【吴恩达】深度学习
参考资料:
deeplearning_ai_book
deeplearning.ai_JupyterNotebooks
GitHub另一个仓库
二、神经网络的编程基础(Basics of Neural Network programming)
2.1 二分类(Binary Classification)
- 例子:图片中是否有猫?

- 如果图片的大小为64x64像素,则 n x = 64 ∗ 64 ∗ 3 = 12288 n_x = 64*64*3 = 12288 nx=64∗64∗3=12288
- 符号定义

- 其中 ( x ( n ) , y ( n ) ) (x^{(n)},y^{(n)}) (x(n),y(n))表示第n个样本(样本数从1开始计数)
- 将所有的输入向量整合为矩阵为 X = { x ( 1 ) , x ( 2 ) , . . . , x ( m ) } X = \{x^{(1)},x^{(2)},...,x^{(m)}\} X={x(1),x(2),...,x(m)},输入矩阵的shape为 n x n_x nx行 m m m列;同样的,输出矩阵 Y = { y ( 1 ) , y ( 2 ) , . . . , y ( m ) } Y= \{y^{(1)},y^{(2)},...,y^{(m)}\} Y={y(1),y(2),...,y(m)}的shape为1行m列。一个好的符号约定能够将不同训练样本的数据很好地组织起来,使用这样的矩阵形式能够更容易实现一个神经网络。
2.2 逻辑回归(Logistic Regression)
- 构建“假设函数” y ^ = w x + b \hat y = wx+b y^=wx+b 来预测图片中是否有猫,但 y ^ ∈ ( − ∞ , + ∞ ) \hat y \in (-\infin,+\infin) y^∈(−∞,+∞),而真实值 y = { 0 , 1 } y = \{0,1\} y={0,1},故使用 s i g m o i d sigmoid sigmoid函数将其压缩至 ( 0 , 1 ) (0,1) (0,1)

- 符号惯例,可以让参数 w w w和参数 b b b分开

2.3 逻辑回归的代价函数(Logistic Regression Cost Function)
-
为什么需要代价函数:

需要使用代价函数来得到使得预测结果最优的参数 w w w和 b b b -
损失函数
又称误差函数,用于衡量算法的运行情况: L ( y ^ , y ) L(\hat y,y) L(y^,y),常用形式:

为什么不用平方差或者平方差的一半?
推导:

损失函数是在单个训练样本中定义的,衡量的是算法在单个训练样本中表现如何。为了衡量算法在全部训练样本上的表现如何,我们需要定义一个算法的代价函数,算法的代价函数是对个样本的损失函数求和然后除以m

- 损失函数<—>单个训练样本;代价函数<—>参数总代价
- 训练逻辑回归模型时,需要找到合适的参数w和b使得代价函数J的总代价降到最低
2.4 梯度下降法(Gradient Descent)
- 梯度下降法可以做什么?
通过最小优化代价函数 J = ( w , b ) J = (w,b) J=(w,b)来训练参数 w w w和 b b b - 梯度下降法的形象化说明

- 在实践中, w w w可以是更高的维度。为了更好地绘图,上图中定义 w w w和 b b b都为单一实数, J ( w , b ) J(w,b) J(w,b)是水平轴w和b上面的曲面。
- 必须定义代价函数是一个凸函数,由此可以找到最小值。
-
梯度下降法怎么走到凸函数最小值点
(1)当代价函数 J ( w ) J(w) J(w)只有一个参数 w w w时,此时可用一维曲线代替多维曲线
迭代公式: w : = w − α d J ( w ) d w w := w- \alpha\dfrac{dJ(w)}{dw} w:=w−αdwdJ(w)其中, : = := :=表示更新参数; α \alpha α表示学习率,用来控制步长 d J ( w ) d w \dfrac{dJ(w)}{dw} dwdJ(w),步长 d J ( w ) d w \dfrac{dJ(w)}{dw} dwdJ(w)即为函数 J ( w ) J(w) J(w)对 w w w的求导。
-
当初始化 w 0 w_0 w0大于最优值 w ∗ w^* w∗:

此时函数 J ( w ) J(w) J(w)于 w 0 w_0 w0处求导结果 d J ( w ) d w \dfrac{dJ(w)}{dw} dwdJ(w)为正数(即该处函数曲线斜率为正值),而 w : = w − α d J ( w ) d w w := w- \alpha\dfrac{dJ(w)}{dw} w:=w−αdwdJ(w),即 w w w值变小,该点向左走,直至逼近最小点。 -
当初始化 w 0 w_0 w0小于最优值 w ∗ w^* w∗:

此时函数 J ( w ) J(w) J(w)于 w 0 w_0 w0处求导结果 d J ( w ) d w \dfrac{dJ(w)}{dw} dwdJ(w)为负数(即该处函数曲线斜率为负值,而 w : = w − α d J ( w ) d w w := w- \alpha\dfrac{dJ(w)}{dw} w:=w−αdwdJ(w),即 w w w值变大,该点向右走,直至逼近最小点。
(2)当代价函数 J ( w , b ) J(w,b) J(w,b)有两个参数 w , b w,b w,b时

- 符号 ∂ \partial ∂表示求偏导,在函数有两个及以上的参数时将使用该符号表示对某一参数求偏导
- 符号 d d d表示求导数,在函数仅有一个参数时使用该符号求参数导数。
2.5 计算图(Computation Graph)
计算图解释了为什么我们前向和反向传输的方式组织计算过程

在上图的例子中,我们确定了参数 a , b , c a,b,c a,b,c的值后,可得出中间值 u , v u,v u,v的值。
-
通过前向计算(蓝色箭头,从左往右),可计算出函数 J ( a , b , c ) J(a,b,c) J(a,b,c)的值;

