分布式训练与主流并行范式
分布式训练(Distributed Training)
什么是分布式系统(Distributed System)

分布式系统由在多台机器上运行的多个软件组件组成。例如,传统的数据库运行在单机上。随着数据量变得非常大,单台机器无法再为企业提供理想的性能,尤其是在黑色星期五等网络流量可能意外高的情况下。为了应对这种压力,现代高性能数据库被设计为在多台机器上运行,它们协同工作,为用户提供高吞吐量和低延迟。
分布式系统的一项重要评估指标是可扩展性(scalability)。例如,当我们在4台机器上运行一个应用程序时,我们自然期望该应用程序的运行速度能够提高4倍。但由于通信开销和硬件性能差异,很难实现线性加速。因此,我们在实现应用程序时考虑如何使应用程序更快是很重要的。良好的算法设计和系统优化有助于提供优异的性能。有时,甚至可以实现线性和超线性(super-linear)加速。
机器学习为何需要分布式训练
早在 2012 年,AlexNet就赢得了 ImageNet 竞赛的冠军,它是在两块 GTX 580 3GB GPU 上训练的。如今,出现在顶级人工智能会议上的大多数模型都是在多个 GPU 上进行训练的。分布式训练无疑是研究人员和工程师开发人工智能模型时的常见做法。这一趋势背后有几个原因:
- 模型尺寸迅速增大。2015 年提出的 ResNet50 有 2000 万个参数, 2018 年提出的 BERT-Large 有 3.45 亿个参数, 2018 年提出的GPT-2 有 15 亿个参数,2020 年提出的 GPT-3 有 1750 亿个参数。很明显,模型尺寸随着时间呈指数级增长。目前最大的模型已经超过10000亿个参数。与较小的同类竞对相比,超大模型通常可以提供更优越的性能。
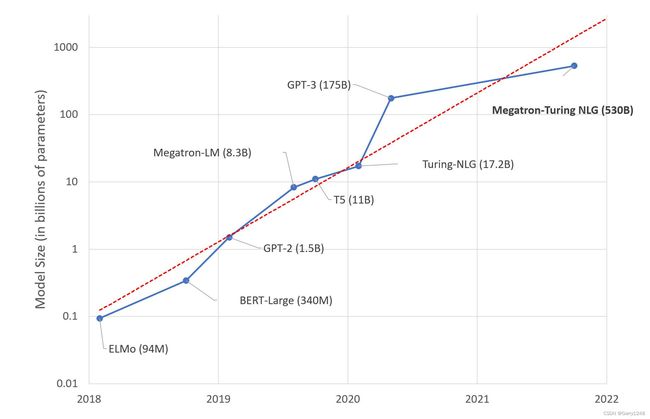
- 数据集尺寸迅速增加。对于大多数机器学习开发人员来说,MNIST 和 CIFAR10 数据集通常是他们训练模型的前几个数据集。然而,与众所周知的 ImageNet 数据集相比,这些数据集非常小。Google 甚至拥有自己的(未发布的)JFT-300M 数据集,其中包含约 3 亿张图像,这比 ImageNet-1k 数据集大了近 300 倍。
- 计算能力变得更强。随着半导体工业的进步,GPU变得越来越强大。由于其核心数量较多,GPU 成为深度学习最常见的计算平台。从2012年的K10 GPU到2020年的A100 GPU,算力提升了数百倍。这使我们能够更快地执行计算密集型任务,而深度学习正是这样的任务。
