基于改进通道注意力和多尺度卷积模块的蛋白质二级结构预测
一、背景:
传统的蛋白质三维结构预测可以通过一些传统方法预测,但是此类方法过于昂贵和耗费时间。
蛋白质二级结构是三维结构和序列的桥梁,其由多肽链中氢键的作用决定。许多研究表明,我们可以通过蛋白质的二级结构来了解其三维结构,因此对蛋白质二级结构的研究可以提高三维结构预测的准确性
蛋白质二级结构预测方法的三个阶段:
1、依赖于二级结构的单个残基的统计概率
2、通过滑动考虑蛋白质的临近残基信息,准确率低
3、多序列比对
级结构受到多肽链中的内部氢键的影响。最初,研究人员将蛋白质的二级结构分为三种状态:螺旋(H)、股(E)和卷曲(C)。随后,将三种状态扩展到八种状态,以描述具有更详细的局部结构信息的蛋白质。
与传统方法相比,深度学习在特征提取和分类方面取得了优异的性能。
二、目的:
利用多尺度卷积和通道注意设计与生成器对抗的鉴别器,通过生成对抗网络的原理使得机器学习自我提升达到更高精度的学习蛋白质的复杂特征
本研究借鉴深度学习和PSSP的研究成果,提出了基于条件GAN的PSSP(CGAN-PSSP)模型,该模型以蛋白质序列及其对应的PSSP作为输入,二级结构作为输出。 该模型由生成器生成蛋白质序列的二级结构,利用鉴别器确定二级结构的真实性。 模型训练后的生成器作为蛋白质二级结构的预测器。 我们还提出了一种基于多尺度卷积模块和改进的信道关注(ICA)模块的PSSP方法。 在多尺度卷积模块和分类模块中加入ICA模块,使模型能够自动理解不同功能通道的重要性。
三、背景知识
1、介绍生成对抗网络:
生成对抗网络(GANs)在特征提取和信号重构方面取得了优异的性能,在图像生成和分类问题中得到了广泛的应用。 虽然我们可以把PSSP看作是一个分类问题,但目前还没有发现任何基于GaN的PSSP研究; 因此,在本研究中,我们将GaN引入PSSP领域。
在GAN中,生成器和鉴别器被设计成相互冲突; 生成器学习样本数据的分布以生成假数据,鉴别器用于确定其输入是由生成器生成的地面真实数据还是假数据。 通过这种对抗性过程,GANS在特征提取和学习方面取得了出色的性能。 GANS广泛应用于图像处理、信号处理、自然语言处理、生物信息处理等领域。
2、输入特征:
将one-hot形式的蛋白质序列与相应的PSSM连接作为输入特征
每个氨基酸转换成大小为1×21(21:20个氨基酸和一个用X表示的未知氨基酸)的OneHot形式,其中只有两个元素,值为0或1,值1的位置对应氨基酸的类别。 其余的元素设置为0。 这样,含有N个氨基酸的蛋白质就会转化成大小为N×21的载体。

如何获得PSSM:
(1)找到数据库中所有与给定序列相似的序列;
(2)构建每个氨基酸的位置频率矩阵;
(3)构建每个氨基酸的位置概率矩阵;
(4)得到最终的PSSM

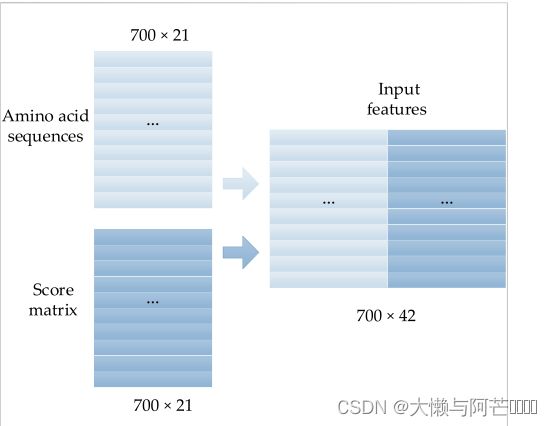
在本研究中,PSSM的大小为N×21,并使用S形函数![]() 将评分矩阵归一化到[0,1]范围内。 由于大多数蛋白质序列长度小于700,残基序列的one-hot编码和PSSM的大小一般统一为700×21。 即长度大于700的序列将被分成两个重叠的序列,而长度小于700的序列则通过填零来增加。 因此,预测模型的输入特征是大小为700×42的矩阵,如图2所示。 在构建的矩阵中,第1~21列为残基序列的一热编码形式,每行第22~42列为对应氨基酸的PSSM。
将评分矩阵归一化到[0,1]范围内。 由于大多数蛋白质序列长度小于700,残基序列的one-hot编码和PSSM的大小一般统一为700×21。 即长度大于700的序列将被分成两个重叠的序列,而长度小于700的序列则通过填零来增加。 因此,预测模型的输入特征是大小为700×42的矩阵,如图2所示。 在构建的矩阵中,第1~21列为残基序列的一热编码形式,每行第22~42列为对应氨基酸的PSSM。
3、CGANs(Conditional GANs条件生成对抗网络)
GAN通常由一个生成器和一个鉴别器组成,这可以提高生成器在对抗学习中的性能。
CGAN的主要思想是在产生器和鉴别器中加入相关的条件信息,使模型能够有条件地产生特定的信号。
CGAN的总体结构图如下:

在CGAN中,期望生成器能产生无限接近真实信号的假信号; 并期望该鉴别器能在给定的条件下准确区分信号的真假。
4、CGAN-PSSP模型
(1)CGAN-PSSP模型综述
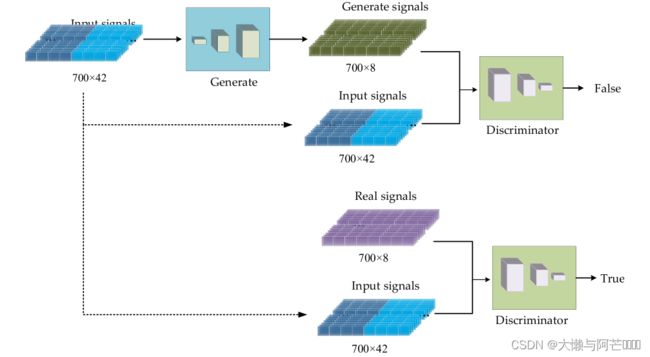
提出的CGAN-PSSP具有一个发生器和一个鉴别器。 在该模型中,生成器的输入是由氨基酸编码特征和PSSM组成的700×42向量,输出是预测蛋白质二级结构的700×8(八态)或700×3(三态)向量。 因此,生成器是蛋白质二级结构预测背后的预测器。 鉴别器的输入是生成器的二级结构和输入特性的组合,输出是鉴别结果。 当二级结构为真时,判别结果应为真; 否则,生成器的生成结果应确定为false。 对于生成器,我们期望二级结构尽可能逼真; 对于鉴别器,期望始终确定生成器生成的二级结构为假。 最终,我们希望在比赛中达到平衡。 因为CGAN-PSSP的目的是构造一个强大的生成器,所以生成器的结构应该稍微复杂一点,以生成一个足够真实的“假二级结构”。CGAN-PSSP模型的主要流程如下图所示:
(2)生成器
在CGAN-PSSP中,生成器的关键功能是根据蛋白质序列的输入特征生成二级结构的假序列。 CGAN-PSSP的生成器结合了一维卷积,以及我们提出的多尺度卷积来捕捉蛋白质的复杂特征。 将蛋白质序列的one-hot形式和PSSM相结合作为生成器的输入特征。 采用三个连续的多尺度卷积进行特征提取,将700×42的输入特征上采样到700×2048。 为了防止原始特征的丢失,将大小为700×42的输入特征连接到多尺度卷积模块的输出,然后生成大小为700×2090的特征映射。 随后,使用一维卷积模块将700×2090特征映射子采样为700×8或700×3特征映射,该特征映射对应于二级结构预测的八种状态和三种状态。 生成器的结构如下图所示,超参数如表1所示。

多尺度卷积模块:
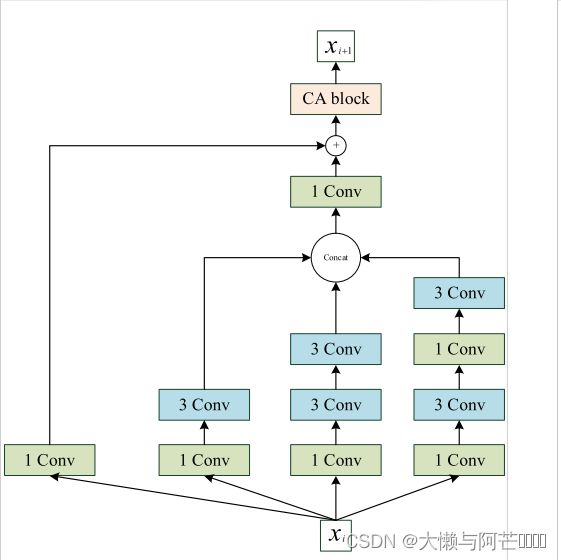
我们在PSSP中引入了一个改进的多尺度卷积(MSC)模块来提取蛋白质序列的特征。卷积:也就是内积,相乘之后再相加。MSC模块由卷积核大小为1(1 Conv)的一维卷积运算和卷积核大小为3(3×3Conv)的一维卷积运算组成。Mish函数被用作非线性激活器。此外,在MSC模块中使用ICA模块来获得每个信道的重要性。在提出的MSC模块中, 代表i层的输入,
代表i层的输入,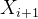 代表i层的输出,ICA块代表ICA模块。
代表i层的输出,ICA块代表ICA模块。
“ICA:独立成分分析最早应用于盲源信号分离。起源于“鸡尾酒会问题”,描述如下:在嘈杂的鸡尾酒会上,许多人在同时交谈,可能还有背景音乐,但人耳却能准确而清晰的听到对方的话语。这种可以从混合声音中选择自己感兴趣的声音而忽略其他声音的现象称为“鸡尾酒会效应”。对于盲源分离问题,ICA是指在只知道混合信号,而不知道源信号、噪声以及混合机制的情况下,分离或近似的分离出源信号的一种分析过程。ICA是一种用来从多变量(多维)统计数据里找到隐含的因素或成分的方法,被认为是PCA和FA的一种扩展。
ICA理论的目标是在只有观察数据的情况下,求得一个分离矩阵W(又称解混矩阵),随后利用分离矩阵W来分离观察数据X,使得获得成分Y是独立源成分S的最优逼近。”
改进通道注意力模块:
ICA机制的主要功能是使模型能够自动理解特征图中各个功能通道的重要性,以提高模型的表达能力和函数拟合能力。 挤压与激励(SE)网络(是由SE操作组成的经典ICA机制网络。 SE将为信道的每个特征映射产生一个权重,以指示信道和关键信息之间的相关性。
