文献阅读:PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization
- 文献阅读:PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization
- 1. 文章简介
- 2. 方法说明
- 3. 实验 & 结论
- 1. 基础实验
- 1. 实验设置
- 2. 结果分析
- 2. 细节讨论
- 1. 泛化性
- 2. 检索策略
- 3. 收敛性分析
- 4. case分析
- 1. 基础实验
- 4. 总结 & 思考
- 文献链接:https://arxiv.org/abs/2310.16427
- GitHub链接:https://github.com/XinyuanWangCS/PromptAgent
1. 文章简介
这篇文章是23年10月微软和Carnegie Mellon大学一起发表的一个Prompt调优的工作。
文中注意到,专家在处理一个问题的时候,是会在问题本身之外引入很多domain知识的(如下图所示),而当前的一些常规的prompt调优的手段,比如CoT或是迭代优化等方法,都是只专注于prompt本身,通过一些prompt表述方式的优化来试图优化LLM的回答质量。

因此,文中提出了一个Prompt Agent的方法,尝试通过反馈迭代的机制,不断地让模型自己在prompt当中引入domain内的专业知识补充,从而获得更好的prompt,让LLM生成更好的回答。

下面,我们就来看看这个Prompt Agent方法的具体实现和实验结果。
2. 方法说明
首先,文中给出了prompt优化的具体问题定义,但是这个其实比较直接,就是给定LLM以及对应的任务,然后优化prompt,然后令LLM能够在对应的task下生成最好的回答。
用数学语言表示就是:
p ∗ = a r g m a x p ∈ S ∑ i R ( p B ( a i ∣ q i , p ) ) p^{*} = \mathop{argmax}\limits_{p \in S} \sum\limits_{i} R(p_{B}(a_i|q_i, p)) p∗=p∈Sargmaxi∑R(pB(ai∣qi,p))
其中, a , q a, q a,q表示回答和对应的问题,然后 p p p表示prompt, R R R表示回答的质量, S S S为对应的prompt空间。
下面,我们首先给出文中给出的的Prompt Agent的整体框架示意图如下:

可以看到:
- 整体来说,Prompt Agent就是一个基于模型反馈的迭代优化算法,先通过CoT给出一个基础的Prompt S 0 S_0 S0,然后通过反馈机制结合Monte Carlo树不断地对prompt进行迭代优化,直到获得最终的prompt。
具体的左侧Monte-Carlo树的伪代码实现如下:

我们给出文中一个具体的输出prompt样例如下:

不过,比较惭愧的是,这里只是整理了一下文中的整体思路和伪代码实现,但是对于Prompt Agent算法的实现细节,比如具体专业知识的导入方式,迭代的实现细节以及最终的迭代停止条件其实我们都没有完全的理解,所以这里就不班门弄斧随便乱说了。好在作者将他们的算法开源了,后面可能去结合一下他们的代码实现细节来理解一下他们的具体实现方法,当然更多的可能性估计还是到时候偷懒直接拿代码来用了,如果后面真的要用的话……
Anyway,言归正传,我们还是回来看一下文中Prompt Agent的具体实验以及对应的实验结果好了。
3. 实验 & 结论
1. 基础实验
1. 实验设置
首先,文中主要是在以下一些任务上进行的基础实验:
- BBH数据集
- NLU Tasks
- Domain Specific Tasks
- General NLU Tasks
其次,关于baseline的选择的话,文中使用的主要是以下这些:
- Human prompt
- CoT
- APE
最后,使用的模型的话,文中主要使用的是GPT3.5进行生成,然后使用GPT4进行prompt的优化。
2. 结果分析
下面,我们给出文中整理的实验结果如下:
-
BBH

-
NLU

可以看到:
- Prompt Agent基本都获得了最优的生成效果。
2. 细节讨论
然后,文中还对Prompt Agent的一些细节点进行了一下额外的考察。
1. 泛化性
首先,文中考察了一下Prompt Agent方法在不同的LLM上的泛化性,得到结果如下:

可以看到:
- Prompt Agent在GPT3.5,GPT4以及PaLM2上面都有明显的效果,说明这个方法本身有着很好的泛用性。
2. 检索策略
其次,文中还考察了一下Prompt Agent实现当中使用不同的prompt检索策略对结果的影响,得到结果如下:

可以看到:
- Beam Search和Greedy算法都能带来一定的效果提升,但是文中给出的MCTS算法能够带来最大的效果增益。
3. 收敛性分析
然后,文中还考察了一下Prompt Agent算法的收敛性与收敛速度,得到结果如下:
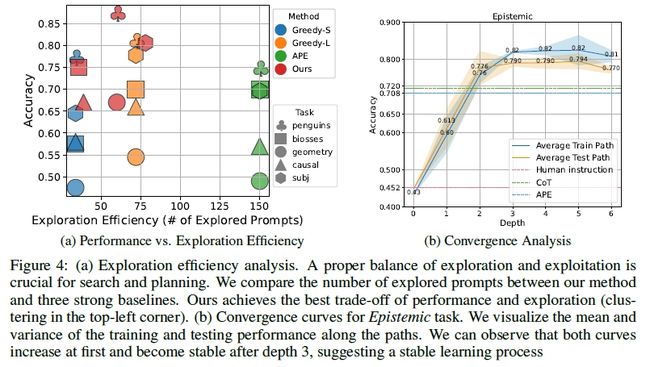
可以看到:
- 基本上,检索深度达到3层的时候,就能够获得一个稳定且效果很好的prompt了;
- 此外,和APE算法相比,Prompt Agent可以在较小的迭代cost的情况下获得更好的prompt。
4. case分析
最后,文中还通过一些具体的case来对prompt agent进行了一下定性分析。

可以看到:
- 确实在每一轮的迭代当中,prompt都增加了一些相关领域的专业知识作为辅助。
4. 总结 & 思考
综上,文中主要是提出了一个prompt agent的方法,其核心的功能是借由文中提出的prompt agent的方法,通过给prompt自动增加domain knowledge的方式来完善prompt,进而获得更好的LLM生成效果。
因此,从原理上来看,这个策略应该更适合一些复杂的问题以及包含很多先验知识的问题,在一些定义明确的场景下,可能不太能有很大的优化空间。
不过,考虑到这个方法本身已经开源了,后面有空还是可以试试的,毕竟在这个LLM猪突猛进,prompt调优越来越重要的大环境下,丰富点武器库总还是有用的。