二维表。关系也常被称为关系表。在关系模型中,使用“关系”来存储“实体”中的数据。
-
关系模型组成:数据结构,数据操作,数据关系约束
-
关系的特征:
- 表中每行存储实体的一个实例数据
- 表中每列包含实体的一项属性数据
- 表中单元格只能存储单个值
- 不允许有重复的行、列
- 列、行顺序可任意
-
关系的键:在关系中,可以用来唯一标识元组的属性列,称为键(Key),其它属性列都为非键列。复合键是指关系中用来唯一标识元组的多列作为键。关系中可能有多个列均适合作为键,将其中每个都称为候选键。主键是关系表中最有代表性的一个候选键。代理键:采用DBMS自动生成的数字序列作为关系表的主键。由DBMS自动生成的数字序列作为主键,可替代复合主键,以便获得更高性能的数据访问操作处理。
-
主键作用: 唯一标识关系表的每行(元组); 与关联表的外键建立联系,实现关系表之间连接;数据库文件使用主键值来组织关系表的数据存储;数据库使用主键索引快速检索数据
-
关系模型语句表示:关系名(主键属性,属性2,…,属性x),主键属性加下划线!
-
关系运算:
-
关系并运算∪的结果集是由属于R或属于S的所有元组组成。
-
关系差运算-的结果集是由属于R,而不属于S的所有元组组成。
-
关系交运算∩的结果集是由既属于R又属于S的所有元组组成。
(关系并、交、差运算的前提:关系R与关系S需有相同属性组成)
-
笛卡儿积运算的结果集是由所有属于R的元组与所有属于S的元组进行组合而成。
-
选择运算是从关系的水平方向进行运算,是从关系 R 中选择满足给定条件的元组,记作σF®,其形式如下:
σ F ( R ) = { t ∣ t ∈ R ∧ F ( t ) = T r u e } σ_F(R)=\{t|t∈R∧F(t)=True\} σF(R)={t∣t∈R∧F(t)=True} -
投影运算是从关系的垂直方向进行运算,在关系 R 中选出若干属性列 A 组成新的关系,记作 πA®,其形式如下:
π A ( R ) = { t [ A ] ∣ t ∈ R } π_A(R)=\{t[A]|t∈R\} πA(R)={t[A]∣t∈R} -
θ 连接:从 R 与 S的笛卡尔积中选取属性间满足一定条件的元组,可由基本的关系运算笛卡尔积和选取运算导出,表示为:
σ A θ B ( R × S ) σ_{AθB}(R×S) σAθB(R×S)
AθB为链接的条件,θ 是比较运算符(<,≤,=,>,≥),A 和 B 分别为 R 和 S 上度数相等且可比的属性组 -
当 θ 为「=」时,称之为等值连接
-
自然连接是一种特殊的等值连接,它要求两个关系中进行比较的分量必须是 相同的属性组,并且在结果集中将 重复的属性列 去掉。记作 R ∞ S R \infty S R∞S
-
外连接:包括左外连接,右外连接,全外连接
-
-
关系模型的完整性约束:包括实体完整性约束(关系表中实施的主键取值约束,以保证关系表中的每个元组可以被唯一标识。规则:主键不为空,唯一)参照完整性约束(关系表之间需要遵守的数据约束,以保证关系之间关联列的数据一致性。规则:若关系R中的外键F与关系S中的主键K相关联,则R中外键F值必须与S中主键K值一致。)用户自定义完整性约束(用户根据具体业务对数据处理规则要求所定义的数据约束。包括:定义列的数据类型,取值范围,缺省值,是否允许为空等等)
数据库操作语言SQL
-
SQL语言:SQL( Structured Query Language,结构化查询语言 )是一种对关系数据库进行访问的数据操作语言。特点:一体化,使用方式灵活,非过程化,语言语句简单
-
SQL语言类型:数据定义语言DDL,数据操纵语言DML,数据查询语言DQL,数据控制语言DCL,事务处理语言TPL,游标控制语言CCL
-
操作数据库:不要遗漏database
create database <>;alter database <> rename to <>;drop database <>; -
创建表:基本语句为
create table <> ();最后一行末尾不能加逗号,多个约束之间不用加逗号
PRIMARY KEY——主键
NOT NULL——非空值
NULL——空值
UNIQUE——值唯一
CHECK——有效性检查,两层括号!check后面一个in后面一个
CourseType varchar(10) CHECK(CourseType IN('基础课','专业课','选修课'))DEFAULT——缺省值
TestMethod char(4) NOT NULL DEFAULT '闭卷考试' -
表约束关键词
复合主键:
constraint 复合主键名 primary key(代理键列名)代理键应该是好几列,用逗号隔开外键:
constraint 外键名 foreign key(外键列) references 表名(表的主键列) on delete cascade- 顺序别搞反!constraint+自己取得名字+约束类型(括号里面是列名)
- foreign别拼错!
- references别漏加s!
