性能分析与调优: Linux 性能分析60秒
目录
一、实验
1.环境
2.Linux性能分析60秒
一、实验
1.环境
(1)主机
表1-1 主机
| 主机 | 架构 | 组件 | IP | 备注 |
| prometheus | 监测 系统 |
prometheus、node_exporter | 192.168.204.18 | |
| grafana | 监测GUI | grafana | 192.168.204.19 | |
| agent | 监测 主机 |
node_exporter | 192.168.204.20 |
(2)性能工具检查表
表1-2 性能工具检查表
| 序号 | 工具 | 检查 |
| 1 | uptime | 平均负载可识别负载的增加或减少(比较1分钟、5分钟和15分钟的平均值) |
| 2 | dmesg -T | tail | 包括OOM事件的内核错误 |
| 3 | vmstat -SM 1 | 系统级统计:运行队列长度、交换、CPU总体使用情况 |
| 4 | mpstat -P ALL 1 | CPU平衡情况:单个CPU很繁忙,意味着线程扩展性糟糕 |
| 5 | pidstat 1 | 每个进程的CPU使用情况:识别意外的CPU消费者,以及 每个进程的用户/系统CPU时间 |
| 6 | iostat -xz 1 | 磁盘I/O统计: IOPS和吞吐量、平均等待时间、忙碌百分比 |
| 7 | free -m | 内存使用情况,包括文件系统的缓存 |
| 8 | sar -n DEV 1 | 网络设备I/O:数据包和吞吐量 |
| 9 | sar -n TCP,ETCP 1 | TCP统计:连接率、重传 |
| 10 | top | 检查概览 |
(3)推荐与参考书籍
《性能之巅》(第2版)
(4)问题诊断思路
1)通过十条命令在一分钟内对机器性能问题进行诊断
在 60 秒内,可以通过运行十个命令,对系统资源使用情况和正在运行的进程有一个高层次的了解。寻找错误和饱和度指标,因为它们都很容易解释,然后是资源利用率。饱和是指资源的负载超出其处理能力的情况,可以作为请求队列的长度或等待时间来公开。2.Linux性能分析60秒
(1)uptime
①命令
[root@prometheus ~]# uptime
![]()
② 分析
1)状态
在 Linux 系统中,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数。可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的。这些数据可以让我们对系统资源使用有一个宏观的了解。
2)输出
命令的输出分别表示 1 分钟、5 分钟、15 分钟的平均负载情况。通过这三个数据,可以了解服务器负载是在趋于紧张还是区域缓解。如果 1 分钟平均负载很高,而 15 分钟平均负载很低,说明服务器正在命令高负载情况,需要进一步排查 CPU 资源都消耗在了哪里。反之,如果 15 分钟平均负载很高,1 分钟平均负载较低,则有可能是 CPU 资源紧张时刻已经过去。
(2)dmesg
