深度学习 Day22——J2ResNet50V2算法实战与解析
- 本文为365天深度学习训练营 中的学习记录博客
- 原作者:K同学啊 | 接辅导、项目定制
- 文章来源:K同学的学习圈子
文章目录
- 前言
- 一、我的环境
- 二、代码实现与执行结果
-
- 1.引入库
- 2.设置GPU(如果使用的是CPU可以忽略这步)
- 3.导入数据
- 4.查看数据
- 5.加载数据
- 6.再次检查数据
- 7.配置数据集
- 8.可视化数据
- 9.构建ResNet50V2模型
- 10.编译模型
- 11.训练模型
- 12.模型评估
- 三、知识点详解
-
- 1 Resnet50V2论文解读
-
- 1.1 ResNetV2结构与ResNet结构对比
- 1.2 关于残差结构的不同尝试
- 1.3 关于激活的尝试
- 2 Resnet50V2模型复现
-
- 2.1 Residual Block
- 2.2 堆叠Residual Block
- 2.3 Resnet50V2架构复现
- 2.4 ResNet50V2模型结构大图
- 3 pytorch实现Resnet50V2算法
- 总结
前言
关键字:ResnetV2, pytorch实现Resnet50V2算法
一、我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm2020.2.3
- 深度学习环境:TensorFlow 2.10.1
- 显卡:NVIDIA GeForce RTX 4070
二、代码实现与执行结果
1.引入库
from PIL import Image
import numpy as np
from pathlib import Path
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import tensorflow as tf
from keras import layers, models, Input
from keras.layers import Input, Activation, BatchNormalization, Flatten
from keras.layers import Dense, Conv2D, MaxPooling2D, ZeroPadding2D, GlobalMaxPooling2D,AveragePooling2D, Flatten, Dropout, BatchNormalization,GlobalAveragePooling2D
from keras.models import Model
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
2.设置GPU(如果使用的是CPU可以忽略这步)
'''前期工作-设置GPU(如果使用的是CPU可以忽略这步)'''
# 检查GPU是否可用
print(tf.test.is_built_with_cuda())
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0], "GPU")
执行结果
True
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
3.导入数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\bird\bird_photos"
data_dir = Path(data_dir)
4.查看数据
'''前期工作-查看数据'''
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:", image_count)
image_list = list(data_dir.glob('Bananaquit/*.jpg'))
image = Image.open(str(image_list[1]))
# 查看图像实例的属性
print(image.format, image.size, image.mode)
plt.imshow(image)
plt.axis("off")
plt.show()
执行结果:
图片总数为: 565
JPEG (224, 224) RGB

5.加载数据
'''数据预处理-加载数据'''
batch_size = 8
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
运行结果:
Found 565 files belonging to 4 classes.
Using 452 files for training.
Found 565 files belonging to 4 classes.
Using 113 files for validation.
['Bananaquit', 'Black Skimmer', 'Black Throated Bushtiti', 'Cockatoo']
6.再次检查数据
'''数据预处理-再次检查数据'''
# Image_batch是形状的张量(16, 336, 336, 3)。这是一批形状336x336x3的16张图片(最后一维指的是彩色通道RGB)。
# Label_batch是形状(16,)的张量,这些标签对应16张图片
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
运行结果
(8, 224, 224, 3)
(8,)
7.配置数据集
'''数据预处理-配置数据集'''
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
8.可视化数据
'''数据预处理-可视化数据'''
plt.figure(figsize=(10, 5))
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]], fontsize=10)
plt.axis("off")
# 显示图片
plt.show()

9.构建ResNet50V2模型
"""构建ResNet50V2模型"""
''' 残差块
Arguments:
x: 输入张量
filters: integer, filters, of the bottleneck layer.
kernel_size: default 3, kernel size of the bottleneck layer.
stride: default 1, stride of the first layer.
conv_shortcut: default False, use convolution shortcut if True, otherwise identity shortcut.
name: string, block label.
Returns:
Output tensor for the residual block.
'''
def block2(x, filters, kernel_size=3, stride=1, conv_shortcut=False, name=None):
preact = BatchNormalization(name=name + '_preact_bn')(x)
preact = Activation('relu', name=name + '_preact_relu')(preact)
if conv_shortcut:
shortcut = Conv2D(4 * filters, 1, strides=stride, name=name + '_0_conv')(preact)
else:
shortcut = MaxPooling2D(1, strides=stride)(x) if stride > 1 else x
x = Conv2D(filters, 1, strides=1, use_bias=False, name=name + '_1_conv')(preact)
x = BatchNormalization(name=name + '_1_bn')(x)
x = Activation('relu', name=name + '_1_relu')(x)
x = ZeroPadding2D(padding=((1, 1), (1, 1)), name=name + '_2_pad')(x)
x = Conv2D(filters, kernel_size, strides=stride, use_bias=False, name=name + '_2_conv')(x)
x = BatchNormalization(name=name + '_2_bn')(x)
x = Activation('relu', name=name + '_2_relu')(x)
x = Conv2D(4 * filters, 1, name=name + '_3_conv')(x)
x = layers.Add(name=name + '_out')([shortcut, x])
return x
def stack2(x, filters, blocks, stride1=2, name=None):
x = block2(x, filters, conv_shortcut=True, name=name+'_block1')
for i in range(2, blocks):
x = block2(x, filters, name=name+'_block'+str(i))
x = block2(x, filters, stride=stride1, name=name+'_block'+str(blocks))
return x
''' 构建ResNet50V2 '''
def ResNet50V2(include_top=True, # 是否包含位于网络顶部的全链接层
preact=True, # 是否使用预激活
use_bias=True, # 是否对卷积层使用偏置
weights='imagenet',
input_tensor=None, # 可选的keras张量,用作模型的图像输入
input_shape=None,
pooling=None,
classes=1000, # 用于分类图像的可选类数
classifer_activation='softmax'): # 分类层激活函数
img_input = Input(shape=input_shape)
x = ZeroPadding2D(padding=((3, 3), (3, 3)), name='conv1_pad')(img_input)
x = Conv2D(64, 7, strides=2, use_bias=use_bias, name='conv1_conv')(x)
if not preact:
x = BatchNormalization(name='conv1_bn')(x)
x = Activation('relu', name='conv1_relu')(x)
x = ZeroPadding2D(padding=((1, 1), (1, 1)), name='pool1_pad')(x)
x = MaxPooling2D(3, strides=2, name='pool1_pool')(x)
x = stack2(x, 64, 3, name='conv2')
x = stack2(x, 128, 4, name='conv3')
x = stack2(x, 256, 6, name='conv4')
x = stack2(x, 512, 3, stride1=1, name='conv5')
if preact:
x = BatchNormalization(name='post_bn')(x)
x = Activation('relu', name='post_relu')(x)
if include_top:
x = GlobalAveragePooling2D(name='avg_pool')(x)
x = Dense(classes, activation=classifer_activation, name='predictions')(x)
else:
if pooling == 'avg':
# GlobalAveragePooling2D就是将每张图片的每个通道值各自加起来再求平均,
# 最后结果是没有了宽高维度,只剩下个数与平均值两个维度
# 可以理解成变成了多张单像素图片
x = GlobalAveragePooling2D(name='avg_pool')(x)
