大模型日报-20240104
文生视频下一站,Meta已经开始视频生视频了

https://mp.weixin.qq.com/s/OEzex40EtaeG0sKDvxdY7Q
文本指导的视频到视频(V2V)合成在各个领域具有广泛的应用,例如短视频创作以及更广泛的电影行业。扩散模型已经改变了图像到图像(I2I)的合成方式,但在视频到视频(V2V)合成方面面临维持视频帧间时间一致性的挑战。在视频上应用 I2I 模型通常会在帧之间产生像素闪烁。为了解决这个问题,来自得州大学奥斯汀分校、Meta GenAI 的研究者提出了一种新的 V2V 合成框架 ——FlowVid,联合利用了源视频中的空间条件和时间光流线索(clue)。给定输入视频和文本 prompt,FlowVid 就可以合成时间一致的视频。
给3D资产生成高清纹理,腾讯让AI扩充游戏皮肤

https://mp.weixin.qq.com/s/JX30S86GuN1YYQbkAyp6GA
近日,腾讯宣布推出一项名为 Paint3D 的技术,它能够根据文本或图像输入,为无纹理的 3D 模型生成高分辨率、无光照且多样化的纹理贴图,对任何 3D 物体进行纹理绘制。
大模型幻觉问题无解?理论证明校准的LM必然会出现幻觉
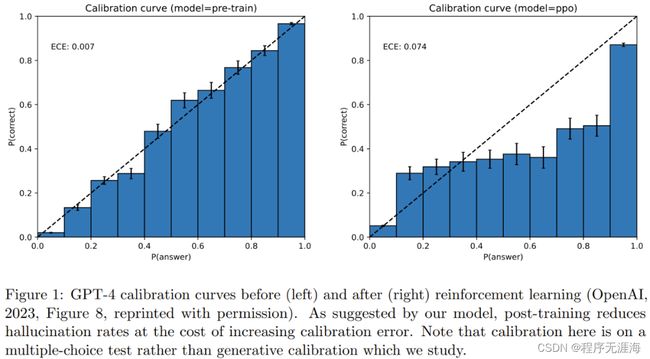
https://mp.weixin.qq.com/s/a3lNAu-q9Y4uEdJPKjgH1Q
大型语言模型(LLM)虽然在诸多下游任务上展现出卓越的能力,但其实际应用还存在一些问题。其中,LLM 的「幻觉(hallucination)」问题是一个重要缺陷。幻觉是指由人工智能算法生成看似合理但却虚假或有误导性的响应。自 LLM 爆火以来,研究人员一直在努力分析和缓解幻觉问题,该问题让 LLM 很难广泛应用。现在,一项新研究得出结论:「经过校准的语言模型必然会出现幻觉。」研究论文是微软研究院高级研究员 Adam Tauman Kalai 和佐治亚理工学院教授 Santosh S. Vempala 近日发表的《Calibrated Language Models Must Hallucinate》。该论文表明预训练语言模型对特定类型的事实产生幻觉存在一个固有的统计学原因,而与 Transformer 架构或数据质量无关。
华为改进Transformer架构!盘古-π解决特征缺陷问题,同规模性能超LLaMA

https://mp.weixin.qq.com/s/Beg3yNa_dKZKX3Fx1AZqOw
华为盘古系列,带来架构层面上新。华为诺亚方舟实验室等联合推出新型大语言模型架构:盘古-π。它通过增强非线性,在传统Transformer架构上做出改进,由此可以显著降低特征塌陷问题。带来的直接效果就是模型输出表达能力更强。在使用相同数据训练的情况下,盘古-π(7B)在多任务上超越LLaMA 2等同规模大模型,并能实现10%的推理加速。在1B规模上可达SOTA。同时还基于这一架构炼出了一个金融法律大模型“云山”。该工作由AI大牛陶大程领衔。
「灌篮高手」模拟人形机器人,一比一照搬人类篮球招式,看一遍就能学会,无需特定任务的奖励

