Spark 之 Shuffle
Shuffle
在Spark中Shuffle的目的是为了保证每一个key所对应的value都会汇聚到同一个分区上去聚合和处理。
exchange
如果某个sql会发生shuffle,那么它的执行计划中一定会出现Exchange(实际ShuffleExchangeExec)节点。
BroadcastExchangeExec(广播)、ShuffleExchangeExec(shuffle)
机制
- 所谓shuffle就是把不同节点上的数据按相同key值拉取到一个节点上。
- shuffle发生在map 和reduce之间(也可以说是两个stage之间),分为shuffleWrite
和shuffleRead两个过程
具体过程
- 前一个stage进行shuffle write 把数据存在blockManage;
- 下一个stage 进行shuffle read 拉取上个stage 的数据。
只有 SortMergeJoinExec 和 ShuffledHashJoinExec 这两种类型的join实现会发生shuffle
hash shuffle vs hash join
shuffle是一种数据分发的方式,它的实现代表的是两个stage之间的数据按照什么方式移动;而join是发生在某个stage中,hash join是指把小表构建成hash表,和基表进关联的操作。
hash shuffle被弃用了,hash join在ShuffledHashJoinExec 和 BroadcastHashJoinExec这两种join的实现中还在使用。
ShuffleManager
ShuffleManager是Spark系统中可插拔的Shuffle系统接口,ShuffleManager会在Driver或Executor的SparkEnv被创建时一并创建,可以通过spark.shuffle.manage配置指定具体的实现类。目前唯一实现类org.apache.spark.shuffle.sort.SortShuffleManager
Spark 中的 Shuffle 操作的特点
- 只有 Key-Value 型的 RDD 才会有 Shuffle 操作, 例如 RDD[(K, V)], 但是有一个特例, 就是repartition 算子可以对任何数据类型 Shuffle
- 早期版本 Spark 的 Shuffle 算法是 Hash base shuffle, 后来改为 Sort base shuffle,更适合大吞吐量的场景
Concept
shuffle作为处理连接map端和reduce端的枢纽,其shuffle的性能高低直接影响了整个程序的性能和吞吐量。map端的shuffle一般为shuffle的Write阶段,reduce端的shuffle一般为shuffle的read阶段。Hadoop和spark的shuffle在实现上面存在很大的不同,spark的shuffle分为两种实现,分别为HashShuffle和SortShuffle。
The final stage which produces the result is called the ResultStage. All other stages that are required for computing the ResultStage are called ShuffleMapStages.
Once we start evaluating the physical plan, Spark scans backwards through the stages and recursively schedules missing stages which are required to calculate the final result. As every stage needs to provide data to subsequent ones, the result of a ShuffleMapStage is to create an output file. This output file is partitioned by the partitioning function and is used by downstream stages to fetch the required data. Therefore, the shuffle occurs as a implicit process which glues together the subsequent execution of tasks dependent stages
go through the execution of a single ShuffleMapTask on an executor
- Fetch: Each executor will be scheduled a taks by the TaskScheduler. The task contains information about which partition to evaluate. So the executor will access the map output files of previous stages (potentially on other workers) to fetch the outputs for the respective partition. The whole process of fetching the data, i.e. resolving the locations of the map output files, its partitioning, is encapsulated in each executors block store.
- Compute: The executor calculates the map output result for the partition by applying the pipelined functions subsequently. Note that this still holds true for plans generated by SparkSQL’s WholeStageCodeGen because it simply produces one RDD (in the logical plan) consisting of one function for all merged functions during the optimization phase. Meaning that from an RDD point of view there is only one MappedRDD initially.
- Write: The ultimate goal of a task is to produce a partitioned file on disk and registers it with the BlockManager to provide it to subsequent stages. The output file needs to be partitined in order to enable subsequent stages to fetch only the data required for their tasks. Generally, the output files are also sorted by key within each partition. This is required as the subsequent task will fetch the records and applies the function iteratively. Therefore, same keys should occure consecutively.