如今,模型可能太大而无法适应单个 GPU,而数据集可能大到足以在单个 GPU 上训练一百天。只有通过使用不同并行化技术在多个 GPU 上训练我们的模型,我们才能加快训练过程并在合理的时间内获得结果。
分布式训练的基本概念
分布式训练需要多台机器/GPU。在训练期间,这些设备之间将会进行通信。为了更好地理解分布式训练,有几个重要术语需要明确。
- 主机(host):主机是通信网络中的主要设备。初始化分布式环境时通常需要它作为参数。
- 端口(port):这里的端口主要是指主机上用于通信的主端口。
- 秩(rank):赋予网络中设备的唯一ID。
- 世界规模(world size):网络中设备的数量。
- 进程组(process group):进程组是包含设备子集的通信网络。始终有一个包含所有设备的默认进程组。子集设备可以形成进程组,以便它们仅在组内的设备之间进行通信。
下图是一个分布式系统示例:
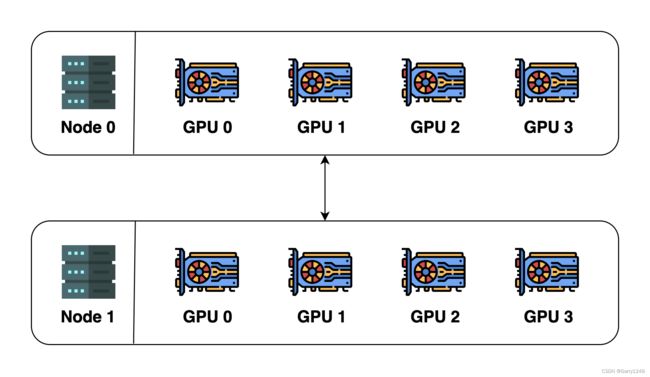
为了说明这些概念,我们假设我们有 2 台机器(也称为节点(node)),每台机器有 4 个 GPU。当我们在这两台机器上初始化分布式环境时,我们实际上启动了 8 个进程(每台机器上有 4 个进程),并且每个进程都绑定到一个 GPU。
在初始化分布式环境之前,我们需要指定主机(master地址)和端口(master端口)。在这个例子中,我们可以让主机为节点0,端口为一个数字,例如29500。然后所有8个进程都会查找地址和端口并相互连接。然后将创建默认进程组。默认进程组的世界大小为8,详细信息如下:
| 进程号 | 秩 | 节点索引 | GPU索引 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1 |
| 2 | 2 | 0 | 2 |
| 3 | 3 | 0 | 3 |
| 4 | 4 | 1 | 0 |
| 5 | 5 | 1 | 1 |
| 6 | 6 | 1 | 2 |
| 7 | 7 | 1 | 3 |
我们还可以创建一个新的进程组。这个新的进程组可以包含进程的任何子集。例如,我们可以创建一个仅包含偶数进程的组,该新组的详细信息将是:
| 进程号 | 秩 | 节点索引 | GPU索引 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 3 |
| 4 | 2 | 2 | 0 |
| 6 | 3 | 2 | 2 |
请注意,秩是相对于进程组而言的,一个进程在不同的进程组中可以具有不同的秩。最高秩始终为 (进程组的世界规模 - 1)。