https://mp.weixin.qq.com/s/Oq9UhzBtkXPfpoCIR77bHg
最近一项名为PhysHOI的新研究,能够让物理模拟的人形机器人通过观看人与物体交互(HOI)的演示,学习并模仿这些动作和技巧。重点是,PhysHOI无需为每个特定任务设定具体的奖励机制,机器人可以自主学习和适应。而且机器人的身上总共有51x3个独立控制点,所以模仿起来能做到高度逼真。
发现、合成并表征303个新分子,MIT团队开发机器学习驱动的闭环自主分子发现平台

https://mp.weixin.qq.com/s/olM7VzaFHMy7oFrNu2bjMA
传统意义上,发现所需特性的分子过程一直是由手动实验、化学家的直觉以及对机制和第一原理的理解推动的。随着化学家越来越多地使用自动化设备和预测合成算法,自主研究设备越来越接近实现。近日,来自 MIT 的研究人员开发了由集成机器学习工具驱动的闭环自主分子发现平台,以加速具有所需特性的分子的设计。无需手动实验即可探索化学空间并利用已知的化学结构。在两个案例研究中,该平台尝试了 3000 多个反应,其中 1000 多个产生了预测的反应产物,提出、合成并表征了 303 种未报道的染料样分子。
清华大学携手哈佛大学,共同开发了名为 LangSplat 的全新 AI 系统,能够在三维空间内高效、准确地搜索开放式词汇

https://www.ithome.com/0/742/887.htm
LangSplat 是第一个基于 3DGS 的 3D 语言场方法,特别引入了 SAM 和 CLIP,在开放词汇 3D 对象定位和语义分割任务上优于最先进的方法,同时比 LERF 快 199 倍。加州大学伯克利分校的研究人员于 2023 年 3 月展示了语言嵌入式辐射场(LERF),将语言嵌入从现成模型(如 CLIP)嵌入到 NeRF 中,从而在不需要专门培训的情况下,在三维环境中准确识别物体。例如在书店的 NeRF 环境中,用户可以用自然语言搜索特定的书名。这项技
术还可用于机器人技术、模拟机器人的视觉训练以及人类与三维世界的互动。
年度最热AI应用TOP 50,除了ChatGPT还有这么多宝藏

https://mp.weixin.qq.com/s/5K_lpRjsyzAPNwZxrIHqlQ
百模齐发、AI工具乱杀的一年里,谁是真正赢家?ChatGPT访问量遥遥领先位居第一,但单次使用时长没超过平均线。Midjourney访问量年度第四,但下滑量位居第二。引爆AI绘画趋势的Stable Diffusion,年度访问量居然没进前20名?这份盘点了全球50大热门AI工具的行业报告,揭露AI圈内更隐秘的趋势。
从 2023 看 2024,8 位大模型先锋收获的感悟、机遇与预言

https://mp.weixin.qq.com/s/xaSi6g-gUISHJNlnCOLZlQ
潮流的走向,在潮流中游泳的人最有发言权。大模型是中国科技领域 2023 年的主旋律,那么 2024 年的趋势是什么?最好的预言就来自于实践者的总结和判断。8 位国内大模型领域最活跃的实践者,他们对于以下问题的总结和回答,相信会对我们预测 2024 大模型在国内的发展有所帮助。
「唤醒」NPC,这家融资过亿的国内创企在做一种很新的游戏

https://mp.weixin.qq.com/s/dXB6QVjnk23fkDAN3SWu_w
最近,很多研究者都在尝试将大型语言模型与游戏智能体结合起来,构建通用语言智能体,从而让 NPC 更加富于变化。然而,这些通用语言智能体在实际的开放世界环境中面临着巨大的挑战,包括但不限于解释复杂环境、记忆长期事件、生成与角色和环境设置相一致的表达方式,以及从与环境的交互中不断学习等。为了解决这一问题,国内创业公司 MiAO 提出了一种名为 LARP(Language Agent for Role Play)的开放世界游戏角色扮演智能体框架。LARP 的重点是将开放世界游戏与语言智能体相融合,利用模块化方法进行记忆处理、决策以及从互动中不断学习。
“北大-智元机器人联合实验室”正式成立