HashShuffle
HashShuffle (2.0 后 已经完全删除) 又分为普通机制和合并机制,普通机制因为其会产生MR个数的巨量磁盘小文件而产生大量性能低下的Io操作,从而性能较低,因为其巨量的磁盘小文件还可能导致OOM,HashShuffle的合并机制通过重复利用buffer从而将磁盘小文件的数量降低到CoreR个,但是当Reducer 端的并行任务或者是数据分片过多的时候,依然会产生大量的磁盘小文件。
SortShuffle
SortShuffle也分为普通机制和bypass机制,普通机制在内存数据结构(默认为5M)完成排序,会产生2M个磁盘小文件。而当shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。或者算子不是聚合类的shuffle算子(比如reduceByKey)的时候会触发SortShuffle的bypass机制,SortShuffle的bypass机制不会进行排序,极大的提高了其性能
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager,因为HashShuffleManager会产生大量的磁盘小文件而性能低下,在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。SortShuffleManager相较于HashShuffleManager来说,有了一定的改进。主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
Spark 2.0 以后, HashShuffleManager 完全被删除
普通运行机制的 SortShuffleManager
在该模式下,数据会先写入一个内存数据结构中,此时根据不同的 shuffle 算子,可能选用不同的数据结构。如果是 reduceByKey 这种聚合类的 shuffle 算子,那么会选用 Map 数据结构,一边通过 Map 进行聚合,一边写入内存;如果是 join 这种普通的 shuffle 算子,那么会选用 Array 数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据 key 对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的 batch 数量是 10000 条,也就是说,排序好的数据,会以每批 1 万条数据的形式分批写入磁盘文件。写入磁盘文件是通过 Java 的 BufferedOutputStream 实现的。BufferedOutputStream 是 Java 的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘 IO 次数,提升性能。
一个 task 将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是merge 过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个 task 就只对应一个磁盘文件,也就意味着该 task 为下游 stage 的 task 准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个 task 的数据在文件中的 start offset 与 end offset。
SortShuffleManager 由于有一个磁盘文件 merge 的过程,因此大大减少了文件数量。比如第一个 stage 有 50 个 task,总共有 10 个 Executor,每个 Executor 执行 5 个 task,而第二个 stage 有 100 个 task。由于每个 task 最终只有一个磁盘文件,因此此时每个 Executor 上只有 5 个磁盘文件,所有 Executor 只有 50 个磁盘文件。
工作原理如下图所示:

bypass 运行机制
Reducer 端任务数比较少的情况下,基于 Hash Shuffle 实现机制明显比基于 Sort Shuffle 实现机制要快,因此基于 Sort Shuffle 实现机制提供了一个带 Hash 风格的回退方案,就是 bypass 运行机制。对于 Reducer 端任务数少于配置属性spark.shuffle.sort.bypassMergeThreshold设置的个数时,使用带 Hash 风格的回退计划。
bypass 运行机制的触发条件如下:
shuffle map task 数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。
不是聚合类的 shuffle 算子。
此时,每个 task 会为每个下游 task 都创建一个临时磁盘文件,并将数据按 key 进行 hash 然后根据 key 的 hash 值,将 key 写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的 HashShuffleManager 是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager 来说,shuffle read 的性能会更好。
而该机制与普通 SortShuffleManager 运行机制的不同在于:第一,磁盘写机制不同;第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write 过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
bypass 运行机制的 SortShuffleManager 工作原理如下图所示:

bypass 机制补充说明
虽然bypass 最终还是会生成一个文件for every map task。
但是它的中间过程中,会根据hash key 生成很多个小文件,数量超过sortmanager,
所以会使用 spark.shuffle.sort.bypassMergeThreshold 对该机制进行限制。
Tungsten Sort 运行机制
Tungsten Sort 是对普通 Sort 的一种优化,Tungsten Sort 会进行排序,但排序的不是内容本身,而是内容序列化后字节数组的指针(元数据),把数据的排序转变为了指针数组的排序,实现了直接对序列化后的二进制数据进行排序。由于直接基于二进制数据进行操作,所以在这里面没有序列化和反序列化的过程。内存的消耗大大降低,相应的,会极大的减少的 GC 的开销。
Spark 提供了配置属性,用于选择具体的 Shuffle 实现机制,但需要说明的是,虽然默认情况下 Spark 默认开启的是基于 SortShuffle 实现机制,但实际上,参考 Shuffle 的框架内核部分可知基于 SortShuffle 的实现机制与基于 Tungsten Sort Shuffle 实现机制都是使用 SortShuffleManager,而内部使用的具体的实现机制,是通过提供的两个方法进行判断的:
对应非基于 Tungsten Sort 时,通过 SortShuffleWriter.shouldBypassMergeSort 方法判断是否需要回退到 Hash 风格的 Shuffle 实现机制,当该方法返回的条件不满足时,则通过 SortShuffleManager.canUseSerializedShuffle 方法判断是否需要采用基于 Tungsten Sort Shuffle 实现机制,而当这两个方法返回都为 false,即都不满足对应的条件时,会自动采用普通运行机制。
因此,当设置了 spark.shuffle.manager=tungsten-sort 时,也不能保证就一定采用基于 Tungsten Sort 的 Shuffle 实现机制。
要实现 Tungsten Sort Shuffle 机制需要满足以下条件:
Shuffle 依赖中不带聚合操作或没有对输出进行排序的要求。
Shuffle 的序列化器支持序列化值的重定位(当前仅支持 KryoSerializer Spark SQL 框架自定义的序列化器)。
Shuffle 过程中的输出分区个数少于 16777216 个。
实际上,使用过程中还有其他一些限制,如引入 Page 形式的内存管理模型后,内部单条记录的长度不能超过 128 MB (具体内存模型可以参考 PackedRecordPointer 类)。另外,分区个数的限制也是该内存模型导致的。
所以,目前使用基于 Tungsten Sort Shuffle 实现机制条件还是比较苛刻的。

Shuffle partitions
spark.sql.shuffle.partitions
默认值为 200
spark.sql.shuffle.partitions 200
The default number of partitions to use when shuffling data for joins or aggregations. Note: For structured streaming, this configuration cannot be changed between query restarts from the same checkpoint location.
如果设置过大,会产生 empty partitions
/**
* Min partition number to use [[HighlyCompressedMapStatus]]. A bit ugly here because in test
* code we can't assume SparkEnv.get exists.
*/
private lazy val minPartitionsToUseHighlyCompressMapStatus = Option(SparkEnv.get)
.map(_.conf.get(config.SHUFFLE_MIN_NUM_PARTS_TO_HIGHLY_COMPRESS))
.getOrElse(config.SHUFFLE_MIN_NUM_PARTS_TO_HIGHLY_COMPRESS.defaultValue.get)
/**
* Min partition number to use [[HighlyCompressedMapStatus]]. A bit ugly here because in test
* code we can't assume SparkEnv.get exists.
*/
private lazy val minPartitionsToUseHighlyCompressMapStatus = Option(SparkEnv.get)
.map(_.conf.get(config.SHUFFLE_MIN_NUM_PARTS_TO_HIGHLY_COMPRESS))
.getOrElse(config.SHUFFLE_MIN_NUM_PARTS_TO_HIGHLY_COMPRESS.defaultValue.get)
zipPartitions
zipPartitions函数将多个RDD按照partition组合成为新的RDD,
该函数需要组合的RDD具有相同的分区数,但对于每个分区内的元素数量没有要求。
scala> var rdd1 = sc.makeRDD(1 to 5,2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[22] at makeRDD at :21
scala> var rdd2 = sc.makeRDD(Seq("A","B","C","D","E"),2)
rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[23] at makeRDD at :21
//rdd1两个分区中元素分布:
scala> rdd1.mapPartitionsWithIndex{
| (x,iter) => {
| var result = List[String]()
| while(iter.hasNext){
| result ::= ("part_" + x + "|" + iter.next())
| }
| result.iterator
|
| }
| }.collect
res17: Array[String] = Array(part_0|2, part_0|1, part_1|5, part_1|4, part_1|3)
//rdd2两个分区中元素分布
scala> rdd2.mapPartitionsWithIndex{
| (x,iter) => {
| var result = List[String]()
| while(iter.hasNext){
| result ::= ("part_" + x + "|" + iter.next())
| }
| result.iterator
|
| }
| }.collect
res18: Array[String] = Array(part_0|B, part_0|A, part_1|E, part_1|D, part_1|C)
//rdd1和rdd2做zipPartition
scala> rdd1.zipPartitions(rdd2){
| (rdd1Iter,rdd2Iter) => {
| var result = List[String]()
| while(rdd1Iter.hasNext && rdd2Iter.hasNext) {
| result::=(rdd1Iter.next() + "_" + rdd2Iter.next())
| }
| result.iterator
| }
| }.collect
res19: Array[String] = Array(2_B, 1_A, 5_E, 4_D, 3_C)
Shuffle Hash Join
The shuffled hash join ensures that data on each partition will contain the same keys by partitioning the second dataset with the same default partitioner as the first, so that the keys with the same hash value from both datasets are in the same partition.