-
通过反向计算(红色箭头,从右到左),可以计算中间值 u , v u,v u,v和参数 a , b , c a,b,c a,b,c的导数。

这里的计算过程也就是我们求多元函数偏导时所说的**“链式法则”**
- 代码中,使用变量 d v a r dvar dvar来表示导数值 d J d v a r \dfrac{dJ}{dvar} dvardJ。比如上图中,可以用 d c dc dc表示导数值 d J d c \dfrac{dJ}{dc} dcdJ
2.6 逻辑回归中的梯度下降(Logistic Regression Gradient Descent)

实现针对单个训练样本的逻辑回归的梯度下降算法:
- 使用 d z = ( a − y ) dz = (a-y) dz=(a−y)计算 d z dz dz,
- 使用 d w 1 = x 1 ∗ d z dw_1 = x_1*dz dw1=x1∗dz计算 d w 1 dw_1 dw1, d w 2 = x 2 ∗ d z dw_2 = x_2*dz dw2=x2∗dz计算, d b = d z db = dz db=dz来计算 d b db db
- 然后使用 w 1 : = w 1 − α d w 1 w_1 := w_1-\alpha dw_1 w1:=w1−αdw1 更新 w 1 w_1 w1, 使用 w 2 : = w 1 − α d w 2 w_2 := w_1-\alpha dw_2 w2:=w1−αdw2 更新 w 2 w_2 w2, 使用 b : = b − α d b b:= b-\alpha db b:=b−αdb 更新 b b b。
但是,训练逻辑回归模型不仅仅只有一个训练样本,而是有个训练样本的整个训练集。
2.7 m 个样本的梯度下降(Gradient Descent on m Examples)
损失函数的定义:

即要对最后 J , w 1 , w 2 , b J,w_1,w_2,b J,w1,w2,b求平均:

代码流程:
J=0;dw1=0;dw2=0;db=0; # 初始化都为0
for i = 1 to m
z(i) = wx(i)+b;
a(i) = sigmoid(z(i));
J += -[y(i)log(a(i))+(1-y(i))log(1-a(i));
dz(i) = a(i)-y(i);
dw1 += x1(i)dz(i);
dw2 += x2(i)dz(i);
db += dz(i);
J/= m;
dw1/= m;
dw2/= m;
db/= m;
w=w-alpha*dw
b=b-alpha*db
但其中的for循环会使得算法效率非常低,故使用特征向量化来提高算法效率。
2.8 向量化(Vectorization)
-
向量化和for循环效率对比

如上图所示,向量化版本花费了1.5毫秒,非向量化版本的for循环花费了大约几乎500毫秒,非向量化版本多花费了300倍时间。
当我们在写神经网络程序时,或者在写逻辑(logistic)回归,或者其他神经网络模型时,应该避免写循环(loop)语句。虽然有时写循环(loop)是不可避免的,但是我们可以使用比如numpy的内置函数或者其他办法去计算。当你这样使用后,程序效率总是快于循环(loop)。
-
例子(numpy中向量的相关操作)
- 两个向量乘积:
r = np.dot(a,b) - 对向量的每个元素做指数操作:
r = np.exp(a)
2.9 向量化逻辑回归(Vectorizing Logistic Regression)

在同一时间内如何完成一个所有 m个训练样本的前向传播向量化计算:
- 对第 i i i个样本 x ( i ) x^{(i)} x(i), x ( i ) x^{(i)} x(i)的shape为 ( n x , 1 ) (n_x,1) (nx,1)。将m个样本的x横向堆叠一起组成输入矩阵 X X X, X X X的shape为 ( n x , m ) (n_x,m) (nx,m)
- 我们需要先使用 z ( i ) = w T x ( i ) + b z^{(i)} = w^T x^{(i)}+b z(i)=wTx(i)+b得出第 i i i个样本的 z ( i ) z^{(i)} z(i),其中 w T w^T wT的shape为 ( 1 , n x ) (1,n_x) (1,nx),故 z ( i ) z^{(i)} z(i)的shape为(1,1),最后将m个z横向堆叠一起组成 Z Z Z, Z Z Z的shape为 ( 1 , m ) (1,m) (1,m)

代码:
import numpy as np
Z = np.dot(w.T,x)+b # 此处 python 自动将 b 扩展为(1,m)的向量
- 最后再由 a ( i ) = σ ( z ( i ) ) a^{(i)} = \sigma(z^{(i)}) a(i)=σ(z(i))得出预测值 a ( i ) a^{(i)} a(i),将m个a横向堆叠一起组成 A A A, A A A的shape为 ( 1 , m ) (1,m) (1,m)
2.10 向量化 logistic 回归的梯度输出(Vectorizing Logistic Regression’s Gradient)
- 在【2.6 逻辑回归中的梯度算法】中,我们知道其中的推导公式和计算步骤为:
- 使用 d z = ( a − y ) dz = (a-y) dz=(a−y)计算 d z dz dz,
- 使用 d w 1 = x 1 ∗ d z dw_1 = x_1*dz dw1=x1∗dz计算 d w 1 dw_1 dw1, d w 2 = x 2 ∗ d z dw_2 = x_2*dz dw2=x2∗dz计算, d b = d z db = dz db=dz来计算 d b db db
- 然后使用 w 1 : = w 1 − α d w 1 w_1 := w_1-\alpha dw_1 w1:=w1−αdw1 更新 w 1 w_1 w1, 使用 w 2 : = w 1 − α d w 2 w_2 := w_1-\alpha dw_2 w2:=w1−αdw2 更新 w 2 w_2 w2, 使用 b : = b − α d b b:= b-\alpha db b:=b−αdb 更新 b b b。
- 那么向量化计算去掉for循环的计算为:
-
使用 d z = ( a − y ) dz = (a-y) dz=(a−y)计算 d z dz dz,

-
使用 d w 1 = x 1 ∗ d z dw_1 = x_1*dz dw1=x1∗dz计算 d w 1 dw_1 dw1, d w 2 = x 2 ∗ d z dw_2 = x_2*dz dw2=x2∗dz计算, d b = d z db = dz db=dz来计算 d b db db
此处遍历训练集的循环需要去掉:

可发现 d b = 1 m ∑ i = 1 m d z ( i ) db=\dfrac{1}{m}\displaystyle\sum_{i=1}^{m}dz^{(i)} db=m1i=1∑mdz(i),使用代码实现:db = (1/m) * np.sum(dZ)而 d w = 1 m ∗ X ∗ d z T dw = \dfrac{1}{m}*X*dz^T dw=m1∗X∗dzT,其中, X X X是一个行向量,即

使用代码实现:dw = (1/m) * np.dot(X,dz.T) -
然后使用 w 1 : = w 1 − α d w 1 w_1 := w_1-\alpha dw_1 w1:=w1−αdw1 更新 w 1 w_1 w1, 使用 w 2 : = w 1 − α d w 2 w_2 := w_1-\alpha dw_2 w2:=w1−αdw2 更新 w 2 w_2 w2, 使用 b : = b − α d b b:= b-\alpha db b:=b−αdb 更新 b b b。

此处对 w , b w,b w,b的更新仍需要for循环
2.11 Python 中的广播(Broadcasting in Python)
-
广播原理:
如果两个数组的后缘维度的轴长度相符或其中一方的轴长度为1,则认为它们是广播兼容的。广播会在缺失维度和轴长度为1的维度上进行。如例: 当 m ∗ n m*n m∗n的矩阵和 1 ∗ n 1*n 1∗n 的矩阵相加。在执行加法操作时,其实是将 1 ∗ n 1*n 1∗n 的矩阵复制成为 m ∗ n m*n m∗n 的矩阵,然后两者做逐元素加法得到结果

2. Tips in coding:
-
但是当我们写代码时不确定矩阵维度的时候,通常会对矩阵进行重塑来确保得到我们想要的列向量或行向量。重塑操作
reshape是一个常量时间的操作,时间复杂度是,它的调用代价极低。 -
尽量不将一维数组当作向量来运算

每次创建一个数组时,都让它成为一个列向量(n,1)或者行向量(1,n),那么其后的向量运算行为更容易被理解,也不会出现向量运算上的奇怪bug。

-
当不完全确定一个向量的维度(dimension)时,扔进一个断言语句(assertion statement)。

这些断言语句实际上是要去执行的,并且它们也会有助于为你的代码提供信息。所以不论你要做什么,不要犹豫直接插入断言语句。
2.18 (选修)logistic 损失函数的解释(Explanation of logistic regression cost function)
暂时留白
其他:
- 注意
np.dot和vector1*vector2的区别
np.dot(vector1*vector2):即矩阵乘法,若vector1的shape为(x1*y1),vector2的shape为(x2,y2),则需要y1=x2才能进行运算(可广播的情况除外),否则报错。结果矩阵的shape为(x1,y2)vector1*vector2:两个向量中每个元素对应相乘,需要两个向量的shape一模一样,若vector1的shape为(x1*y1),vector2的shape为(x2,y2),则需要x1=x2,y1=y2才能进行运算(可广播的情况除外)否则报错。最后得出的结果向量的shape与vector1和vector2的一样。
a = np.random.randn(4,3)
a
array([[ 0.76779236, 0.18444005, 1.21712122],
[ 0.38977012, -0.56798278, 0.39299285],
[ 0.04380387, 0.25158324, 0.225215 ],
[-0.61341907, 0.74052763, -0.59685251]])
b = np.random.randn(3,2)
b
array([[-1.00104395, 0.26388446],
[-0.26633242, 0.44364925],
[ 0.40333879, -0.55962817]])
a*b
Traceback (most recent call last):
File "", line 1, in <module>
ValueError: operands could not be broadcast together with shapes (4,3) (3,2)
np.dot(a,b) # 矩阵乘法
array([[-0.32680406, -0.39670016],
[-0.08039554, -0.36906072],
[-0.02001642, -0.00286278],
[ 0.17609917, 0.50067824]])
c = np.random.randn(4,3)
a*c # 按对应元素相乘
array([[-0.91545714, 0.15368263, 0.08580373],
[-0.36117068, 0.0390558 , 0.37478451],
[-0.05269544, -0.09970869, 0.35626428],
[-1.26493901, 0.87666868, -0.65915348]])
d = np.random.randn(4,1)
a*d # 广播,d横向复制三次后shape为(4,3)
array([[-0.9078016 , -0.21807324, -1.43906692],
[-0.07042533, 0.10262555, -0.07100762],
[ 0.07332278, 0.42112225, 0.37698475],
[ 0.35215146, -0.4251219 , 0.34264093]])
- softmax:You can think of softmax as a normalizing function used when your algorithm needs to classify two or more classes. You will learn more about softmax in the second course of this specialization.

3.1 神经网络概述(Neural Network Overview)
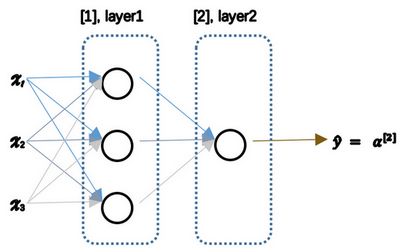
- 前向传播
layer1:输入值为特征向量x,参数w[1]和b[1];结果为a[1]

layer2:输入值为a[1]和新参数w[2],b[2];结果为最终输出a[2],并得出损失函数L(a[2],y)

- 反向传播:计算倒数,更新参数

3.2 神经网络的表示(Neural Network Representation)

- 输入层:输入特征的堆叠。一般不将输入层算为神经网络的一层(或当作第0层)
- 隐藏层:在训练集中,这些中间结点的准确值我们是不知道到的,也就是说你看不见它们在训练集中应具有的值。你能看见输入的值,你也能看见输出的值,但是隐藏层中的东西,在训练集中你是无法看到的。
- 输出层:只有一个结点的层,负责产生预测值
3.3 计算一个神经网络的输出(Computing a Neural Network’s output)
- 神经网络的符号惯例: x x x表示输入特征, a a a表示每个神经元的输出( a [ 0 ] a^{[0]} a[0]则表示输入层), W W W表示特征的权重,上标表示神经网络的层数(隐藏层为1),下标表示该层的第几个神经元。
- 神经网络的计算
-
神经网络的计算单元:

