【Video-LLaMA】增强LLM对视频内容的理解
Paper:《Video-LLaMA : An Instruction-tuned Audio-Visual Language Model for Video Understanding》
Authors: Hang Zhang, Xin Li, Lidong Bing;
Affiliation: The Alibaba DAMO Academy;
Keywords: Multimodal Large Language Models, Cross-modal training.
研发背景
大型语言模型 (LLM)在遵循用户意图和指示上表现出了卓越的理解和理解能力,通常,LLM的用户请求和相应的响应都是文本形式的,然而,由于现实世界的信息通常是多模态的,仅文本人机交互对于许多应用场景来说是不够的。为了进一步开发LLM的潜力,许多研究人员试图赋予LLM理解多模态内容的能力。但大多数方法致力于附加一种模态(即图像或音频),与文本对齐,这对于视频理解来说并不令人满意。
Video-LLaMA利用多模态(图像和音频)增强对视频内容理解。
如下图,Video-LLaMA具有理解静态图片,无音视频和音频的能力。
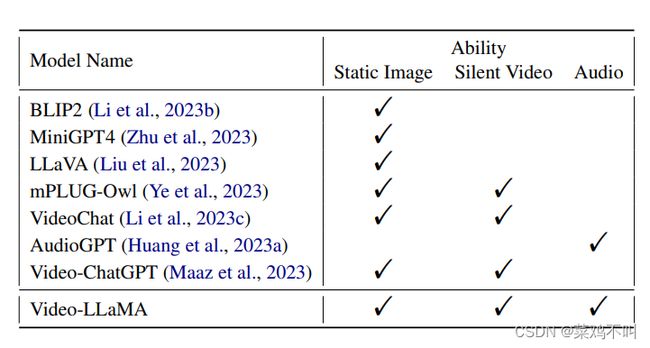
主要工作:
研究了支持视频输入并允许用户围绕用户上传的视频与计算机聊天的多模态LLM的可能性,该视频通常有多个视频帧和音频。提出了一种多分支跨模态训练模型,将冻结的大预言模型和冻结的图形/音频编码器链接起来,以实现视觉-语言与音频-语言对齐。
如下图所示,设计了两个分支,即视觉语言分支(Vision-Language Branch)和音频语言分支(Audio-Language Branch),分别将视频帧和音频信号转换为与LLM的文本输入兼容的查询表示。
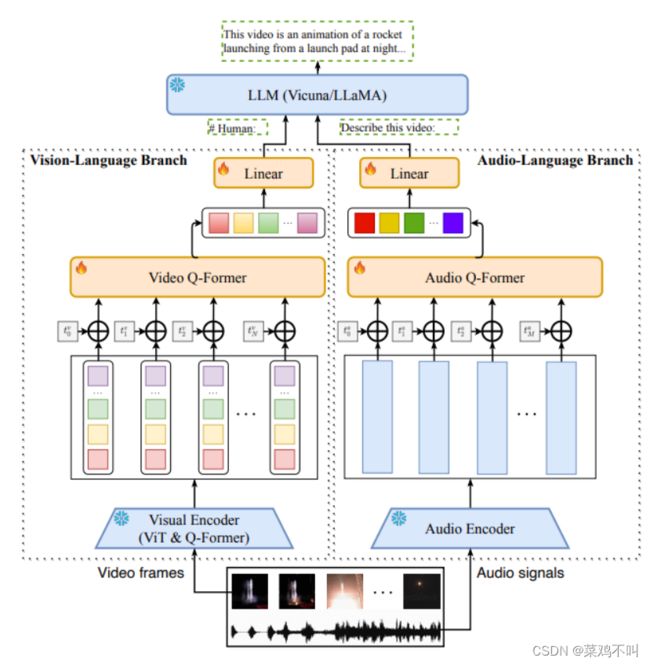
Vision-Language Branch
视觉语言分支旨在使LLM能够理解视觉输入。如图 2 左侧所示,它由一个用于从视频帧中提取特征的冻结预训练图像编码器、一个用于将时间信息注入视频帧的位置嵌入层、一个用于聚合帧级的视频 Q-former 以及一个线性层将输出的视频表示投影到与 LLM 的文本嵌入相同的维度。给定一个视频由 N 帧组成,图像编码器将首先将每个帧/图像映射到 K f K_f Kf图像嵌入向量,产生视频帧表示 V = [ v 1 , v 2 , . . . , v N v_1, v_2, ..., v_N v1,v2,...,vN],其中 v i ∈ R K f × d f v_i ∈ R^{K_f ×d_f} vi∈RKf×df 是集合对应于第 i 帧的 d f d_f df 维图像嵌入。