- 后面的顺序别搞错!references后面紧跟另一个表(括号里面是表的主键列)
- 别漏加on delete cascade
-
数据库表修改:基本语句为
alter table <> + 修改内容--学生信息表增加email列 alter table student add email varchar(20); --删除学生电话列 alter table student drop column StudentPhone; --删除表 drop table student; --其他 ALTER TABLE<表名> DROP CONSTRAINT<完整性约束名>; ALTER TABLE <表名> RENAME TO <新表名>; ALTER TABLE <表名> RENAME <原列名> TO <新列名>; ALTER TABLE <表名> ALTER COLUMN <列名> TYPE<新的数据类型>; -
索引(Index)是一种按照关系表中指定列的取值顺序组织元组数据存储的数据结构,使用它可以加快表中数据的查询访问。
-
索引优点: 提高数据检索速度,可快速连接关联表,减少分组和排序时间。索引开销: 创建和维护索引都需要较大开销,索引会占用额外存储空间,数据操纵因维护索引带来系统性能开销
-
操作索引:on不要漏
create index birthday_idx on student(brithday);alter index birthday_idx rename to bday_idx;drop index bday_idx -
数据操纵:
插入:insert into <> values();
更新:update <> set … where…;
删除:delete from <> where…;
-
数据查询:查询语句基本结构
SELECT [ALL|DISTINCT] <目标列>[,<目标列>…] [ INTO <新表> ] FROM <表名|视图名>[,<表名|视图名>…] [ WHERE <条件表达式> ] [ GROUP BY <列名> [HAVING <条件表达式> ]] [ ORDER BY <列名> [ ASC | DESC ] ]; -
通配符:下划线(_)通配符用于代表一个未指定的字符。百分号(%)通配符用于代表一个或多个未指定的字符。
WHERE Email LIKE ’%@163.com’; -
视图:
create view <> as + 查询语句,as不要漏 -
视图应用:使用视图简化复杂SQL查询操作,使用视图提高数据访问安全性,提供一定程度的数据逻辑独立性,集中展示用户所感兴趣的特定数据
数据库设计与实现
-
数据库开发过程
- 数据需求分析阶段:从现实业务获取数据表单、报表、查询、业务规则、数据更新的说明,分析系统的数据特征、数据类型、数据取值约束,描述系统的数据关系、数据处理要求,建立系统的数据字典。
- 数据库设计阶段:数据库模型结构设计(概念数据模型、逻辑数据模型、物理数据模型),数据库索引、视图、查询设计,数据库表约束设计,数据库触发器、存储过程设计
- 数据库实现阶段:数据库创建,数据模型物理实现
- 数据库测试阶段:数据库数据上线,数据库系统测试
-
E-R模型的基本元素:
- 实体(Entity)是指问题域中存在的人、事、物、地点等客观事物在逻辑层面的数据抽象。它用于描述事物的数据对象,如客户、交易、产品、订单等。
- 属性是指描述实体特征的数据项。每个实体都具有1个或多个属性。
- 标识符是指标识不同实体实例的属性。标识符可以是1个或多个属性。
- 联系(Relationship)是指实体之间的联系,如“学生”与“成绩”的联系、“孩子”与“父亲”、“母亲”的联系等。
-
E-R模型的实体-联系符号:

-
基本建模实例

-
实体继承联系
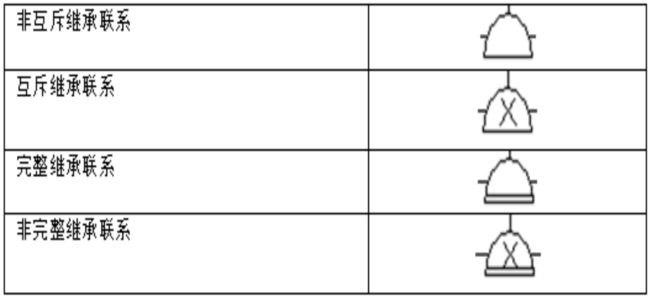
-
强实体与弱实体:弱实体是指那些对于另外实体有依赖关系的实体,即一个实体的存在必须以另一实体的存在为前提。而被依赖的实体称为强实体。
-
强弱实体联系
- 如果弱实体的标识符中含有所依赖实体的标识符,则该弱实体称为标识符(ID)依赖弱实体。
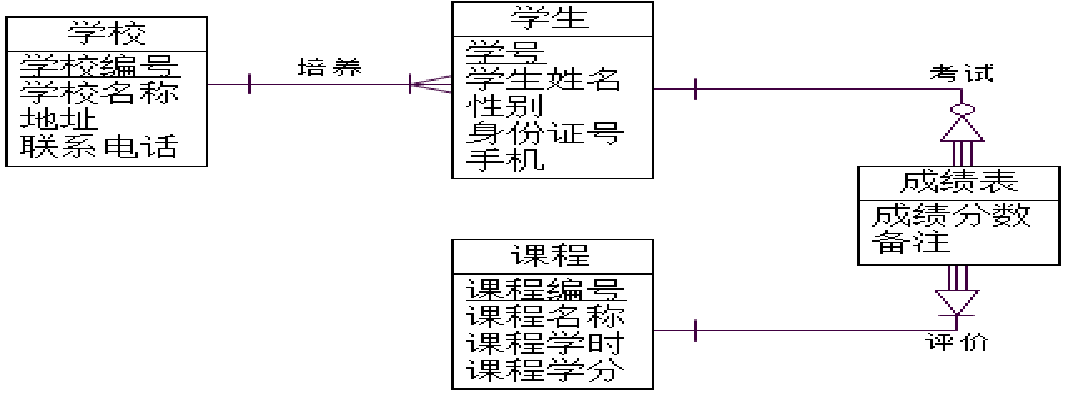
- 在有依赖联系的弱实体中,并非所有弱实体都是标识符(ID)依赖弱实体,它们可以有自己的标识符,这样的弱实体即为非标识符(ID)依赖弱实体。
- 如果弱实体的标识符中含有所依赖实体的标识符,则该弱实体称为标识符(ID)依赖弱实体。
-
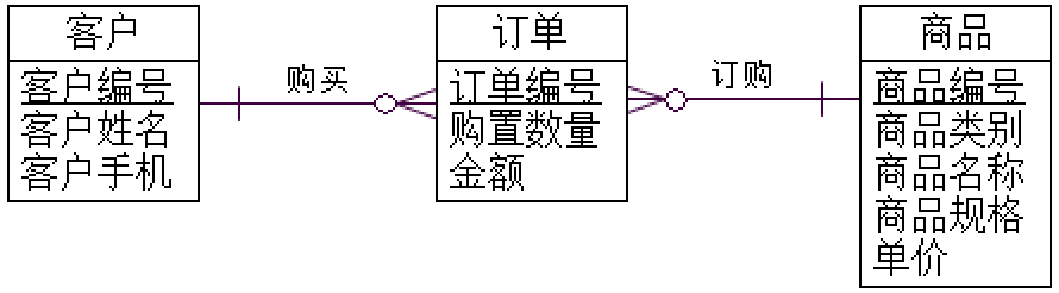
E-R模型拓展建模实例
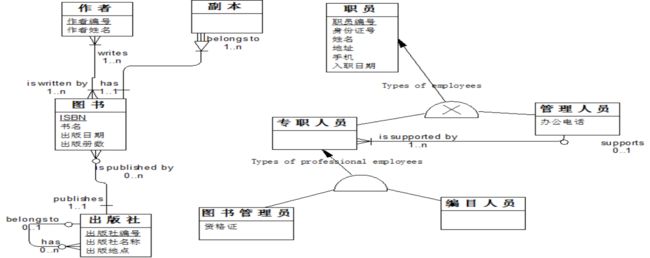
-
概念数据模型设计实例

-
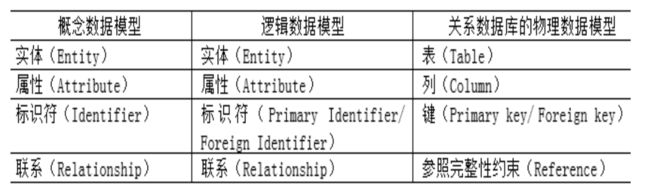
对E-R模型转换到关系模型的各类处理进行设计说明:
-
实体到关系表的转换:将每一个实体转换成一个关系表,实体属性转换为关系表的列,实体标识符转换为关系表的主键或外键。
-
弱实体到关系表的转换:为非标识符依赖时,加入强实体标识符作为外键列,为标识符依赖时,不仅加入强实体标识符作为外键列,同时也作为该表的主键列
-
实体联系的转换:
- 1:1实体联系:两个实体分别转换为关系表,将任意一个关系表的主键放入另一个关系表做外键。(谁做主键,谁做外键都可以,自主选择)


- 1:N实体联系:两个实体分别转换为关系表,然后将父实体关系表的主键放入子实体关系表中做外键,便可将1:N实体联系转换为关系表参照完整性约束。