该神经元中的计算与逻辑回归一样,分为两步:
(1) 计算 z 1 [ 1 ] z_1^{[1]} z1[1]
(2) 通过激活函数计算 a 1 [ 1 ] a_1^{[1]} a1[1] -
向量化计算
则第一层隐含层的四个神经元计算过程为:

将上面4个式子向量化:


- 总结

- 如上图左半部分所示为神经网络,把网络左边部分盖住先忽略,那么最后的输出单元就相当于一个逻辑回归的计算单元。注意 a [ 1 ] a^{[1]} a[1]的shape为(4,1), a [ 2 ] = y ^ ( 最 后 输 出 ) a^{[2]} = \hat y(最后输出) a[2]=y^(最后输出)的shape为(1,1)
- 当你有一个包含一层隐藏层的神经网络,你需要去实现以计算得到输出的是右边的四个等式,并且可以看成是一个向量化的计算过程,计算出隐藏层的四个逻辑回归单元和整个隐藏层的输出结果,如果编程实现需要的也只是这四行代码。
3.4 多样本向量化(Vectorizing across multiple examples)

- 垂直方向:从上到下对应神经网络同一层的不同神经元。比如,逻辑回归的输出 A [ 1 ] A^{[1]} A[1]的第一列展开为 a [ 1 ] ( 1 ) = [ a 1 [ 1 ] ( 1 ) , a 2 [ 1 ] ( 1 ) , a 3 [ 1 ] ( 1 ) , a 4 [ 1 ] ( 1 ) ] a^{[1](1)} = [a^{[1](1)}_1,a^{[1](1)}_2,a^{[1](1)}_3,a^{[1](1)}_4] a[1](1)=[a1[1](1),a2[1](1),a3[1](1),a4[1](1)]
- 水平方向:从左到右对应第一个训练样本的值一直到第m个训练样本的值。比如,逻辑回归的输出 A [ 1 ] = [ a [ 1 ] ( 1 ) , a [ 1 ] ( 2 ) , . . . , a [ 1 ] ( m ) ] A^{[1]} = [a^{[1](1)},a^{[1](2)},...,a^{[1](m)}] A[1]=[a[1](1),a[1](2),...,a[1](m)]
3.5 激活函数(Activation functions)
- 四种激活函数

-
sigmoid 函数:
a = σ ( z ) = 1 1 + e − z a = \sigma(z) = \dfrac{1}{1+e^{-z}} a=σ(z)=1+e−z1,值域为(0,1)。二分类问题中,因为预测值应为0或1,故需让输出值 y ^ \hat y y^数值介于0和1之间,此时需使用sigmoid函数。处理其他问题时,基本不用该函数。
-
tanh函数:
a = tan h ( z ) = e z − e − z e z + e − z a = \tan h(z) = \dfrac{e^z-e^{-z}}{e^z+e^{-z}} a=tanh(z)=ez+e−zez−e−z,值域为(-1,1)。事实上,tanh函数是sigmoid的向下平移和伸缩后的结果。在训练一个算法模型时,如果使用tanh函数代替sigmoid函数中心化数据,因为它的值域在-1和+1,这使得数据的平均值更接近0而不是0.5,故其效果总是优于sigmoid函数。
sigmoid函数和tanh函数两者共同的缺点:在 z z z特别大或者特别小的情况下,导数的梯度或者函数的斜率会变得特别小,最后就会接近于0,导致降低梯度下降的速度很慢
-
修正线性单元的函数(ReLu):
a = m a x ( 0 , z ) a = max(0,z) a=max(0,z)在该函数中,只要 z z z是正值,导数恒等于1,当 z z z是负值时,导数恒等于0。 z z z在ReLu的梯度一半都是0,但是,有足够的隐藏层使得z值大于0,所以对大多数的训练数据来说学习过程仍然可以很快。
一些选择激活函数的经验法则:如果输出是0、1值(二分类问题),则输出层选择sigmoid函数,然后其它的所有单元都选择Relu函数。
- Leaky Relu:
a = { z if z ≥ 0 α z if z ≤ 0 , α 通 常 取 值 为 0.01 a = \begin{dcases} z &\text{if } z \geq 0 \\ \alpha z &\text{if } z \le 0 \end{dcases}, \alpha通常取值为0.01 a={zαzif z≥0if z≤0,α通常取值为0.01
- 总结
-
在 z z z的区间变动很大的情况下,激活函数的导数或斜率都远大于0,在程序实现就是一个if-else语句,而sigmoid函数需要进行浮点四则运算,在实践中,使用ReLu激活函数神经网络通常会比使用sigmoid或者tanh激活函数学习的更快。
-
sigmoid和tanh函数的导数在正负饱和区的梯度都会接近于0,这会造成梯度弥散。而Relu和Leaky ReLu函数大于0的部分都为常数,不会产生梯度弥散现象。(同时应该注意到的是,Relu进入负半区的时候,梯度为0,神经元此时不会训练,产生所谓的稀疏性,而Leaky ReLu不会有这问题)
-
一般来说,如果不确定用哪个激活函数,就使用ReLu或者Leaky ReLu,但具体问题具体分析,这也不是绝对的。
3.6 为什么需要非线性激活函数?(why need a nonlinear activation function?)
- 如果你使用线性激活函数或者没有使用一个激活函数,那么无论你的神经网络有多少层一直在做的只是计算线性函数,所以不如直接去掉全部隐藏层。即非线性激活函数为神经网络带来非线性,否则堆多少层都与单个线性层无异。
- 线性两层: f = W 2 W 1 x 可 以 等 价 为 f = W 3 x ( 其 中 W 3 = W 1 W 2 ) f = W_2W_1x 可以等价为 f = W_3x(其中W_3=W_1W_2) f=W2W1x可以等价为f=W3x(其中W3=W1W2)
- 总而言之,不能在隐藏层用线性激活函数,可以用ReLU或者tanh或者leaky ReLU或者其他的非线性激活函数,唯一可以用线性激活函数的通常就是输出层。
3.7 神经网络的梯度下降(Gradient descent for neural networks)
-
图解