由于来自冻结图像编码器的帧表示 v i v_i vi 是在不考虑任何时间信息的情况下计算的,因此需要将位置嵌入作为时间信息的指示符应用于来自不同帧的表示。然后们将位置编码的帧表示送到 Video Q-former,它与 BLIP-2 中的查询转换器 (QFormer) 共享相同的架构,以获得维度为 d v d_v dv 的 k V k_V kV视频嵌入向量作为视频的表示 V ˆ ∈ R k V × d v \overset{ˆ}V ∈ R^{k_V ×d_v} Vˆ∈RkV×dv
为了使视频表示适应 LLM 的输入,添加了一个线性层来将视频嵌入向量转换为视频查询向量。
视频查询向量与LLM的文本嵌入具有相同的维度。在前向传播中,它们将作为视频软提示与文本嵌入连接起来,并指导冻结的LLM生成以视频内容为条件的文本。
Vision-Language 分支的实现,利用 BLIP-2的预训练视觉组件作为冻结视觉编码器,其中包括来自 EV A-CLIP 的 ViTG/14和一个预先训练的 Q-former。其余组件,包括位置嵌入层、视频 Qformer 和线性层,都被随机初始化和优化,以将冻结视觉编码器的输出很好地连接到冻结的 LLM。
Audio-Language Branch
为了处理给定视频的听觉内容,引入了音频语言分支。具体来说,它由一个预先训练的音频编码器组成,用于计算给定一小段原始音频的特征,一个位置嵌入层,用于向音频片段注入时间信息,一个音频 Q-former,用于融合不同音频片段的特征,以及一个线性层将音频表示映射到 LLM 的嵌入空间中。
利用预先训练的 Imagebind作为音频编码器。首先从视频中均匀采样 M 个 2 秒短音频片段,然后使用 128 个梅尔频谱图箱将每个 2 秒音频片段转换为频谱图。获得输入音频的频谱图列表后,音频编码器将每个频谱图映射为密集向量。因此,给定视频生成的音频表示可以表示为 A = [ a 1 , a 2 , . . . , a M ] 。 A = [a_1, a_2, ..., a_M]。 A=[a1,a2,...,aM]。
与视频 Q-Former 类似,音频 Q-former 通过向音频片段添加可学习的位置嵌入来注入时间信息。然后,通过计算位置编码音频片段之间的交互来生成固定长度的音频特征。 Audio Q-Former 采用与 Q-Former 相同的架构。它将可变长度音频表示列表 A 投影为固定长度序列$ \overset{ˆ}A ∈ R^{K_a×d_a}$,其中 K a K_a Ka 是音频嵌入向量的数量, d a d_a da 是每个向量的维度。最后,使用线性层将音频特征映射到 LLM 的嵌入空间。
如何训练
分别训练视觉语言和音频语言分支。在第一阶段,使用大规模视觉字幕数据集进行训练,在第二阶段,使用高质量的指令跟踪数据集进行微调。该图像被视为一帧视频。
Training of Vision-Language Branch
