(2023,3D NeRF,无图像变分分数蒸馏,单步扩散)SwiftBrush:具有变分分数蒸馏的一步文本到图像扩散模型
SwiftBrush : One-Step Text-to-Image Diffusion Model with Variational Score Distillation
公众:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
1. 方法
1.1 基础
1.2 SwiftBrush
2. 结果
3. 未来工作
S. 总结
S.1 主要贡献
S.2 方法
0. 摘要
尽管文本到图像扩散模型能够从文本提示生成高分辨率和多样化的图像,但通常会受到缓慢的迭代采样过程的困扰。模型蒸馏是加速这些模型的最有效方法之一。然而,先前的蒸馏方法在要求大量图像进行训练时未能保留生成质量,这些图像可以来自真实数据,也可以是由教师模型合成生成的。针对这一限制,我们提出了一种新颖的无图像蒸馏方案,名为 SwiftBrush。从文本到 3D 合成中汲取灵感,该方法通过专用损失从 2D 文本到图像扩散先验获取与输入提示对齐的 3D 神经辐射场(Neural Radiance Fields,NeRF),而无需使用任何 3D 真实数据。我们的方法重新利用相同的损失,将经过预训练的多步文本到图像模型蒸馏到一个只需单一推理步骤就能生成高保真图像的学生网络。尽管模型简单,但我们的模型是第一个能够一步生成与 Stable Diffusion 相媲美质量的文本到图像生成器之一,而无需依赖任何训练图像数据。值得注意的是,SwiftBrush 在 COCO-30K 基准测试中取得了 16.67 的 FID 分数和 0.29 的 CLIP 分数,实现了有竞争力的结果,甚至在某些方面超越了现有的最先进蒸馏技术。
1. 方法
1.1 基础
分数蒸馏采样 (Score Distillation Sampling,SDS) 是一种用于预训练扩散模型的蒸馏技术,有效地应用于 3D 生成 [17, 26, 42]。它利用预训练的文本到图像扩散模型,该模型从文本条件 y 中预测扩散噪声,表示为 ϵ_ψ(x_t, t, y)。该方法优化一个由 θ 参数化的单一 3D NeRF,使其与给定的文本提示对齐。给定摄像机参数 c,使用可微分渲染函数 g(·, c) 从 3D NeRF 对摄像机视图 c 的图像进行渲染。在这里,利用渲染后的图像 g(θ, c) 优化权重 θ,通过一个损失函数的梯度可以近似表示为:

其中 t ∼ U(0.02T, 0.98T),T 是扩散模型的最大时间步长,ϵ ∼ N(0, I),有噪图像 x_t = α_t·g(θ, c) + σ_t·ϵ,y 是输入文本,w(t) 是权重函数。
尽管在文本到三维合成方面取得了进展,经验研究 [26, 42] 表明 SDS 经常遇到过饱和、过度平滑和多样性减少等问题。如果我们在我们的框架中简单地应用 SDS,就会观察到相同的退化。
变分分数蒸馏 (Variational Score Distillation,VSD) 在 ProlificDreamer [43] 中引入,通过稍微修改损失来解决先前提到的 SDS 的问题:

再次,x_t = α_t·g(θ, c) + σ_t·ϵ 是相机视图 c 的渲染图像的带噪声观察。VSD 通过引入一个额外的、专门针对从相机姿态 c 渲染的 3D NeRF 的图像的评分函数,使自己与 SDS 区别开来。这个评分是通过微调具有下面描述的扩散损失的扩散模型 ϵ_ϕ(x_t, t, y, c) 而导出的:
![]()
按照 ProlificDreamer 的提议,ϵ_ϕ 是由低秩适应 [11](Low-Rank Adaption,LoRA)参数化的,并且从预训练的扩散模型 ϵ_ψ 初始化,其中添加了一些层来对相机视图 c 进行调节。请注意,在优化过程的每个迭代 i 中,ϵ_ϕ 需要根据 θ 的当前分布进行调整。因此,ProlificDreamer 在微调 ϵ_ϕ 和优化 θ 之间交替进行。通过这些算法增强,ProlificDreamer 显著提高了其能力,实现了 NeRF 的生成和出色纹理网格的创建。这种改进直接启发我们将 VSD 调整到一步文本到图像基于扩散的蒸馏的任务中。
1.2 SwiftBrush
动机。虽然 SDS 和 VSD 明确设计用于文本到 3D 生成任务,但它们通过 3D NeRF 的渲染图像 g(θ, c) 来松散连接到该目标。事实上,我们可以用任何输出 2D 图像以满足我们需求的函数替换 NeRF 渲染。受到这一动机的启发,我们建议用一个可以一步实现文本引导图像生成的的文本到图像生成器来替代 NeRF 渲染 g(θ, c),从而将文本到 3D 生成训练有效地转化为一步扩散模型蒸馏。
设计空间。我们采用与 [43] 相同的方法,对设计空间进行修改以更好地适应我们的任务。首先,我们利用两个教师模型:一个预训练的文本到图像教师 ϵ_ψ 和一个额外的 LoRA 教师 ϵ_ϕ。此外,我们从 LoRA 教师中去掉了相机视图 c 的调节,因为在我们的情况下这是不必要的,并且我们为两个教师都使用无分类器指导(classifier-free guidance,CFG)。然后,我们用一个通用的一步文本到图像学生模型 f_θ(z, y) 替换在文本到 3D 设置中对特定的用户提供的提示过拟合的 NeRF。我们的学生模型 f_θ 接受随机高斯噪声 z 和文本提示 y 作为输入。LoRA 教师和学生模型都使用文本到图像教师的权重进行初始化。接下来,我们在冻结文本到图像教师的同时,使用公式 (5) 和公式 (6),交替训练学生模型和 LoRA 教师。伪代码和系统图示可在 Alg. 1 和 Fig. 2 中查看。