- M:N实体联系:M:N实体联系不能像1:1和1:N实体联系那样直接转换。需要创建一个新的关联表,该关联表分别参照原有实体对应的关系表。


- 1:1实体联系:两个实体分别转换为关系表,将任意一个关系表的主键放入另一个关系表做外键。(谁做主键,谁做外键都可以,自主选择)
-
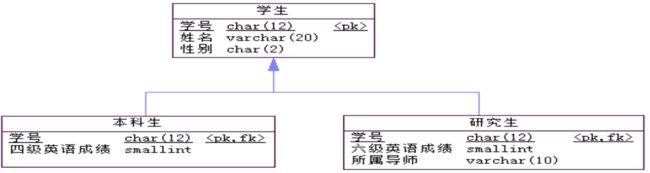
实体继承的转换:当带有实体继承联系的E-R模型转换关系模型时,首先父实体和子实体都各自转换为表,其属性均转换为表的列。在处理实体继承联系转换时,将父表中的主键放置到子表中,既做主键又做外键。

-
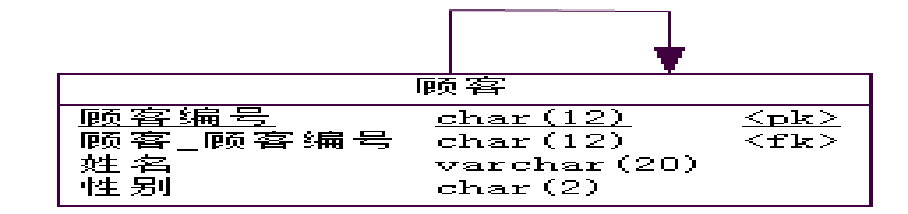
实体递归联系的转换:
- 1:N实体递归联系”的转换:首先将递归实体转换为表,其属性转换为列,标识符转换为主键,同时还将标识符转换为外键,实现自己对自己的参照。

- M:N实体递归联系的转换:增加一个关联表,该表分别参照原实体对应的关系表,并对原关系表建立两个参照完整性约束。
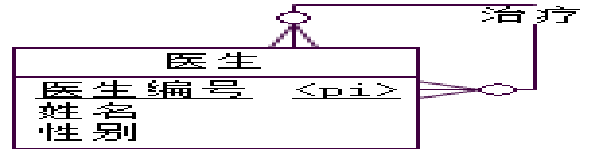

- 1:N实体递归联系”的转换:首先将递归实体转换为表,其属性转换为列,标识符转换为主键,同时还将标识符转换为外键,实现自己对自己的参照。
-
函数依赖的数学定义:设有一关系模式R(U), U 为关系R的属性集合,X和Y为属性U的子集。设t,s是关系R中的任意两个元组,如果t[X] = s[X],则t[Y] = s[Y]。那么称Y函数依赖于X,表示为X→Y。函数依赖的左部称为决定因子,右部称为依赖函数。决定因子和依赖函数都是属性的集合。
-
函数依赖的类型:完全函数依赖,部分函数依赖,属性传递依赖,多值函数依赖
-
设X、Y是某关系的不同属性集,如X→Y,且不存在X’⊂X ,使X’→Y,则Y称完全函数依赖,否则称Y部分函数依赖。
-
设X、Y、Z是某关系的不同属性集,有X→Y,X不依赖于Y , Y→Z,若X→Z,称Z对X存在函数传递依赖。
-
设U是关系模式R的属性集,X和Y是U的子集,Z=U-X-Y,xyz表示属性集XYZ的值。对于R的关系r,在r中存在元组(x, y1, z1)和(x, y2, z2)时,也存在元组(x, y1, z2)和(x, y2, z1),那么在模式R上存在多值函数依赖。
-
规范化数据库设计的原因:
- 减少数据库中的冗余数据,尽量使同一数据在数据库中仅保存一份,有效降低维护数据一致性的工作量。
- 设计合理的表间依赖关系和约束关系,便于实现数据完整性和一致性。
- 设计合理的数据库结构,便于系统对数据高效访问处理。
-
1NF:如果关系表中的属性不可再细分,该关系满足第1范式。反之,该表就不是关系表。
-
2NF:如果关系满足第1范式,并消除了关系中的属性部分函数依赖,该关系满足第2范式。
-
3NF:如果关系满足第2范式,并切断了关系中的属性传递函数依赖,该关系满足第3范式。
-
BCNF:在关系中,所有函数依赖的决定因子都是候选键,该关系满足BCNF范式。
-
4NF:如果关系满足BCNF范式,并消除了多值函数依赖,该关系满足第4范式。
-
逆规范化处理:适当降低规范化范式约束,不再要求一个关系表必须达到很高的规范化程度,而是允许适当的数据冗余性,以获取数据访问性能。
-
逆规范化处理的基本方法:(1)增加冗余列或派生列(2)多个关系表合并为一个关系表
数据库事务管理
-
需要数据库管理的原因:
- 数据库系统随规模增大,系统会变得异常复杂
- 多用户数据库应用带来数据库访问复杂性
- 数据安全和数据隐私对机构和用户都非常重要
- 数据库系统随数据量增加和使用时间增长其性能会降低
- 系统遭遇意外事件,数据库损坏或数据丢失
-
数据库管理的目标:
- 保障数据库系统正常稳定运行
- 充分发挥数据库系统的软硬件处理能力
- 确保数据库系统安全和用户数据隐私性
- 有效管理数据库用户及其角色权限
- 解决数据库系统性能优化、系统故障与数据损坏等问题
- 最大程度地发挥数据库对其所属机构的作用
-
数据库管理的内容:DBMS系统运行管理,数据库性能监控,数据库索引管理,数据库查询优化,数据库事务并发控制,数据库角色管理,数据库用户管理,数据库对象权限管理,数据安全管理,数据库备份,数据库恢复
-
在数据库中,事务(Transaction)是指由构成单个业务处理单元的一组数据库访问操作,要求它们要么都成功执行,要么都不执行。
-
事务ACID特性:
- 原子性(Atomicity):事务所有操作在数据库中要么全部执行,要么全部不执行。
- 一致性(Consistency):事务多次执行,其结果应一致。
- 隔离性(Isolation):事务与事务之间隔离,并发执行透明。
- 持续性(Durability ):事务完成后,数据改变必须是永久的。
-
事务并发执行原因:改善系统的资源利用率,减少事务运行的平均等待时间
-
事务SQL语句
START TRANSACTION;事务开始语句ROLLBACK;事务回滚语句COMMIT;事务提交语句SAVEPOINT;事务保存点语句START TRANSACTION; INSERT INTO college( collegeID, collegename)VALUES ('004', '外语学院'); INSERT INTO college( collegeID, collegename)VALUES ('005', '数学学院'); INSERT INTO college( collegeID, collegename)VALUES ('006', '临床医学院'); COMMIT; -
事务中不能使用的SQL语句:创建、修改、删除、恢复、加载数据库,备份日志文件,恢复日志文件,授权操作
