自然语言处理(第16课 机器翻译4、5/5)
一、学习目标
1.学习各种粒度的系统融合方法
2.学习两类译文评估标准
3.学习语音翻译和文本翻译的不同
4.学习语音翻译实现方法
二、系统融合
以一个最简单的例子来说明系统融合,就是相当于用多个翻译引擎得到不同的翻译结果,然后选择其中最好的作为最终结果:

不同于分类方法中的系统融合,因为分类方法中,各引擎的输出结果是类别,可以使用投票法(少数服从多数)、取均值等方法,机器翻译的结果是译文,是不能使用投票法、取均值法来得到结果的。
于是在机器翻译中,针对不同粒度的系统融合方法,需要对输出们“加和”的操作中进行变动,包括:(1)句子级系统融合;(2)词语级系统融合;(3)词语级系统融合;(4)基于深度学习的系统融合。
1.句子级系统融合

其核心思想是计算一个输出与其它输出的相似度,加和取平均。然后每个输出都有一个对其他输出的相似度加和平均结果,最好的结果就是相似度最大的那个,例子如下:

优点:只需要计算就能得到结果,方便。
缺点:如果每个翻译引擎都翻译得不好,最终结果也不好。
2.短语级系统融合

如果能回想起前面讲过的短语级的机器翻译,就是像它那样使用对齐一致性的词语划分方法来对翻译结果进行划分,然后选取出其中出现次数多的短语组合形成新的结果。例子如下:

优点:能找到比句子级系统融合更优的结果。
缺点:需要足够多的翻译引擎才能有提升。
3.词语级系统融合

我们先看其一个例子:(其中null表示为空)

显然,词语级系统融合的关键在于构建上面的有向图,从而可以找到得分最高的路径作为最优结果,而构建有向图的基础是对齐操作。所以对齐是其重中之重。其整体模型运行过程如下:

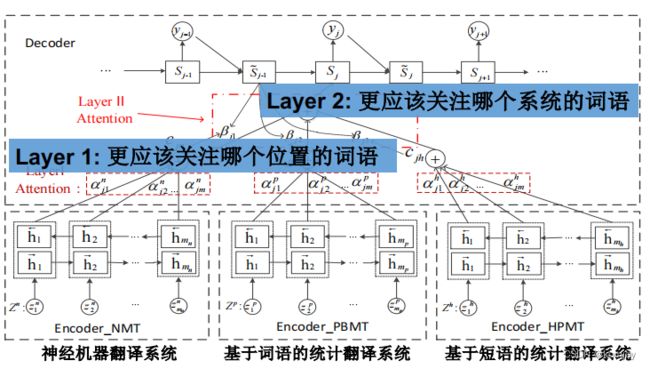
4.基于深度学习的系统融合

其重点在于使用了注意力机制,就相当于分类模型系统融合中的adaboost,给每个系统都分配权值,从而能汇聚所有翻译引擎的信息。整体结构如下:
三、译文评估方法
不像分类任务,直接统计模型输出结果是否分类成功,从而得到正确率或者错误率去评判模型的好坏。机器翻译翻译的结果是文本,标签也是文本,无法直接进行比较,而且文本也有同意性,不同句子可以表达同种意思。于是机器翻译特别地设计了各种译文评估方法。
1.主观评测
主观评测就是让双语翻译专家来打分,考察标准分三类:流畅度、充分性、语义保持性。三个标准的评分表如下:



以一个例子来说明:

显然,主观评测的结果是十分准确且合理的。但确点也很明显,对于上百万条翻译语句,让人工去评判,消耗的时间和资源是不等价的。
2.客观评测
客观评测就是让程序自己根据模型输出结果和参考译文来计算正确率和错误率。几个常见的是:


一个十分常用的评价法是BLEU评价法:

我们用一个例子来理解它:

如果n=1,则系统译文的词集合为{the},由于the在参考译文中出现,故得分为1/1=1;
再取n=2,则系统译文的词集合为{'the the'},而'the the'未在参考译文中出现,故得分0/1=0;
同理n=3、4,(一般n取到4)得分都为0,综合得分为1+0+0+0=1。(当然这里可以归一化一下,甚至给不同的n的得分分配不同权重)。
于是我们可以有最后的计算公式:(w就是上面说的权重,p是各个得分,BP是惩罚项,用于惩罚过短的句子,原因可见红字部分)