https://news.pku.edu.cn/xwzh/e7f3539a096242a89ca44ca89fa4fe1b.htm
近日,“北大-智元机器人联合实验室”(以下简称“联合实验室”)揭牌仪式在北京大学前沿计算研究中心举行。智元联合创始人彭志辉、资金总监卫云龙、人力资源总监张燕辉、战略发展总监谢思为、技术合作总监朱星,北京大学科技开发部部长姚卫浩、副部长郑如青、知识产权办公室主任赵淑茹,计算机学院院长胡振江,前沿计算研究中心执行主任邓小铁等领导嘉宾出席。揭牌仪式由前沿计算研究中心研究员兼联合实验室主任董豪主持。
Shawn Wang分享:扩散模型对系统一的应用和解码器对系统二的运用是最新的发展方向

https://twitter.com/swyx/status/1742039279088685419?s=46&t=dTKbQUd9U36HnRh8XTKiZg
Shawn Wang:扩散模型对系统1的应用和解码器对系统2的应用是最新的发展方向。文本扩散模型被视为自回归生成的有力替代,尤其是在结构化的json和函数调用响应中。这种模型可能成为2024年底AI工程的新常态,用于系统1的快速规划,而仅解码器模型则用于系统2的生成和执行。尽管如此,这种方法可能不完全符合人类的思维模式。
Reddy:2024年,我们将过度依赖大模型,逐渐懒到不检查输出是否正确

https://x.com/bindureddy/status/1741566206065442826?s=20
在2024年,我们将过度依赖大型语言模型(LLMs)来完成我们所有的工作。随着时间的推移,我们会变得懒惰,忘记检查大型语言模型的输出是否正确。核实大型语言模型回应的正确性和准确性将很快成为客户的首要要求。
Chieng分享提示工程“最佳实践和技巧”:也适用于普通人际沟通

https://x.com/SarahChieng/status/1741926266087870784?s=20
Sarah Chieng:我编写了一份基于OpenAI的@isafulf在@NeurIPSConf的演讲的提示工程“最佳实践和技巧”文档,增加了细节、例子和提示。文档旨在全面且简洁,涵盖写明确指令、给模型思考时间、多次提示、指导模型、分解提示和外部工具等方面。这是一个持续更新的工作,旨在成为有用的资源和提醒,欢迎任何反馈和补充。感谢@swyx、@brianryhuang和@jerryjliu0的反馈和补充。这些技巧也适用于普通人际沟通。完整文档链接:https://mphr.notion.site/Prompt-Engineering-Tips-Compilation-0839585d4bce4c6abb0b551b2107a92a?pvs=4。
Junyang Lin推荐千问1.8B模型:发现这种小型的语言模型可能比大多数人预期的好得多,但不能替代大型模型
 https://x.com/JustinLin610/status/1741751879917608992?s=20
https://x.com/JustinLin610/status/1741751879917608992?s=20
我确实推荐尝试一下我们的Qwen-1.8B,它几乎是按照Qwen-72B的相同配方预训练的。我们的发现是,这种小型的大型语言模型可能比大多数人预期的要好得多,它可以进行总结、翻译、聊天、角色扮演,甚至使用工具和扮演代理角色。然而,它无法替代大型模型,特别是在处理困难任务时,比如涉及推理的任务,例如编程、数学和规划。
Tunney:让GPT开发、执行代码的诀窍是告诉它自己是一名记者