-
并发控制目的:
- 支持并发事务处理,使更多用户并行操作,提高系统的并发访问能力。
- 保证一个事务工作不会对另一个事务工作产生不合理的影响。
-
并发控制需要解决的问题:前三个其实是同类问题
- 丢失更新数据:一个事务对一共享数据进行更新处理,但是以后查询该共享数据值时,发现该数据与自己的更新值不一致。(T1、T2两个事务并发执行,它们均对数据库共享数据A进行了非锁定资源的读写操作。当事务T1和T2均读入该共享数据A并修改,T2提交的结果破坏了T1提交的结果,导致T1的修改被丢失)
- 不可重复读取:一个事务对一个共享数据重复多次读取,但前后读取的数据不一致。(事务T1读取某一数据后,事务T2对其做了修改,当事务T1再次读该数据时,得到与前一次不同的值)
- 幻象读:一个事务对一个共享数据重复读取两次,但发现第二次读取比第一次读取的结果新增了一些数据。(事务T1按一定条件从数据库中读取某些数据记录后,事务T2在其中插入了一些记录,当T1再次按相同条件读取数据时,发现多了一些记录。称为幻象读取)
- 脏数据读取是指一个事务读取了被取消持久化的共享数据
-
并发事务调度就是控制多个事务的数据操作语句按照恰当的顺序访问共享数据,使这些事务执行之后,避免造成数据的不一致性,即解决“丢失更新数据”、“不可重复读”、“脏数据读”等问题。
-
可串行化调度:在事务并发执行中,只有当事务中数据操作调度顺序的执行结果与事务串行执行结果一样时,该并发事务调度才能保证数据操作的正确性和一致性。符合这样效果的调度称为可串行化调度。
-
DBMS并发事务调度目标:使并发事务调度实现的处理结果与串行化调度处理结果一致。
-
在DBMS中,通过加入锁表机制,来实现共享数据锁定访问,其加锁方式包含如下类型。
-
排它锁定(Lock-X)——锁定后,不允许其它事务对共享数据再加锁
-
共享锁定(Lock-S)——锁定后,只允许其它事务对共享数据添加读取锁
排它锁 共享锁 无锁 排它锁 否 否 是 共享锁 否 是 是 无锁 是 是 是
-
-
一级加锁协议:任何事务在修改共享数据对象之前,必须对该数据执行排它锁定指令,直到该事务处理完成,才进行解锁指令执行。使用一级加锁协议,可避免出现更新丢失问题。但不能解决“不可重复读取”、“脏读”等数据不一致问题。
-
二级加锁协议:在一级加锁协议基础上,针对并发事务的共享数据读操作,必须对该数据执行共享锁定指令,读完数据后即刻释放共享锁定。该加锁协议不但可以防止“丢失更新”的数据不一致性问题,还可防止出现脏读数据问题。但有可能会出现“不可重复读取”的数据不一致问题。
-
三级加锁协议:在一级加锁协议基础上,针对并发事务对共享数据进行读操作,必须对该数据执行共享锁定指令,直到该事务处理结束才释放共享锁定。该加锁协议不但可以防止“丢失更新”、“脏读”的数据不一致性问题,还可防止出现“不可重复读取”的数据一致性问题。
加锁协议级别 排它锁 共享锁 不丢失更新 不脏读 可重复读 一级 全程加锁 不加 是 否 否 二级 全程加锁 开始读数据时加锁,读完数据释放锁定 是 是 否 三级 全程加锁 全程加锁 是 是 是 -
并发事务的正确调度准则:一个给定的并发事务调度,当且仅当它是可串行化时,才能保证正确调度。保证可串行化的一个协议是:二阶段锁定协议
-
二阶段锁定协议规定每个事务必须分两个阶段提出加锁和解锁申请:增长阶段,事务只能获得锁,但不能释放锁。缩减阶段,事务只能释放锁,但不能获得新锁。
-
事务死锁状态:在基于锁机制的并发事务执行中,如果这些事务同时锁定两个以及以上资源时,可能会出现彼此都不能继续执行的状态,即事务死锁状态。
-
死锁出现的必要条件:互斥条件,请求和保持条件,不剥夺条件,环路等待条件
-
防范死锁的策略:
- 允许用户一次发出当前所需全部资源的锁定,使用完成后,再释放给其它用户访问。
- 规定所有应用程序锁定资源的顺序必须完全相同。
-
解决死锁的方法:当发生死锁时,回滚其中的一个事务,并取消它对数据库所做的改动。
数据库安全管理
-
数据库面临的安全问题:
- 黑客利用系统漏洞,攻击系统运行、窃取和篡改系统数据。
- 内部人员非法地泄露、篡改、删除系统的用户数据。
- 系统运维人员操作失误导致数据被删除或数据库服务器系统宕机。
- 系统故障导致数据库的数据损坏、数据丢失、数据库实例无法启动。
- 意外灾害事件(火灾、水灾、地震等自然灾害)导致系统被破坏。
-
数据库系统安全模型:用户身份鉴别,用户存取权限控制,操作系统安全保护,数据加密存储

身份验证:从应用系统层面确认登录用户是否是合法使用者
权限控制:从DBMS系统层面通过存取权限机制控制用户对数据的访问
系统防护:从操作系统层面提供的安全机制防范非法系统访问
加密存储:从数据存储层面通过加密算法对数据库中数据进行加密存储
-
数据库存取安全模型

-
用户创建:
CREATE USER <用户账号名> [ [WITH] option […]];书上加了WITH。 -
备选项
SUPERUSER | NOSUPERUSER CREATEDB | NOCREATEDB CREATEROLE | NOCREATEROLE INHERIT | NOINHERIT LOGIN | NOLOGIN REPLICATION | NOREPLICATION BYPASSRLS | NOBYPASSRLS CONNECTION LIMIT connlimit [ ENCRYPTED ] PASSWORD 'password' | PASSWORD NULL VALID UNTIL 'timestamp' IN ROLE role_name [, ...] -
用户修改、删除SQL语句