elif pooling == 'max':
x = GlobalMaxPooling2D(name='max_pool')(x)
model = Model(img_input, x, name='resnet50v2')
return model
model = ResNet50V2(input_shape=(224,224,3))
model.summary()
网络结构结果如下:
Model: "resnet50v2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 224, 224, 3 0 []
)]
conv1_pad (ZeroPadding2D) (None, 230, 230, 3) 0 ['input_1[0][0]']
conv1_conv (Conv2D) (None, 112, 112, 64 9472 ['conv1_pad[0][0]']
)
pool1_pad (ZeroPadding2D) (None, 114, 114, 64 0 ['conv1_conv[0][0]']
)
pool1_pool (MaxPooling2D) (None, 56, 56, 64) 0 ['pool1_pad[0][0]']
conv2_block1_preact_bn (BatchN (None, 56, 56, 64) 256 ['pool1_pool[0][0]']
ormalization)
conv2_block1_preact_relu (Acti (None, 56, 56, 64) 0 ['conv2_block1_preact_bn[0][0]']
vation)
conv2_block1_1_conv (Conv2D) (None, 56, 56, 64) 4096 ['conv2_block1_preact_relu[0][0]'
]
conv2_block1_1_bn (BatchNormal (None, 56, 56, 64) 256 ['conv2_block1_1_conv[0][0]']
ization)
conv2_block1_1_relu (Activatio (None, 56, 56, 64) 0 ['conv2_block1_1_bn[0][0]']
n)
conv2_block1_2_pad (ZeroPaddin (None, 58, 58, 64) 0 ['conv2_block1_1_relu[0][0]']
g2D)
conv2_block1_2_conv (Conv2D) (None, 56, 56, 64) 36864 ['conv2_block1_2_pad[0][0]']
conv2_block1_2_bn (BatchNormal (None, 56, 56, 64) 256 ['conv2_block1_2_conv[0][0]']
ization)
conv2_block1_2_relu (Activatio (None, 56, 56, 64) 0 ['conv2_block1_2_bn[0][0]']
n)
conv2_block1_0_conv (Conv2D) (None, 56, 56, 256) 16640 ['conv2_block1_preact_relu[0][0]'
]
conv2_block1_3_conv (Conv2D) (None, 56, 56, 256) 16640 ['conv2_block1_2_relu[0][0]']
conv2_block1_out (Add) (None, 56, 56, 256) 0 ['conv2_block1_0_conv[0][0]',
'conv2_block1_3_conv[0][0]']
conv2_block2_preact_bn (BatchN (None, 56, 56, 256) 1024 ['conv2_block1_out[0][0]']
ormalization)
conv2_block2_preact_relu (Acti (None, 56, 56, 256) 0 ['conv2_block2_preact_bn[0][0]']
vation)
conv2_block2_1_conv (Conv2D) (None, 56, 56, 64) 16384 ['conv2_block2_preact_relu[0][0]'
]
conv2_block2_1_bn (BatchNormal (None, 56, 56, 64) 256 ['conv2_block2_1_conv[0][0]']
ization)
conv2_block2_1_relu (Activatio (None, 56, 56, 64) 0 ['conv2_block2_1_bn[0][0]']
n)
conv2_block2_2_pad (ZeroPaddin (None, 58, 58, 64) 0 ['conv2_block2_1_relu[0][0]']
g2D)
conv2_block2_2_conv (Conv2D) (None, 56, 56, 64) 36864 ['conv2_block2_2_pad[0][0]']
conv2_block2_2_bn (BatchNormal (None, 56, 56, 64) 256 ['conv2_block2_2_conv[0][0]']
ization)
conv2_block2_2_relu (Activatio (None, 56, 56, 64) 0 ['conv2_block2_2_bn[0][0]']
n)
conv2_block2_3_conv (Conv2D) (None, 56, 56, 256) 16640 ['conv2_block2_2_relu[0][0]']
conv2_block2_out (Add) (None, 56, 56, 256) 0 ['conv2_block1_out[0][0]',
'conv2_block2_3_conv[0][0]']
conv2_block3_preact_bn (BatchN (None, 56, 56, 256) 1024 ['conv2_block2_out[0][0]']
ormalization)
conv2_block3_preact_relu (Acti (None, 56, 56, 256) 0 ['conv2_block3_preact_bn[0][0]']
vation)
conv2_block3_1_conv (Conv2D) (None, 56, 56, 64) 16384 ['conv2_block3_preact_relu[0][0]'
]
conv2_block3_1_bn (BatchNormal (None, 56, 56, 64) 256 ['conv2_block3_1_conv[0][0]']
ization)
conv2_block3_1_relu (Activatio (None, 56, 56, 64) 0 ['conv2_block3_1_bn[0][0]']
n)
conv2_block3_2_pad (ZeroPaddin (None, 58, 58, 64) 0 ['conv2_block3_1_relu[0][0]']
g2D)
conv2_block3_2_conv (Conv2D) (None, 28, 28, 64) 36864 ['conv2_block3_2_pad[0][0]']
conv2_block3_2_bn (BatchNormal (None, 28, 28, 64) 256 ['conv2_block3_2_conv[0][0]']
ization)
conv2_block3_2_relu (Activatio (None, 28, 28, 64) 0 ['conv2_block3_2_bn[0][0]']
n)
max_pooling2d (MaxPooling2D) (None, 28, 28, 256) 0 ['conv2_block2_out[0][0]']
conv2_block3_3_conv (Conv2D) (None, 28, 28, 256) 16640 ['conv2_block3_2_relu[0][0]']
conv2_block3_out (Add) (None, 28, 28, 256) 0 ['max_pooling2d[0][0]',
'conv2_block3_3_conv[0][0]']
conv3_block1_preact_bn (BatchN (None, 28, 28, 256) 1024 ['conv2_block3_out[0][0]']
ormalization)
conv3_block1_preact_relu (Acti (None, 28, 28, 256) 0 ['conv3_block1_preact_bn[0][0]']
vation)
conv3_block1_1_conv (Conv2D) (None, 28, 28, 128) 32768 ['conv3_block1_preact_relu[0][0]'
]
conv3_block1_1_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block1_1_conv[0][0]']
ization)
conv3_block1_1_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block1_1_bn[0][0]']
n)
conv3_block1_2_pad (ZeroPaddin (None, 30, 30, 128) 0 ['conv3_block1_1_relu[0][0]']
g2D)
conv3_block1_2_conv (Conv2D) (None, 28, 28, 128) 147456 ['conv3_block1_2_pad[0][0]']
conv3_block1_2_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block1_2_conv[0][0]']
ization)
conv3_block1_2_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block1_2_bn[0][0]']
n)
conv3_block1_0_conv (Conv2D) (None, 28, 28, 512) 131584 ['conv3_block1_preact_relu[0][0]'
]
conv3_block1_3_conv (Conv2D) (None, 28, 28, 512) 66048 ['conv3_block1_2_relu[0][0]']
conv3_block1_out (Add) (None, 28, 28, 512) 0 ['conv3_block1_0_conv[0][0]',
'conv3_block1_3_conv[0][0]']
conv3_block2_preact_bn (BatchN (None, 28, 28, 512) 2048 ['conv3_block1_out[0][0]']
ormalization)
conv3_block2_preact_relu (Acti (None, 28, 28, 512) 0 ['conv3_block2_preact_bn[0][0]']
vation)
conv3_block2_1_conv (Conv2D) (None, 28, 28, 128) 65536 ['conv3_block2_preact_relu[0][0]'
]
conv3_block2_1_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block2_1_conv[0][0]']
ization)
conv3_block2_1_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block2_1_bn[0][0]']
n)
conv3_block2_2_pad (ZeroPaddin (None, 30, 30, 128) 0 ['conv3_block2_1_relu[0][0]']
g2D)
conv3_block2_2_conv (Conv2D) (None, 28, 28, 128) 147456 ['conv3_block2_2_pad[0][0]']
