NLP:预测新闻类别 - 自然语言处理中嵌入技术
简介
在数字时代,在线新闻内容呈指数级增长,需要有效的分类以增强可访问性和用户体验。先进机器学习技术的出现,特别是在自然语言处理(NLP)领域,为文本数据的自动分类开辟了新的领域。本文[1]探讨了在 NLP 中使用嵌入技术来预测新闻类别,这是管理不断增长的海量新闻文章的一项关键任务。
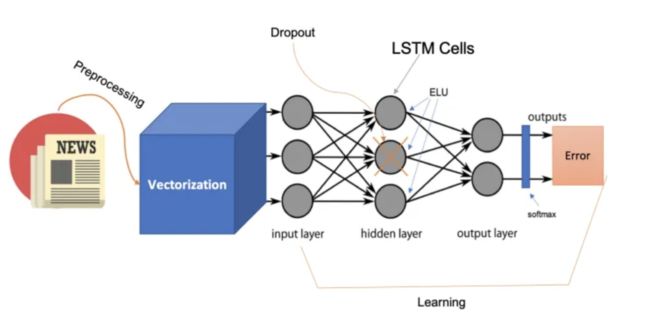
机器学习和 NLP 在文本分类中的作用
机器学习是人工智能的一个子集,它极大地影响了我们处理和分析大型数据集(包括文本数据)的方式。 NLP 是机器学习的一个专门领域,专注于计算机和人类语言之间的交互。它涉及以对计算机有意义且有用的方式理解、解释和操作人类语言。新闻内容分类是 NLP 的主要应用,其目标是将新闻文章自动分类为预定义的类别,例如政治、体育、娱乐等。
自然语言处理中的嵌入
NLP 的核心是嵌入,它是表示文本数据的复杂技术。嵌入将单词、句子或整个文档转换为数值向量。这种转变至关重要,因为擅长处理数字数据的机器学习算法却难以处理原始文本。嵌入不仅捕获单词的存在,还捕获单词之间的上下文和语义关系。
词嵌入
词嵌入(例如 Word2Vec 和 GloVe)将单个单词转换为向量空间。这些嵌入捕获语义含义,允许具有相似含义的单词具有相似的表示。例如,在政治新闻文章中,“选举”和“投票”等词将紧密地放置在向量空间中。
句子和文档嵌入
虽然单词嵌入处理单个单词,但句子和文档嵌入(例如 BERT、Doc2Vec)代表更大的文本块。这些对于新闻分类至关重要,因为它们捕获整篇文章的上下文,这对于准确分类至关重要。
应用嵌入进行新闻分类
- 问题定义:新闻分类的主要挑战是根据文章内容将文章准确分类为特定类别。由于新闻写作中存在不同的风格、背景和潜台词,这项任务变得复杂。
- 数据预处理:预处理涉及清理和准备新闻数据以供分析。这包括对文本进行标记(将其分解为单词或句子),然后使用嵌入技术将这些标记转换为向量。
- 模型训练:将矢量化文本数据输入到机器学习模型中进行训练。这些模型学习将嵌入中的特定模式与特定的新闻类别相关联。例如,模型可能会学习将与运动相关术语相对应的向量与“运动”类别相关联。
挑战和考虑因素
在这种背景下出现了一些挑战。新闻文章可能包含讽刺、地方口语或复杂的隐喻,所有这些对于模型来说都很难正确解释。此外,语言和新闻主题不断变化的性质需要不断地重新训练和更新这些模型。
一些组织和新闻机构已成功实施基于嵌入的分类系统,证明了其有效性。对不同嵌入技术的比较分析可以揭示它们各自的优势以及对各种新闻类型的适用性。
在新闻分类中嵌入技术的未来看起来很有希望。基于 Transformer 的模型(例如 GPT 和 BERT)的进步提供了处理语言细微差别的复杂方法。与其他人工智能技术(例如预测分析和多媒体分析)的集成可以进一步增强分类过程。
Code
使用嵌入技术创建用于预测新闻类别的完整 Python 代码涉及几个步骤,包括生成合成数据集、预处理文本数据、训练模型和可视化结果。以下是该过程的概述,然后是实际代码:
大纲
- 生成综合数据集:我们将创建一个简单的新闻标题综合数据集,分为几种类型。
- 预处理:对文本进行标记并将其转换为嵌入。
- 模型训练:使用机器学习模型从这些嵌入中学习。
- 评估和可视化:评估模型性能并可视化结果。
依赖
您需要安装以下库:
- numpy 用于数值运算。
- pandas 用于数据处理。
- sklearn 用于机器学习功能。
- matplotlib 和 seaborn 用于绘图。
import pandas as pd
import numpy as np
# Sample categories
categories = ['Politics', 'Sports', 'Technology', 'Entertainment']
