霹雳吧啦Wz《pytorch图像分类》-p1卷积神经网络LeNet
《pytorch图像分类》p1卷积神经网络基础及代码
- 一、卷积神经网络
-
- 1.反向传播(back propagation)
- 2.常用的激活函数
- 二、神经网络层类型概述
-
- 1.全连接层
- 2.卷积层
-
- 卷积过程中出现越界
- 3.池化层/下采样层
- 三、课程代码
-
- 1.零碎知识点
-
- 1.1 nn.Conv2d
- 1.2 nn.Maxpool2d
- 1.3 enumerate
- 2.课程代码
-
- 2.1 model.py
- 2.2 train.py
- 2.3 predict.py
一、卷积神经网络
CNN(Convolution Neural Network)卷积神经网络
只要包含了卷积层的网络都可以叫做卷积神经网络
功能:图像分类、目标检测、图像分割、无人驾驶(识别车和行人)、图像风格迁移
1.反向传播(back propagation)
反向传播是一种用于计算误差函数对参数的导数(梯度)。
在前馈传播过程中,我们通过网络的每一层,从输入层到输出层,计算每个神经元的输出。这样,我们就可以获得网络的预测结果。在反向传播过程中,我们需要计算每个参数对误差的导数,以便我们可以调整参数来最小化误差。
举个例子:
在线性回归函数 y = ω ⋅ x + b y = \omega\cdot x +b y=ω⋅x+b 中,我们假设了 ω \omega ω 和 b b b 的值,代入 x x x ,得到 y ^ \hat{y} y^,但是 y ^ \hat{y} y^ 和 y y y 是有偏差的,所以为了进一步精确参数,我们需要利用反向传播来计算它的导数,不断调整误差。
我之前学过了部分,可以参考一下:刘二大人《PyTorch深度学习实践》p4反向传播
2.常用的激活函数

- Sigmoid激活函数
Sigmoid函数的优点是输出范围在(0, 1)之间,可以将输入映射到概率形式或者用于二分类问题中。
缺点是激活函数饱和时,梯度非常小,网络层数较深时容易出现梯度消失。
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+\mathcal{e}^{-x}} f(x)=1+e−x1 - ReLU激活函数
relu函数求导简单方便;但是当反向传播过程中,权值更新小于0时,导致该处的导数始终为0,无法更新权值,会进入失活状态。
f ( x ) = M a x ( 0 , x ) f(x)=Max(0,x) f(x)=Max(0,x)
二、神经网络层类型概述
1.全连接层
全连接层由许许多多的神经元连接
作用是对输入特征进行组合和转换,引入非线性变换,并且能够学习到输入数据中的复杂关系。
2.卷积层
卷积层通过应用卷积操作,将输入数据与一系列可学习的卷积核(也称为滤波器)进行卷积运算。
简单来说就是一个滑动窗口在特征图上滑动并计算。
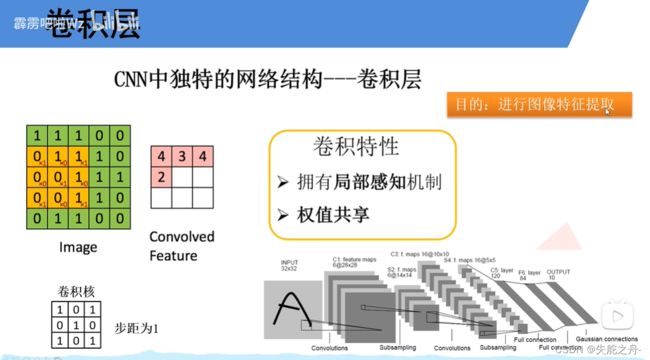
卷积核的深度与输入特征层的深度相同
输出的特征矩阵的深度和卷积核的个数相同
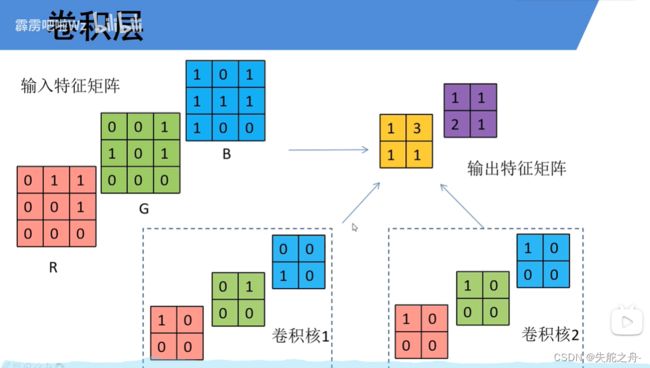
卷积过程中出现越界
一般是补0操作
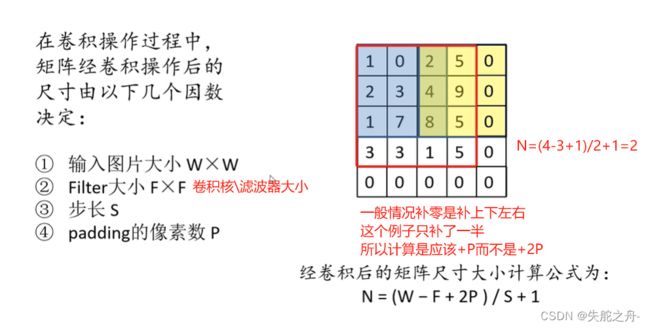
3.池化层/下采样层
下采样层(Pooling Layer),用于减少特征图的维度和参数数量,并提取最显著的特征。
常用的下采样操作有两种形式:
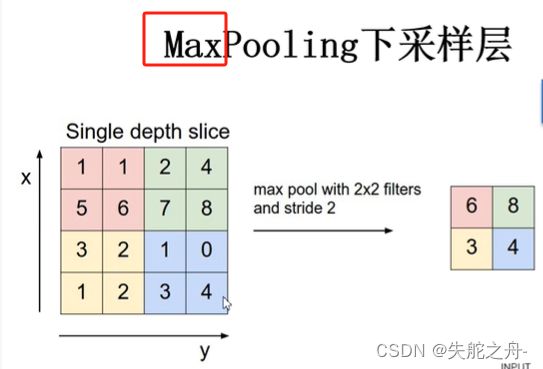
- 最大池化(Max Pooling):
最大池化是一种常用的下采样操作,它在每个池化窗口内选择最大的特征值作为汇聚后的值。最大池化会保留局部区域内的最显著特征,并且具有一定的平移不变性。
- 平均池化(Average Pooling):
平均池化是另一种常用的下采样操作,它在每个池化窗口内取特征值的平均作为汇聚后的值。平均池化能够对局部特征进行平均并减少图像的细节。与最大池化不同,平均池化通常在一些场景中更加平滑并保留更广泛的感受野。

