NLP-语义解析(Text2SQL):Text2SQL 数据集
Text2SQL
Text to SQL( 以下简称Text2SQL),是将自然语言文本(Text)转换成结构化查询语言SQL的过程,属于自然语言处理-语义分析(Semantic Parsing)领域中的子任务。
它的目的可以简单概括为:“打破人与结构化数据之间的壁垒”,即普通用户可以通过自然语言描述完成复杂数据库的查询工作,得到想要的结果。
Text2SQL 简单示例 (Demo)
示例
表_1-1
| 代码 | 名称 | 上市地点 | 收盘价 | 周涨跌幅 | 月涨跌幅 |
|---|---|---|---|---|---|
| SINA.O | 新浪 | 纳斯达克 | 58.93 | -4.52 | 8.791 |
| BITA.N | 易车 | 纽约证券交易所 | 18.11 | -4.78 | -11.742 |
| JRJC.O | 金融界 | 纳斯达克 | 1.09 | -9.17 | 2.834 |
| SFUN.N | 淘屏 | 纳斯达克 | 1.09 | -9.17 | 2.834 |
| SFUN.N | 搜房网 | 纽约证券交易所 | 1.71 | -9.52 | 28.575 |
| RENN.N | 人人网 | 纽约证券交易所 | 1.61 | -9.55 | 14.18 |
Query:新浪和人人网的周涨跌幅分别是多少?
SQL: SELECT 周涨跌幅 FROM 表_1-1 WHERE 名称=‘新浪’ OR 名称=‘人人网’
用户输入一句普通文本,模型将其转换为 SQL,查询数据库得到结果:"-4.52, -9.55"
当然实际场景或业务中,需要查询的内容可能更加复杂(例如涉及跨表、嵌套查询,group by/having 等查询条件等)。
SQL组成
SQL组成来自三部分:数据库中元素(表名、列名)、问题中的词汇、 SQL关键字
已有数据集 (Datasets)
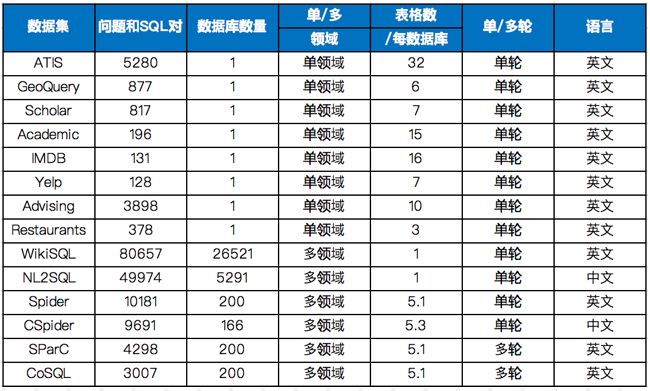
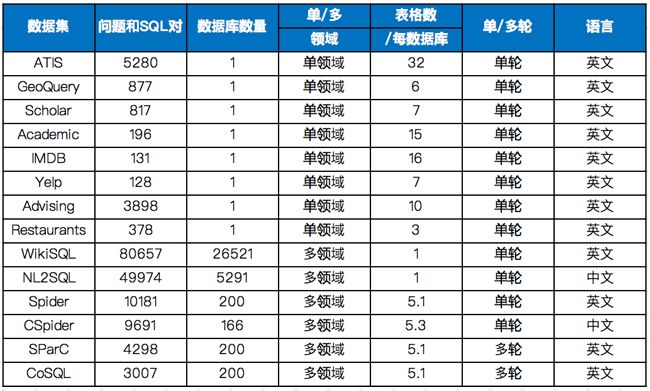
现有Text2SQL数据集List:
1.WikiSQL
WikiSQL 标注数据集 适合入门数据集
WikiSQL是一个大型的语义解析数据集,由80,654个自然语句表述和24,241张表格的sql标注构成。
WikiSQL中每一个问句的查询范围仅限于同一张表,不包含排序、分组、子查询等复杂操作。
虽然数据规模大,SQL语法却非常简单;适合做NL2SQL任务入门。
2.Spider
Spider 难度最大数据集
耶鲁大学在2018年新提出的一个大规模的NL2SQL(Text-to-SQL)数据集。
该数据集包含了10,181条自然语言问句、分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同的领域。
涉及的SQL语法最全面,是目前难度最大的NL2SQL数据集。
3.CSpider
Cspider 中文Spider
CSpider是Spider的中文版,西湖大学出品。对该任务感兴趣的同学可以尝试去链接中对应的榜单刷榜,目前只有2个team提交。
美中不足的是,数据集只是翻译了Spider的question部分,表格列名等仍是英文,需要额外处理对齐。
数据集已完整打包在data目录下。
4.WikitableQuestion
3.WikitableQuestion 表格问答
WikitableQuestion是斯坦福自然语言处理小组的工作。数据集中每个问题都带有来自Wikipedia的表格。给定问题和表格,任务是根据表格回答问题。
数据集包含来自各种主题的2,108个表和具有不同复杂性的22,033个问题
5.天池NL2SQL中文挑战赛数据集
NL2SQL天池大赛 中文NL2SQL数据集
2020年之前公开的Text2SQL数据集中唯一一份高质量的中文数据集,由比赛主办方追一科技提供。数据集使用金融以及通用领域的表格数据作为数据源,提供在此基础上人工标注的自然语言和SQL语句的匹配对。
一共包含49,867条有标注的训练集数据,10,000条无标注数据作为测试集
6.DuSQL中文数据集
2020语言与智能技术竞赛:语义解析任务 难度接近Spider的中文数据集
2020语言与智能技术竞速提供的大规模开放领域的复杂中文Text-to-SQL数据集,语法覆盖了 "order by","group by","having","嵌套SQL","join" 等几乎所有SQL语法。
包含18602训练集,2039开发集和4868测试集
7.Sparc
Sparc 多轮交互Text2SQL
耶鲁大学在2019年提出的基于对话的Text-to-SQL数据集。
SParC是一个跨域上下文语义分析的数据集,是Spider任务的上下文交互版本。SParC由4298个对话(12k+个单独的问题,每个对话平均4-5个子问题,由14个耶鲁学生标注)组成,这些问题通过用户与138个领域的200个复杂数据库进行交互获得。
8.CoSQL
CoSQL 多轮交互Text2SQL
耶鲁大学在2019年提出的基于对话的Text-to-SQL数据集。
内容和Sparc相似,但是标注风格略有不同,例如数据集中SQL各关键字的分布差异较大。
9.CHASE
CHASE 多轮交互中文Text2SQL (ACL 2021)
2021年,微软亚研院和北航、西安交大联合提出的首个大规模上下文依赖的Text-to-SQL中文数据集。
内容分为CHASE-C和CHASE-T两部分,CHASE-C从头标注实现,CHASE-T将Sparc从英文翻译为中;相比以往数据集,CHASE大幅增加了hard类型的数据规模,减少了上下文独立样本的数据量,弥补了Text2SQL多轮交互任务中文数据集的空白。
GitHub - yechens/NL2SQL: Text2SQL 语义解析数据集、解决方案、paper资源整合项目
GitHub - jkkummerfeld/text2sql-data: A collection of datasets that pair questions with SQL queries. 首届中文NL2SQL挑战赛_算法大赛_赛题与数据_天池大赛-阿里云天池