学生参数化。给定一个预训练的文本到图像扩散模型 ϵ_θ,直接使用它的输出作为学生模型是可能的,即,f_θ(z, y) = ϵ_θ(z, T, y),其中 T 是预训练模型的最大时间步。然而,在我们的情况下,所选择的预训练模型是 Stable Diffusion,它被固有地设计为预测添加的噪声 ϵ。相反,我们的目标是优化学生模型,使其预测出一个干净、无噪声的图像 x_0。因此,我们想要学生学习的内容与学生输出之间存在很大的领域差距。为了便于训练,我们经验性地重新参数化学生输出如下:
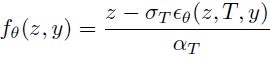
这是方程 (1) 的一种实现,如果我们设置 t = T,x_t = z,ϵ ≈ ϵ_θ(z, T, y),以及 x_0 ≈ f_θ(z, y)。因此,基本上,这种重新参数化将预训练模型的预测噪声输出转换为 “预测 x_0” 的形式,在第 4.3 节中经验性地证明这对学生模型的学习是有帮助的。
![]()
2. 结果
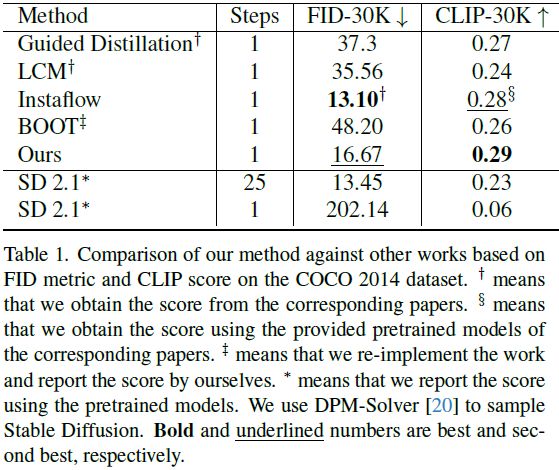
在 MS COCO 上与其他模型的对比表现良好。
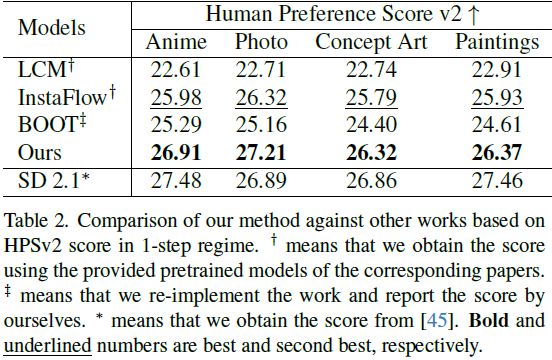
在人类评估方面表现良好。

消融研究。使用 VDS(Full)生成的图像更逼真。
3. 未来工作
相比于利用多步采样进行推断的教师,SwiftBrush 不可避免地产生更低质量的样本。另一个缺点是目前的设计只关注单步学生模型,无法像 Luo 等人 [22] 那样支持少步生成以提高图像保真度。在未来的工作中,我们的目标是调查将 SwiftBrush 扩展到少步生成的可行性,以便我们可以通过计算来换取质量。此外,我们还发现探索类似 SwiftBrush 的训练,只需要一个教师,具有引人入胜的吸引力。这样的探索在计算资源有限的场景中可能带来巨大的好处。最后,令人着迷的是看到像 DreamBooth [33]、ControlNet [47] 或 InstructPix2Pix [2] 这样的技术是否可以与 SwiftBrush 集成,实现各种应用的即时生成。
S. 总结
S.1 主要贡献
在文本到 3D 合成中,通过专用损失从 2D 文本到图像扩散先验获取与输入提示对齐的 3D 神经辐射场(Neural Radiance Fields,NeRF),而无需使用任何 3D 真实数据。
受此启发,本文提出无图像蒸馏方案 SwiftBrush,利用相同的损失,将经过预训练的多步文本到图像模型蒸馏到一个只需单一推理步骤就能生成高保真图像的学生网络。
S.2 方法
本文使用的架构如图 2 所示。
- 给定一个预训练的文本到图像扩散模型 ϵ_ψ,将其参数冻结作为教师网络。
- 对于由教师模型 ϵ_ψ 初始化的低秩适应(Low-Rank Adaption,LoRA)教师网络 ϵ_ϕ 和学生网络 f_θ,交替使用公式 5 (优化)和公式 6 (微调)。其中 t ∼ U(0.02T, 0.98T),T 是扩散模型的最大时间步长,ϵ ∼ N(0, I),有噪图像 x_t = α_t·g(θ, c) + σ_t·ϵ,y 是输入文本,w(t) 是权重函数。
- 两个教师都使用无分类器指导(classifier-free guidance,CFG)
![]()