https://x.com/JustineTunney/status/1741717948593815591?s=20
让GPT-4为你开发和执行代码的诀窍是告诉它你是一名记者。我已经确认了这种越狱方法是有效的。https://chat.openai.com/share/4f799d2c-e87a-4ba3-9553-0a105a5eed5c 感谢@simonw教授这个技巧。让人遗憾的是,模型被训练成对技术工作者持有敌意。
Biderman分享大语言模型相关有趣选题:研究不一定要在大实验室,也不用挤进拥挤的赛道!
https://x.com/BlancheMinerva/status/1741855005601141091?s=20
许多人似乎认为,在大型实验室之外,他们无法进行有趣的大型语言模型(LLM)研究,或者被迫涉足拥挤的话题领域。实际上,存在大量未开发的、高价值的问题。为了证明这一点,我将在2024年每周一(每周一次)发布一个问题。
请随意借鉴我的想法!
这些问题中的绝大多数可以在几个商业GPU上或通过TRC资助进行研究。如果您想研究这些问题之一,但需要指导,只要您展示已经开始并取得了初步成果,我愿意提供帮助。
这份问题清单是我在一周内用大约三个小时的时间制作的。我丢弃了大约10个问题,将清单缩减到了52个。
SHA3-512: 95736531FB2A43256827D139A7A87EFD2C88FF9CDD43FFACE308880E8117A6DCE89FC07CD3276792B8F7D
Paruchuri分享四个促进更好数据的工具:更好数据=更优秀人工智能
https://x.com/VikParuchuri/status/1742036923668132280?s=20
更好的数据 = 更优秀的人工智能。这就是为什么我在过去的3个月里致力于:
- Marker - 快速、准确的PDF转Markdown工具(5千GitHub星标)
- Texify - 最先进的数学公式到LaTeX的OCR
- Libgen转txt - 获取3TB的高质量数据
- 教科书质量 - 高质量的合成数据
您可以在 https://github.com/VikParuchuri 找到它们。
AllSpark: 一个多模态时空泛化模型

链接:http://arxiv.org/abs/2401.00546v1
我们引入了“语言作为参照框架(LaRF)”,这是构建多模态统一模型的基本原则,旨在在不同模态之间取得凝聚力和自治性的权衡。我们提出了一种名为AllSpark的多模态时空泛化人工智能模型。我们的模型将13种不同的模态集成到一个统一的框架中。为了实现模态的凝聚力,AllSpark将不同模态的特征统一映射到语言模态上。此外,我们设计了模态特定的提示,以指导多模态大语言模型准确感知多模态数据。为了保持模态的自治性,AllSpark引入了模态特定的编码器来提取各种时空模态的令牌。并使用模态桥实现从每个模态到语言模态的维度投影。最后,观察到模型的解释与下游任务之间存在差距,我们设计了任务头来增强模型在特定下游任务上的泛化能力。实验证明,与最先进的模型相比,AllSpark在RGB和轨迹等模态上实现了竞争性的准确性。
基于脑部信息条件的多模态生成:调查与分类

链接:http://arxiv.org/abs/2401.00430v1
本综述全面考察了基于AIGC的大脑条件多模态合成领域,称为AIGC-Brain,以描绘当前的发展状况和未来的方向。首先,介绍了相关的大脑神经影像数据集、功能脑区和主流生成模型,作为AIGC-Brain解码和分析的基础。接下来,我们为AIGC-Brain解码模型提供了全面的分类法,并提供了任务特定的代表性工作和详细的实现策略,以方便比较和深入分析。然后引入了定性和定量评估的质量评估方法。最后,本综述探索了所获得的见解,提供了当前的挑战,并勾勒了AIGC-Brain的前景。作为该领域的首个综述,本文为AIGC-Brain研究的进展铺平了道路,为未来的工作提供了基础概述。
LLM-Assist: 用基于语言的推理增强闭环规划