It follows the classic map-reduce pattern:
- First it maps through two tables(dataframes)
- Uses the join keys as output key
- Shuffles both dataframes by the output key, So that rows related to
same keys - from both tables will be moved on to same machine.
- In reducer phase, join the two datasets.
Sort merge join
This is Spark’s default join strategy, Since Spark 2.3 the default value of spark.sql.join.preferSortMergeJoin has been changed to true.
Spark performs this join when you are joining two BIG tables, Sort Merge Joins minimize data movements in the cluster, highly scalable approach and performs better when compared to Shuffle Hash Joins.
Performs disk IO operations same like Map Reduce paradigm which makes this join scalable.
Three phases of sort Merge Join –
- Shuffle Phase : The 2 big tables are repartitioned as per the join keys across the partitions in the cluster.
- Sort Phase: Sort the data within each partition parallelly.
- Merge Phase: Join the 2 Sorted and partitioned data. This is basically merging of dataset by iterating over the elements and joining the rows having the same value for the join key.
Source Code
spill
core/src/main/scala/org/apache/spark/util/collection/ExternalSorter.scala
/**
* Spills the current in-memory collection to disk if needed. Attempts to acquire more
* memory before spilling.
*
* @param collection collection to spill to disk
* @param currentMemory estimated size of the collection in bytes
* @return true if `collection` was spilled to disk; false otherwise
*/
protected def maybeSpill(collection: C, currentMemory: Long): Boolean = {
var shouldSpill = false
if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) {
// Claim up to double our current memory from the shuffle memory pool
val amountToRequest = 2 * currentMemory - myMemoryThreshold
val granted = acquireMemory(amountToRequest)
myMemoryThreshold += granted
// If we were granted too little memory to grow further (either tryToAcquire returned 0,
// or we already had more memory than myMemoryThreshold), spill the current collection
shouldSpill = currentMemory >= myMemoryThreshold
}
shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold
// Actually spill
if (shouldSpill) {
_spillCount += 1
logSpillage(currentMemory)
spill(collection)
_elementsRead = 0
_memoryBytesSpilled += currentMemory
releaseMemory()
}
shouldSpill
}
/**
* Spill our in-memory collection to a sorted file that we can merge later.
* We add this file into `spilledFiles` to find it later.
*
* @param collection whichever collection we're using (map or buffer)
*/
override protected[this] def spill(collection: WritablePartitionedPairCollection[K, C]): Unit = {
val inMemoryIterator = collection.destructiveSortedWritablePartitionedIterator(comparator)
val spillFile = spillMemoryIteratorToDisk(inMemoryIterator)
spills += spillFile
}
/**
* Spill contents of in-memory iterator to a temporary file on disk.
