【数据库原理】(10)数据定义功能
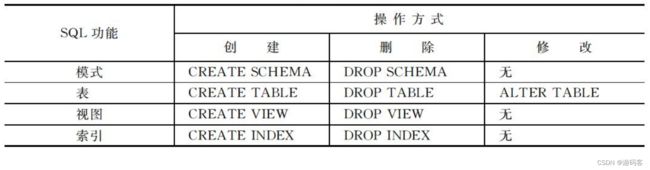
SQL 数据定义功能包括定义模式、定义表、定义索引和定义视图,其语句如表所示。
一.创建、删除模式
1.创建模式 (Create Schema)
用途:创建模式是为了在数据库中定义一个新的命名空间,它可以包含多个数据库对象。
语法:
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>;
只有获得了授权的用户才能创建模式。
示例:
用户 Li 定义一个数据库模式“教学管理”EM:
CREATE SCHEMA "EM" AUTHORIZATION Li;
如果没有指定模式名,那么模式名隐含为用户名,请看下面的例子:
用户 Li 定义一个数据库模式“Li”
CREATE SCHEMA AUTHORIZATION Li;
2.删除模式 (Drop Schema)
用途:删除一个现有的模式以及其包含的所有数据库对象。
语法:
DROP SCHEMA <模式名> <CASCADE|RESTRICT>
其中 CASCADE 和 RESTRICT 必选其一。
选项:
CASCADE:(级联)删除模式及其包含的所有对象。RESTRICT:(限制)仅当模式中没有关联对象时,才能删除模式。
示例:
- 删除模式 “EM” 及其所有对象:
DROP SCHEMA "EM" CASCADE;
注意事项
- 权限:只有具有相应权限的用户才能创建或删除模式。
- 影响:删除模式可能会影响到依赖于该模式中对象的其他数据库组件。
- 数据库系统差异:不同的数据库系统对模式的支持可能会有所差异,尤其是在命名约定和权限管理方面。
二.创建、删除、修改基本表
**1.创建基本表
目的:在数据库中定义一个新表,包括列名、数据类型及可能的完整性约束条件。
格式:
CREATE TABLE <基本表名>(
<列名 1><数据类型> [列名 1的列级完整性约束条件]
[,<列名 2><数据类型> [列名 2 的列级完整性约束条件]
...
,<列名 n> <数据类型>[列名 n 的列级完整性约束条件]]
[
,<表级完整性约束条件 1 >
[,<表级完整性约束条件 2>]
...
[,<表级完整性约束条件 m>]
]
- 表名:要定义的新表的名称。
- 列:由列名、数据类型和可选的列级完整性约束组成。
- 完整性约束:保证数据的准确性和可靠性,如主键、外键等。
示例
创建课程表 C
- 包含课程编号、名称、学分和前导课程编号。
- 课程编号为主键,不允许为空且唯一;课程名称唯一。
CREATE TABLE C(
Cno CHAR(3) NOT NULL UNIQUE,/* 列级完整性约束条件,Cno 不空且唯一 */
Cname CHAR(20) UNIQUE,/* 列级完整性约束条件,Cname 唯一*/
Cpno CHAR(3),
Ccredit INT
);
系统执行上面的 CREATE TABLE 语句后,就在数据库中建立了一个新的空的“课程表”C,并将有关“课程表”的定义及有关约束条件存放在数据字典中。
定义表的各个属性时需要指明其数据类型及长度。
建立一个“课程表”C 的同时先行课是自身的外码。
CREATE TABLE C(
Cno CHAR(3) PRIMARY KEY, /* 表级完整性约束条件 */
Cname CHAR(20) UNIQUE, /*表级完整性约束条件 */
Cpno CHAR(3),/*先行棵*/
Ccredit INT,
FOREIGN KEY (Cpno) REFERENCES C(Cno) /* 表级完整性约束条件 */
);
创建学生表 S
- 包含学号、性别、年龄和班级。
- 学号为主键。
CREATE TABLE S(
Sno CHAR(10) PRIMARY KEY,/*列级完整性约束条件,Sno 是主码 */
Ssex CHAR(1),
Sage INT,
Sclass CHAR(6)
);
创建选修表 SC
- 包含学号、课程编号和成绩。
- 学号和课程编号联合主键,分别引用学生表和课程表。
CREATE TABLE SC(
Sno CHAR(10),
Cno CHAR(3),
Grade INT,
PRIMARY KEY(Sno,Cno),
FOREIGN KEY(Sno) REFERENCES S(Sno),/* 表级完整性约束条件 */
FOREIGN KEY(Cno) REFERENCES C(Cno)/* 表级完整性约束条件 */
)
2.修改基本表
目的:
对已存在的表结构进行调整,包括增加列、修改列定义或删除完整性约束。
ALTER TABLE <表名>
[ ADD<新列名><数据类型>[完整性约束]]