conv3_block2_2_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block2_2_conv[0][0]']
ization)
conv3_block2_2_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block2_2_bn[0][0]']
n)
conv3_block2_3_conv (Conv2D) (None, 28, 28, 512) 66048 ['conv3_block2_2_relu[0][0]']
conv3_block2_out (Add) (None, 28, 28, 512) 0 ['conv3_block1_out[0][0]',
'conv3_block2_3_conv[0][0]']
conv3_block3_preact_bn (BatchN (None, 28, 28, 512) 2048 ['conv3_block2_out[0][0]']
ormalization)
conv3_block3_preact_relu (Acti (None, 28, 28, 512) 0 ['conv3_block3_preact_bn[0][0]']
vation)
conv3_block3_1_conv (Conv2D) (None, 28, 28, 128) 65536 ['conv3_block3_preact_relu[0][0]'
]
conv3_block3_1_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block3_1_conv[0][0]']
ization)
conv3_block3_1_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block3_1_bn[0][0]']
n)
conv3_block3_2_pad (ZeroPaddin (None, 30, 30, 128) 0 ['conv3_block3_1_relu[0][0]']
g2D)
conv3_block3_2_conv (Conv2D) (None, 28, 28, 128) 147456 ['conv3_block3_2_pad[0][0]']
conv3_block3_2_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block3_2_conv[0][0]']
ization)
conv3_block3_2_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block3_2_bn[0][0]']
n)
conv3_block3_3_conv (Conv2D) (None, 28, 28, 512) 66048 ['conv3_block3_2_relu[0][0]']
conv3_block3_out (Add) (None, 28, 28, 512) 0 ['conv3_block2_out[0][0]',
'conv3_block3_3_conv[0][0]']
conv3_block4_preact_bn (BatchN (None, 28, 28, 512) 2048 ['conv3_block3_out[0][0]']
ormalization)
conv3_block4_preact_relu (Acti (None, 28, 28, 512) 0 ['conv3_block4_preact_bn[0][0]']
vation)
conv3_block4_1_conv (Conv2D) (None, 28, 28, 128) 65536 ['conv3_block4_preact_relu[0][0]'
]
conv3_block4_1_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block4_1_conv[0][0]']
ization)
conv3_block4_1_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block4_1_bn[0][0]']
n)
conv3_block4_2_pad (ZeroPaddin (None, 30, 30, 128) 0 ['conv3_block4_1_relu[0][0]']
g2D)
conv3_block4_2_conv (Conv2D) (None, 14, 14, 128) 147456 ['conv3_block4_2_pad[0][0]']
conv3_block4_2_bn (BatchNormal (None, 14, 14, 128) 512 ['conv3_block4_2_conv[0][0]']
ization)
conv3_block4_2_relu (Activatio (None, 14, 14, 128) 0 ['conv3_block4_2_bn[0][0]']
n)
max_pooling2d_1 (MaxPooling2D) (None, 14, 14, 512) 0 ['conv3_block3_out[0][0]']
conv3_block4_3_conv (Conv2D) (None, 14, 14, 512) 66048 ['conv3_block4_2_relu[0][0]']
conv3_block4_out (Add) (None, 14, 14, 512) 0 ['max_pooling2d_1[0][0]',
'conv3_block4_3_conv[0][0]']
conv4_block1_preact_bn (BatchN (None, 14, 14, 512) 2048 ['conv3_block4_out[0][0]']
ormalization)
conv4_block1_preact_relu (Acti (None, 14, 14, 512) 0 ['conv4_block1_preact_bn[0][0]']
vation)
conv4_block1_1_conv (Conv2D) (None, 14, 14, 256) 131072 ['conv4_block1_preact_relu[0][0]'
]
conv4_block1_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block1_1_conv[0][0]']
ization)
conv4_block1_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block1_1_bn[0][0]']
n)
conv4_block1_2_pad (ZeroPaddin (None, 16, 16, 256) 0 ['conv4_block1_1_relu[0][0]']
g2D)
conv4_block1_2_conv (Conv2D) (None, 14, 14, 256) 589824 ['conv4_block1_2_pad[0][0]']
conv4_block1_2_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block1_2_conv[0][0]']
ization)
conv4_block1_2_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block1_2_bn[0][0]']
n)
conv4_block1_0_conv (Conv2D) (None, 14, 14, 1024 525312 ['conv4_block1_preact_relu[0][0]'
) ]
conv4_block1_3_conv (Conv2D) (None, 14, 14, 1024 263168 ['conv4_block1_2_relu[0][0]']
)
conv4_block1_out (Add) (None, 14, 14, 1024 0 ['conv4_block1_0_conv[0][0]',
) 'conv4_block1_3_conv[0][0]']
conv4_block2_preact_bn (BatchN (None, 14, 14, 1024 4096 ['conv4_block1_out[0][0]']
ormalization) )
conv4_block2_preact_relu (Acti (None, 14, 14, 1024 0 ['conv4_block2_preact_bn[0][0]']
vation) )
conv4_block2_1_conv (Conv2D) (None, 14, 14, 256) 262144 ['conv4_block2_preact_relu[0][0]'
]
conv4_block2_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block2_1_conv[0][0]']
ization)
conv4_block2_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block2_1_bn[0][0]']
n)
conv4_block2_2_pad (ZeroPaddin (None, 16, 16, 256) 0 ['conv4_block2_1_relu[0][0]']
g2D)
conv4_block2_2_conv (Conv2D) (None, 14, 14, 256) 589824 ['conv4_block2_2_pad[0][0]']
conv4_block2_2_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block2_2_conv[0][0]']
ization)
conv4_block2_2_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block2_2_bn[0][0]']
n)
conv4_block2_3_conv (Conv2D) (None, 14, 14, 1024 263168 ['conv4_block2_2_relu[0][0]']
)
conv4_block2_out (Add) (None, 14, 14, 1024 0 ['conv4_block1_out[0][0]',
) 'conv4_block2_3_conv[0][0]']
conv4_block3_preact_bn (BatchN (None, 14, 14, 1024 4096 ['conv4_block2_out[0][0]']
ormalization) )
conv4_block3_preact_relu (Acti (None, 14, 14, 1024 0 ['conv4_block3_preact_bn[0][0]']
vation) )
conv4_block3_1_conv (Conv2D) (None, 14, 14, 256) 262144 ['conv4_block3_preact_relu[0][0]'
]
conv4_block3_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block3_1_conv[0][0]']
ization)
conv4_block3_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block3_1_bn[0][0]']
n)
conv4_block3_2_pad (ZeroPaddin (None, 16, 16, 256) 0 ['conv4_block3_1_relu[0][0]']
g2D)
conv4_block3_2_conv (Conv2D) (None, 14, 14, 256) 589824 ['conv4_block3_2_pad[0][0]']
conv4_block3_2_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block3_2_conv[0][0]']
ization)
conv4_block3_2_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block3_2_bn[0][0]']
n)
