关于SqlServer高并发死锁现象的分析排查
问题描述
通过定期对生产环境SqlServer日志的梳理,发现经常会出现类似事务与另一个进程被死锁在资源上,并且已被选作死锁牺牲品,请重新运行该事务的异常,简单分析一下原因:在高并发场境下,多个事务同时对某个资源进行持锁 [ 读/写 ] 操作,同时又需要对方释放锁资源,进而出现死锁
下面将通过一个简单的案例来重现这种异常,了解了死锁的原因后,我们在写sql语句、创建索引时,就可以有效避免掉这些坑
创建表
CREATE TABLE [dbo].[t_test](
[id] [int] NOT NULL, --主键
[name] [varchar](50) NULL, --名称
[age] [bigint] NULL, --年龄
[address] [varchar](50) NULL, --地址
CONSTRAINT [PK_t_test] PRIMARY KEY CLUSTERED([id] ASC)
添加索引
# 在name列上创建非聚集索引,包含列为age
CREATE UNIQUE NONCLUSTERED INDEX [index_name] ON [dbo].[t_test]([name] ASC) INCLUDE ([age]);
CREATE UNIQUE CLUSTERED INDEX [index_id] ON [dbo].[t_test]([id] ASC);
注:include 可以指定多个列字段,通常把 select 查询的列放到 include 中,好处是索引查找的开销较小
准备数据
insert into t_test values (1, '张三', 21, '上海市徐汇区');
insert into t_test values (2, '李四', 19, '浙江省杭州市');
insert into t_test values (3, '王五', 28, '湖北省武汉市');
查看执行计划
开始测试之前,我们先通过SqlServer的 执行计划 来了解一下本案例涉及的 select 和 update 操作背后的详细过程
select操作
SELECT address FROM t_test WHERE name = '张三'
执行计划如下:
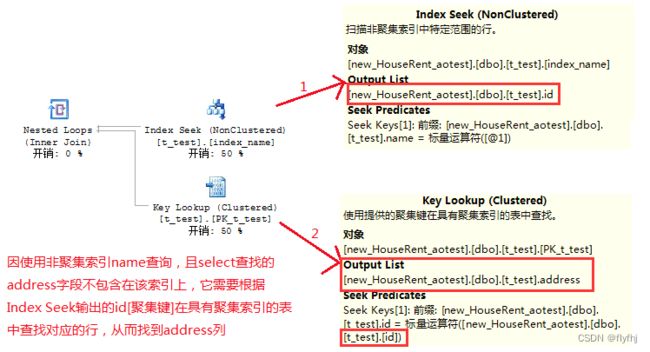
如上图,因使用非聚集索引name做为where条件查询,且select查找的address字段不包含在该索引字段上,所以需要根据Index Seek输出的id[聚集键]在具有聚集索引的表中查找对应的行,从面找到address列,我们常称做 回表查询
update操作
UPDATE t_test SET age=age+1 WHERE id = 1
执行计划如下:
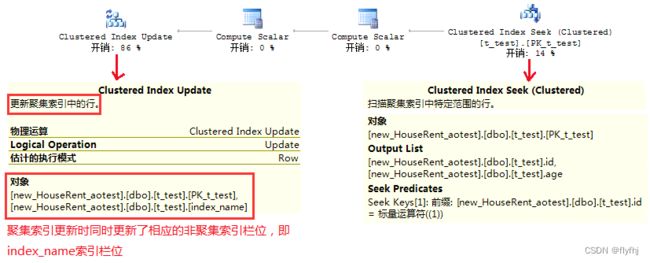
过程分析:首先根据主键id在聚集索引上进行Index Seek(索引查找),输出的字段为[id]和[age],因为我们要更新的数据存储在聚集索引的叶子节点上,所以直接在聚集索引上更新数据(age+1)。其实到这一步还没有结束,因为字段age的值修改了,该字段所在的非聚集索引要进行"旋转"或"页拆分"处理,所以SqlServer还要继续更新非聚集索引栏位(index_name)
示例演示
脚本一:声明一个循环查询语句,其中:where 查询条件使用非聚集索引字段 name ,select 的字段 address 为普通字段(注:目的是让其进行回表)
DECLARE @num int
SET @num = 1
While 1=1
BEGIN
SELECT address FROM t_test WHERE name = '张三'
set @num=@num+1
END
脚本二:声明一个循环更新语句,根据主键修改 age(include字段) 的值
DECLARE @i int
SET @i=1
While 1=1
BEGIN
UPDATE t_test SET age=age + @i WHERE id = 1
SET @i=@i+1
END
运行了大概6秒钟,死锁(不是阻塞)就出现了,结果直接上图吧
![]()
此时表数据如下:
| id | name | age | address |
|---|---|---|---|
| 1 | 张三 | 15826967 | 上海市徐汇区 |
| 2 | 李四 | 19 | 浙江省杭州市 |
| 3 | 王五 | 28 | 湖北省武汉市 |
原因分析
Query查询时使用非聚集索引来select数据,那么它会在非聚集索引 [name(include age)] 上持有一个S锁,因为select的列不在该索引上,所以它需要根据rowid找到对应的聚集索引的那一行磁盘地址,然后找到其他数据。而此时在第二个更新语句中,update正在聚集索引上进行定位、加锁、修改操作,但因为正在修改的 age 列,是另外一个非聚集索引的某个列,所以此时,它需要同时更改那个非聚集索引的信息,这就需要在非聚集索引 [name(include age)] 上加第二个X锁,select开始等待update的X锁,update开始等待select的S锁,死锁就发生了
图例:
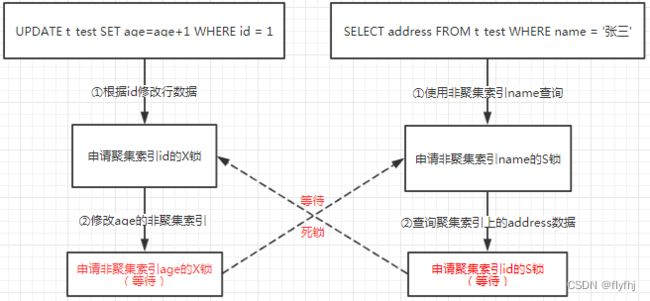
如上图:update开始等待select的S锁,select开始等待update的X锁
解决方案
- 持锁时间越长,死锁的概率越大,尽量缩短事务的执行时间,避免长事务产生
- 按同一顺序访问对象,避免事务交叉进行 [这点很重要]
- select查询时避免使用通配符*,减少多余的index seek查找
- 适当允许脏读的情况下,使用WITH(NOLOCK),可以提高查询性能,避免死锁
- 根据业务场景,可以考虑设置较低的隔离级别降低死锁的发生频率
其它
文章最后补充一下 索引 include 的使用技巧:
索引不包含include列
缺点:会增加一次通过主键索引的回表操作,增加了逻辑读次数,影响性能
索引包含include列
优点:通过非聚集索引就可以直接查询返回include列的数据,不需要通过主键索引回表,减少了逻辑读次数,提升了查询效率(建议当select查询字段较少时,可以用包含include的索引)
缺点:会增加 非集索引的空间占用
(完结)