三、课程代码
1.零碎知识点
1.1 nn.Conv2d
nn.Conv2d是PyTorch中的一个卷积层类。它用于定义二维卷积操作,可以在深度神经网络中对输入数据进行卷积计算。
基本语法如下:nn.Conv2d(in_channels,out_channels,kernel_size)
可以简单理解为nn.Conv2d(特征矩阵的深度,卷积核的个数,卷积核的大小),比如一张彩色图片,我们子集定义16个5×5的卷积核,就应该写为nn.Conv2d(3,16,5)
- in_channels:输入特征图的通道数。
- out_channels:输出特征图的通道数,也称作卷积核的数量。
- kernel_size:卷积核的大小,可以是一个整数或一个元组。
1.2 nn.Maxpool2d
nn.MaxPool2d是PyTorch中的类,用于实现二维最大池化操作。
基本语法如下:nn.MaxPool2d(- kernel_size,stride)
- kernel_size:池化窗口的大小,可以是一个整数或一个元组。如果是一个整数,则表示宽度和高度相等的池化窗口;如果是一个元组,则表示宽度和高度不同的池化窗口。
- stride:池化窗口的步长,默认值是kernel_size。
1.3 enumerate
学习记录:enumerate

2.课程代码
具体代码见老师分享的github:霹雳吧啦Wzdeep-learning-for-image-processing
2.1 model.py
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
2.2 train.py
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
def main():
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
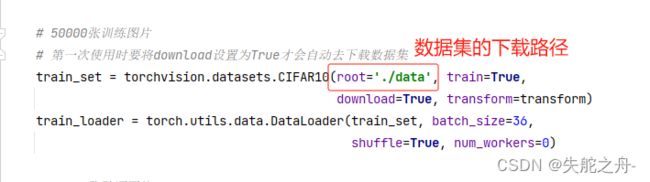
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)
# classes = ('plane', 'car', 'bird', 'cat',
# 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(val_image) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
2.3 predict.py
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
transform = transforms.Compose(
[transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
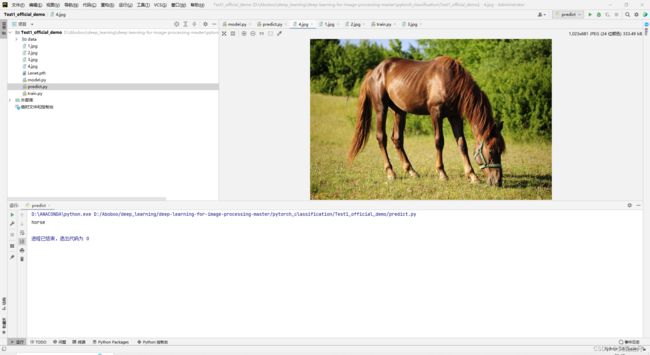
im = Image.open('4.jpg')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]
with torch.no_grad():
outputs = net(im)
predict = torch.max(outputs, dim=1)[1].numpy()
print(classes[int(predict)])
if __name__ == '__main__':
main()
马的图片预测成功~