第二十三周:深度学习基础和pytorch学习
第二十三周:深度学习和pytorch学习
- 摘要
- Abstract
- 1. TensorBoard的使用
- 2. transforms的使用
-
- 2.1 ToTensor的使用
- 2.2 Normalization的使用
- 3. torchvision中数据集的使用
- 4. DataLoader的使用
- 5. 一维到三维推广
- 总结
摘要
TensorBoard是TensorFlow开发团队提供的一个可视化工具,用于帮助开发人员理解和调试TensorFlow计算图模型。TensorBoard可以显示训练过程中的实时图像,可视化网络模型结构、参数分布、训练和测试指标等。本文将介绍如何使用TensorBoard,以及对于数据集的基本处理,Dataset、DataLoader的使用。
Abstract
TensorBoard is a visualization tool provided by the TensorFlow development team to help developers understand and debug the TensorFlow computational graph model.TensorBoard can display real-time images of the training process, visualize the network model structure, parameter distributions, training and testing metrics and so on. This article will introduce how to use TensorBoard, as well as for the basic processing of datasets, Dataset, DataLoader use.
1. TensorBoard的使用
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter('logs')
image_path = "../dataset/hymenoptera_data/train/bees/16838648_415acd9e3f.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
print(img_array.shape)
writer.add_image("test", img_array, 2, dataformats='HWC')
for i in range(100):
writer.add_scalar("y=x", i, i )
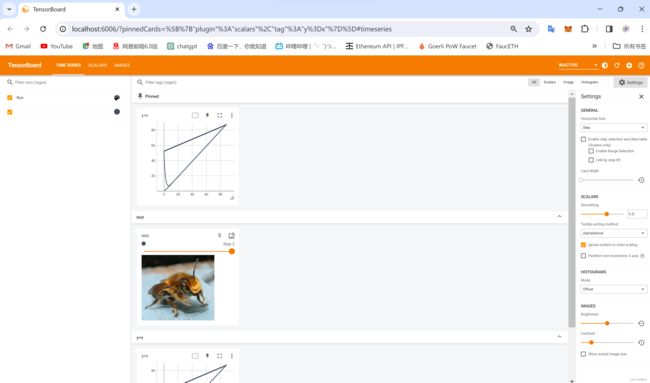
2. transforms的使用
from torchvision import transforms
from PIL import Image
# python的用法 -》Tensor数据类型
# 通过 transforms.ToTensor去看两个问题
# 2. Tensor数据类型
img_path = "../dataset/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(img_path)
# 1. transforms该如何使用
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(tensor_img)


2.1 ToTensor的使用
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
writer = SummaryWriter("logs")
img = Image.open("dataset/hymenoptera_data/train/ants/0013035.jpg")
print(img)
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
print(img_tensor)

2.2 Normalization的使用
将一列数据变化到某个固定区间(范围)中,通常,这个区间是[0, 1] 或者(-1,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。

从公式看: 归一化输出范围在0-1之间
该方法实现对原始数据的等比例缩放。通过利用变量取值的最大值和最小值(或者最大值)将原始数据转换为界于某一特定范围的数据,从而消除量纲和数量级影响,改变变量在分析中的权重来解决不同度量的问题。由于极值化方法在对变量无量纲化过程中仅仅与该变量的最大值和最小值这两个极端值有关,而与其他取值无关,这使得该方法在改变各变量权重时过分依赖两个极端取值。
print(img_tensor[0][0][0])
print(img_tensor)
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
# output[channel] = (input[channel] - mean[channel]) / std[channel]
img_norm = trans_norm(img_tensor)
print(img_norm)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
writer.close()


3. torchvision中数据集的使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True,transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False,transform=dataset_transform, download=True)
writer = SummaryWriter("p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()

4. DataLoader的使用
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
test_loader = DataLoader(test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
# test_loader中每个batch_size有4张图片,4个target值,
# batch_size示例
# torch.Size([4, 3, 32, 32]) --> imgs
# tensor([3, 4, 0, 8]) --> targets
# 利用tensorboard将图片展示出来
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("test_data_drop_last", imgs, step)
step += 1
writer.close()


5. 一维到三维推广
我们之前学习了许多关于卷积神经网络(ConvNets)的知识,从卷积神经网络框架,到如何使用它进行图像识别、对象检测、人脸识别与神经网络转换。即使我们大部分讨论的图像数据,某种意义上而言都是2D数据,考虑到图像如此普遍,许多你所掌握的思想不仅局限于2D图像,甚至可以延伸至1D,乃至3D数据。

让我们回头看看在之前学习关于2D卷积,你可能会输入一个14×14的图像,并使用一个5×5的过滤器进行卷积,接下来你看到了14×14图像是如何与5×5的过滤器进行卷积的,通过这个操作你会得到10×10的输出。

如果你使用了多通道,比如14×14×3,那么相匹配的过滤器可能是5×5×3,如果你使用了多重过滤,比如16,最终你得到的是10×10×16。

事实证明早期想法也同样可以用于1维数据,举个例子,左边是一个EKG信号,或者说是心电图,当你在你的胸部放置一个电极,电极透过胸部测量心跳带来的微弱电流,正因为心脏跳动,产生的微弱电波能被一组电极测量,这就是人心跳产生的EKG,每一个峰值都对应着一次心跳。
如果你想使用EKG信号,比如医学诊断,那么你将处理1维数据,因为EKG数据是由时间序列对应的每个瞬间的电压组成,这次不是一个14×14的尺寸输入,你可能只有一个14尺寸输入,在这种情况下你可能需要使用一个1维过滤进行卷积,你只需要一个1×5的过滤器,而不是一个5×5的。

