tflite模型转换和量化
ref
https://www.tensorflow.org/lite/convert?hl=zh-cn
if you're using TF2 then the following will work for you to post quantized the .pb file.
import tensorflow as tf
graph_def_path = "resnet50_v1.pb"
tflite_model_path = "resnet50_v1.tflite"
input_arrays = ["input_tensor"]
input_shapes = {"input_tensor" :[1,224,224,3]}
output_arrays = ["softmax_tensor", "ArgMax"]
converter = tf.compat.v1.lite.TFLiteConverter.from_frozen_graph(graph_def_path, input_arrays, output_arrays, input_shapes)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
with open(tflite_model_path, "wb") as f:
f.write(tflite_model)
incase if you want full int8 quantization then
import tensorflow as tf
from google.protobuf import text_format
graph_def_path = "resnet50_v1.pb"
tflite_model_path = "resnet50_v1_quant.tflite"
input_arrays = ["input_tensor"]
input_shapes = {"input_tensor" :[1,224,224,3]}
output_arrays = ["softmax_tensor", "ArgMax"]
converter = tf.compat.v1.lite.TFLiteConverter.from_frozen_graph(graph_def_path, input_arrays, output_arrays, input_shapes)
tflite_model = converter.convert()
converter.optimizations = [tf.lite.Optimize.DEFAULT]
image_shape = [1,224,224,3]
def representative_dataset_gen():
for i in range(10):
# creating fake images
image = tf.random.normal(image_shape)
yield [image]
# IMAGE_MEAN = 127.5;
# IMAGE_STD = 127.5;
# def norm_image(img):
# img_f = (np.array(img, dtype="float32")- IMAGE_MEAN) / IMAGE_STD;
# return img_f
# def read_image(img_name):
# img = cv2.imread(img_name)
# tgt_shape = [299,299]
# img = cv2.resize(img, tgt_shape).reshape([1,299,299,3])
# return img
# def representative_dataset_gen():
# img_folder="resnet_v2_101/test_imgs/"
# img_names = glob.glob(img_folder+"*.jpg")
# for img_name in img_names:
# img = read_image(img_name)
# img = norm_image(img)
# yield [img]
converter.representative_dataset = tf.lite.RepresentativeDataset(representative_dataset_gen)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8 # or tf.uint8
converter.inference_output_type = tf.int8 # or tf.uint8
tflite_model = converter.convert()
with open(tflite_model_path, "wb") as f:
f.write(tflite_model)
FP16量化:
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()float16 量化的优点如下:
将模型的大小缩减一半(因为所有权重都变成其原始大小的一半)。
实现最小的准确率损失。
支持可直接对 float16 数据进行运算的部分委托(例如 GPU 委托),从而使执行速度比 float32 计算更快。
float16 量化的缺点如下:
它不像对定点数学进行量化那样减少那么多延迟。
默认情况下,float16 量化模型在 CPU 上运行时会将权重值“反量化”为 float32。(请注意,GPU 委托不会执行此反量化,因为它可以对 float16 数据进行运算。)
具有 8 位权重的 16 位激活
也就是A18W8量化
这是一个实验性量化方案。它与“仅整数”方案类似,但会根据激活的范围将其量化为 16 位,权重会被量化为 8 位整数,偏差会被量化为 64 位整数。这被进一步称为 16x8 量化。
这种量化的主要优点是可以显著提高准确率,但只会稍微增加模型大小。
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.representative_dataset = representative_dataset
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8]
tflite_quant_model = converter.convert()如果模型中的部分算子不支持 16x8 量化,模型仍然可以量化,但不受支持的算子会保留为浮点。要允许此操作,应将以下选项添加到 target_spec 中。
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.representative_dataset = representative_dataset
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS]
tflite_quant_model = converter.convert()通过此量化方案提高了准确率的用例示例包括:* 超分辨率、* 音频信号处理(如降噪和波束成形)、* 图像降噪、* 单个图像 HDR 重建。
这种量化的缺点是:
- 由于缺少优化的内核实现,目前的推断速度明显比 8 位全整数慢。
- 目前它不兼容现有的硬件加速 TFLite 委托。
注:这是一项实验性功能。
可以在此处找到该量化模型的教程。
模型准确率
由于权重是在训练后量化的,因此可能会造成准确率损失,对于较小的网络更是如此。TensorFlow Lite 模型存储库为特定网络提供了预训练的完全量化模型。请务必检查量化模型的准确率,以验证准确率的任何下降都在可接受的范围内。有一些工具可以评估 TensorFlow Lite 模型准确率。
另外,如果准确率下降过多,请考虑使用量化感知训练。但是,这样做需要在模型训练期间进行修改以添加伪量化节点,而此页面上的训练后量化技术使用的是现有的预训练模型。
量化张量的表示
8 位量化近似于使用以下公式得到的浮点值。
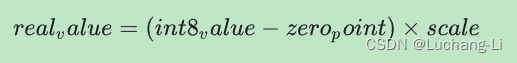
该表示包含两个主要部分:
-
由 int8 补码值表示的逐轴(即逐通道)或逐张量权重,范围为 [-127, 127],零点等于 0。
-
由 int8 补码值表示的逐张量激活/输入,范围为 [-128, 127],零点范围为 [-128, 127]。
有关量化方案的详细信息,请参阅我们的量化规范。对于想要插入 TensorFlow Lite 委托接口的硬件供应商,我们鼓励您实现此规范中描述的量化方案。