-
公式:

3.8(选修)直观理解反向传播(Backpropagation intuition)
3.9 随机初始化(Random+Initialization)
- 逻辑回归:
- 权重可以初始化为0
- 神经网络:

-
对称问题:若将权重都初始化为0,则神经网络里所有的隐含单元计算的都是同一个函数,所有的隐含单元就会对输出单元有同样的影响,即隐含单元是对称的。不管训练网络多久时间隐含单元仍然计算的是相同的函数。
-
打破对称:随机初始化权重,使用
np.random.randn(n,m)*0.01;偏移量b可以初始化为0,即np.zeros(n,1)- 为什么权重初始化乘以的常数是
0.01,而不是10或100:如果初始化常数太大,权重w就会很大或很小,那么激活值z就会很大或者很小,即停在激活函数(sigmoid或tanh)的平坦处,这些地方的梯度很小,也就意味着梯度下降会很慢,因此学习就会很慢。
- 为什么权重初始化乘以的常数是
测验:
- The tanh activation is not always better than sigmoid activation function for hidden units because the mean of its output is closer to zero, and so it centers the data, making learning complex for the next layer.
4.1 深层神经网络(Deep L-layer neural network)
深度学习符号
4.2 前向传播和反向传播(Forward and backward propagation)

4.3 深层网络中的前向传播(Forward propagation in a Deep Network)
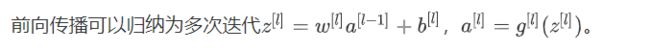
向量化实现:

4.4 核对矩阵的维数(Getting your matrix dimensions right)
-
向量化前:
w [ l ] . s h a p e = d w [ l ] . s h a p e : ( n [ l ] , n [ l − 1 ] ) , 即 ( 该 层 维 数 , 前 一 层 维 数 ) b [ l ] . s h a p e = d b [ l ] . s h a p e : ( n [ l ] , 1 ) , 即 ( 该 层 维 数 , 1 ) z [ l ] = w [ l ] a [ l − 1 ] + b [ l ] , z [ l ] . s h a p e = d z [ l ] . s h a p e : ( n [ l ] , 1 ) a [ l ] = g [ l ] ( z [ l ] ) , a [ l ] . s h a p e = d a [ l ] . s h a p e : ( n [ l ] , 1 ) ( 输 入 x 即 为 a [ 0 ] ) w^{[l]}.shape = dw^{[l]}.shape:(n^{[l]},n^{[l-1]}),即(该层维数,前一层维数)\\ b^{[l]}.shape = db^{[l]}.shape:(n^{[l]},1),即(该层维数,1)\\ z^{[l]} = w^{[l]}a^{[l-1]}+b^{[l]},z^{[l]}.shape = dz^{[l]}.shape:(n^{[l]},1)\\ a^{[l]} = g^{[l]}(z^{[l]}),a^{[l]}.shape = da^{[l]}.shape:(n^{[l]},1)(输入x即为a^{[0]}) w[l].shape=dw[l].shape:(n[l],n[l−1]),即(该层维数,前一层维数)b[l].shape=db[l].shape:(n[l],1),即(该层维数,1)z[l]=w[l]a[l−1]+b[l],z[l].shape=dz[l].shape:(n[l],1)a[l]=g[l](z[l]),a[l].shape=da[l].shape:(n[l],1)(输入x即为a[0])
-
向量化后: w w w和 b b b的维度不变, z , a z,a z,a的维度变化
m 为 训 练 集 大 小 : Z [ l ] . s h a p e = d Z [ l ] . s h a p e : ( n [ l ] , m ) , A [ l ] . s h a p e = d A [ l ] . s h a p e : ( n [ l ] , m ) , A [ 0 ] = X . s h a p e : ( n [ l ] , m ) m为训练集大小:\\ Z^{[l]}.shape = dZ^{[l]}.shape : (n^{[l]},m),\\ A^{[l]}.shape = dA^{[l]}.shape : (n^{[l]},m),\\ A^{[0]} = X.shape: (n^{[l]},m) m为训练集大小:Z[l].shape=dZ[l].shape:(n[l],m),A[l].shape=dA[l].shape:(n[l],m),A[0]=X.shape:(n[l],m)
4.5 为什么使用深层表示?(Why deep representations?)
Small:隐藏单元的数量相对较少
Deep:隐藏层数目比较多
深层的网络隐藏单元数量相对较少,隐藏层数目较多,如果浅层的网络想要达到同样的计算结果则需要指数级增长的单元数量才能达到。
4.6 搭建神经网络块(Building blocks of deep neural networks)


第二门课 改善深层神经网络:超参数调试、正则化以及优化(Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)
第一周:深度学习的实践层面(Practical aspects of Deep Learning)
1.1 训练,验证,测试集(Train / Dev / Test sets)
- 在机器学习中,我们通常将样本分成训练集,验证集和测试集三部分,数据集规模相对较小,适用传统的划分比例(三七分或者60%+20%+20%);数据集规模较大的(百万级),验证集和测试集要小于数据总量的20%或10%。
- 确保验证集和测试集的数据来自同一分布
- 就算没有测试集也不要紧,测试集的目的是对最终所选定的神经网络系统做出无偏估计,如果不需要无偏估计,也可以不设置测试集。如果只有验证集,没有测试集,我们要做的就是,在训练集上训练,尝试不同的模型框架,在验证集上评估这些模型,然后迭代并选出适用的模型。因为验证集中已经涵盖测试集数据,其不再提供无偏性能评估。
1.2 偏差,方差(Bias /Variance)