在原始SE网中包含的参数的数目太小,不能准确地表示每个通道在PSSP中的重要性。因此,我们通过在挤压操作中添加两个卷积操作来增加参数的数量,从而改进了原始SE网。因此,我们对原有的SE网络进行了改进,在压缩运算的基础上增加了两个卷积运算,以增加参数的数量。 这使得我们能够提高ICA机制表达PSSP中每个通道重要性的能力。
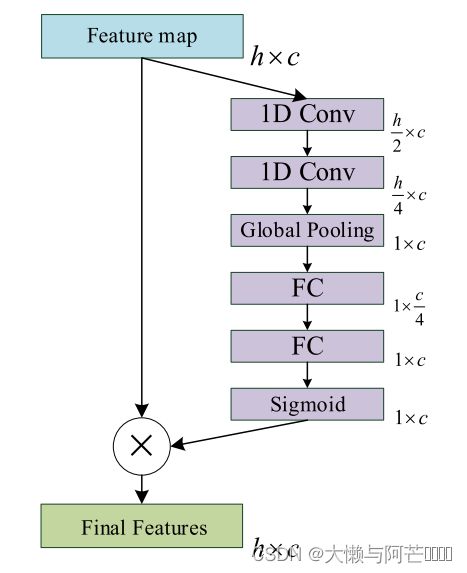
ICA模块如上图所示,其中1D CONV表示卷积内核大小为3的一维卷积操作,Global Pooling表示全局平均池(池化层:用来降低特征图的维度,这里用平均池化,取每个特征图的平均值)操作,而FC表示全连接操作。 Sigmoid表示Sigmoid函数,最终特征表示具有通道重要性的特征映射。
卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间,全连接层起到分类器的作用。从池化层1×c到1×c/4,是为了降低维度方便计算,但由于最终的特征图是h×c,因此需要再来一层。sigmoid函数输出范围为(0,1),我们想要将输出视作⼆元分类问题的概率时, sigmoid仍然被⼴泛⽤作输出单元上的激活函数。因为处理的现实世界问题都是非线性的,而卷积是线性运算,所以要添加一个像sigmoid函数一样的非线性函数加入非线性的性质。
一维卷积模块:
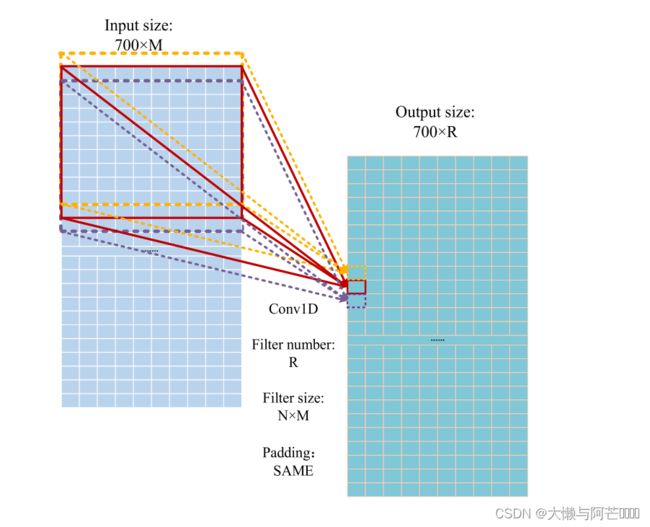
将一维卷积运算(Guo等,2020)作为提取蛋白质特征的基本运算。 模型中一维卷积的运算过程如图所示,其中卷积信号为700×M矩阵,卷积信号的滤波器大小为N×M,因为输出大小取决于卷积信号的个数(R),所以输出信号的大小为700×R。
(3)鉴别器
在CGAN-PSSP模型中,鉴别器的作用是判断二级结构的真伪。 如果生成器生成的二级结构是假的,那么鉴别器的判断应该是假的。 对于真实的二级结构序列,鉴别器的判断应该是真实的。 下图描述了判别式的结构,其输入是二级结构和氨基酸特征矩阵的组合。 因此,用该模型预测三种状态时,输入特征的大小为700×45; 用该模型预测8种状态时,输入特征的大小为700×50。
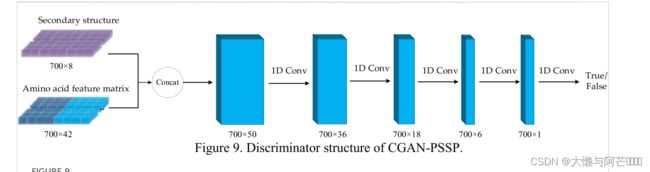
上图以Q8为例。采用四个连续的一维卷积将输入特征采样到大小为700×1的映射中。 最后,利用Sigmoid函数将输出矩阵的所有值转换为[0,1]的概率。 输出矩阵中的每个值表示二级结构序列上相应残差的真假。 在训练过程中,当二级结构为真时,输出的是一个所有值为1的矩阵。 当二级结构为false时,输出是一个值都为0的矩阵。 在测试过程中,如果输出矩阵中的值大于0.5,则判断相应的二级结构为真; 如果该值小于或等于0.5,则判断为假。