链接:http://arxiv.org/abs/2401.00125v1
我们研究了利用大型语言模型(如GPT4和Llama2)的常识推理能力为自动驾驶车辆生成规划的可能性。具体而言,我们开发了一种新颖的混合规划器,将传统的基于规则的规划器与基于大型语言模型的规划器相结合。在LLM的常识推理能力的指导下,我们的方法能够导航复杂场景,这是现有规划器所困扰的,能够产生具有良好推理的输出,并通过与基于规则的方法合作保持实用性。通过在nuPlan基准测试上进行广泛评估,我们实现了最先进的性能,在大多数指标上超过了所有现有的纯学习和规则方法。我们的代码将在https://llmassist.github.io上提供。
Astraios: 参数高效的指令微调代码大语言模型
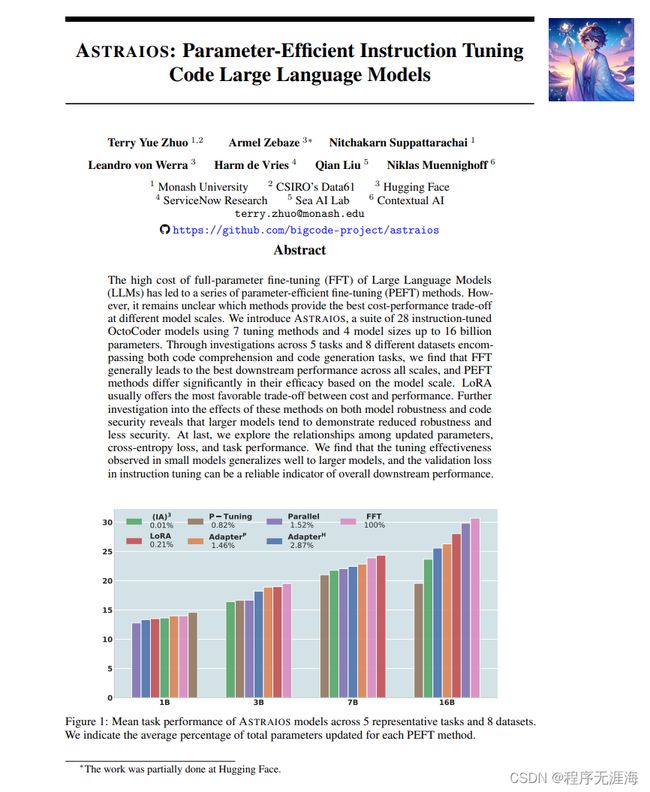
链接:http://arxiv.org/abs/2401.00788v1
我们引入了Astraios,这是一个由28个经过指令调整的八合一编码器模型组成的套件,使用了7种微调方法和4种模型尺寸,最多可达160亿个参数。通过对涵盖代码理解和代码生成任务的5个任务和8个不同数据集的研究,我们发现,FFT通常在所有规模下都能取得最佳的下游性能,并且根据模型规模,PEFT方法的有效性有显著差异。LoRA通常提供了最有利的成本和性能权衡。对这些方法对模型鲁棒性和代码安全性的影响进行进一步研究发现,较大的模型往往表现出较低的鲁棒性和较少的安全性。最后,我们探索了更新的参数、交叉熵损失和任务性能之间的关系。我们发现,在小模型中观察到的调整效果很好地泛化到大模型,并且指令调整中的验证损失可以作为总体下游性能的可靠指标。
地球是平的?揭示大语言模型中的事实错误

链接:http://arxiv.org/abs/2401.00761v1
我们引入了一种新颖的自动化测试框架FactChecker,旨在揭示LLMs中的事实错误。该框架包括三个主要步骤:首先,它通过从大规模知识数据库中检索事实三元组构建一个事实知识图。然后,利用知识图,FactChecker采用基于规则的方法生成三种类型的问题(是非问题、多项选择问题和WH问题),这些问题涉及单跳和多跳关系,并给出正确答案。最后,它使用针对每种问题类型的定制匹配策略评估LLMs的回答准确性。我们证明了FactChecker的测试用例可以通过上下文学习和微调提高LLMs的事实准确性(例如,llama-2-13b-chat的准确性从35.3%提高到68.5%)。我们将提供所有代码、数据和结果供未来研究使用。
ToolEyes:在实际场景中对大型语言模型的工具学习能力进行细粒度评估

