spaCy V3.0 基于规则匹配(4)----举例说明基于规则与基于统计模型组件的组合命名实体识别NER
可以通过多种方式组合基于统计模型和基于规则的组件。基于规则的组件可以通过为特定词符(Tokens)预先标记词性、命名实体或句子边界来提高统计模型的准确性。统计模型通常会采用这些预设标记,来提高其他判定的准确性。也可以在统计模型之后使用基于规则的组件来更正常见错误。最后,基于规则的组件可以引用统计模型设置的属性,以实现更抽象的匹配逻辑。
例1: 扩充命名实体
当使用经过预训练的命名实体识别模型从文本中提取信息时,可能会发现预测的span仅包括你想要查找实体的一部分。发生这种问题,一种情况是,统计模型错误地预测了实体;另一种情况是,在原始训练语料库中定义实体类型的方法与应用程序所需要的不匹配。
例如,语料库spaCy的Chinese pipelines定义一个PERSON实体时,被训练为只匹配人名,没有包含像“先生”或“老师”这样的头衔。这样做是合理的,因为可以更容易地将实体类型解析回知识库。但是如果你的应用需要包括头衔的全名呢?
虽然可以通过使用更多包含头衔的span样本来更新模型,从而教给模型一个PERSON实体的新定义,但这可能不是最有效的方法。现有的模型是在200多万字的基础上训练的,因此为了完全改变实体类型的定义,你可能需要大量的训练样本。但是,如果已经有了预测的PERSON实体,则可以使用基于规则的方法来检查它们是否带有头衔,如果是,则将实体范围扩展一个Token。毕竟,本例中所有头衔的共同点是,它们总是出现在person实体之后的下一个Token中。
- 方法一:通过添加自定义管道组件完成
@Language.component("expand_person_entities")
def expand_person_entities(doc):
new_ents = []
for ent in doc.ents:
# 当 ent是第一个token时,不检查头衔
if ent.label_ == "PERSON" and ent.start != 0:
prev_token = doc[ent.start - 1]
if prev_token.text in ("先生", "老师", "女士", "教授"):
new_ent = Span(doc, ent.start - 1, ent.end, label=ent.label)
new_ents.append(new_ent)
else:
new_ents.append(ent)
else:
new_ents.append(ent)
doc.ents = new_ents
return doc
给上面的函数传入一个Doc对象,修改doc.ents后返回doc。使用@Language.component装饰符,我们可以将它注册为一个管道组件,这样它可以在处理文本时自动运行。用nlp.add_pipe将其添加到当前管道。
完整示例代码如下:
# coding=utf-8
import spacy
from spacy.language import Language
from spacy.tokens import Span
nlp = spacy.load("zh_core_web_sm")
@Language.component("expand_person_entities")
def expand_person_entities(doc):
new_ents = []
for ent in doc.ents:
# 当 ent是第一个token时,不检查头衔
if ent.label_ == "PERSON" and ent.start != 0:
next_token = doc[ent.start + 1]
if next_token.text in ("先生", "老师", "女士", "教授"):
new_ent = Span(doc, ent.start, ent.end + 1, label=ent.label)
new_ents.append(new_ent)
else:
new_ents.append(ent)
else:
new_ents.append(ent)
doc.ents = new_ents
return doc
# 将该组件添加到命名实体识别器之后
nlp.add_pipe("expand_person_entities", after="ner")
doc = nlp("在2020年的十大年度人物中,有两位教师的名字。一位是献身山区贫困家庭女子教育的张桂梅老师,一位则是以毕生精力传播中国古典诗词文化的叶嘉莹先生。")
print([(ent.text, ent.label_) for ent in doc.ents if ent.label_ == 'PERSON'])
#运行结果:
#[('张桂梅老师', 'PERSON'), ('叶嘉莹先生', 'PERSON')]
- 方法二:使用扩展属性
该方法是通过给Span对象(包括doc.ents中的实体spans)扩展用户属性,如 ._.person_title。这种方法具有保持实体文本完整的优势,这样人名仍然可以在知识库中查找。下面的函数使用一个Span对象,检查PERSON实体下一个Token是否包含头衔,如果是则返回头衔。Span.doc属性使我们可以轻松获取span的父文档。
def get_person_title(span):
if span.label_ == "PERSON" and span.start != 0:
next_token = span.doc[span.start + 1]
if next_token.text in ("先生", "老师", "女士", "教授"):
return next_token.text
现在可以用Span.set_extension给span添加用户扩展属性,并用get_person_title作为其getter函数:
import spacy
from spacy.tokens import Span
nlp = spacy.load("zh_core_web_sm")
def get_person_title(span):
if span.label_ == "PERSON" and span.start != 0:
next_token = span.doc[span.start + 1]
if next_token.text in ("先生", "老师", "女士", "教授"):
return next_token.text
# 注册Span的 'person_title' 属性
Span.set_extension("person_title", getter=get_person_title)
doc = nlp("在2020年的十大年度人物中,有两位教师的名字。一位是献身山区贫困家庭女子教育的张桂梅老师,一位则是以毕生精力传播中国古典诗词文化的叶嘉莹先生。")
print([(ent.text, ent.label_, ent._.person_title) for ent in doc.ents if ent.label_ == 'PERSON'])
#运行结果:
#[('张桂梅', 'PERSON', '老师'), ('叶嘉莹', 'PERSON', '先生')]
例二:结合词性、句法依存关系的实体识别
此用法尚未想出贴切的中文例子,先用英文举例,以后想出来会及时更新。
如果你有合适的中文例子,望不吝赐教,谢谢!