DROP <完整性约束名>]
[ MODIFY <列名><数据类型>];
- 表名:指定需要修改的表。
- ADD:用于增加新列或完整性约束。
- DROP:用于删除指定的完整性约束。
- MODIFY:用于修改列的数据类型。
示例
向表 C 增加列
- 增加名为
Ctype的列,数据类型为定长字符串。
ALTER TABLE C ADD Ctype CHAR(16);
删除列级完整性约束
- 删除课程名称
Cname的唯一性约束。
ALTER TABLE C DROP UNIOUE Cname;
修改列的数据类型
- 将选修表 SC 中的
Grade列的数据类型改为浮点型。
ALTER TABLE SC MODIFY Grade FLOAT(4);
3.删除基本表
目的:从数据库中完全移除一个表及其数据。
删除表的一般格式
DROP TABLE <表名>[];
- 表名:指定要删除的表。
- CASCADE:删除表及其相关的所有依赖对象(如视图、触发器等),谨慎使用。
- RESTRICT:缺省情况是 RESTRICT,仅在没有任何依赖关系时允许删除表。
示例:
删除名为 C 的表:
DROP TABLE C;
注意事项
- 使用 CASCADE 选项时需格外小心,因为它会删除所有依赖于该表的数据库对象,可能导致数据丢失或完整性问题。
- RESTRICT 选项确保在表有任何外部依赖(如外键引用、视图或存储过程)时阻止删除操作,以保持数据库的完整性。
- 不同的数据库系统对 CASCADE 和 RESTRICT 的实现可能略有差异,因此在使用时应参考特定数据库系统的文档。
三.创建、删除、修改索引
建立索引是加快表的查询速度的有效手段。索引就像书的目录一样。可以直接定位到要查找的内容。SQL语言支持用户根据应用环境的需要,在基本表上建立一个或多个索引,以提供多种存取路径,加快查找速度。
1.建立索引(Create Index)
目的:为数据库表的一个或多个列创建索引,以加速查询操作。
格式:
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名>(<列名 1> [<次序>][,<列名 2>[<次序>]]... );
其中,<表名>指定要建索引的基本表的名字。索引可以建在该表的一列或多列上,各列名之间用逗号分隔。每个<列名>后面还可以用<次序>指定索引值的排列次序,包括ASC(升序)或 DESC(降序),默认值为 ASC。
UNIQUE 为唯一性索引,表示此索引的每一个索引值只对应唯一的数据记录。
CLUSTER 为聚簇索引,指索引项的顺序与表中记录的物理顺序一致的索引组织。
例如CREATE CLUSTER INDEX Cname ON C(Cname); 将会在表 C的Cname 列建一个聚簇索引,而且表中的记录将按照 Cname 值的升序存放。
示例
为课程表 C 按课程号升序建立唯一性索引。
CREATE UNIOUE INDEX idxCno ON C(Cno);
为学生表 S 按学号升序建立聚簇索引
CREATE CLUSTER INDEX CidxSno ON S(Sno);
创建一个复合索引,以加快基于这些字段的查询速度。我们将使用 UNIQUE 和 CLUSTER 关键字,并指定列的排序次序。
CREATE UNIQUE CLUSTER INDEX idxOrders ON Orders(OrderID ASC, CustomerID DESC, OrderDate ASC);
这条 SQL 语句执行以下操作:
- CREATE INDEX: 创建一个新索引。
- UNIQUE: 确保索引列的组合值在表中是唯一的。
- CLUSTER: 索引的顺序将决定表中数据的物理存储顺序。
- idxOrders: 为新索引指定的名称。
- ON Orders: 指定索引将创建在
Orders表上。 - OrderID ASC, CustomerID DESC, OrderDate ASC: 索引包含三列,其中
OrderID按升序排列,CustomerID按降序排列,而OrderDate按升序排列。
2.删除索引 (Drop Index)
目的:删除已存在的索引。
格式:
DROP INDEX <索引名>;
示例:
- 删除课程表 C 的 idxCno 索引:
DROP INDEX idxCno;
删除索引时,系统会同时从数据字典中删去有关该索引的描述。
注意事项
- 聚簇索引:因为聚簇索引影响数据的物理存储顺序,所以在经常更新的列上创建聚簇索引可能会影响性能。
- 索引维护:创建和删除索引时,数据库会自动更新数据字典中的相关信息。
- 索引选择:选择在哪些列上创建索引需要谨慎考虑,以平衡查询速度和更新成本。