*/
private[this] def spillMemoryIteratorToDisk(inMemoryIterator: WritablePartitionedIterator)
: SpilledFile = {
// Because these files may be read during shuffle, their compression must be controlled by
// spark.shuffle.compress instead of spark.shuffle.spill.compress, so we need to use
// createTempShuffleBlock here; see SPARK-3426 for more context.
val (blockId, file) = diskBlockManager.createTempShuffleBlock()
// These variables are reset after each flush
var objectsWritten: Long = 0
val spillMetrics: ShuffleWriteMetrics = new ShuffleWriteMetrics
val writer: DiskBlockObjectWriter =
blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, spillMetrics)
// List of batch sizes (bytes) in the order they are written to disk
val batchSizes = new ArrayBuffer[Long]
// How many elements we have in each partition
val elementsPerPartition = new Array[Long](numPartitions)
// Flush the disk writer's contents to disk, and update relevant variables.
// The writer is committed at the end of this process.
def flush(): Unit = {
val segment = writer.commitAndGet()
batchSizes += segment.length
_diskBytesSpilled += segment.length
objectsWritten = 0
}
var success = false
try {
while (inMemoryIterator.hasNext) {
val partitionId = inMemoryIterator.nextPartition()
require(partitionId >= 0 && partitionId < numPartitions,
s"partition Id: ${partitionId} should be in the range [0, ${numPartitions})")
inMemoryIterator.writeNext(writer)
elementsPerPartition(partitionId) += 1
objectsWritten += 1
if (objectsWritten == serializerBatchSize) {
flush()
}
}
if (objectsWritten > 0) {
flush()
} else {
writer.revertPartialWritesAndClose()
}
success = true
} finally {
if (success) {
writer.close()
} else {
// This code path only happens if an exception was thrown above before we set success;
// close our stuff and let the exception be thrown further
writer.revertPartialWritesAndClose()
if (file.exists()) {
if (!file.delete()) {
logWarning(s"Error deleting ${file}")
}
}
}
}
// 创建并返回 spilledFile
SpilledFile(file, blockId, batchSizes.toArray, elementsPerPartition)
}
/**
* Iterate through the data and write out the elements instead of returning them. Records are
* returned in order of their partition ID and then the given comparator.
* This may destroy the underlying collection.
*/
def destructiveSortedWritablePartitionedIterator(keyComparator: Option[Comparator[K]])
: WritablePartitionedIterator = {
val it = partitionedDestructiveSortedIterator(keyComparator)
new WritablePartitionedIterator {
private[this] var cur = if (it.hasNext) it.next() else null
def writeNext(writer: PairsWriter): Unit = {
writer.write(cur._1._2, cur._2)
cur = if (it.hasNext) it.next() else null
}
def hasNext(): Boolean = cur != null
def nextPartition(): Int = cur._1._1
}
}
DiskBlockObjectWriter
core/src/main/scala/org/apache/spark/storage/DiskBlockObjectWriter.scala
/**
* Writes a key-value pair.
*/
override def write(key: Any, value: Any): Unit = {
if (!streamOpen) {
open()
}
objOut.writeKey(key)
objOut.writeValue(value)
recordWritten()
}
Serializer
core/src/main/scala/org/apache/spark/serializer/Serializer.scala
/** Writes the object representing the key of a key-value pair. */
def writeKey[T: ClassTag](key: T): SerializationStream = writeObject(key)
/** Writes the object representing the value of a key-value pair. */
def writeValue[T: ClassTag](value: T): SerializationStream = writeObject(value)
core/src/main/scala/org/apache/spark/serializer/KryoSerializer.scala
override def writeObject[T: ClassTag](t: T): SerializationStream = {
kryo.writeClassAndObject(output, t)
this
}
DISK_ISSUE
org.apache.spark.network.shuffle.checksum.ShuffleChecksumHelper
/**
* Diagnose the possible cause of the shuffle data corruption by verifying the shuffle checksums.
*
* There're 3 different kinds of checksums for the same shuffle partition:
* - checksum (c1) that is calculated by the shuffle data reader
* - checksum (c2) that is calculated by the shuffle data writer and stored in the checksum file
* - checksum (c3) that is recalculated during diagnosis
*
* And the diagnosis mechanism works like this:
* If c2 != c3, we suspect the corruption is caused by the DISK_ISSUE. Otherwise, if c1 != c3,
* we suspect the corruption is caused by the NETWORK_ISSUE. Otherwise, the cause remains
* CHECKSUM_VERIFY_PASS. In case of the any other failures, the cause remains UNKNOWN_ISSUE.