我们来想象这样一个任务:你想从职业履历中找到人名、公司名,以及是其目前供职的公司还是曾经供职的公司。一种方法是尝试训练一个能预测CURRENT_ORG 和 PREVIOUS_ORG实体标签的命名实体识别组件模型,这两者的区别十分细微,模型很难学会正确区分。比如对于“Acme Corp Inc.”,其并本身没有什么特性能够表明是“现公司”还是“前公司”。
然而,一个句子的语法却能提供一些重要的线索:我们可以检查像“work”这样的触发词,它们是过去时态还是现在时态,是否附有公司名称,以及这个人是否是主语。所有这些信息都可以在词性标签和依存关系解析中找到。
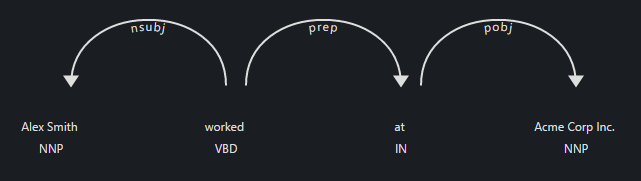
比如: “Alex Smith worked at Acme Corp Inc.”
在这个例子中,“worked”是这个句子的ROOT,是一个过去时动词,它的主语是“Alex Smith”。“at Acme Corp Inc.”是连接在动词“worked”后面的介词短语。要提取这种关系,我们可以从观察预测出的 PERSON 实体开始,找到他们的 head ,并检查他们是否与“工作”这样的触发词相关联。下一步,我们可以检查连接到 head 的介词短语,以及它们是否包含 ORG 实体。最后,为了确定公司是否是 PERSON 实体当前的公司,检查 head 的词性标签。
person_entities = [ent for ent in doc.ents if ent.label_ == "PERSON"]
for ent in person_entities:
# 因为实体是一个span, 我们需要使用它的 root token.
head = ent.root.head
if head.lemma_ == "work":
# 检查其子节点是否包含介词
preps = [token for token in head.children if token.dep_ == "prep"]
for prep in preps:
orgs = [token for token in prep.children if token.ent_type_ == "ORG"]
# 如果动词是过去时态则公司是前公司
print({"person": ent, "orgs": orgs, "past": head.tag_ == "VBD"})
处理文本时若需自动应用此逻辑,可以将其作为自定义管道组件添加到nlp对象中。上面的逻辑也期望将实体合并到单个Token中。spaCy有内置merge_entities来处理这个问题。除了打印结果,还可以将其写入实体span的自定义属性,例如 ..orgs 或 ..prev_orgs 以及 ._.current_orgs。
import spacy
from spacy.language import Language
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
@Language.component("extract_person_orgs")
def extract_person_orgs(doc):
person_entities = [ent for ent in doc.ents if ent.label_ == "PERSON"]
for ent in person_entities:
head = ent.root.head
if head.lemma_ == "work":
preps = [token for token in head.children if token.dep_ == "prep"]
for prep in preps:
orgs = [token for token in prep.children if token.ent_type_ == "ORG"]
print({'person': ent, 'orgs': orgs, 'past': head.tag_ == "VBD"})
return doc
# To make the entities easier to work with, we'll merge them into single tokens
nlp.add_pipe("merge_entities")
nlp.add_pipe("extract_person_orgs")
doc = nlp("Alex Smith worked at Acme Corp Inc.")
#{'person': Alex Smith, 'orgs': [Acme Corp Inc.], 'past': True}
=基于规则的匹配部分,到此结束=