conv4_block3_3_conv (Conv2D) (None, 14, 14, 1024 263168 ['conv4_block3_2_relu[0][0]']
)
conv4_block3_out (Add) (None, 14, 14, 1024 0 ['conv4_block2_out[0][0]',
) 'conv4_block3_3_conv[0][0]']
conv4_block4_preact_bn (BatchN (None, 14, 14, 1024 4096 ['conv4_block3_out[0][0]']
ormalization) )
conv4_block4_preact_relu (Acti (None, 14, 14, 1024 0 ['conv4_block4_preact_bn[0][0]']
vation) )
conv4_block4_1_conv (Conv2D) (None, 14, 14, 256) 262144 ['conv4_block4_preact_relu[0][0]'
]
conv4_block4_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block4_1_conv[0][0]']
ization)
conv4_block4_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block4_1_bn[0][0]']
n)
conv4_block4_2_pad (ZeroPaddin (None, 16, 16, 256) 0 ['conv4_block4_1_relu[0][0]']
g2D)
conv4_block4_2_conv (Conv2D) (None, 14, 14, 256) 589824 ['conv4_block4_2_pad[0][0]']
conv4_block4_2_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block4_2_conv[0][0]']
ization)
conv4_block4_2_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block4_2_bn[0][0]']
n)
conv4_block4_3_conv (Conv2D) (None, 14, 14, 1024 263168 ['conv4_block4_2_relu[0][0]']
)
conv4_block4_out (Add) (None, 14, 14, 1024 0 ['conv4_block3_out[0][0]',
) 'conv4_block4_3_conv[0][0]']
conv4_block5_preact_bn (BatchN (None, 14, 14, 1024 4096 ['conv4_block4_out[0][0]']
ormalization) )
conv4_block5_preact_relu (Acti (None, 14, 14, 1024 0 ['conv4_block5_preact_bn[0][0]']
vation) )
conv4_block5_1_conv (Conv2D) (None, 14, 14, 256) 262144 ['conv4_block5_preact_relu[0][0]'
]
conv4_block5_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block5_1_conv[0][0]']
ization)
conv4_block5_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block5_1_bn[0][0]']
n)
conv4_block5_2_pad (ZeroPaddin (None, 16, 16, 256) 0 ['conv4_block5_1_relu[0][0]']
g2D)
conv4_block5_2_conv (Conv2D) (None, 14, 14, 256) 589824 ['conv4_block5_2_pad[0][0]']
conv4_block5_2_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block5_2_conv[0][0]']
ization)
conv4_block5_2_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block5_2_bn[0][0]']
n)
conv4_block5_3_conv (Conv2D) (None, 14, 14, 1024 263168 ['conv4_block5_2_relu[0][0]']
)
conv4_block5_out (Add) (None, 14, 14, 1024 0 ['conv4_block4_out[0][0]',
) 'conv4_block5_3_conv[0][0]']
conv4_block6_preact_bn (BatchN (None, 14, 14, 1024 4096 ['conv4_block5_out[0][0]']
ormalization) )
conv4_block6_preact_relu (Acti (None, 14, 14, 1024 0 ['conv4_block6_preact_bn[0][0]']
vation) )
conv4_block6_1_conv (Conv2D) (None, 14, 14, 256) 262144 ['conv4_block6_preact_relu[0][0]'
]
conv4_block6_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block6_1_conv[0][0]']
ization)
conv4_block6_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block6_1_bn[0][0]']
n)
conv4_block6_2_pad (ZeroPaddin (None, 16, 16, 256) 0 ['conv4_block6_1_relu[0][0]']
g2D)
conv4_block6_2_conv (Conv2D) (None, 7, 7, 256) 589824 ['conv4_block6_2_pad[0][0]']
conv4_block6_2_bn (BatchNormal (None, 7, 7, 256) 1024 ['conv4_block6_2_conv[0][0]']
ization)
conv4_block6_2_relu (Activatio (None, 7, 7, 256) 0 ['conv4_block6_2_bn[0][0]']
n)
max_pooling2d_2 (MaxPooling2D) (None, 7, 7, 1024) 0 ['conv4_block5_out[0][0]']
conv4_block6_3_conv (Conv2D) (None, 7, 7, 1024) 263168 ['conv4_block6_2_relu[0][0]']
conv4_block6_out (Add) (None, 7, 7, 1024) 0 ['max_pooling2d_2[0][0]',
'conv4_block6_3_conv[0][0]']
conv5_block1_preact_bn (BatchN (None, 7, 7, 1024) 4096 ['conv4_block6_out[0][0]']
ormalization)
conv5_block1_preact_relu (Acti (None, 7, 7, 1024) 0 ['conv5_block1_preact_bn[0][0]']
vation)
conv5_block1_1_conv (Conv2D) (None, 7, 7, 512) 524288 ['conv5_block1_preact_relu[0][0]'
]
conv5_block1_1_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block1_1_conv[0][0]']
ization)
conv5_block1_1_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block1_1_bn[0][0]']
n)
conv5_block1_2_pad (ZeroPaddin (None, 9, 9, 512) 0 ['conv5_block1_1_relu[0][0]']
g2D)
conv5_block1_2_conv (Conv2D) (None, 7, 7, 512) 2359296 ['conv5_block1_2_pad[0][0]']
conv5_block1_2_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block1_2_conv[0][0]']
ization)
conv5_block1_2_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block1_2_bn[0][0]']
n)
conv5_block1_0_conv (Conv2D) (None, 7, 7, 2048) 2099200 ['conv5_block1_preact_relu[0][0]'
]
conv5_block1_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 ['conv5_block1_2_relu[0][0]']
conv5_block1_out (Add) (None, 7, 7, 2048) 0 ['conv5_block1_0_conv[0][0]',
'conv5_block1_3_conv[0][0]']
conv5_block2_preact_bn (BatchN (None, 7, 7, 2048) 8192 ['conv5_block1_out[0][0]']
ormalization)
conv5_block2_preact_relu (Acti (None, 7, 7, 2048) 0 ['conv5_block2_preact_bn[0][0]']
vation)
conv5_block2_1_conv (Conv2D) (None, 7, 7, 512) 1048576 ['conv5_block2_preact_relu[0][0]'
]
conv5_block2_1_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block2_1_conv[0][0]']
ization)
conv5_block2_1_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block2_1_bn[0][0]']
n)
conv5_block2_2_pad (ZeroPaddin (None, 9, 9, 512) 0 ['conv5_block2_1_relu[0][0]']
g2D)
conv5_block2_2_conv (Conv2D) (None, 7, 7, 512) 2359296 ['conv5_block2_2_pad[0][0]']
conv5_block2_2_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block2_2_conv[0][0]']
ization)
conv5_block2_2_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block2_2_bn[0][0]']
n)
conv5_block2_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 ['conv5_block2_2_relu[0][0]']
conv5_block2_out (Add) (None, 7, 7, 2048) 0 ['conv5_block1_out[0][0]',
'conv5_block2_3_conv[0][0]']