# Generate synthetic headlines
np.random.seed(0)
data = {'headline': [f"headline {i}" for i in range(1, 101)],
'category': [np.random.choice(categories) for _ in range(100)]}
df = pd.DataFrame(data)
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df['headline']).toarray()
y = df['category']
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
# Splitting the dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Model Training
model = LogisticRegression()
model.fit(X_train, y_train)
# Predictions
y_pred = model.predict(X_test)
# Classification report
print(classification_report(y_test, y_pred))
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt="d")
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
执行和可视化
在Python环境中运行上述代码。最终输出将包括指示模型性能的分类报告和代表混淆矩阵的热图。
局限和改进
- 合成数据:现实世界的数据更加复杂和多样。考虑使用实际的新闻数据集来获得更有意义的见解。
- 嵌入技术:词袋是一种基本方法。 Word2Vec、GloVe 或 BERT 等先进技术提供了更细致的文本表示。
- 模型复杂性:逻辑回归是一个基本模型。尝试使用更复杂的模型(例如随机森林、梯度提升或神经网络)以获得更好的性能。
- 评估指标:除了准确性之外,还可以考虑其他指标,例如 F1 分数、精确率和召回率来进行综合评估。
precision recall f1-score support
Entertainment 0.20 1.00 0.33 4
Politics 0.00 0.00 0.00 6
Sports 0.00 0.00 0.00 8
Technology 0.00 0.00 0.00 2
accuracy 0.20 20
macro avg 0.05 0.25 0.08 20
weighted avg 0.04 0.20 0.07 20
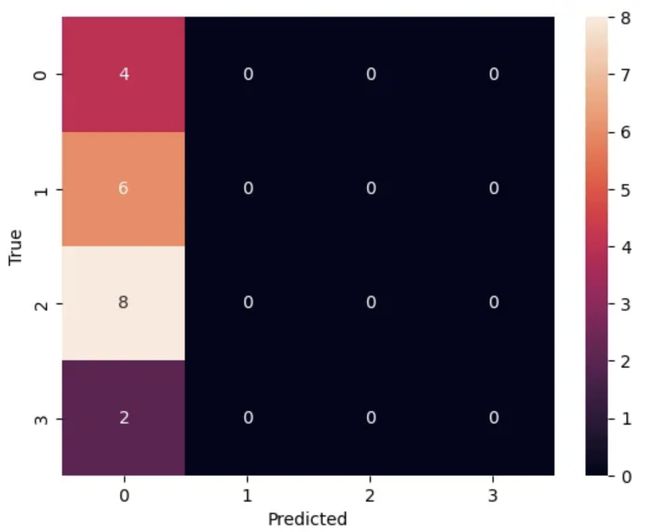
请记住,这是一个简化的示例。现实世界的应用程序需要更强大的数据处理、复杂的嵌入技术和先进的建模方法。
总结
NLP 中的嵌入技术代表了自动化新闻分类领域的重大进步。它们提供了细致入微且上下文感知的方法来处理人类语言的复杂性。随着技术的发展,这些技术将变得更加完善,从而带来更加准确和高效的新闻分类系统。这一进步不仅有利于新闻机构管理其内容,而且还增强了最终用户在浩瀚的数字新闻海洋中航行的体验。
Reference
[1]Source: https://medium.com/aimonks/predicting-news-category-using-embedding-techniques-in-natural-language-processing-01585dcc3620
本文由 mdnice 多平台发布