Distributed Heuristic Multi-Agent Path Finding with Communication
基于通信的分布启发式多智能体路径规划算法
文章目录
- 基于通信的分布启发式多智能体路径规划算法
- 一、introduction
- 二、学习环境
-
- 1.环境设定
- 2.观察表征
- 3.动作空间
- 4.奖励函数的设定
- 三、算法详解
-
- 算法主要三个特点:Distributed、Heuristic、Communication
- 1.agent Q-Network
- 2.heuristic channels
- 3.图卷积通信
- 4.多智能体分布式优先经验回放
- 四、实验结果
-
- 评价指标:
-
- 1.Success rate and Average Step
- 2.With and Without Heuristic or Communication
- 总结
一、introduction
传统的MAPF主要是基于搜索算法,这种集中式规划的算法局限性是无法很好的扩展到大规模的智能体。RL的分散执行已经应用到MAPF问题当中,在分散执行的过程中,每个agent根据自身的策略,在局部观察的条件下做出决策。为了避免agent之间发生碰撞,会训练一种反应策略纠正agent的动作,而且会在密集与紧张的环境当中造成死锁或活锁的问题。目前主流的方法通过结合RL与IL或者单智能体最短路径。然而这些方式都不能满足多智能体路径规划的环境设定,这些策略并不能解决这些情况:智能体同时移动或解决活锁与死锁、当智能体到达目标位置后或者阻碍其他智能体到达目标位置等问题。
本文方法:
为了解决上述的问题,作者提出了基于单智能体启发式指导与通信的DQN算法,能够遵循MAPF问题的设定:智能体同时移动并且在到达目标后依旧在环境中。
具体做法:没有提供特定的路径作为指导,而且嵌入最短路径潜在选择作为启发式的指导作为DQN网络的输入,这能使得模型能够通过自我启发学习到合理的知识。同时将环境形式化为图,使智能体与其邻域的智能体之间通过图卷积进行交流,提升agent之间的协作能力,在其中利用多头注意力机制作为卷积核提取agents之间的关系特征。为了能够更好的扩展到大规模,没有学习联合动作价值空间,采用single-agent DQN解决部分观测的马尔科夫博弈过程。在训练过程基于ApeX框架,在课程学习策略下进行训练,在分散执行过程,每个agent采用相同的策略并且同时移动。
知识补充
Independent Q-Learning (IQL):每个agent同时单独学习自己的动作价值函数,每个agent将其他智能体当作环境的一部分。
二、学习环境
1.环境设定
创建离散的gridword环境,整个环境空间为 m ∗ m m*m m∗m二值矩阵,0代表可用空间,1代表已占用空间。对于n个智能体随机产生n个起始位置与n个目标位置,并且这2n个位置不会发生重复,每个智能体能同时移动并且能够很好的解决冲突问题,在到达目标位置后,该智能体也会维持在环境当中。
2.观察表征
在局部可观察的设定当中,每个智能体只能观察到 l ∗ l l*l l∗l的网格视场,l设置为奇数确保每个智能体在视场的中心,观察特征被分为了两个channel,第一个channel是二值矩阵表达视场内的障碍,第二个channel同样是二值矩阵表达视场内的其他智能体,并且添加了四个启发式的channel作为模型的输入。
3.动作空间
智能体在gridworld中采取离散的动作,每个时间agent能选择去邻域或不动,不考虑对角的移动,因此每个智能体具有五个动作状态,该方法会对所有的动作进行采用,即使会发生碰撞的动作,通过迭代的方式得到最终无碰撞的动作。
4.奖励函数的设定
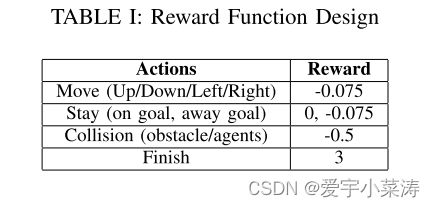
三、算法详解
算法主要三个特点:Distributed、Heuristic、Communication
1.agent Q-Network

DHC主要包括三个部分:observation encoder、communication block、Q-network
整体流程:第i个agent以局部环境信息与上一时刻的交流信息(隐藏状态)作为输入,通过observation encoder得到第t时刻的中间信息 e i t e_i^t eit,将 a g e n t i agent_i agenti与其周围的agent的中间信息作为交流模块的输入,通过communication block得到t时刻的交流信息 e i " t e_i^"t ei"t,最终的 e i " t e_i^"t ei"t作为Q网络的输入计算Q值。
2.heuristic channels

