庙算兵棋推演AI开发初探(2-编写策略(上))
开始研读step()函数的编写方法。
这个是图灵网提供了一些基础的ai代码下载(浏览需要注册,下载需要审批)。
AI开发中心-人机对抗智能 (ia.ac.cn) http://turingai.ia.ac.cn/ai_center/show
http://turingai.ia.ac.cn/ai_center/show
一、代码研读(BaseAgent类)
1.step函数
这段代码定义了一个 step 方法,用于根据当前的游戏状态生成行动,并返回一个包含所有行动的列表。
这是社区开发版的step函数代码,还是在注释中写解读。
step函数是RL(强化学习)环境中的一个基本方法,用于在环境中执行一个步骤,并返回相应的观察、奖励和是否结束的布尔值。在这个函数中,self表示当前环境对象,observation是一个字典,包含了当前环境的观察状态。函数的目的是根据当前的观察状态,生成一个动作,然后将这个动作应用到环境中,得到一个新的观察状态、奖励和是否结束。最后,函数返回这些值。
函数step,主要是部署阶段管部署,其他阶段找活着的、属于自己的、能使用的行动来执行
def step(self, observation: dict):
# 暂存一些信息
#通信相关信息,communication里面找200,201的type的指令?
#初始化返回值
total_actions = []
# observation.time.stage==1-部署阶段
# 特殊处理,将"sub_type"是人员2 / 无人战车4 /发射指令
if observation["time"]["stage"] == 1:
actions = []
for item in observation["operators"]:
if item["obj_id"] in self.controllable_ops:
operator = item
if operator["sub_type"] == 2 or operator["sub_type"] == 4:
actions.append(
{
"actor": self.seat,
"obj_id": operator["obj_id"],
"type": 303,
"target_obj_id": operator["launcher"],
}
)
actions.append({
"actor": self.seat,
"type": 333
})
return actions
#这里不再是部署阶段了
#这行代码的目的是遍历 observation["valid_actions"] 字典中的每个键值对,
#并将键(obj_id)和值(valid_actions)分别赋值给变量 obj_id 和 valid_actions。
#找活着的算子
for obj_id, valid_actions in observation["valid_actions"].items():
#找属于自己的算子
if obj_id not in self.controllable_ops:
continue
#找到能用的行动类型
for (
action_type
) in self.priority: # 'dict' is order-preserving since Python 3.6
if action_type not in valid_actions:
continue
#====找到基于类型的动作生成方法!要改的就是这里的函数====
gen_action = self.priority[action_type]
action = gen_action(obj_id, valid_actions[action_type])
if action:
total_actions.append(action)
break # one action per bop at a time
return total_actions1)python语言知识
相对于C的结构体,这里的引用方式大概是这样的:
if observation["time"]["stage"] == 1:转换为C语言的写法
if (observation.time.stage == 1)代码里大量的使用字典代替结构体定义,这个看懂了会很有用。
1-字典
observation: dict
声明observation是一个字典
使用方括号
[]来获取值,例如my_dict['key']。
2-列表
total_actions.append(action)
看起来代码这里一般用来当作队列使用
3-元组
代码里几乎没有用到
2)传入的参数
1-态势( observation)定义
它接受一个字典类型的参数 observation,表示当前的游戏状态、环境信息或玩家信息等。
以下是态势( observation)最外层的数据结构以及他们代表的含义。
obs = {
"actions": list, # 上一步接收到的动作
"cities": [], # 各个夺控点的信息
"communication": [], # 通信相关信息
"jm_points": [], # 间瞄点信息
"judge_info": [], # 裁决信息
"landmarks": {}, # 地标信息,雷场,路障
"operators": [], # 算子信息
"passengers": [], # 乘员信息
"role_and_grouping_info": {}, # 玩家信息和编组信息
"scenario_id": 0, # 想定ID
"scores": {}, # 分数
"terrain_id": 0, # 地图id
"time": {}, # 时间信息
"valid_actions": {} # 当前态势下的可做动作信息
}再下一层的定义在链接的4.1.1开始有说明
《庙算 陆战指挥官》兵棋推演平台AI开发指南 (yuque.com)
2-态势说明
将 observation 赋值给 self.observation,以便在后续步骤中使用。
State一般代表环境当前的所有状态。Observation一般情况下代表对于某个智能体可观测的态势。Observation是State的子集。
TrainEnv的step函数返回的state,表示当前环境的所有状态合集。状态合集有红方蓝方绿方态势组成:state[0]代表的是红方态势,state[1]代表的是蓝方态势,state[-1]代表的是绿方态势。
AI代码的step函数接受的参数是就是态势observation,它封装了当前时间,此AI能观测到的所有盘面信息,包括算子信息、裁决信息等。以下是态势最外层的数据结构以及他们代表的含义。
2.与其他基准ai比对
我在上方的图灵网上下载了几个基准AI,对其与默认版进行比较。
用TortiseGit进行代码比对,发现这个基准AI对step函数作了相当多的修改。
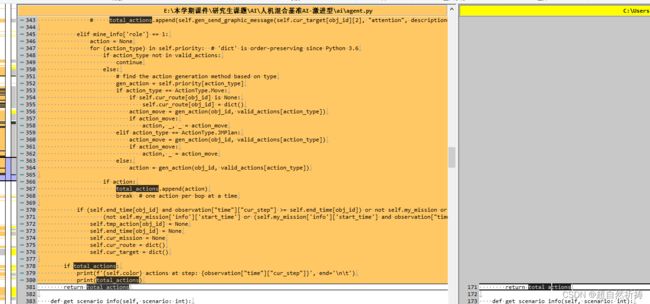
要怎么改呢……