(4)损失函数
鉴别器使用均方误差(MSE)函数作为损失函数。 交叉熵是用于分类问题的深度学习中流行的损失函数。 为了防止预测模型随着权重的增加而过度拟合,本文根据二次结构的特点,引入了一种改进的交叉熵函数来提高预测模型的性能,使预测模型在one-hot分布和均匀分布的情况下都能得到满意的性能。 改进后的损失函数公式为
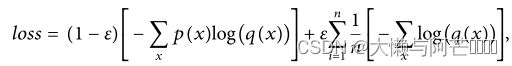
5、MCNN-PSSP模型
(1)模型概述
MCNN-PSSP模型的输入特征是蛋白质编码特征和PSSM的结合。 首先,MSC模块将700×42个输入序列特征扩展到700×256个,以提取原始特征。 为了防止特性丢失,700×42输入特性连接到MSC模块的输出。 然后,分类模块将700×298特征张量卷积为大小为700×8或700×3的输出张量,分别对应蛋白质二级结构的八种或三种状态。 在MSC模块和分类模块中加入ICA模块,使模型能够自动理解不同功能渠道的重要性。
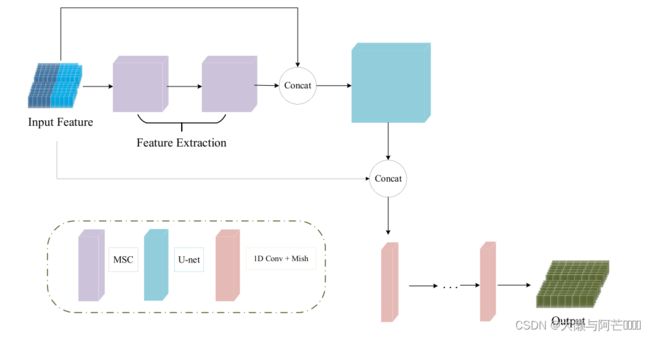
(2)预测模块
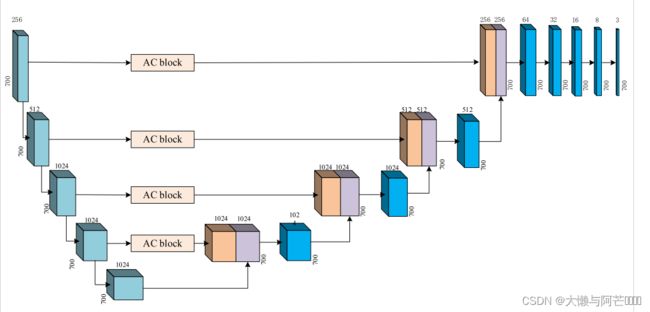
MCNN-PSSP中的分类模块用于分析提取的特征,并进行三个或八个状态的二级结构分类。分类模块的结构如图11所示,它由一个U形网和一个一维卷积组成。U-net由下采样过程和上采样过程组成,它们在结构上是对称的。跳过连接可以增强收缩路径和扩展路径之间的接触。为了更好地分析提取的特征,ICA模块也被集成到U-网。一维卷积模块由一维卷积运算、批量正则化和Mish激活函数组成。它负责将700 × 512的特征图转换为700 × 8或700 × 3的输出,分别对应于二级结构的八个或三个状态。
四、实验与分析
1、评估标准
Q分值用于评估所提出的PSSP模型的性能。 Q分值定义为所有氨基酸残基中被正确预测的残基百分比,其公式可表示为
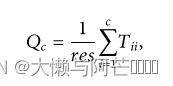
其中c是标记的数目,三个状态对应于Q3,八个状态对应于Q8,res是所有氨基酸序列的数目,并且Tii表示i-状态中氨基酸的正确数目。
2、数据库
CB513、CullPDB、CASP10(123个序列)、CASP11(105个序列)。
对于CullPDB,将其分成三个子集,序列1-4850用于训练,序列4850-5053用于验证,剩余272用于测试,其余三个数据集都用于测试。