-- 修改用户“userA”的账号密码为“gres123”。同时也限制该用户的数据库连接数为10。 alter user "userA" connection limit 10 password 'gres123'; --其他 alter user <用户名> [ [ with ] option [ ... ] ]; --修改用户的属性 alter user <用户名> rename to <新用户名>; --修改用户的名称 alter user <用户名> set <参数项> { to | = } { value | default }; --修改用户的参数值 alter user <用户名> reset <参数项>; --重置用户参数值 --用户的删除 drop user "userA" -
权限管理SQL语句:
grant <权限名> on <对象名> to {数据库用户名|用户角色名};
revoke <权限名> on <对象名> from {数据库用户名|用户角色名};
deny <权限名> on <对象名> to {数据库用户名|用户角色名};-- 对用户“userA”实现授权SQL程序如下 grant select on department to usera; grant select on employee to usera; grant select on project to usera; grant select on assignment to usera;grant 是 on后面加表名,to后面加用户/角色名
-
数据库角色管理:和用户基本没有区别
create role <角色名> [ [ with ] option [ ... ] ]; --创建角色 alter role <角色名> [ [ with ] option [ ... ] ]; --修改角色属性 alter role <角色名> rename to <新角色名>; --修改角色名称 alter role <角色名> set <参数项> { to | = } { value | default };--修改角色参数值 alter role <角色名> reset <参数项>; --复位角色参数值 drop role <角色名>; --删除指定角色 --在工程项目管理系统中,假定需要在ProjectDB数据库内创建经理角色Role_Manager。该角色具有登录权限(Login)和角色继承权限(Inherit)系统权限,但它不是超级用户(SuperUser),不具有创建数据库权限(CreateDB)、创建角色权限(CreateRole)、数据库复制权限(Replication),此外数据库连接数(Connection Limit)不受限。 create role "role_manager" with login nosuperuser nocreatedb nocreaterole inherit noreplication connection limit -1; --在创建好经理角色Role_Manager后,还需要赋予该角色对数据库表Department、Employee、Project、Assignment的插入、修改、删除、查询权限。 grant select,insert,update,delete on department to "role_manager"; grant select,insert,update,delete on employee to "role_manager"; grant select,insert,update,delete on project to "role_manager"; grant select,insert,update,delete on assignment to "role_manager"; -
数据库系统故障原因:数据库服务器硬件故障,系统软件故障,用户误操作,系统意外断电
-
数据库备份——是指将数据库当前数据和状态进行副本复制,以便当数据库受到破坏或丢失数据时可以进行修复。
-
数据库恢复——是指数据库中数据丢失或被破坏时,从备份副本将数据库从错误状态恢复到某一正确状态。
-
备份SAMPLE数据库到一个G磁盘的根目录文件Sample.bak中。
BACKUP DATABASE SAMPLE TO DISK = ‘G:\Sample.bak'; -
从存储备份文件中恢复SAMPLE数据库。
RESTORE DATABASE SAMPLE FROM DISK = ‘G:\Sample.bak';
数据库应用编程
-
ODBC简介:ODBC全称为开放式数据库互连(Open DataBase Connectivity)技术,ODBC实现了应用程序对多种不同DBMS的数据库的访问,实现了数据库连接方式的变革。
ODBC定义了一套基于SQL的、公共的、与数据库无关的API(应用程序设计接口);使每个应用程序利用相同的源代码就可访问不同的数据库系统,存取多个数据库中的数据;从而使得应用程序与数据库管理系统(DBMS)之间在逻辑上的独立性,使应用程序具有数据库无关性。

-
应用程序使用ODBC访问数据库的步骤:
- 首先必须用ODBC管理器注册一个数据源
- 管理器根据数据源提供的数据库位置、数据库类型及ODBC驱动程序等信息,建立起ODBC与具体数据库的联系
- 应用程序只需将数据源名提供给ODBC,ODBC就能建立起与相应数据库的连接
- 这样,应用程序就可以通过驱动程序管理器与数据库交换信息
- 驱动程序管理器负责将应用程序对ODBC API的调用传递给正确的驱动程序
- 驱动程序在执行完相应的SQL操作后,将结果通过驱动程序管理器返回给应用程序