- 高偏差(high bias):不能很好地拟合该数据,称为“欠拟合”(underfitting)。
- 适度拟合(just right):复杂程度适中,数据拟合适度的分类器,这个数据拟合看起来更加合理,介于过度拟合和欠拟合中间的一类。
- 高方差(high variance):数据过度拟合(overfitting)。采用曲线函数或二次元函数会产生高方差,因为它曲线灵活性太高以致拟合了这两个错误样本和中间这些活跃数据。
1.3 机器学习基础(Basic Recipe for Machine Learning)
怎么找到一个低偏差,低方差的框架?注意以下两点:
- 高偏差和高方差是两种不同的情况,所对应的解决方法也可能完全不同。通常可使用训练验证集来诊断是哪个问题。所以大家要清楚存在的问题是偏差还是方差,还是两者都有问题,明确这一点有助于我们选择出最有效的方法。
- 训练网络,选择网络或者准备更多数据。深度学习可能存在过拟合问题——高方差,有两个解决方法,一个是正则化,另一个是准备更多的数据。
1.4 正则化(Regularization)
- L 2 L_2 L2正则化(较 L 1 L_1 L1正则化更常见):
.
- 为什么只正则化w,而不正则化b?
- 可以正则化b(添加 λ 2 m b 2 \dfrac{\lambda}{2m}b^2 2mλb2),但没有太大影响,可以忽略不计。因为w通常是一个高位参数矢量,而b只是单个数字
- λ是正则化参数,通常使用验证集或交叉验证集来配置这个参数,尝试各种各样的数据,要考虑训练集之间的权衡,把参数设置为较小值,这样可以避免过拟合,所以λ是另外一个需要调整的超级参数。另外,因为
lambda在python中是一个关键字,所以编码时通常写作lambd,以避免冲突。
- L 1 L_1 L1正则化:
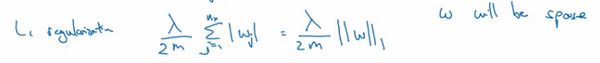
- 如果用的是 L 1 L_1 L1正则化,最终w会是稀疏的,也就是说w向量中有很多0。但这并不能使得模型变得稀疏,并没有降低太多存储内存。
- 利用该范数实现梯度下降
backprop:J对W的偏导数 ∂ J ∂ W [ l ] \dfrac{\partial J}{\partial W^{[l]}} ∂W[l]∂J
在更新参数W时带入:

具体展开可得:

可以看到,相较于之前的 W [ l ] : = W [ l ] − α d W [ l ] W^{[l]}:=W^{[l]}-\alpha dW^{[l]} W[l]:=W[l]−αdW[l],W乘以小于1等于的数再减去学习率那一部分,所以 L 2 L_2 L2正则化有时被称为 “权重衰减”。
1.5 为什么正则化有利于预防过拟合呢?(Why regularization reduces overfitting?)

-
从公式分析:
如果 λ \lambda λ设置得足够大,权重矩阵 W W W被设置为接近于0的值,直观理解就是把多隐藏单元的权重设为0,可近似为消除了这些隐藏单元的影响。此时被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元(其实不然,实际上是该神经网络的所有隐藏单元依然存在,但是它们的影响变得更小了),可是深度却很大,它会使这个网络从过拟合的状态更接近左图的高偏差状态(high bias)。也就是说, λ \lambda λ的增大能带来方差减小的效果。 -
从激活函数角度分析:
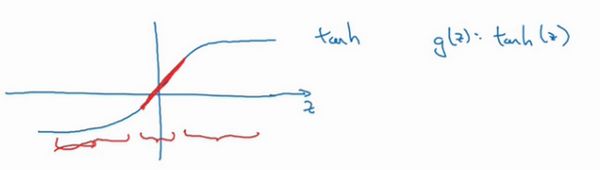
λ变大 -> W变小 -> |Z|变小
如果|Z|始终在这个范围内,激活函数最后可近似为线性函数,整个神经网络会计算离线性函数近的值,这个线性函数非常简单,并不是一个极复杂的高度非线性函数,不会发生过拟合。 -
使用正则化函数时,损失函数应使用:

如果你用的是原损失函数J(也就是第一个项),你可能看不到单调递减现象,为了调试梯度下降,请务必使用新定义的损失函数J(两项和),它包含第二个正则化项,否则函数可能不会在所有调幅范围内都单调递减。
1.6 dropout 正则化(Dropout Regularization)
1. 工作原理:dropout(随机失活)会遍历网络的每一层,并设置消除神经网络中节点的概率,之后我们会消除一些节点,然后删除掉从该节点进出的连线,最后得到一个节点更少,规模更小的网络,然后用backprop方法进行训练。
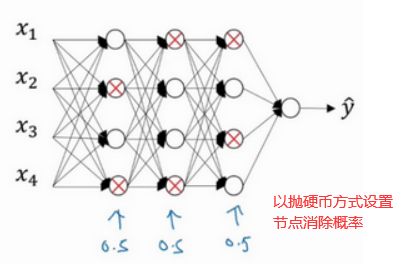

- 每层每个节点以某一概率(这里以50%为例)被选中为需要删除的节点(如下图中标上X的节点)
- 被选中为删除的节点,不仅要删除节点,与之相连的线段也要删除
- 使用反向传播算法对精简后的神经网络进行权重更新计算
- 恢复被删节点,然后循环往复上面的步骤,直到得到我们想要的结果
2. inverted dropout(反向随机失活)-- 较为常用:
- keep-prob:保留某个隐藏单元的概率,意味着消除任意一个隐藏单元的概率是1-(keep-prob)。作用就是生成随机矩阵
- a3表示三层网络各节点的值, a3=[a[1],a[2],a[3]].
- d3表示一个三层的dropout向量,其维度与a3相同,用python实现如下:
keepProb = 0.8
# d3元素值为True或False
d3 = np.random.rand(a3.shape[0], a3.shape[1]) < keepProb
# 在相乘运算时,python会自动将True转化为1,False转化为0
# 所以可以选出概率大于keepProb的节点继续留下来进行计算
a3 = np.multiply(a3, d3)
a3 /= keepProb
第四行代码:我们假设网络的隐藏层,即a[2]有50个units,那么按照keepProb=0.8可以知道需要删除10个units,也就是说a[2]会减少20%,那么我们在计算下一层,即 z [ 3 ] = w [ 3 ] a [ 2 ] + b [ 3 ] z[3]=w[3]a[2]+b[3] z[3]=w[3]a[2]+b[3]时就会使得z[3]的期望值(均值)发生变化,为了不影响z[3]的期望值,我们需要用 w [ 3 ] a [ 2 ] ÷ 0.8 w[3]a[2]÷0.8 w[3]a[2]÷0.8来修正或弥补我们所需的20%。
3. 补充说明
- 在测试阶段,我们不需要再使用dropout,而是像之前一样直接将各层的权重,偏差带入计算出预测值即可
- keepProb也可以是跟着各层节点数变化的,以下面的神经网络为例

