书生·浦语大模型全链路开源体系 学习笔记 第一课
背景
大模型是发展人工通用人工智能的一个重要途径,能够解决多种任务和多种模态,展示了一个更面向更高阶的智能的潜在途径。大模型的发展历程是从专用模型到通用模型的过程,从语音识别、图像识别、人脸识别等专用模型,到通用的大模型,能够解决多种任务和多种模态。

书生浦语大模型覆盖了轻量级、中量级、重量级的不同大小的系列,具备强大的性能和全面的优势,能够超过相近量级的模型,且开源可用。

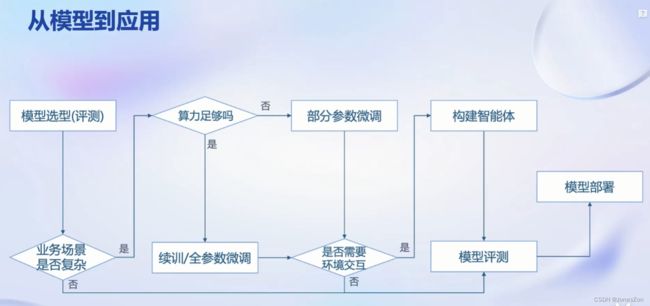
技术路线-从模型到应用
有了模型之后,需要在多个场景应用。从模型怎么样去到最终的应用,是目前研究的重点方向之一。

第一步模型选型。针对于应用场景,比较多种大模型相关维度的能力,进行模型评测。经过模型评测初步选型之后,可选定意向大模型。
第二步评估业务场景复杂度。若不复杂,可直接把模型拿过来应用。则继续如果业务场景非常复杂,通常来讲直接开源模型无法满足需求,需要微调、prompt工程等进一步构建。
第三步,判断全参数微调或部分微调等,并计算所需算力,应提前规划,避免微调失败。如果算力足够,可进行全参数微调。如果算力资源比较受限,只能进行部分参数微调,类似把大部分的参数固定住,只调一小部分参数。
第四步,构建基于大模型的智能体需要考虑模型与环境的交互。如果需要调用外部API或与已有业务数据库交互,就需要构建智能体。如果不需要与环境交互,就可以直接将微调好的模型在业务场景中试用。
第五步,模型评测,并评估是否上线应用或继续迭代。
第六步,模型部署。关于软件系统相关性能、安全、功能等方面内容。如考虑如何以更少的资源部署模型,或者如何提升整个应用的吞吐量。
开源数据和工具-书生·浦语
进行了一些基本介绍。
书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili

书生浦语全链条开放体系,包括了书生万卷多模态的语料库,包括文本、图像、视频等数据,大小超过2个TB,涵盖了不同领域的数据。提供了超过5400多个数据集,涵盖了30多种模态,总共大概有80TB的数据,包括图像、视频、文本语料、3D模型、音频等不同数据。
预训练工具的特点包括高可扩展性、极致的性能优化、兼容主流生态、开箱启用等特点。
增量续训和有精度微调的区别是什么?增量续训主要是让基座模型学习到新的知识,训练数据通常包括垂直领域的文章、书籍、代码等;有精度微调主要是让模型学会理解和遵循各种指令,训练数据主要是高质量的对话数据和问答数据。
有监督微调中的部分参数微调是什么?部分参数微调是将预先的权重固定住,引入新的较小的可训练参数进行微调,可以大大节省训练代价。
xTuner框架能够适配多种生态,兼容不同的微调算法和策略,同时能够加载开源生态的模型和数据集,并进行自动化优化加速。xTuner框架支持NVIDIA20系以上的所有显卡,包括2080、3060到3090等。同时支持多种数据格式和训练引擎。
OpenCompass评测体系是一个全球领先的开源评测体系,提供了六大维度和超过80个数据集,支持40多万道评测题目,涵盖了大模型能力的多个维度和细分,形成一个比较全面的评测体系。同时,它不仅仅是一个评测维度或体系,还提供了一系列工具。包括平台级架构,分为模型层和能力层,支持基础模型和对话模型,以及通用能力和特色能力等评测。
OpenCompass提供了便捷的数据集接口,社区用户可以快速添加自定义的数据集。支持主流的模型
部署方面
语言模型部署面临的技术挑战包括设备存储、推理加速、动态shape、内存管理和利用、吞吐量提升、请求响应时间降低等

LMDeploy是一个高效的推理框架,能够提供大模型部署的全流程解决方案。

智能体应用方面
LLM作为核心,执行不同动作如网络搜索、python代码解释器等
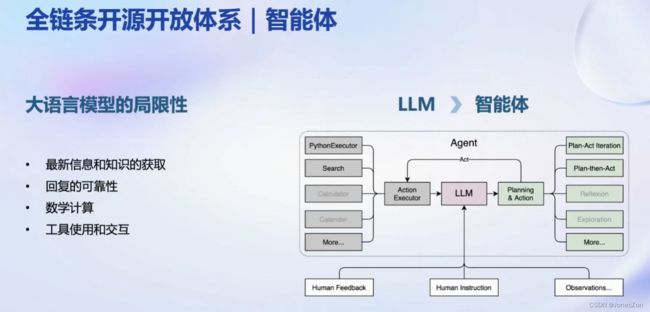
legend支持哪些大语言模型?

AgentLego可以做什么?可以连接大语言模型和环境,调用更多的工具完成任务。
Lagent和AgentLego有什么区别?Lagent是搭建智能体框架,而AgentLego是为大模型提供工具集合。