*
* @param algorithm The checksum algorithm that is used for calculating checksum value
* of partitionData
* @param checksumFile The checksum file that written by the shuffle writer
* @param reduceId The reduceId of the shuffle block
* @param partitionData The partition data of the shuffle block
* @param checksumByReader The checksum value that calculated by the shuffle data reader
* @return The cause of data corruption
*/
public static Cause diagnoseCorruption(
String algorithm,
File checksumFile,
int reduceId,
ManagedBuffer partitionData,
long checksumByReader) {
...
}
AQE
原理可以参考这篇文章
https://www.databricks.com/blog/2020/05/29/adaptive-query-execution-speeding-up-spark-sql-at-runtime.html
https://www.waitingforcode.com/apache-spark-sql/whats-new-apache-spark-3-shuffle-partitions-coalesce/read
自适应执行(Adaptive Query Execution, AQE)是Spark3的重要功能,通过收集运行时Stats,来动态调整后续的执行计划,从而解决由于Optimizer无法准确预估Stats导致生成的执行计划不够好的问题。AQE主要有三个优化场景: Partition合并(Partition Coalescing), Join策略切换(Switch Join Strategy),以及倾斜Join优化(Optimize Skew Join)。
Partition合并
Partition合并的目的是尽量让reducer处理的数据量适中且均匀,做法是首先Mapper按较多的Partition数目进行Shuffle Write,AQE 框架统计每个Partition的Size,若连续多个Partition的数据量都比较小,则将这些Partition合并成一个,交由一个Reducer去处理。


优化后的Reducer2需读取原属于Reducer2-4的数据,对Shuffle框架的需求是ShuffleReader需要支持范围Partition:
def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K, C]
Join策略切换
Join策略切换的目的是修正由于Stats预估不准导致Optimizer把本应做的Broadcast Join错误的选择了SortMerge Join或ShuffleHash Join。具体而言,在Join的两张表做完Shuffle Write之后,AQE框架统计了实际大小,若发现小表符合Broadcast Join的条件,则将小表Broadcast出去,跟大表的本地Shuffle数据做Join.

Join策略切换有两个优化:1. 改写成Broadcast Join; 2. 大表的数据通过LocalShuffleReader直读本地。其中第2点对Shuffle框架提的新需求是支持Local Read。
倾斜Join优化
倾斜Join优化的目的是让倾斜的Partition由更多的Reducer去处理,从而避免长尾。具体而言,在Shuffle Write结束之后,AQE框架统计每个Partition的Size,接着根据特定规则判断是否存在倾斜,若存在,则把该Partition分裂成多个Split,每个Split跟另外一张表的对应Partition做Join。


Partiton分裂的做法是按照MapId的顺序累加他们Shuffle Output的Size,累加值超过阈值时触发分裂。对Shuffle框架的新需求是ShuffleReader要能支持范围MapId。综合Partition合并优化对范围Partition的需求,ShuffleReader的接口演化为:
def getReader[K, C](
handle: ShuffleHandle,
startMapIndex: Int,
endMapIndex: Int,
startPartition: Int,