二维数据的卷积是将同一个5×5特征检测器应用于图像中不同的位置(编号1所示),你最后会得到10×10的输出结果。1维过滤器可以取代你的5维过滤器(编号2所示),可在不同的位置中应用类似的方法(编号3,4,5所示)。

当你对这个1维信号使用卷积,你将发现一个14维的数据与5维数据进行卷积,并产生一个10维输出。

再一次如果你使用多通道,在这种场景下可能会获得一个14×1的通道。如果你使用一个EKG,就是5×1的,如果你有16个过滤器,可能你最后会获得一个10×16的数据,这可能会是你卷积网络中的某一层。
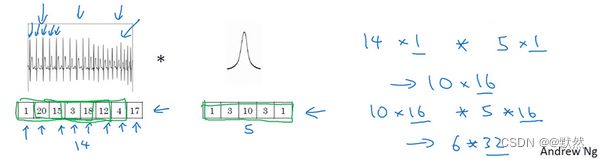
对于卷积网络的下一层,如果输入一个10×16数据,你也可以使用一个5维过滤器进行卷积,这需要16个通道进行匹配,如果你有32个过滤器,另一层的输出结果就是6×32,如果你使用了32个过滤器的话。
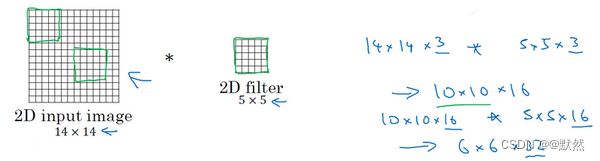
对于2D数据而言,当你处理10×10×16的数据时也是类似的,你可以使用5×5×16进行卷积,其中两个通道数16要相匹配,你将得到一个6×6的输出,如果你用的是32过滤器,输出结果就是6×6×32,这也是32的来源。
所有这些方法也可以应用于1维数据,你可以在不同的位置使用相同的特征检测器,比如说,为了区分EKG信号中的心跳的差异,你可以在不同的时间轴位置使用同样的特征来检测心跳。
所以卷积网络同样可以被用于1D数据,对于许多1维数据应用,你实际上会使用递归神经网络进行处理,这个网络你会在下一个课程中学到,但是有些人依旧愿意尝试使用卷积网络解决这些问题。
下一门课将讨论序列模型,包括递归神经网络、LCM与其他类似模型。我们将探讨使用1D卷积网络的优缺点,对比于其它专门为序列数据而精心设计的模型。
这也是2D向1D的进化,对于3D数据来说如何呢?什么是3D数据?与1D数列或数字矩阵不同,你现在有了一个3D块,一个3D输入数据。以你做CT扫描为例,这是一种使用X光照射,然后输出身体的3D模型,CT扫描实现的是它可以获取你身体不同片段(图片信息)。
当你进行CT扫描时,与我现在做的事情一样,你可以看到人体躯干的不同切片(整理者注:图中所示为人体躯干中不同层的切片,附CT扫描示意图,图片源于互联网),本质上这个数据是3维的。

一种对这份数据的理解方式是,假设你的数据现在具备一定长度、宽度与高度,其中每一个切片都与躯干的切片对应。
如果你想要在3D扫描或CT扫描中应用卷积网络进行特征识别,你也可以从第一张幻灯片(Convolutions in 2D and 1D)里得到想法,并将其应用到3D卷积中。为了简单起见,如果你有一个3D对象,比如说是14×14×14,这也是输入CT扫描的宽度与深度(后两个14)。再次提醒,正如图像不是必须以矩形呈现,3D对象也不是一定是一个完美立方体,所以长和宽可以不一样,同样CT扫描结果的长宽高也可以是不一致的。为了简化讨论,我仅使用14×14×14为例。

如果你现在使用5×5×5过滤器进行卷积,你的过滤器现在也是3D的,这将会给你一个10×10×10的结果输出,技术上来说你也可以再×1(编号1所示),如果这有一个1的通道。这仅仅是一个3D模块,但是你的数据可以有不同数目的通道,那种情况下也是乘1(编号2所示),因为通道的数目必须与过滤器匹配。如果你使用16过滤器处理5×5×5×1,接下来的输出将是10×10×10×16,这将成为你3D数据卷积网络上的一层。

如果下一层卷积使用5×5×5×16维度的过滤器再次卷积,通道数目也与往常一样匹配,如果你有32个过滤器,操作也与之前相同,最终你得到一个6×6×6×32的输出。
某种程度上3D数据也可以使用3D卷积网络学习,这些过滤器实现的功能正是通过你的3D数据进行特征检测。CT医疗扫描是3D数据的一个实例,另一个数据处理的例子是你可以将电影中随时间变化的不同视频切片看作是3D数据,你可以将这个技术用于检测动作及人物行为。
总结
这周收获还是挺大的,在学习pytorch、TensorBoard的过程中,我又了解了数据从一维到三维的推广,下周在学习pytorch之余,我会详细的阅读文献,并做好文献阅读笔记。加油!