可知第二层的系数最多,所以最有可能造成过拟合,所以该层的keepProb应该取得比较小,如0.5而其他的层则可以取为0.8 ,对于完全不会产生过拟合的就可以取1.
1.7 理解 dropout(Understanding Dropout)
为什么dropout可以起到正则化的作用呢:
- 理解一:不要依赖于任何一个特征,因为该单元的输入可能随时被清除,因此该单元通过这种方式传播下去,并为单元的四个输入增加一点权重,通过传播所有权重,dropout将产生收缩权重的平方范数的效果,和 L 2 L_2 L2正则化相似,但dropout更适用于不同的输入范围。与 L 2 L_2 L2不同权重的衰减是不同的,它取决于倍增的激活函数的大小。
- 理解二:因为每个节点都有可能被消除,所以一般都不会给任何一个输入加给太多的权重。例如状态perfect的节点被随机消除后,其他节点就要更大的调节,慢慢优化整体的效果。
1.8 其他正则化方法(Other regularization methods)
- 数据扩增,即对原有数据集进行如下操作生成新一批数据集:
- 水平翻转
- 随意裁剪图片
- 添加数字
- 随意旋转
- 扭曲数字
- early stopping

训练过程中在中间点就停下来。
- 缺点:early stopping的主要缺点就是你不能独立地处理这两个问题,因为提早停止梯度下降,也就是停止了优化代价函数,因为现在你不再尝试降低代价函数,所以代价函数的值可能不够小,同时你又希望不出现过拟合,你没有采取不同的方式来解决这两个问题
- 优点:只运行一次梯度下降,你可以找出 w w w的较小值,中间值和较大值,而无需尝试 L 2 L_2 L2正则化超级参数的很多值。
1.9 归一化输入(Normalizing inputs)
- 应用情景与实施方法
-
应用情景:数据集有多维特征,而各个特征取值范围不同时,需要使用归一化加快算法运行。
-
实施步骤
如下例,假设数据集有两个特征x1,x2。其中 x 1 ∈ ( 0 , 5 ) , x 2 ∈ ( 1 , 2 ) x_1\in (0,5),x_2 \in (1,2) x1∈(0,5),x2∈(1,2)

-
零均值化: x : = x − μ x:=x- \mu x:=x−μ,即移动数据集。其中 μ = 1 m ∑ i = 1 m x ( i ) \mu = \dfrac{1}{m}\displaystyle\sum_{i=1}^{m}x^{(i)} μ=m1i=1∑mx(i)为一个向量。
-
归一化方差: x 1 x_1 x1方差比 x 2 x_2 x2的要大得多, x : = x / σ 2 x:=x/\sigma^2 x:=x/σ2,其中 σ = 1 m ∑ i = 1 m ( x ( i ) ) 2 \sigma = \dfrac{1}{m}\displaystyle\sum_{i=1}^{m}(x^{(i)})^2 σ=m1i=1∑m(x(i))2
注意:用相同的 μ , σ \mu,\sigma μ,σ来归一化测试集和训练集
- 为什么归一化输入特征:
以二维特征为例:

- 不使用归一化:代价函数将会变得非常细长狭窄,因为输入特征值在不同范围,参数 w 1 , w 2 w_1,w_2 w1,w2的范围或比率将会非常不同,那么在使用梯度下降法寻找最小值的时候,需要使用很小的步长,算法要反复执行才能找到最小值。
- 使用归一化:代价函数是一个匀称的球形轮廓,不论从那个位置开始,梯度下降法中可以使用较大步长,能更快地找到最小值。
1.10 梯度消失/梯度爆炸(Vanishing / Exploding gradients)

![]()
-
假设每个权重矩阵
W [ l ] = [ 1.5 0 0 1.5 ] W^{[l]} = \begin{bmatrix} 1.5 & 0\\ 0 & 1.5 \end{bmatrix} W[l]=[1.5001.5]
最后计算结果就是 y ^ = 1. 5 ( L − 1 ) x \hat y = 1.5^{(L-1)}x y^=1.5(L−1)x,对于一个深度网络来说, L L L值越大,最后 y ^ \hat y y^呈指数爆炸式增长,增长比率为 1. 5 L 1.5^L 1.5L -
相反,假设每个权重矩阵
W [ l ] = [ 0.5 0 0 0.5 ] W^{[l]} = \begin{bmatrix} 0.5 & 0\\ 0 & 0.5 \end{bmatrix} W[l]=[0.5000.5]
最后计算结果就是 y ^ = 0. 5 ( L − 1 ) x \hat y = 0.5^{(L-1)}x y^=0.5(L−1)x,对于一个深度网络来说, L L L值越大,最后 y ^ \hat y y^以指数级递减,递减比率为 0. 5 L 0.5^L 0.5L,此时梯度下降算法的步长会非常非常小,梯度下降算法将花费很长时间来学习。
1.11 神经网络的权重初始化(Weight Initialization for Deep NetworksVanishing / Exploding gradients)