3、模型训练
CGAN-PSSP模型是在Nvidia的Titan RTX GPU上训练的。模型结构由Keras(一种高层神经网络API,由纯python编写的基于theano/tensorflow的深度学习框架)实现,Mish(激活函数)和Softmax函数(SoftMax函数:分类器。根据全连接层的输出来得到每个字符对应标签的概率分布,计算所属的类别。)用作模型的激活器。通过MSRA初始化权重,并使用Adam优化算法(优化器选用Adam算法,Adam等自适应学习率算法对于稀疏数据具有优势,且收敛速度很快)自动更新模型的权重和学习率。训练时间设置为750,因为模型的预测精度趋于稳定。下表示出了所提出的方法在CullPDB数据集上的Q8/Q3训练精度和验证精度
MSRA初始化对于网络的训练很重要,好的初始化参数能够加速收敛,并且更可能找到较优解初始化方法:模型权重的。

4、模型测试和比较
CGAN-PSSP模型在四个测试集上的Q3和Q8精度表明,CGAN-PSSP模型与其他模型的精度相比不具竞争力,而MCNN-PSSP模型在Q8和Q3精度方面比其他方法更具竞争力。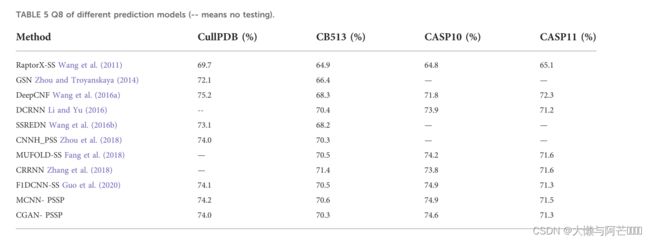
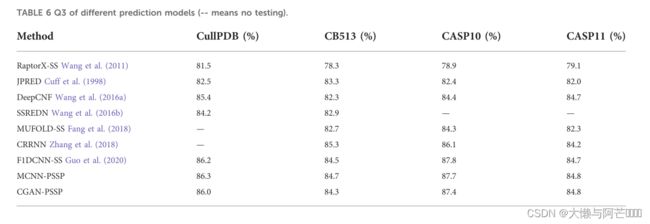
CGAN-SS的预测模型与目前基于深度学习的方法不同,它是一种对抗性学习模型。在我们的方法中,生成器和鉴别器被设计成彼此冲突。生成器学习样本数据的分布以生成假数据,并且鉴别器用于确定其输入是由生成器产生的地面真实数据还是假数据。因此,基于GAN的方法可以减少PSSP中训练数据集的依赖性。然而,其他基于深度学习的方法的性能依赖于训练数据集,这些数据集难以获得并且数量有限。
五、结论
本文在CGAN的基础上提出了一种新的PSSP模型CGAN-PSSP,该模型可用于预测八态和三态蛋白质二级结构。在该模型中,利用PSSM和蛋白质序列的输入,利用生成器预测蛋白质的二级结构,并设计了一个判别器与生成器冲突。 因此,生成器可以学习蛋白质序列的复杂特征,从而预测蛋白质的二级结构。此外,我们引入了一种新的多尺度卷积,它具有一个改进的ICA模块。该研究表明GAN可以用于PSSP,生成对抗学习在蛋白质结构预测方面具有很大的潜力。 此外,我们将U-Net与所提出的MSC和ICA模块相结合,提出了一种PSSP方法。 然而,可以在几个方面进行改进,如损失函数和模型结构。 实验结果表明,与其他传统模型相比,本文提出的方法取得了满意的性能,多尺度卷积模型和独立分量分析模型是有效的。
GAN在特征提取方面具有突出的能力,