[root@prometheus ~]# dmesg | tail
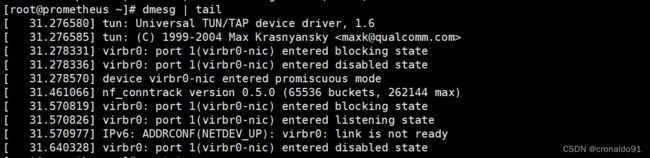 ② 分析
② 分析
这将查看最近 10 条系统消息(如果有)。查找可能导致性能问题的错误。(3)vmstat
①命令
[root@prometheus ~]# vmstat

② 分析
1)状态
每行会输出一些系统核心指标,这些指标可以让我们更详细的了解系统状态。后面跟的参数 1,表示每秒输出一次统计信息,表头提示了每一列的含义,
2)一些和性能调优相关的列:
r:等待在 CPU 资源的进程数。这个数据比平均负载更加能够体现 CPU 负载情况,数据中不包含等待 IO 的进程。如果这个数值大于机器 CPU 核数,那么机器的 CPU 资源已经饱和。
free:系统可用内存数(以千字节为单位),如果剩余内存不足,也会导致系统性能问题。下文介绍到的 free 命令,可以更详细的了解系统内存的使用情况。
si, so:交换区写入和读取的数量。如果这个数据不为 0,说明系统已经在使用交换区(swap),机器物理内存已经不足。
us, sy, id, wa, st:这些都代表了 CPU 时间的消耗,它们分别表示用户时间(user)、系统(内核)时间(sys)、空闲时间(idle)、IO 等待时间(wait)和被偷走的时间(stolen,一般被其他虚拟机消耗)。
3)原因
上述这些 CPU 时间,可以让我们很快了解 CPU 是否出于繁忙状态。一般情况下,如果用户时间和系统时间相加非常大,CPU 出于忙于执行指令。如果 IO 等待时间很长,那么系统的瓶颈可能在磁盘 IO。
(4) mpstat
①命令
[root@prometheus ~]# mpstat -P ALL 1

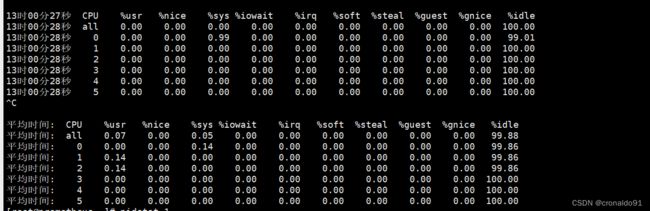 ② 分析
② 分析
该命令可以显示每个 CPU 的占用情况,如果有一个 CPU 占用率特别高,那么有可能是一个单线程应用程序引起的。(5) pidstat
①命令
[root@prometheus ~]# pidstat 1
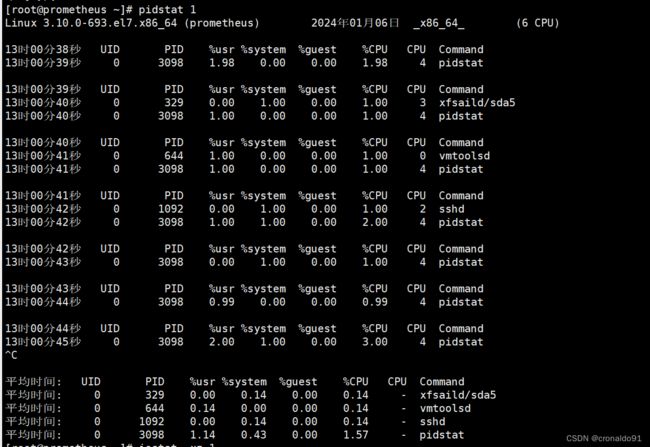 ② 分析
② 分析
pidstat 命令输出进程的 CPU 占用率,该命令会持续输出,并且不会覆盖之前的数据,可以方便观察系统动态。(6) iostat
①命令
[root@prometheus ~]# iostat -xz 1
 ② 分析
② 分析
1)状态
iostat 命令主要用于查看机器磁盘 IO 情况。
2)该命令输出列的含义
r/s, w/s, rkB/s, wkB/s:分别表示每秒读写次数和每秒读写数据量(千字节)。读写量过大,可能会引起性能问题。
await:IO 操作的平均等待时间,单位是毫秒。这是应用程序在和磁盘交互时,需要消耗的时间,包括 IO 等待和实际操作的耗时。如果这个数值过大,可能是硬件设备遇到了瓶颈或者出现故障。
avgqu-sz:向设备发出的请求平均数量。如果这个数值大于 1,可能是硬件设备已经饱和(部分前端硬件设备支持并行写入)。