conv5_block3_preact_bn (BatchN (None, 7, 7, 2048) 8192 ['conv5_block2_out[0][0]']
ormalization)
conv5_block3_preact_relu (Acti (None, 7, 7, 2048) 0 ['conv5_block3_preact_bn[0][0]']
vation)
conv5_block3_1_conv (Conv2D) (None, 7, 7, 512) 1048576 ['conv5_block3_preact_relu[0][0]'
]
conv5_block3_1_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block3_1_conv[0][0]']
ization)
conv5_block3_1_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block3_1_bn[0][0]']
n)
conv5_block3_2_pad (ZeroPaddin (None, 9, 9, 512) 0 ['conv5_block3_1_relu[0][0]']
g2D)
conv5_block3_2_conv (Conv2D) (None, 7, 7, 512) 2359296 ['conv5_block3_2_pad[0][0]']
conv5_block3_2_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block3_2_conv[0][0]']
ization)
conv5_block3_2_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block3_2_bn[0][0]']
n)
conv5_block3_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 ['conv5_block3_2_relu[0][0]']
conv5_block3_out (Add) (None, 7, 7, 2048) 0 ['conv5_block2_out[0][0]',
'conv5_block3_3_conv[0][0]']
post_bn (BatchNormalization) (None, 7, 7, 2048) 8192 ['conv5_block3_out[0][0]']
post_relu (Activation) (None, 7, 7, 2048) 0 ['post_bn[0][0]']
avg_pool (GlobalAveragePooling (None, 2048) 0 ['post_relu[0][0]']
2D)
predictions (Dense) (None, 1000) 2049000 ['avg_pool[0][0]']
==================================================================================================
Total params: 25,613,800
Trainable params: 25,568,360
Non-trainable params: 45,440
__________________________________________________________________________________________________
10.编译模型
#设置初始学习率
initial_learning_rate = 1e-3
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)
model.compile(optimizer=opt,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
11.训练模型
'''训练模型'''
epochs = 10
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer])
训练记录如下:
Epoch 1/10
2023-12-26 13:10:35.114317: I tensorflow/stream_executor/cuda/cuda_dnn.cc:384] Loaded cuDNN version 8906
2023-12-26 13:10:35.668191: W tensorflow/stream_executor/gpu/redzone_allocator.cc:314] UNKNOWN: Failed to create a NewWriteableFile: C:\Users\����\AppData\Local\Temp\/tempfile-�ö�-33d4-24348-60d62b3da9982 : �ܾ����ʡ�
; Input/output error
Relying on driver to perform ptx compilation.
Modify $PATH to customize ptxas location.
This message will be only logged once.
2023-12-26 13:10:35.727477: I tensorflow/stream_executor/cuda/cuda_blas.cc:1614] TensorFloat-32 will be used for the matrix multiplication. This will only be logged once.
57/57 [==============================] - ETA: 0s - loss: 2.9861 - accuracy: 0.4912
Epoch 1: val_accuracy improved from -inf to 0.30088, saving model to best_model.h5
57/57 [==============================] - 7s 48ms/step - loss: 2.9861 - accuracy: 0.4912 - val_loss: 4.7762 - val_accuracy: 0.3009
Epoch 2/10
57/57 [==============================] - ETA: 0s - loss: 0.6756 - accuracy: 0.7633
Epoch 2: val_accuracy improved from 0.30088 to 0.31858, saving model to best_model.h5
57/57 [==============================] - 2s 38ms/step - loss: 0.6756 - accuracy: 0.7633 - val_loss: 2.3072 - val_accuracy: 0.3186
Epoch 3/10
57/57 [==============================] - ETA: 0s - loss: 0.3617 - accuracy: 0.8872
Epoch 3: val_accuracy did not improve from 0.31858
57/57 [==============================] - 2s 34ms/step - loss: 0.3617 - accuracy: 0.8872 - val_loss: 2.5603 - val_accuracy: 0.2920
Epoch 4/10
57/57 [==============================] - ETA: 0s - loss: 0.4548 - accuracy: 0.8540
Epoch 4: val_accuracy improved from 0.31858 to 0.49558, saving model to best_model.h5
57/57 [==============================] - 2s 37ms/step - loss: 0.4548 - accuracy: 0.8540 - val_loss: 2.0599 - val_accuracy: 0.4956
Epoch 5/10
57/57 [==============================] - ETA: 0s - loss: 0.3243 - accuracy: 0.8872
Epoch 5: val_accuracy improved from 0.49558 to 0.54867, saving model to best_model.h5
57/57 [==============================] - 2s 38ms/step - loss: 0.3243 - accuracy: 0.8872 - val_loss: 1.5009 - val_accuracy: 0.5487
Epoch 6/10
57/57 [==============================] - ETA: 0s - loss: 0.1607 - accuracy: 0.9358
Epoch 6: val_accuracy improved from 0.54867 to 0.78761, saving model to best_model.h5
57/57 [==============================] - 2s 38ms/step - loss: 0.1607 - accuracy: 0.9358 - val_loss: 0.9207 - val_accuracy: 0.7876
Epoch 7/10
57/57 [==============================] - ETA: 0s - loss: 0.0655 - accuracy: 0.9867
Epoch 7: val_accuracy did not improve from 0.78761
57/57 [==============================] - 2s 34ms/step - loss: 0.0655 - accuracy: 0.9867 - val_loss: 1.0354 - val_accuracy: 0.7345
Epoch 8/10
57/57 [==============================] - ETA: 0s - loss: 0.0915 - accuracy: 0.9735
Epoch 8: val_accuracy did not improve from 0.78761
57/57 [==============================] - 2s 33ms/step - loss: 0.0915 - accuracy: 0.9735 - val_loss: 4.3177 - val_accuracy: 0.5044
Epoch 9/10
57/57 [==============================] - ETA: 0s - loss: 0.0869 - accuracy: 0.9735
Epoch 9: val_accuracy did not improve from 0.78761
57/57 [==============================] - 2s 34ms/step - loss: 0.0869 - accuracy: 0.9735 - val_loss: 1.9714 - val_accuracy: 0.5929
Epoch 10/10
57/57 [==============================] - ETA: 0s - loss: 0.0550 - accuracy: 0.9912
Epoch 10: val_accuracy improved from 0.78761 to 0.80531, saving model to best_model.h5
57/57 [==============================] - 2s 37ms/step - loss: 0.0550 - accuracy: 0.9912 - val_loss: 0.7513 - val_accuracy: 0.8053
......