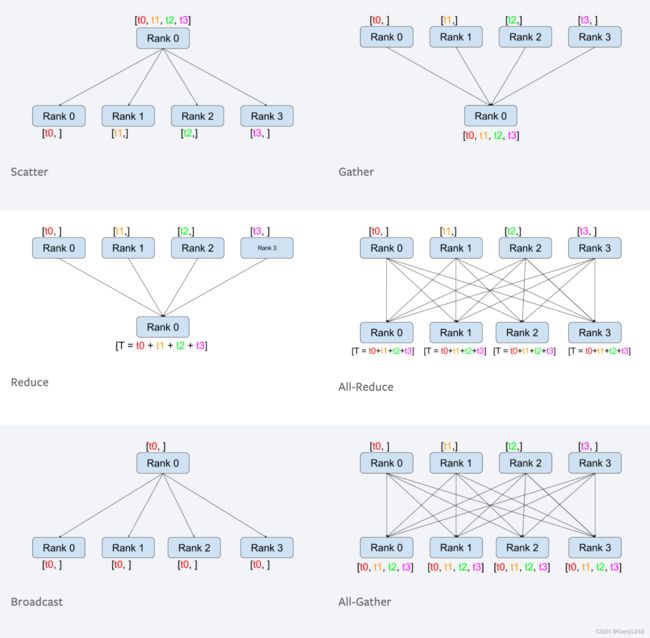
在进程组中,进程可以通过两种方式进行通信:
- 点对点(peer-to-peer):一个进程向另一个进程发送数据;
- 集合通信(collective):一组进程一起执行分散(scatter)、聚集(gather)、全归约( all-reduce)、广播(broadcast)等操作。
下图是Pytorch 分布式 tutorial 中的集合通信:
并行范式(Paradigms of Parallelism)
随着深度学习的发展,并行训练的需求越来越大。这是因为模型和数据集变得越来越大,如果我们坚持使用单 GPU 训练,训练时间就会变成一场噩梦。在本节中,我们将简要概述现有的并行训练方法。
数据并行 (Data Parallel)
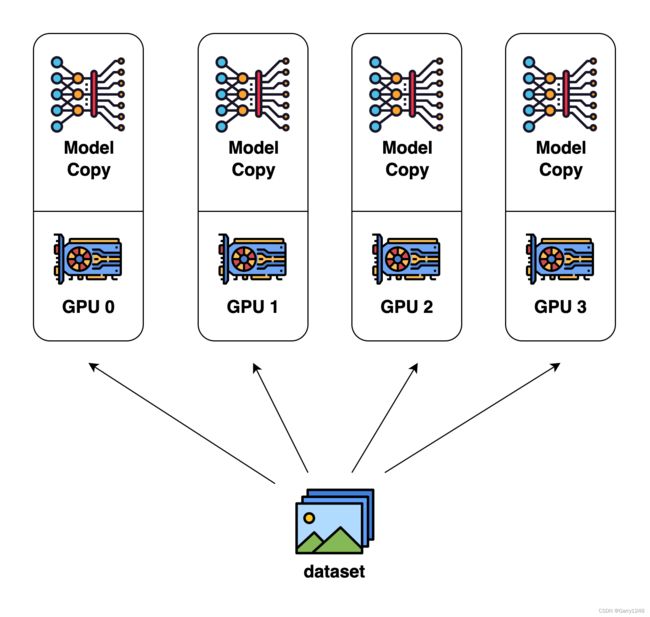
由于其简单性,数据并行是最常见的并行形式。在数据并行训练中,数据集被分成多个分片,每个分片分配给一个设备。这相当于沿着batch维度并行化训练过程。每个设备将保存模型副本的完整副本,并在分配的数据集分片上进行训练。经过反向传播后,模型的梯度将进行全规约(all-reduced),从而使不同设备上的模型参数保持同步。
模型并行(Model Parallel)
在数据并行训练中,一个突出的特点是每个GPU都保存整个模型权重的副本。这带来了冗余问题。并行性的另一个范例是模型并行性,其中模型被分割并分布在一系列设备上。一般有两种并行类型:张量并行和pipeline并行。张量并行是在矩阵乘法等运算中并行化计算。pipeline并行就是层与层之间的计算并行化。因此,从另一个角度来看,张量并行可以看作是层内并行,pipeline并行可以看作是层间并行。
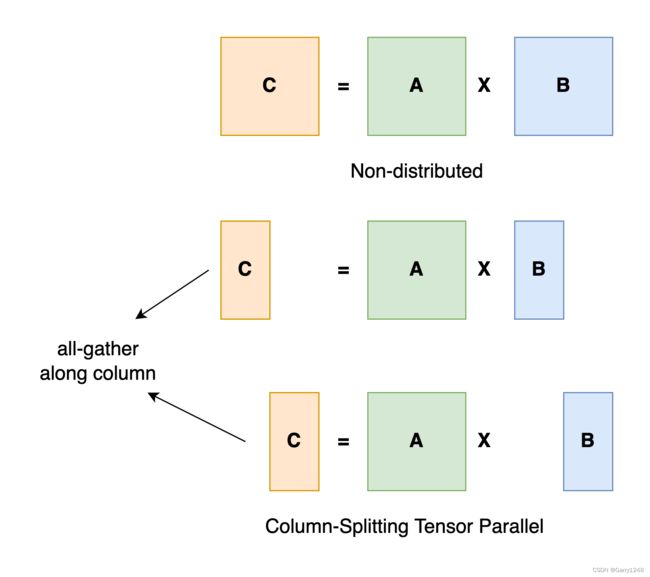
张量并行(Tensor Parallel)
张量并行训练是将张量沿特定维度分割成$$块,每个设备仅保存1/N 整个张量的 1 / N 1/N 1/N,而不影响计算图的正确性。这需要额外的通信以确保结果正确。
以一般矩阵乘法为例,假设 C = A B C = AB C=AB。我们可以沿着列维度将 B B B 拆分 [ B 0 B 1 B 2 . . . B n ] [B_0 B_1 B_2 ... B_n] [B0B1B2...Bn]为每个设备持有一个列。