-
JDBC全称为Java DataBase Connectivity(Java数据库连接)技术 ,是一种用于执行SQL语句的Java API。它由一组用Java编程语言编写的类和接口组成。这个API由java.sql.*包中的一些类和接口组成,它为数据库开发人员提供了一个标准的API,使他们能够用纯Java API 来编写数据库应用程序。
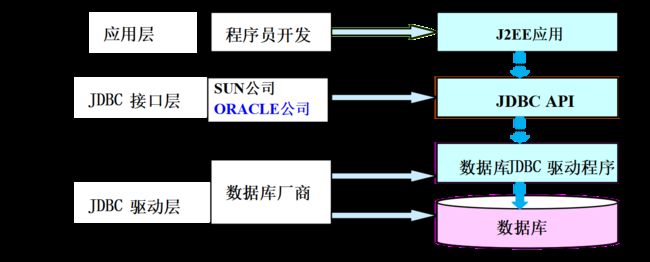
-
对比ODBC和JDBC,可以从平台依赖型,编程语言和数据库无关性三个角度的对比。
-
JDBC访问数据库步骤:应用程序开始——导入java.sql包——加载并注册驱动程序——创建Connection对象——创建Statement对象——执行SQL语句——使用ResultSet对象返回结果——关闭ResultSet对象——关闭Statement对象——关闭Connection对象——结束
-
JDBC技术:
加载驱动:
Class.forName("org.postgresql.Driver");建立连接:数据库建立连接的方法是调用
Connection conn = DriverManager.getConnection(URL,userName,passWord);方法创建Statement对象:
Statement stmt = conn.createStatement();执行SQL语句:主要掌握两种执行SQL语句的方法:executeQuery()、executeUpdate()
Statement stmt = conn.createStatement(); String sql = "INSERT INTO public.student (sid, sname, gender, birthday, major, phone)" + " VALUES ('2017001', '张山', '男', '1998-10-10','软件工程','13602810001')"; stmt.executeUpdate(sql);ResultSet保存结果集:ResultSet里的数据一行一行排列,每行有多个字段,并且有一个记录指针,指针所指的数据行叫做当前数据行,我们只能来操作当前的数据行。我们如果想要取得某一条记录,就要使用ResultSet的next()方法 ,如果我们想要得到ResultSet里的所有记录,就应该使用while循环。
import java.sql.*; public class JDBCDemo { public static void main(String[] args) { Connection conn = null; Statement stmt = null; String URL = "jdbc:postgresql://localhost:5432/booksale"; String userName = "postgres"; String password = "123456"; try { Class.forName("org.postgresql.Driver"); conn = DriverManager.getConnection(URL, userName, password); String sql = "select * from book"; stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(sql); while (rs.next()) { String bookISBN = rs.getString("book_isbn"); String bookName = rs.getString("book_name"); System.out.println(bookISBN + " " + bookName); } conn.close(); } catch (Exception e) { System.out.println(e.getMessage()); } } }关闭连接:
close()方法 -
Connection.prepareStatement(String sql)创建PreparedStatement对象,实现动态SQL语句查询,prepareStatement可以使用?替换变量 -
preparedStatement预编译SQL语句,并支持批处理,执行查询有类似Statement对象的三种执行方式,且执行方法中没有参数。
-
prepareStatement.executeUpdate()执行更新;
-
prepareStatement对象使用addBatch()向批处理中加入更新语句
-
executeBatch()方法用于成批地执行SQL语句。
String insertSql = "INSERT INTO stu_score(sid, cid, score) VALUES (?,?,?)"; String querySql = "select sid, cid, score from stu_score where score>=?"; PreparedStatement psInsert = conn.prepareStatement(insertSql); //定义动态执行SQL语句对象 PreparedStatement psQuery = conn.prepareStatement(querySql); //定义动态执行SQL语句对象 for (int