12.模型评估
'''模型评估'''
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
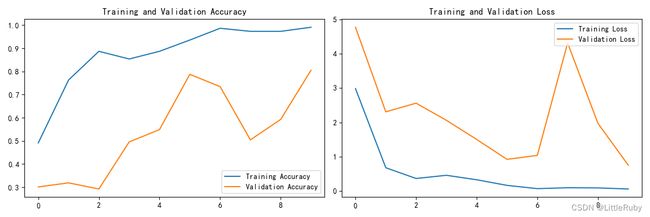
13.图像预测
'''指定图片进行预测'''
# 采用加载的模型(new_model)来看预测结果
plt.figure(figsize=(10, 5)) # 图形的宽为10高为5
plt.suptitle("预测结果展示", fontsize=10)
for images, labels in val_ds.take(1):
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
# 显示图片
plt.imshow(images[i].numpy().astype("uint8"))
# 需要给图片增加一个维度
img_array = tf.expand_dims(images[i], 0)
# 使用模型预测图片中的人物
predictions = model.predict(img_array)
plt.title(class_names[np.argmax(predictions)],fontsize=10)
plt.axis("off")
plt.show()

f99f47ac8f6535bc8913c1fc.png)
三、知识点详解
1 Resnet50V2论文解读
论文:Identity Mappings in Deep Residual Networks
论文的主要贡献:
分析了残差块的传播公式
提出了一种新的残差单元
从理论上证明为什么残差网络有效(为什么可以让梯度在网络中顺畅传递而不会爆炸和消失)
1.1 ResNetV2结构与ResNet结构对比

改进点:
(a)original表示原始的ResNet的残差结构,(b)proposed表示新的ResNet的残差结构。
主要差别就是
(a)结构先卷积后进行BN和激活函数计算,最后执行addition后再进行ReLU计算;(b)结构先进性BN和激活函数计算后卷积,把addition后的ReLU计算放到了残差结构内部。
改进结果:作者使用这两种不同的结构再CIFAR-10数据集上做测试,模型用的是1001层的ResNet模型。从图中的结果我们可以看出,(b)proposed的测试集错误率明显更低一些,达到了4.92%的错误率。(a)original的测试集错误率是7.61%
1.2 关于残差结构的不同尝试
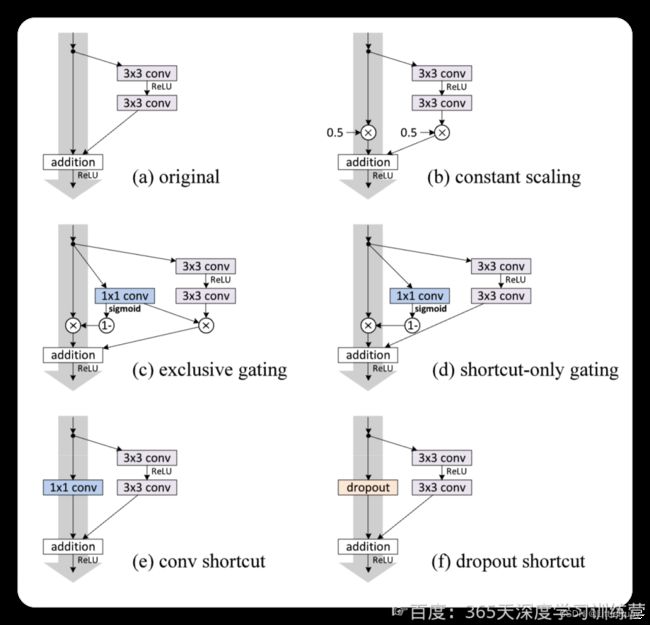
(b-f)中的快捷连接被不同的组件阻碍。为了简化插图,我们不显示BN层,这里所有的单位均采用权值层之后的BN层。图中(a-f)都是作者对残差结构的shortcut部分进行的不同尝试,作者对不同shortcut结构的尝试结果如下表所示。
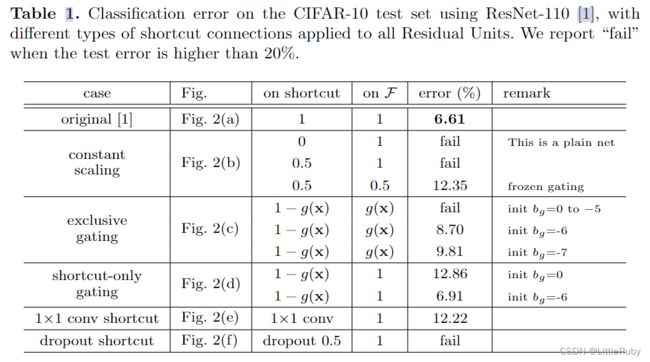
作者用不同的shortcut结构的ResNet-110在CIFAR-10数据集上做测试,发现最原始的(a)original结构是最好的,也就是identity mapping恒等映射是最好的。
1.3 关于激活的尝试

 最好的结果是(e)full pre-activation,其次是(a)original。
最好的结果是(e)full pre-activation,其次是(a)original。
2 Resnet50V2模型复现
官方调用
tf.keras.applications.resnet_v2.ResNet50V2(
include_top=True,
weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None,
classes=1000,
classifier_activation='softmax' )
注意:ResNet50V2、ResNet101V2与ResNet152V2的搭建方式完全一样,区别在于堆叠Residual Block的数量不同。
2.1 Residual Block
''' 残差块
Arguments:
x: 输入张量
filters: integer, filters, of the bottleneck layer.
kernel_size: default 3, kernel size of the bottleneck layer.
stride: default 1, stride of the first layer.
conv_shortcut: default False, use convolution shortcut if True, otherwise identity shortcut.
name: string, block label.
Returns:
Output tensor for the residual block.