采用四个启发式通道信息,采用单智能体路径规划器作为启发信息,而不采用集中式的多智能体路径规划器,这样能够大幅降低计算消耗,同时不采用特定的路径作为启发的信息,使得智能体自己学到有用的启发式信息。**具体做法:**对于四个动作up、down、left、right作为四个通道,每个通道具有相同的FOV,对于FOV的每个位置,采取对于的动作后,如果能够靠近最终的goal,那么设定该位置为1,阻碍位置与下一步到达阻碍位置的情况则不考虑。
3.图卷积通信
将每个智能体当做一个节点,如果两个智能体都互相在各自的FOV中,则这两个智能体会当做相邻的节点,因此所有的智能体被所示为图,该篇论文采用多头注意力作为卷积核计算智能体之间的交互,将智能体i的中间信息 e i t e_i^t eit估计为Q、K、V矩阵输入到每个独立的注意力头h中,将i与其相邻智能体j的交互信息通过公式(1)计算得到第h头的输出。

d k d_k dk代表K的维度, d k \sqrt{d_k} dk用来稳定训练,每个head的输出都是与其邻域的智能体的信息的加权和(公式2),将每个head的输出进行concatenate,再通过神经网络最终得到图卷积的输出 e i t ^ \hat{e_i^t} eit^,将 e i t ^ \hat{e_i^t} eit^与 e i t e_i^t eit通过GRU聚合后得到通信模块的输出。

4.多智能体分布式优先经验回放
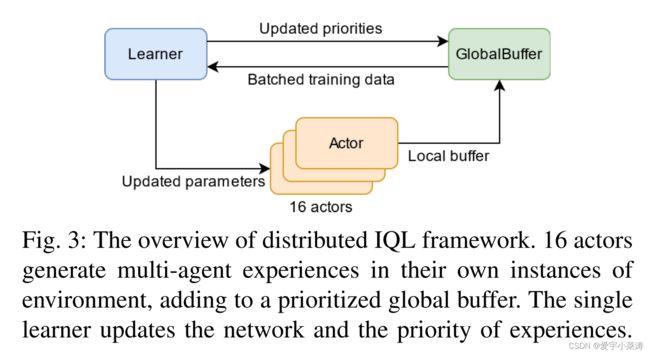
IQL相对比集中式规划器,能够避免伸缩性问题,不需要学习联合动作Q函数,能够适应智能体数目增加带来的维度爆炸的问题。IQL能够在局部观测的条件下自然的学习分布式的策略,为了简化训练过程,采用单个智能体的视角训练训练单个模型得到最终的策略。为了加速训练过程,选择基于共享经验池的并行数据生产与选择,能够使得更多priority data充分利用,本文中采用的是Ape-X框架。
该论文中采用16个独立的actors生产数据,1个learner进行训练,每个actor会复制当前Q-network的环境信息,并且在贡献回收池的先验下生产出新的多智能体交互数据,learner采样最重要的经验更新network的参数,虽然模型是针对单个智能体进行训练,但所有智能体之间的交互都需要被储存用于通信,随着优先的共享,actor会探索更好的经验用于learner提升学习的策略。最终的损失函数如下:

知识补充
memory repaly:存储最近的样本,产生训练样本,提高样本的利用效率,同时神经网络要求数据之间不具备依赖性,但在同一批次产生的数据一般具有关联性,因此采用经验池回收,能够降低关联性
四、实验结果
评价指标:
1.Success rate and Average Step
success rate:在给定的时间步长内完成任务的能力
average step:一个任务的所有的平均时间,越小代表着具有更优的策略
对于给定数量的智能体 { 4 , 8 , 16 , 32 , 64 } \{4,8,16,32,64\} {4,8,16,32,64},进行200次测试,对于40X40map的最大time step为256,对于80X80map的最大time step为386。实验结果如下图所示

实验结果展示:DHC在从小地图转换到大地图需要更少的路径增长数量,表明DHC学习到了更多有用启发式的信息,能够在大地图中更好的确定路径;DHC需要更少的时间步长完成任务,展示出通信能够很好的解决冲突并且加速路径规划
2.With and Without Heuristic or Communication

通过对比DHC与不带有通信模块/启发式信息的DHC,结果展示出当地图较大时,启发式的引导能够帮助模型学到更多有用的信息,具有更好的表现;当智能体数量较少时,缺少通信模块对整体的影响较小,但当数量增加后,通信模块能够更好的解决冲突问题。
总结
本文提出基于通信的分布式启发深度Q网络,引入单智能体最短路径启发式信息作为指导,引入图卷积机制进行智能体之间的通信,以单个智能体的视角进行训练,不需要学习联合动作状态空间,便于拓展,与PRIMAL相比,具有更好的success rate,更少的average step。未来工作:增加通信的范围同时降低开销与延迟。