然后我们在每个设备上将 B B B的每一列乘以 A A A,我们将得到 [ A B 0 A B 1 A B 2 . . . A B n ] [AB_0 AB_1 AB_2 ... AB_n] [AB0AB1AB2...ABn]。此时,每个设备仍保存部分结果,例如秩为0的设备保存 A B 0 AB_0 AB0。为了确保结果正确,我们需要 all-gather 分部结果并沿列维度连接张量。通过这种方式,我们能够在设备上分配张量,同时确保计算流程保持正确。
Pipeline并行
Pipeline并行通常很容易理解。如果你回想一下你的计算机体系结构课程,这确实存在于 CPU 设计中。下图给出了pipeline并行示意图:

Pipeline并行的核心思想是将模型按层分割成多个块,每个块给一个设备。在前向传递期间,每个设备将中间激活传递到下一个阶段。在向后传递期间,每个设备将输入张量的梯度传递回前一个pipeline阶段。这允许设备同时计算,并增加训练吞吐量。流水线并行训练的一个缺点是,会存在一些设备进行计算的冒泡时间,导致计算资源的浪费。

优化器级并行(Optimizer-Level Parallel)
另一种范式工作在优化器级别,该范式当前最著名的方法是 ZeRO,它代表零冗余优化器。ZeRO 在三个级别上工作以消除内存冗余(ZeRO 需要 fp16 训练):
- 第 1 级:优化器状态跨进程划分;
- 第 2 级:用于更新模型权重的reduced 32-bit梯度也被划分,以便每个进程仅存储与其优化器状态分区相对应的梯度。
- 第 3 级:16-bit模型参数跨进程分区。
异构系统并行(Parallelism on Heterogeneous System)
上述方法一般需要大量GPU来训练大型模型。然而,人们经常忽视的是,与 GPU 相比,CPU 的内存要大得多。在典型的服务器上,CPU 可以轻松拥有数百 GB RAM,而每个 GPU 通常只有 16 或 32 GB RAM。这促使社区思考为什么不利用 CPU 内存进行分布式训练。
最近的进展依赖 CPU 甚至 NVMe 磁盘来训练大模型。主要思想是在张量不使用时将其offload回 CPU 内存或 NVMe 磁盘。通过使用异构系统架构,可以在单台机器上容纳巨大的模型。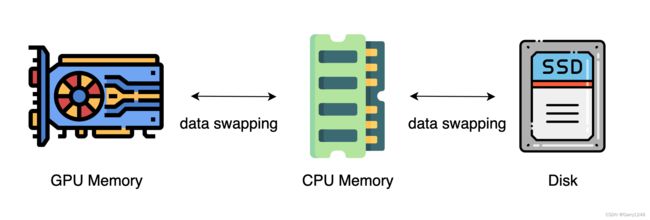
参考资料:
[1] https://colossalai.org/docs/concepts/distributed_training
[2] https://insujang.github.io/2022-06-11/parallelism-in-distributed-deep-learning/