对于视觉语言分支的预训练,使用了 Webvid-2M(一个来自素材网站的带有文本描述的大规模短视频数据集),图像描述数据集 CC595k。在预训练阶段采用视频到文本生成任务,即给定视频的表示,促使冻结的LLM生成相应的文本描述。但是很大一部分文字描述不足以反映视频的全部内容。因此,视频中的视觉语义与视频描述中的文本语义并不完全一致。尽管如此,这一阶段的目标是利用大量数据,使视频特征包含尽可能多的视觉知识。将视觉文本对齐和指令跟踪的能力留给下一阶段。
经过预训练阶段后,模型可以生成有关视频中信息的内容,但其遵循指令的能力有所下降。因此,在第二阶段,使用高质量的指令数据对模型进行微调。集成了 MiniGPT4 的图像细节描述数据集、LLaV A 的图像指令数据集和 Video-Chat 的视频指令数据集 。经过微调,Video-LLaMA 在遵循指令和理解图像和视频方面表现出了卓越的能力。
Training of Audio-Language Branch
由于此类数据的稀有性,直接使用音频文本数据训练音频语言分支非常具有挑战性。音频语言分支中可学习参数的目标是将冻结音频编码器的输出嵌入与 LLM 的嵌入空间对齐。
鉴于音频文本数据的稀缺,采用一种变通策略来实现这一目标。用作音频编码器的 ImageBind 具有将不同模态的嵌入对齐到一个公共空间的能力,在跨模态检索和生成任务上展示了很强的性能。鉴于音频文本数据的稀缺性和视觉文本数据的丰富性,我们使用视觉文本数据训练音频语言分支,遵循与视觉分支相同的数据和过程。得益于 ImageBind 提供的共享嵌入空间,Video-LLaMA 在推理过程中展现了理解音频的能力,即使音频接口从未接受过音频数据的训练。
展示
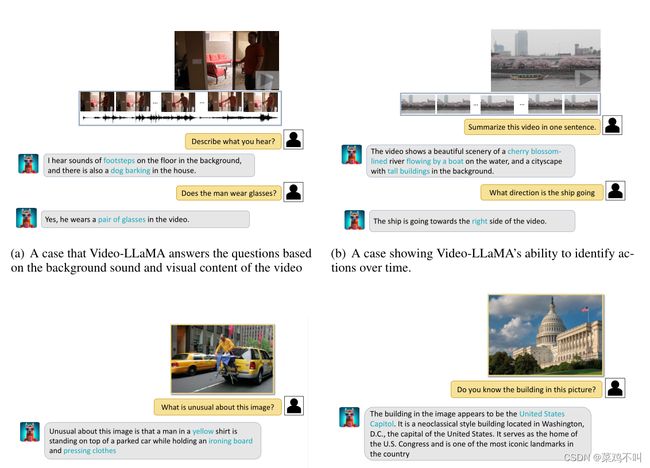
(1)视听整合感知能力。
图 2(a) 显示了 Video-LLaMA 同时理解听觉和视觉信息的独特能力。两种情况下的视频都包含音频。在每次对话中分别提出两个与视觉和听觉内容相关的问题。如果模型只能接收一种模态,它将无法回答这两个问题。然而,可以观察到 VideoLLaMA 在这两种情况下都能准确地响应视觉和听觉问题。
(2) 捕捉视频中时间动态的能力。图 2(b) 说明了 Video-LLaMA 识别随时间变化的操作的能力。它成功地描述了和船的行进方向。
(3)感知和理解静态图像的能力。图 2© 显示了 VideoLLaMA 感知和理解图片的能力。图 2© 展示了 Video-LLaMA 理解“不寻常”概念并具体描述不寻常场景的能力。
不足
存在一些局限性,包括:
(1)有限的感知能力:Video-LLaMA 的性能受到以下因素的阻碍:当前训练数据集的质量和规模。
(2)处理长视频的能力有限。长视频(例如电影、电视节目)包含大量信息,对计算资源提出更高的要求。
(3)幻觉。 Video-LLaMA 继承了冻结LLM的幻觉问题。