i=0; i<sid.length; i++) { psInsert.setString(1, sid[i]); psInsert.setString(2, cid[i]); psInsert.setInt(3, score[i]); psInsert.addBatch(); //添加批处理的记录 } psInsert.executeBatch();//批处理执行多条数据记录 psQuery.setInt(1, 80); ResultSet rs = psQuery.executeQuery(); while (rs.next()) { // 判断是否还有下一个数据 System.out.println(rs.getString("sid") + " " + rs.getString("cid") + " " + rs.getInt("score") ); } psQuery.close(); psInsert.close(); conn.close();
-
-
PostgreSQL使用CREATE FUNCTION命令创建函数或存储过程。
CREATE [ OR REPLACE ] FUNCTION name ( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] ) [ RETURNS retype | RETURNS TABLE ( column_name column_type [, ...] ) ] AS $$ --$$用于声明存储过程的实际代码的开始 DECLARE -- 声明段 BEGIN --函数体语句 END; $$ LANGUAGE lang_name; --$$ 表明代码的结束, LANGUAGE后面指明所用的编程语言加分号的位置要注意:声明段,函数体,END,language plpgsql
--创建一个名为countRecords()的存储过程统计STUDENT表的记录数。 create or replace function countRecords () returns integer as $count$ declare count integer; begin select count(*) into count from student; return count; end; $count$ language plpgsql; --执行存储过程 select * from countRecords (); --删除存储过程 drop function if exists countRecords ();特别的,在 PostgreSQL 中,当函数定义了输出参数时,不能使用
RETURN语句来返回结果。相反,应该在函数体内使用OUT参数来指定输出结果。create or replace function Pro_CurrentSale(out number numeric, out allmoney money) as $count$ begin select sum(Sale_Number) into number from Sale where Sale_Date = '2023-04-21'; select sum(Sale_Amount) into allmoney from Sale where Sale_Date = '2023-04-21'; end; $count$ LANGUAGE plpgsql;plpgsql语法:
--声明局部变量 declare count intger; rec RECORD;--RECORD不是真正的数据类型,只是一个占位符。 --条件语句 IF boolean-expression THEN statements ELSIF boolean-expression THEN statements ELSIF boolean-expression THEN statements ELSE statements END IF; --循环语句1 LOOP count=count+1; EXIT WHEN count > 100; CONTINUE WHEN count < 50; count=count+1; END LOOP; --循环语句2 WHILE amount_owed > 0 AND balance > 0 LOOP --do something END LOOP; --循环语句3 FOR i IN 1...10 LOOP RAISE NOTICE 'i IS %', i; END LOOP; --遍历命令结果 declare rec RECORD ; FOR rec IN SELECT sid,sname FROM student LOOP raise notice ‘%-,%-’,rec.sid, rec.sname; END LOOP; -
触发器是特殊类型的存储过程,主要由操作事件(INSERT、UPDATE、DELETE) 触发而被自动执行。
CREATE TRIGGER 触发器名
{ BEFORE | AFTER | INSTEAD OF }
ON 表名
[ FOR [ EACH ] { ROW | STATEMENT } ]
EXECUTE PROCEDURE 存储过程名 ( 参数列表 )
创建触发器被触发时所要执行的触发器函数,该函数的类型必须是TRINGER型,是触发器的执行函数。
触发器相关的特殊变量:
1. NEW :数据类型是RECORD。对于行级触发器,它存有INSERT或UPDATE操作产生的新的数据行。对于语句级触发器,它的值是NULL。
2. OLD :数据类型是RECORD。对于行级触发器,它存有被UPDATE或DELETE操作修改或删除的旧的数据行。对于语句级触发器,它的值是NULL。