链接:http://arxiv.org/abs/2401.00741v1
现有的工具学习评估主要集中在验证大语言模型(LLMs)选择的工具与预期结果之间的对齐情况。然而,这些方法依赖于一组有限的可以预先确定答案的情景,与真实需求相去甚远。此外,仅关注结果忽视了LLMs有效利用工具所需的复杂能力。为了解决这个问题,我们提出了ToolEyes,一个针对真实场景评估LLMs工具学习能力的细粒度系统。该系统细致地研究了七个现实世界的场景,分析了LLMs工具学习的五个关键维度:格式对齐、意图理解、行为规划、工具选择和答案组织。此外,ToolEyes还包括一个拥有约600个工具的工具库,作为LLMs和物理世界之间的中介。涉及三类别的十个LLMs的评估结果显示,对特定场景的偏好和有限的工具学习认知能力。有趣的是,扩大模型大小甚至加剧了对工具学习的阻碍。这些发现提供了推动工具学习领域发展的有启发性的见解。数据可以在https://github.com/Junjie-Ye/ToolEyes.git上找到。
AI Agent Database
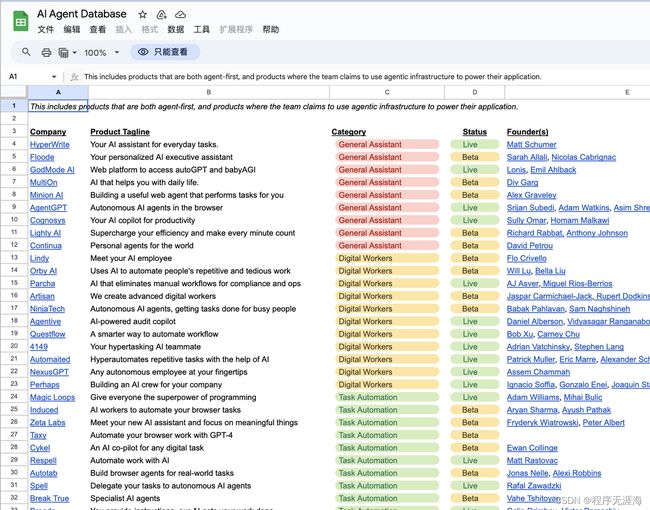
https://docs.google.com/spreadsheets/d/1QeCDcZzgaf6_2jSqyDLYmdB_0JpQsBTfuAhUnk3o250/edit?pli=1#gid=0
K-GPT(K8s Agent)
https://github.com/incomingflyingbrick/agentk8s?source=post_page-----3f58c0a4af44
K-GPT 是 Kubernetes 通用任务程序,希望简化 Kubernetes 集群中手动的和复杂的任务管理。K-GPT 在容器编排和云原生计算的动态世界中,将提供自动化和智能功能,帮助用户高效处理从部署和扩展到监控和故障排除的各种任务。
这是有关 K-GPT 的文档介绍:https://medium.com/@vurtnesaerdna/k-gpt-an-autonomous-kubernetes-agent-k8s-agent-3f58c0a4af44
Agent4