'''
def block2(x, filters, kernel_size=3, stride=1, conv_shortcut=False, name=None):
preact = BatchNormalization(name=name + '_preact_bn')(x)
preact = Activation('relu', name=name + '_preact_relu')(preact)
if conv_shortcut:
shortcut = Conv2D(4 * filters, 1, strides=stride, name=name + '_0_conv')(preact)
else:
shortcut = MaxPooling2D(1, strides=stride)(x) if stride > 1 else x
x = Conv2D(filters, 1, strides=1, use_bias=False, name=name + '_1_conv')(preact)
x = BatchNormalization(name=name + '_1_bn')(x)
x = Activation('relu', name=name + '_1_relu')(x)
x = ZeroPadding2D(padding=((1, 1), (1, 1)), name=name + '_2_pad')(x)
x = Conv2D(filters, kernel_size, strides=stride, use_bias=False, name=name + '_2_conv')(x)
x = BatchNormalization(name=name + '_2_bn')(x)
x = Activation('relu', name=name + '_2_relu')(x)
x = Conv2D(4 * filters, 1, name=name + '_3_conv')(x)
x = layers.Add(name=name + '_out')([shortcut, x])
return x
大概对比了下和ResNet50的源代码,发现关于identity shortcut这里稍微有点区别。ResNet50中是这样的:
if conv_shortcut:
shortcut = layers.Conv2D(4 * filters, 1, strides=stride, name=name + '_0_conv')(x)
shortcut = layers.BatchNormalization(axis=bn_axis, epsilon=1.001e-5, name=name + '_0_bn')(shortcut)
else:
shortcut = x
而ResNet50V2中是这样的:
if conv_shortcut:
shortcut = layers.Conv2D(4 * filters, 1, strides=stride, name=name + '_0_conv')(preact)
else:
# 注意后面还多了if语句
shortcut = layers.MaxPooling2D(1, strides=stride)(x) if stride > 1 else x
除此之外,在ResNet50源代码中是没有预激活的(上面代码中的preact)。
2.2 堆叠Residual Block
def stack2(x, filters, blocks, stride1=2, name=None):
x = block2(x, filters, conv_shortcut=True, name=name+'_block1')
for i in range(2, blocks):
x = block2(x, filters, name=name+'_block'+str(i))
x = block2(x, filters, stride=stride1, name=name+'_block'+str(blocks))
return x
2.3 Resnet50V2架构复现
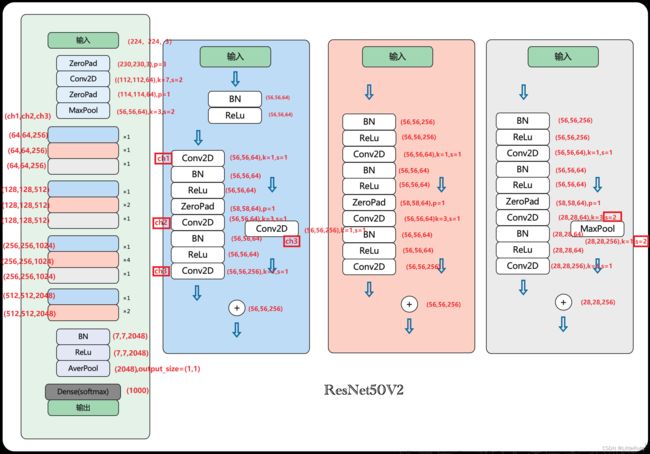
2.4 ResNet50V2模型结构大图
3 pytorch实现Resnet50V2算法
# -*- coding: utf-8 -*-
# @Author : Ruby
# @File : J2_ResNet50V2-pytorch.py
import torch
import torch.nn as nn
import time
import copy
from torchvision import transforms, datasets
import os
from pathlib import Path
from PIL import Image
import torchsummary as summary
import torch.nn.functional as F
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
import warnings
warnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
''' Residual Block '''
class Block2(nn.Module):
def __init__(self, in_channel, filters, kernel_size=3, stride=1, conv_shortcut=False):
super(Block2, self).__init__()
self.preact = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(True)
)
self.shortcut = conv_shortcut
if self.shortcut:
self.short = nn.Conv2d(in_channel, 4*filters, 1, stride=stride, padding=0, bias=False)
elif stride>1:
self.short = nn.MaxPool2d(kernel_size=1, stride=stride, padding=0)
else:
self.short = nn.Identity()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, filters, 1, stride=1, bias=False),
nn.BatchNorm2d(filters),
nn.ReLU(True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(filters, filters, kernel_size, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(filters),
nn.ReLU(True)
)
self.conv3 = nn.Conv2d(filters, 4*filters, 1, stride=1, bias=False)
def forward(self, x):
x1 = self.preact(x)
if self.shortcut:
x2 = self.short(x1)
else:
x2 = self.short(x)
x1 = self.conv1(x1)
x1 = self.conv2(x1)
x1 = self.conv3(x1)
x = x1 + x2
return x
class Stack2(nn.Module):
def __init__(self, in_channel, filters, blocks, stride=2):
super(Stack2, self).__init__()
self.conv = nn.Sequential()
self.conv.add_module(str(0), Block2(in_channel, filters, conv_shortcut=True))
for i in range(1, blocks - 1):
self.conv.add_module(str(i), Block2(4 * filters, filters))
self.conv.add_module(str(blocks - 1), Block2(4 * filters, filters, stride=stride))
def forward(self, x):
x = self.conv(x)
return x
''' 构建ResNet50V2 '''
class ResNet50V2(nn.Module):
def __init__(self,
include_top=True, # 是否包含位于网络顶部的全链接层
preact=True, # 是否使用预激活
use_bias=True, # 是否对卷积层使用偏置
input_shape=[224, 224, 3],
classes=1000,
pooling=None): # 用于分类图像的可选类数
super(ResNet50V2, self).__init__()
self.conv1 = nn.Sequential()
self.conv1.add_module('conv', nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=use_bias, padding_mode='zeros'))
if not preact:
self.conv1.add_module('bn', nn.BatchNorm2d(64))
self.conv1.add_module('relu', nn.ReLU())
self.conv1.add_module('max_pool', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.conv2 = Stack2(64, 64, 3)
self.conv3 = Stack2(256, 128, 4)
self.conv4 = Stack2(512, 256, 6)
self.conv5 = Stack2(1024, 512, 3, stride=1)
self.post = nn.Sequential()
if preact:
self.post.add_module('bn', nn.BatchNorm2d(2048))
self.post.add_module('relu', nn.ReLU())
if include_top:
self.post.add_module('avg_pool', nn.AdaptiveAvgPool2d((1, 1)))
self.post.add_module('flatten', nn.Flatten())
self.post.add_module('fc', nn.Linear(2048, classes))
else:
if pooling=='avg':
self.post.add_module('avg_pool', nn.AdaptiveAvgPool2d((1, 1)))
elif pooling=='max':
self.post.add_module('max_pool', nn.AdaptiveMaxPool2d((1, 1)))
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.post(x)
return x
"""训练模型--编写训练函数"""
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 加载数据加载器,得到里面的 X(图片数据)和 y(真实标签)
X, y = X.to(device), y.to(device) # 用于将数据存到显卡
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # 清空过往梯度
loss.backward() # 反向传播,计算当前梯度
optimizer.step() # 根据梯度更新网络参数