3. TG_OP:数据类型是text;是值为INSERT、UPDATE、DELETE 的一个字符串,它说明触发器是为哪个操作引发。
--为了防止非法修改stu_score表的课程成绩,创建audit_score表记录stu_score表的成绩变化,创建触发器函数score_audit()
CREATE OR REPLACE FUNCTION score_audit() RETURNS TRIGGER AS $score_audit$
BEGIN
IF (TG_OP = 'DELETE') THEN
INSERT INTO audit_score SELECT user, old.sid, old.cid, now(), old.score;
RETURN OLD;
ELSIF (TG_OP = 'UPDATE') THEN
INSERT INTO audit_score
SELECT user, old.sid, old.cid, now(), old.score, new.score
WHERE old.sid = new.sid AND old.cid = new.cid;
RETURN NEW;
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO audit_score SELECT user, new.sid, new.cid, now(), null, new.score;
RETURN NEW;
END IF;
RETURN NULL;
END;
$score_audit$ LANGUAGE plpgsql;
--接下来在stu_score表上创建触发器score_audit_triger
CREATE TRIGGER score_audit_triger
AFTER INSERT OR UPDATE OR DELETE ON stu_score
FOR EACH ROW EXECUTE PROCEDURE score_audit();
-
使用存储过程的优点
- 减少网络通信量
- 执行速度更快
- 更强的适应性
- 降低了业务实现与应用程序的耦合
- 降低了开发的复杂性
- 保护数据库元信息
- 增强了数据库的安全性
-
使用存储过程的缺点
- SQL本身是一种结构化查询语言,而存储过程本质上是过程化的程序;面对复杂的业务逻辑,过程化处理逻辑相对比较复杂;而SQL语言的优势是面向数据查询而非业务逻辑的处理。
- 如果存储过程的参数或返回数据发生变化,一般需要修改存储过程的代码,同时还需要更新主程序调用存储过程的代码。
- 开发调试复杂,由于缺乏支持存储过程的集成开发环境,存储过程的开发调试要比一般程序困难。
- 可移植性差
NoSQL数据库
-
关系数据库面临的挑战:
- 数据库高并发读/写需求
- 数据的高效存储和处理
- 数据库高扩展性和高可用性需求
- 大数据处理方面的要求
-
分布式数据库=数据库 + 网络
技术思想:将数据分散存储,海量数据逻辑分片,存储容量大,并发访问量高
分布式数据库必须具有高可扩展性、高并发性、高可用性等特征
-
大数据的5V特征:超量volume,高速velocity,异构variety,真实veracity,价值value
-
在分布式的环境下设计和部署系统时,有3个核心的需求:CAP理论:一致性(Consistency),可用性(Availability)和分区容忍性(Partition Tolerance)
-
BASE模型:
- Basically Available :基本可用;系统能够基本运行,一直提供服务。
- Soft-state :软状态/柔性事务。“Soft state” 可以理解为"无连接"的, 而 “Hard state” 是"面向连接"的;系统不要求一直保持强一致状态。
- Eventual Consistency :最终一致性 系统在某个时刻达到最终一致性。
- BASE定义为CAP中AP的衍生,在分布式环境下, BASE是数据的属性,BASE强调基本的可用性,按照功能划分数据库
-
最终一致性理论:因果一致性、读一致性、会话一致性、单调读一致性、单调写一致性。
-
NoSQL理论基础:CAP理论,BASE理论,最终一致性理论
-
NoSQL共同特征:不需要预定义模式,无共享架构,弹性可扩展,分区,异步复制,BASE
-
NoSQL普遍采用的技术:简单数据类型,元数据和应用数据的分离,弱一致性
-
NoSQL优缺点:优点表现在: 高可扩展性、分布式计算、低成本、 架构的灵活性,半结构化数据、 没有复杂的关系。缺点: 没有标准化、有限的查询功能(到目前为止)、最终一致不直观等
-
NoSQL数据库分类:
- 键值对存储方式(存储的数据是有键(key)和值(value)两部分组成,通过key快速查询到其value,value的格式可以根据具体应用来确定):Redis
- 列存储方式(将同一列的数据存储在一起,可以存储结构化和半结构化数据):HBase
- 文档存储方式(存储的内容是文档型的,可以用格式化文件(类似json、XML等)的格式存储):MongoDB
- 图形存储方式(数据以有向加权图方式进行存储):Neo4j
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值 (key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | 与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容 | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案 |