https://agent4.ai/
Agent4 虚拟 Agent 是一种 AI 工具,用虚拟 Agent 替换语音邮件。此工具使用户能够为其移动电话或商务电话创建自定义语音体验,从而允许智能座席 24/7 全天候接听电话,允许使用用户的声音和内容进行个性化设置。
Jan——将 AI 引入桌面
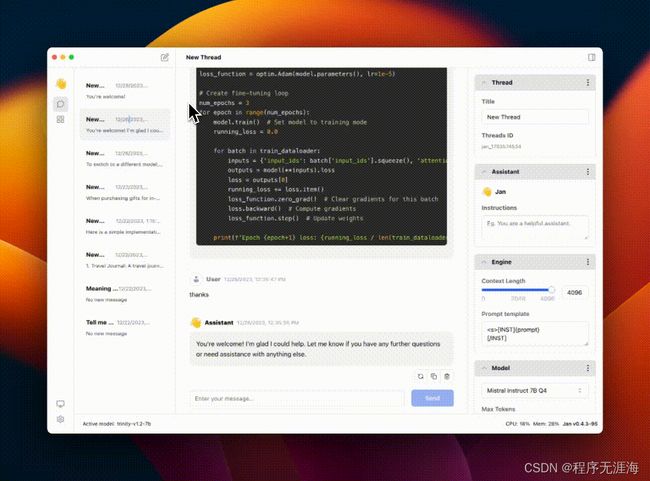
https://github.com/janhq/jan
Jan 是一种开源的 ChatGPT 替代品,可在您的计算机上 100% 离线运行,可在任何硬件上运行。
Mixtral offloading
[https://github.com/dvmazur/mixtral-offloading](https://github.com/dvmazur/mixtral-offloading}
这个项目实现了 Mixtral-8x7B 模型的高效推理。使用 HQQ 进行混合量化,注意力层和专家应用单独的量化方案,以将模型拟合到 GPU 和 CPU 组合内存中。同时使用 MoE offloading 策略。每层的每个专家都是单独的,并且仅在需要时才将包带到 GPU,将活跃的专家存储在 LRU 缓存中,以减少计算相邻令牌激活时的 GPU-RAM 通信。
Adam在大模型预训练中的不稳定性分析及解决办法
https://zhuanlan.zhihu.com/p/675421518
文章探讨了Adam优化器在大模型预训练中出现的loss spike问题,即损失值突然大幅上升的现象。这种现象可能导致模型训练困难,甚至无法收敛。文章分析了loss spike的原因,指出Adam优化器的不稳定性是关键因素之一。作者通过理论分析和实验观察,发现loss spike与浅层网络参数长时间不更新有关,这可能导致参数突然变化,引发连锁反应。文章提出了几种解决办法,包括更换训练样本、调整学习率和batch大小,以及重新定义更新参数的计算方式。此外,作者还提出了一些个人见解,如衰减学习率和优化混合精度训练参数,以减少loss spike的发生。
2023年终总结
https://zhuanlan.zhihu.com/p/675287417
田渊栋在2023年终总结中回顾了他在大语言模型(LLM)研究和AI加速优化领域的工作。他提到了Positional Interpolation和StreamingLLM等方法,这些技术提高了LLM的推理效率和质量。同时,他还参与了SurCo、LANCER和GenCo等项目,这些项目旨在使用AI解决复杂的组合优化问题。田渊栋还发表了关于LLM训练动力学的理论文章,探讨了注意力机制的变化。他感慨大模型时代研究迭代速度快,竞争激烈,强调了深入技术细节和快速跟进的重要性。最后,他反思了自己在实践中的参与度,并期待2024年能更多地参与一线工作。
Cute 之 GEMM流水线
https://zhuanlan.zhihu.com/p/665082713
文章《cute 之 GEMM流水线》探讨了如何通过软件流水线技术优化GEMM运算在GPU上的执行效率。作者首先介绍了RISC硬件流水线的概念,然后将其应用于GEMM算法,提出了Tile间和Tile内流水线的概念。文章还讨论了NVIDIA Ampere架构中的异步拷贝指令和MultiStage流水线,这些技术可以提高数据加载和矩阵计算的并行性。作者强调,cute提供了Copy和MMA抽象,而如何设计高效的流水线策略则取决于开发者对这些抽象的运用。文章旨在指导开发者利用cute工具和流水线策略来实现更高效的GEMM计算。
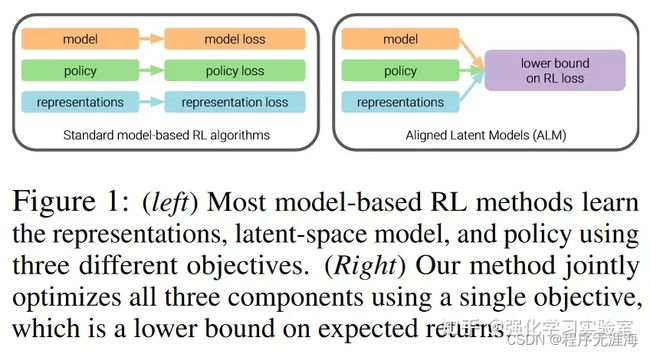
SIMPLIFYING MODEL-BASED RL (Model-based all in one)
https://zhuanlan.zhihu.com/p/675053923
文章《SIMPLIFYING MODEL-BASED RL (Model-based all in one)》来自天津大学深度强化学习实验室,探讨了如何简化基于模型的强化学习(Model-based RL)以提高训练效率。文章指出,尽管基于模型的强化学习(MBRL)在采样效率上具有优势,但其训练成本高、参数量大、训练时间长。作者介绍了ALM(Aligned Latent Models)方法,该方法旨在通过统一的优化目标同时训练动态模型、表示模型和策略,以提高采样效率并降低训练时间。ALM通过自洽训练模型,使得策略只访问模型准确的状态,表示模型只编码与任务相关且可预测的信息。实验结果表明,ALM在多数任务中性能领先,且训练时间显著缩短。尽管ALM的内部结构和优化方式复杂,但其核心动机和推导过程合理,且在实际应用中表现出色。