机器学习(二) -- 数据预处理(3)
系列文章目录
机器学习(一) -- 概述
机器学习(二) -- 数据预处理(1-3)
未完待续……
目录
前言
tips:这里只是总结,不是教程哈。本章开始会用到numpy,pandas以及matplotlib,这些就不在这讲了哈。
“***”开头的是给好奇心重的宝宝看的,其实不太重要可以跳过。
此处以下所有内容均为暂定,因为我还没找到一个好的,让小白(我自己)也能容易理解(更系统、嗯应该是宏观)的讲解顺序与方式。
第一文主要简述了一下机器学习大致有哪些东西(当然远远不止这些),对大体框架有了一定了解。接着我们根据机器学习的流程一步步来学习吧,掐掉其他不太用得上我们的步骤,精练起来就4步(数据预处理,特征工程,训练模型,模型评估),其中训练模型则是我们的重头戏,基本上所有算法也都是这一步,so,这个最后写,先把其他三个讲了,然后,在结合这三步来进行算法的学习,兴许会好点(个人拙见)。
四、***【数据集成】
将多个数据源中的数据合并,存放于一个一致的数据存储中。
数据集成过程中的关键问题:1. 实体识别、2. 数据冗余和相关分析、3.元组重复、4. 数据值冲突检测与处理
常见的数据集成方式包括:数据堆叠(stack)、数据合并(merge)和数据拼接(concatenate)等。
不算最重要的,大致了解即可。
五、***【数据变换】
数据变换是指将原始数据集转换成适合机器学习算法模型的新数据集的过程,它是机器学习中重要的一步。在数据变换的过程中,常常需要对数据进行特征缩放、特征选择和特征降维等操作。
(提前解答好奇宝宝:其实数据预处理和特征工程,两者并无明显的界限,都是为了更好的探索数据集的结构,获得更多的信息,将数据送入模型中之前进行整理。可以说数据预处理是初级的特征处理,特征工程是高级的数据预处理,也可以说这里的预处理过程是广义的,包含所有的建模前的数据预处理过程。)既然如此这个就特征工程的时候讲。
六、***【数据归约】
数据挖掘时往往数据量非常大,在大量数据上进行挖掘分析需要很长的时间,数据归约技术可以用来得到数据集的归约表示,它小得多,但仍然接近于保持原数据的完整性,并结果与归约前结果相同或几乎相同。也就是说,在归约后的数据集上挖掘将更有效,而且仍会产生相同或相似的分析结果。
数据归约包括维度归约、数量归约和数据压缩。
维度归约:如果数据只有有些维度对数据挖掘有益,就可以去除不重要的维度,保留对挖掘有帮助的维度。
数量归约:另外一种处理数据相关性的方式是将数据表示为不同的形式来减小数据量,如聚类、回归等
数据压缩:如果数据具有潜在的相关性,那么数据实际的维度可能并不高,可以用变换的方式,用低维的数据对高维数据进行近似的表示。
非参数化数据归约包括直方图、抽样、数据立方体聚集等方法。
直方图:直方图方法就是分箱。
抽样:通过选取随机样本(子集),实现用小数据代表大数据的过程。
数据立方体聚集:数据立方体聚集帮助我们从低粒度的数据分析聚合成汇总粒度的数据分析
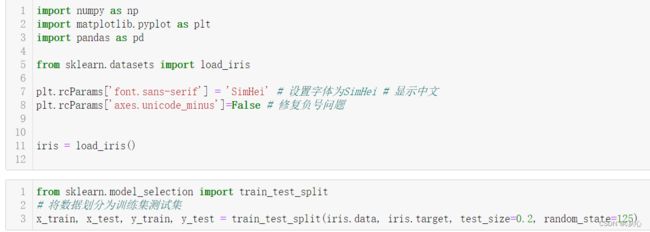
七、数据拆分
数据拆分:机器学习的数据集划分一般分为两个部分:
训练数据:用于训练,构建模型。一般占70%-80%(数据量越大,取得比例最好越大)
测试数据:用于模型评估,检验模型是否有效。一般占20%-30%
未完待续……
1、近似值
该处使用的url网络请求的数据。
2、内容
该处使用的url网络请求的数据。
3、思维方式
该处使用的url网络请求的数据。
4、根本课题
该处使用的url网络请求的数据。
1.1、嗡嗡嗡
嗡嗡嗡
1.2、十五万
嗡嗡嗡