3.基于深度学习的客观评测
其主要思想是通过注意力机制来计算得分。以例子来说明:

网格左边是原文,下面是译文(这里是英译英,但理解其思想就行)。网格中就是左边词与下边词的注意力度,相当于联系性,所以取最大的得分,认为其联系性最大(可以互相翻译),网格之外还有一排数据,是说明句子各词的重要性(权重),网格红色得分乘上权重,最后就可以得到总分,继而可求召回率、准确率、F1。
四、语音翻译
1.语音翻译的定义

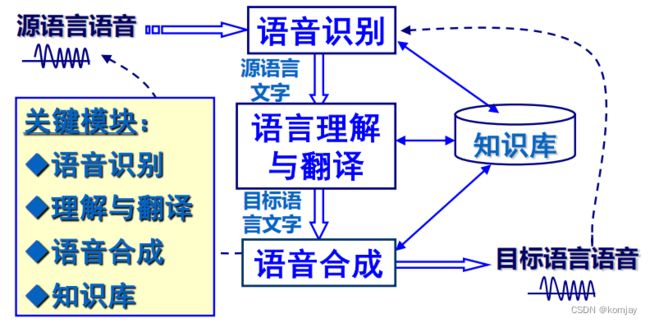
语音翻译的基本原理相比大家都能猜到:将源语言识别出源文本、源文本转目标文本、目标文本转目标语音:(但是,要注意的是,源语言和目标语言的转换应该是双向的)
2.语音翻译与文本翻译的不同
语音翻译是肯定比文本翻译难的,
在语音识别上,有:(1)系统工作环境的多样、(2)复杂的口语习惯、(3)语音库收集难。(显然还有:杂音、集外词、缺少标点符号)
在语言表示上,口语翻译还有的特点:

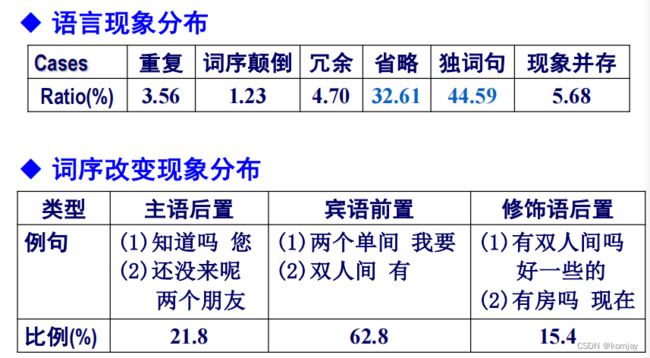 在语言使用上,有省略、冗余等问题。
在语言使用上,有省略、冗余等问题。
在语音合成上,有自然、流畅、清楚、有情感、与说话人语音一致等要求。
此外,手势和表情也会对语言的表达有辅助作用。
五、语音翻译实现
1.重点问题
现有的语音翻译基本都没做这些问题的解决方法。

2.级联方法
级联方法就是前面说的语音识别-机器翻译-语音合成三步结合的方法。过程如下:
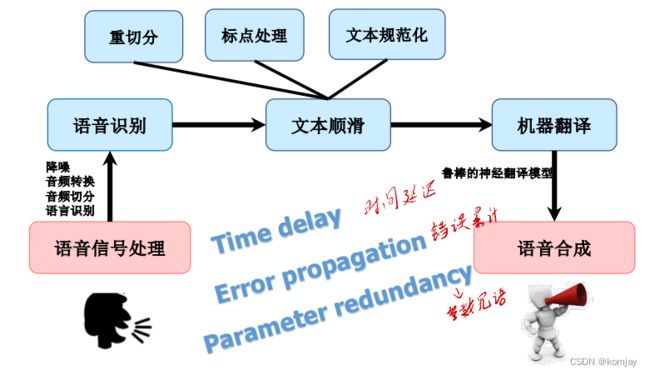
如上面所说,其有三个重要的问题:时间延迟、错误累计、参数冗余。于是提出端到端的方法。
3.端到端方法
端到端的思想是,直接将源语言语音输入到模型中,模型输出目标语言的文本,通过语音合成输出目标语音:


二者比较,各有优缺点:

六、本章小结
1.机器翻译的系统融合方法,并由于问题不同引起的融合方法的不同和评估方法的不同
2.语音翻译与文本翻译的不同,语音翻译的两种实现方法。