%util:设备利用率。这个数值表示设备的繁忙程度,经验值是如果超过 60,可能会影响 IO 性能(可以参照 IO 操作平均等待时间)。如果到达 100%,说明硬件设备已经饱和。
3)原因
如果显示的是逻辑设备的数据,那么设备利用率不代表后端实际的硬件设备已经饱和。值得注意的是,即使 IO 性能不理想,也不一定意味这应用程序性能会不好,可以利用诸如预读取、写缓存等策略提升应用性能。
(7) free
①命令
[root@prometheus ~]# free –m
 ② 分析
② 分析
1)状态
free 命令可以查看系统内存的使用情况,-m 参数表示按照兆字节展示。最后两列分别表示用于 IO 缓存的内存数,和用于文件系统页缓存的内存数。
2)原因
如果可用内存非常少,系统可能会动用交换区(如果配置了的话),这样会增加 IO 开销(可以在 iostat 命令中提现),降低系统性能。
(8)sar -n DEV 1
①命令
[root@prometheus ~]# sar -n DEV 1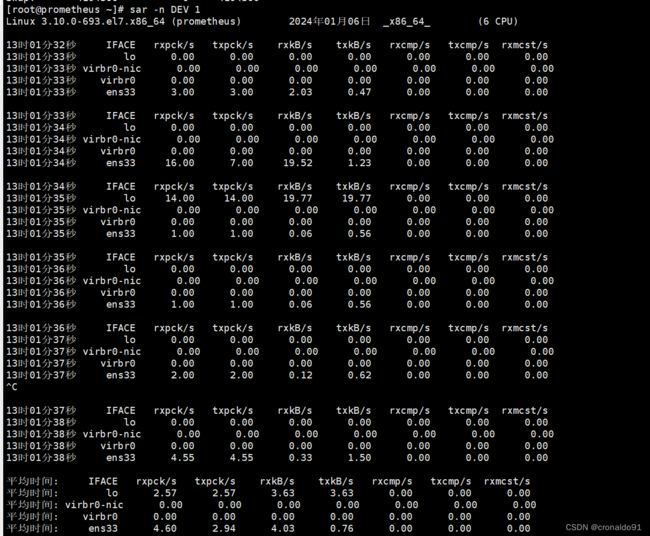 ② 分析
② 分析
1)状态
sar 命令在这里可以查看网络设备的吞吐率。在排查性能问题时,可以通过网络设备的吞吐量,判断网络设备是否已经饱和。
2)列含义
rxkB/s 表示吞吐率
(9)sar -n TCP,ETCP 1
①命令
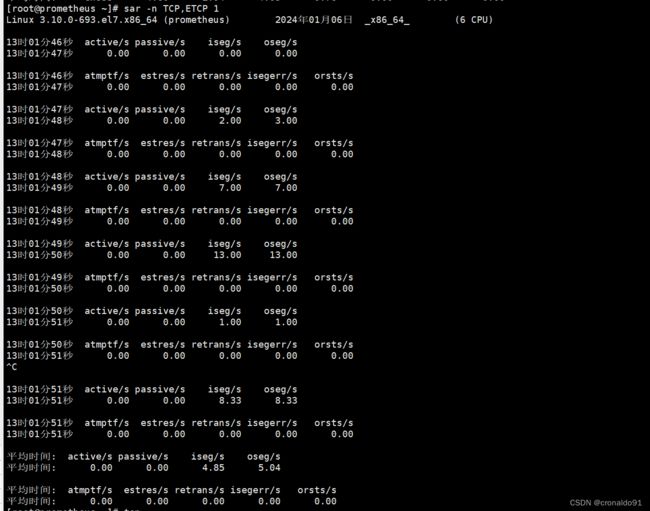
[root@prometheus ~]# sar -n TCP,ETCP 1
 ② 分析
② 分析
1)状态
sar 命令在这里用于查看 TCP 连接状态。
2)列含义
active/s:每秒本地发起的 TCP 连接数,既通过 connect 调用创建的 TCP 连接;
passive/s:每秒远程发起的 TCP 连接数,即通过 accept 调用创建的 TCP 连接;
retrans/s:每秒 TCP 重传数量。
3)原因
TCP 连接数可以用来判断性能问题是否由于建立了过多的连接,进一步可以判断是主动发起的连接,还是被动接受的连接。TCP 重传可能是因为网络环境恶劣,或者服务器压力过大导致丢包。重传会严重影响tcp的效率,可以使用Brendan Gregg开发的一个轻量级tcp重传抓取工具: tcpretrans。
(10)top
①命令
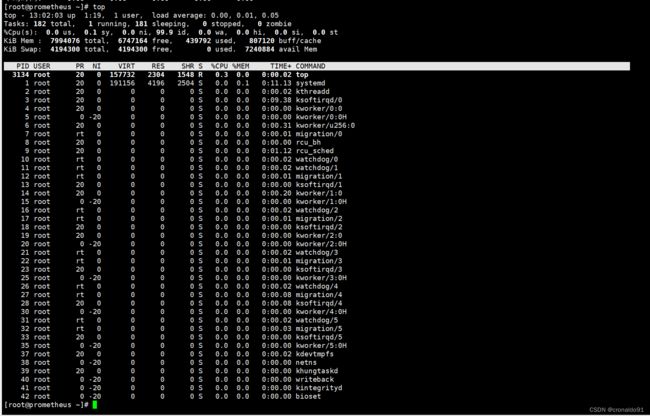
[root@prometheus ~]# top
 ② 分析
② 分析
1)状态
top 命令包含了前面好几个命令的检查的内容。比如系统负载情况(uptime)、系统内存使用情况(free)、系统 CPU 使用情况(vmstat)等。因此通过这个命令,可以相对全面的查看系统负载的来源。同时,top 命令支持排序,可以按照不同的列排序,方便查找出诸如内存占用最多的进程、CPU 占用率最高的进程等。
2)对比
但是,top 命令相对于前面一些命令,输出是一个瞬间值,如果不持续盯着,可能会错过一些线索。这时可能需要暂停 top 命令刷新,来记录和比对数据。