endPartition: Int,
context: TaskContext,
metrics: ShuffleReadMetricsReporter): ShuffleReader[K, C]
Ali RSS
RSS的核心设计是Push Shuffle + Partition数据聚合,即不同的Mapper把属于同一个Partition的数据推给同一个Worker做聚合,Reducer直读聚合后的文件。

在核心设计之外,RSS还实现了多副本,全链路容错,Master HA,磁盘容错,自适应Pusher,滚动升级等特性。
支持Partition合并
Partition合并对Shuffle框架的需求是支持范围Partition,在RSS中每个Partition对应着一个文件
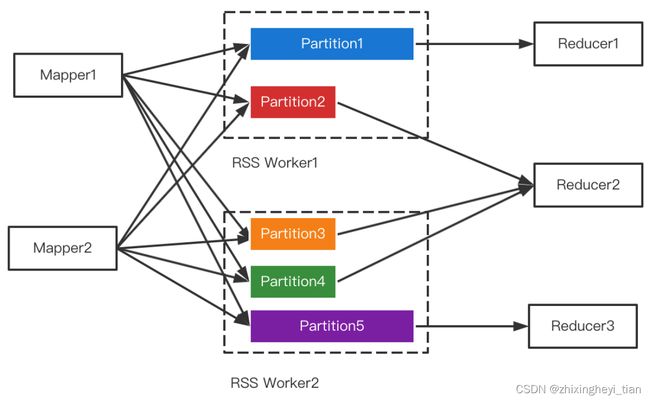
支持Join策略切换
Join策略切换对Shuffle框架的需求是能够支持LocalShuffleReader。由于RSS的Remote属性,数据存放在RSS集群,仅当RSS和计算集群混部的场景下才会存在在本地,因此暂不支持Local Read(将来会优化混部场景并加以支持)。需要注意的是,尽管不支持Local Read,但并不影响Join的改写,RSS支持Join改写优化
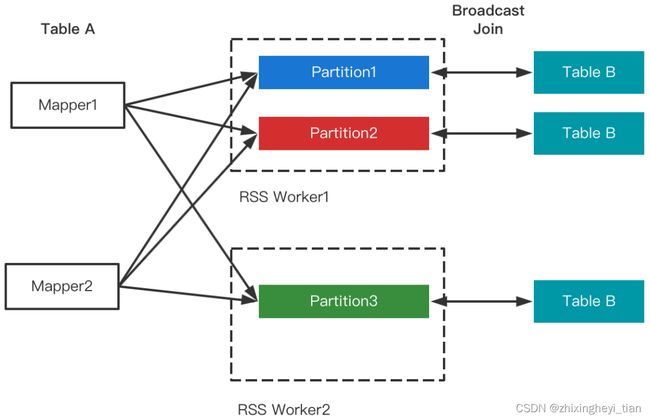
在AQE的三个场景中,RSS支持Join倾斜优化是最为困难的一点。RSS的核心设计是Partition数据聚合,目的是把Shuffle Read的随机读转变为顺序读,从而提升性能和稳定性。多个Mapper同时推送给RSS Worker,RSS在内存聚合后刷盘,因此Partition文件中来自不同Mapper的数据是无序的

Spark ESS
Spark的动态资源分配就是executor数据量的动态增减,具体的增加和删除数量根据业务的实际需要动态的调整。具体表现为:如果executor数据量不够,则增加数量,如果executor在一段时间内空闲,则移除这个executor。
动态资源分配的开启
(1)spark.dynamicAllocation.enabled=true,表示开启动态资源分配功能
(2)spark.shuffle.service.enabled=true,表示在nodemanager上开启shuffle功能,只有这两个配置项都开启的时候,动态资源分配功能才算生效。
如果 以spark on yarn为例,spark.shuffle.service.enabled=true,还需要在yarn-site.xml中配置以下内容。
yarn.nodemanager.aux-services
mapreduce_shuffle,spark_shuffle
yarn.nodemanager.aux-services.spark_shuffle.class
org.apache.spark.network.yarn.YarnShuffleService
spark.shuffle.service.port
xxxx
ESS
现在我们在来看下external shuffle service(ESS),其乍从其名字上看,ESS是spark分布式集群为存储shuffle data而设计的分布式组件。但其实它只是Spark通过Executor获取Shuffle data块的代理。
我们可以理解为ESS负责管理shuffle write端生成的shuffle数据,ESS是和yarn一起使用的, 在yarn集群上的每一个nodemanager上面都运行一个ESS,是一个常驻进程。一个ESS管理每个nodemanager上所有的executor生成的shuffle数据。总而言之,ESS并不是分布式的组件,它的生命周期也不依赖于Executor。
Spark ESS 为 Spark Shuffle 操作带来了以下好处:
- 即使 Spark Executor 正在经历 GC 停顿,Spark ESS 也可以为 Shuffle 块提供服务。
- 即使产生它们的 Spark Executor 挂了,Shuffle 块也能提供服务。
- 可以释放闲置的 Spark Executor 来节省集群的计算资源。
缺点:
ESS服务的存在也会影响文件删除。在正常情况下(没有外部 shuffle 服务),当Executor停止时,它会自动删除生成的文件。但是启用ESS服务后,Executor关闭后文件不会被清理。
shuffle 数据目录
# cd /data10/nm/usercache/root/appcache/application_1690958779805_0001/
# ll
total 20K
drwxr-xr-x 66 root root 4.0K Aug 2 15:07 blockmgr-0b8c2df3-abcf-44c4-82a3-402d8d4e90dd