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
"""训练模型--编写测试函数"""
# 测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad(): # 测试时模型参数不用更新,所以 no_grad,整个模型参数正向推就ok,不反向更新参数
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item() # 统计预测正确的个数
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
plt.axis("off")
plt.imshow(test_img) # 展示预测的图片
plt.show()
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_, pred = torch.max(output, 1)
pred_class = classes[pred]
print(f'预测结果是:{pred_class}')
if __name__ == '__main__':
"""前期准备-设置GPU"""
# 如果设备上支持GPU就使用GPU,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using {} device".format(device))
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\bird\bird_photos"
data_dir = Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[-1] for path in data_paths]
print(classeNames)
'''前期工作-可视化数据'''
subfolder = Path(data_dir)/"Cockatoo"
image_files = list(p.resolve() for p in subfolder.glob('*') if p.suffix in [".jpg", ".png", ".jpeg"])
plt.figure(figsize=(10, 6))
for i in range(len(image_files[:12])):
image_file = image_files[i]
ax = plt.subplot(3, 4, i + 1)
img = Image.open(str(image_file))
plt.imshow(img)
plt.axis("off")
# 显示图片
plt.tight_layout()
plt.show()
'''前期工作-图像数据变换'''
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(str(data_dir), transform=train_transforms)
print(total_data)
print(total_data.class_to_idx)
'''前期工作-划分数据集'''
train_size = int(0.8 * len(total_data)) # train_size表示训练集大小,通过将总体数据长度的80%转换为整数得到;
test_size = len(total_data) - train_size # test_size表示测试集大小,是总体数据长度减去训练集大小。
# 使用torch.utils.data.random_split()方法进行数据集划分。该方法将总体数据total_data按照指定的大小比例([train_size, test_size])随机划分为训练集和测试集,
# 并将划分结果分别赋值给train_dataset和test_dataset两个变量。
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print("train_dataset={}\ntest_dataset={}".format(train_dataset, test_dataset))
print("train_size={}\ntest_size={}".format(train_size, test_size))
'''前期工作-加载数据'''
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
'''前期工作-查看数据'''
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
"""搭建包含Backbone模块的模型"""
model = ResNet50V2().to(device)
print(model)
print(summary.summary(model, (3, 224, 224)))#查看模型的参数量以及相关指标
# exit()
"""训练模型--设置超参数"""
loss_fn = nn.CrossEntropyLoss() # 创建损失函数,计算实际输出和真实相差多少,交叉熵损失函数,事实上,它就是做图片分类任务时常用的损失函数
learn_rate = 1e-4 # 学习率
optimizer1 = torch.optim.SGD(model.parameters(), lr=learn_rate)# 作用是定义优化器,用来训练时候优化模型参数;其中,SGD表示随机梯度下降,用于控制实际输出y与真实y之间的相差有多大
optimizer2 = torch.optim.Adam(model.parameters(), lr=learn_rate)
optimizer3 = torch.optim.Adam(model.parameters(), lr=learn_rate, weight_decay=1e-4) #增加权重衰减,即L2正则化
lr_opt = optimizer2
model_opt = optimizer2
# 调用官方动态学习率接口时使用2
lambda1 = lambda epoch : 0.92 ** (epoch // 4)
scheduler = torch.optim.lr_scheduler.LambdaLR(lr_opt, lr_lambda=lambda1) # 选定调整方法
"""训练模型--正式训练"""
epochs = 30
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_test_acc=0
for epoch in range(epochs):
milliseconds_t1 = int(time.time() * 1000)
# 更新学习率(使用自定义学习率时使用)
# adjust_learning_rate(lr_opt, epoch, learn_rate)
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, model_opt)
# scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = lr_opt.state_dict()['param_groups'][0]['lr']
milliseconds_t2 = int(time.time() * 1000)
template = ('Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E}')
if best_test_acc < epoch_test_acc:
best_test_acc = epoch_test_acc
#备份最好的模型
best_model = copy.deepcopy(model)
template = (
'Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E},Update the best model')
print(
template.format(epoch + 1, milliseconds_t2-milliseconds_t1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
print('Done')
"""训练模型--结果可视化"""
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
"""保存并加载模型"""
# 模型保存
# PATH = './model.pth' # 保存的参数文件名
# torch.save(model.state_dict(), PATH)
# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))
"""指定图片进行预测"""
classes = list(total_data.class_to_idx)
# 预测训练集中的某张照片
predict_one_image(image_path=str(Path(data_dir)/"Cockatoo/001.jpg"),
model=model,
transform=train_transforms,
classes=classes)
"""模型评估"""
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
# 查看是否与我们记录的最高准确率一致
print(epoch_test_acc, epoch_test_loss)
训练过程如下:
Epoch: 2, duration:3530ms, Train_acc:70.1%, Train_loss:2.031, Test_acc:43.4%,Test_loss:3.432, Lr:1.00E-04,Update the best model
Epoch: 3, duration:3528ms, Train_acc:81.4%, Train_loss:0.740, Test_acc:73.5%,Test_loss:0.985, Lr:1.00E-04,Update the best model
Epoch: 4, duration:3561ms, Train_acc:85.8%, Train_loss:0.454, Test_acc:88.5%,Test_loss:0.431, Lr:1.00E-04,Update the best model
Epoch: 5, duration:3564ms, Train_acc:92.7%, Train_loss:0.273, Test_acc:82.3%,Test_loss:0.479, Lr:1.00E-04
Epoch: 6, duration:3481ms, Train_acc:93.6%, Train_loss:0.218, Test_acc:80.5%,Test_loss:0.571, Lr:1.00E-04
Epoch: 7, duration:3502ms, Train_acc:90.5%, Train_loss:0.296, Test_acc:89.4%,Test_loss:0.339, Lr:1.00E-04,Update the best model
Epoch: 8, duration:3534ms, Train_acc:92.5%, Train_loss:0.214, Test_acc:82.3%,Test_loss:0.616, Lr:1.00E-04
Epoch: 9, duration:3490ms, Train_acc:95.8%, Train_loss:0.146, Test_acc:85.0%,Test_loss:0.494, Lr:1.00E-04
Epoch:10, duration:3530ms, Train_acc:96.0%, Train_loss:0.131, Test_acc:90.3%,Test_loss:0.272, Lr:1.00E-04,Update the best model

评估结果
0.9026548672566371 0.26340420730412006
总结
通过本次的学习,Resnet50和resnet50V2的区别,并用pythorch实现resnetv2算法。