为了预防z值过大或过小,n越大则需要w越小
![]()
- 如果用的是Sigmoid激活函数,设置 w i = 1 n w_i = \dfrac{1}{n} wi=n1,即

- 如果用的是Relu激活函数,设置 w i = 2 n w_i = \dfrac{2}{n} wi=n2
- 如果用的是tanh激活函数,设置 w i = 1 n [ l − 1 ] w_i = \sqrt\dfrac{1}{n^{[l-1]}} wi=n[l−1]1
1.12 梯度的数值逼近(Numerical approximation of gradients)

- 预估梯度时,通过这个绿色大三角形同时考虑了这两个小三角形,所以我们得到的不是一个单边公差而是一个双边公差。
- 使用双边误差的方法更逼近导数,而且在梯度检验和反向传播中使用该方法时,它与运行两次单边公差的速度一样。所以在执行梯度检验时,我们使用双边误差,即 f ( θ + ϵ ) − f ( θ − ϵ ) 2 ϵ \dfrac{f(\theta+\epsilon)-f(\theta-\epsilon)}{2\epsilon} 2ϵf(θ+ϵ)−f(θ−ϵ),而不使用单边公差,因为它不够准确。
1.13 梯度检验(Gradient checking/Grad check)
步骤:
-
将参数 W [ l ] , b [ l ] , l ∈ ( 1 , L ) W^{[l]},b^{[l]},l \in (1,L) W[l],b[l],l∈(1,L)转换为向量 θ \theta θ,那么代价函数就是关于 θ \theta θ的一个函数 J ( θ ) J(\theta) J(θ)
-
将参数 d W [ l ] , d b [ l ] , l ∈ ( 1 , L ) dW^{[l]},db^{[l]},l \in (1,L) dW[l],db[l],l∈(1,L)转换为向量 d θ d\theta dθ,因为 d W [ l ] . s h a p e = W [ l ] . s h a p e , d b [ l ] . s h a p e = b [ l ] . s h a p e dW^{[l]}.shape = W^{[l]}.shape,db^{[l]}.shape = b^{[l]}.shape dW[l].shape=W[l].shape,db[l].shape=b[l].shape,所以 d θ . s h a p e = θ . s h a p e d\theta.shape = \theta.shape dθ.shape=θ.shape
-
怎么检验神经网络的梯度实施是否正确?该问题等价于“ d θ d\theta dθ和代价函数 J J J的梯度或坡度有什么关系”
-
使用双边误差计算 d θ a p p r o x [ i ] d\theta_{approx}[i] dθapprox[i]:

理论来说, d θ a p p r o x [ i ] ≈ d θ [ i ] = ∂ J ∂ θ i d\theta_{approx}[i] \approx d\theta[i] = \dfrac{\partial J}{\partial \theta_i} dθapprox[i]≈dθ[i]=∂θi∂J -
验证这些向量是否彼此接近:

注意这里 ∣ ∣ d θ a p p r o x − d θ ∣ ∣ 2 ||d\theta_{approx}-d\theta||_2 ∣∣dθapprox−dθ∣∣2没有平方,它是误差平方之和,然后求平方根,得到欧式距离,然后用向量长度归一化,使用向量长度的欧几里得范数。分母只是用于预防这些向量太小或太大,分母使得这个方程式变成比率。 -
取 ϵ = 1 0 − 7 \epsilon = 10^{-7} ϵ=10−7来计算上一步的式子。
- 若结果 ≤ 1 0 − 7 \le 10^{-7} ≤10−7意味着梯度计算实施正确。
- 若结果在 1 0 − 5 10^{-5} 10−5范围内,就要小心了,也许这个值没问题,但Andrew Ng会再次检查向量 θ \theta θ 的所有项,确保没有一项误差过大,可能这里有bug。
- 若结果在 ≥ 1 0 − 3 \ge10^{-3} ≥10−3范围内,就要担心是否存在bug。这时应该仔细检查 θ \theta θ所有项,看是否有一个具体的 i i i 值,使得 d θ a p p r o x [ i ] 与 d θ [ i ] d\theta_{approx}[i] 与 d\theta[i] dθapprox[i]与dθ[i]大不相同,并用它来追踪一些求导计算是否正确,经过一些调试,最终结果会是这种非常小的值( 1 0 − 7 10^{-7} 10−7),那么,你的实施可能是正确的。
1.14 梯度检验应用的注意事项(Gradient Checking Implementation Notes)

- 不要在训练中使用梯度检验,它只用于调试
- 如果算法的梯度检验失败,要检查所有项,检查每一项,并试着找出bug
- 在实施梯度检验时,如果使用正则化,请注意不要遗漏正则项

- 梯度检验不能与dropout同时使用,因为每次迭代过程中,dropout会随机消除隐藏层单元的不同子集,难以计算dropout在梯度下降上的代价函数。因此dropout可作为优化代价函数的一种方法,但是代价函数J被定义为对所有指数极大的节点子集求和。而在任何迭代过程中,这些节点都有可能被消除,所以很难计算代价函数。
- 当w和b接近0时,梯度下降的实施是正确的,在随机初始化过程中……,但是在运行梯度下降时,w和b变得更大。可能只有在w和b接近0时,backprop的实施才是正确的。但是当W和b变大时,它会变得越来越不准确。你需要做一件事,我(Andrew)不经常这么做,就是在随机初始化过程中,运行梯度检验,然后再训练网络,w和b会有一段时间远离0,如果随机初始化值比较小,反复训练网络之后,再重新运行梯度检验。
第二周:优化算法 (Optimization algorithms)
2.1 Mini-batch 梯度下降(Mini-batch gradient descent)
- 三种梯度下降算法
- Batch Gradient Descent:同时处理整个训练集
- Mini-Batch Gradient Descent:将训练集分批处理
- Stochastic Gradient Descent:每次只处理一个数据集
- Mini-Batch Gradient Descent
- mini-batch(每批数据集大小)最好是2的次方
- 确保mini-batch大小与你使用的CPU/GPU大小相符