drwxr-xr-x 66 root root 4.0K Aug 2 15:08 blockmgr-8f29b0df-155e-4079-b4ea-65a2b17a923f
drwxr-xr-x 66 root root 4.0K Aug 2 15:07 blockmgr-a3e9ed5e-d4f2-44cc-9206-d9985e11f7e7
drwxr-xr-x 66 root root 4.0K Aug 2 15:04 blockmgr-c2cf05e4-5f2b-438a-b7c0-68af3a0da6c7
drwx--x--- 2 root root 10 Aug 2 14:47 container_1690958779805_0001_01_000001
drwx--x--- 3 root root 4.0K Aug 2 14:47 container_1690958779805_0001_01_000002
drwx--x--- 2 root root 10 Aug 2 14:47 container_1690958779805_0001_01_000003
drwx--x--- 2 root root 10 Aug 2 14:47 container_1690958779805_0001_01_000004
drwx--x--- 2 root root 10 Aug 2 14:47 container_1690958779805_0001_01_000005
drwx--x--- 2 root root 10 Aug 2 14:47 filecache
drwxr-xr-x 4 root root 58 Aug 2 14:53 gluten-14209dc5-7054-4ec6-b692-f4d0bb108b7f
drwxr-xr-x 5 root root 73 Aug 2 14:53 gluten-21301fa5-846f-4678-a2fb-ccf756ca467e
drwxr-xr-x 5 root root 73 Aug 2 14:53 gluten-423af483-72ef-4027-a3ff-19912bf76d66
drwxr-xr-x 4 root root 58 Aug 2 14:53 gluten-e9e557ac-f5f2-4494-97e4-9c36f7a3405b
# ll /data10/tmp
total 4.0K
drwxr-xr-x 65 root root 4.0K Aug 2 15:43 blockmgr-8c0b227f-e497-46d5-99e8-95f2ede8db6d
drwxr-xr-x 2 root root 10 Aug 2 14:47 gluten-dc2cc119-89e3-4fbd-b405-1a5993f99475
drwx------ 2 root root 10 Aug 2 14:47 spark-257449ed-897b-4583-81d7-b777fcbef55d
Spark AQE and rebalance
参考链接
https://blog.csdn.net/monkeyboy_tech/article/details/125548654
相关jira
- [SPARK-35786][SQL] Add a new operator to distingush if AQE can optimize safely https://issues.apache.org/jira/browse/SPARK-35786
- SPARK-35725 Support repartition expand partitions in AQE
- https://issues.apache.org/jira/browse/SPARK-35793
spark sql hints
https://spark.apache.org/docs/3.2.1/sql-ref-syntax-qry-select-hints.html#hints
SELECT /*+ COALESCE(3) */ * FROM t;
SELECT /*+ REPARTITION(3) */ * FROM t;
SELECT /*+ REPARTITION(c) */ * FROM t;
SELECT /*+ REPARTITION(3, c) */ * FROM t;
SELECT /*+ REPARTITION_BY_RANGE(c) */ * FROM t;
SELECT /*+ REPARTITION_BY_RANGE(3, c) */ * FROM t;
SELECT /*+ REBALANCE */ * FROM t;
SELECT /*+ REBALANCE(c) */ * FROM t;