TSBS数据库性能测试
使用须知
由于TSBS是由go语言编写所以安装TSBS之前需要进行go语言的安装以及环境的配置(linux)
一、go语言环境的搭建
1、安装包的下载
wget https://dl.google.com/go/go1.12.6.linux-amd64.tar.gz
2、将压缩包解压指定的文件夹
tar -C /usr/local -xzf go1.12.6.linux-amd64.tar.gz
3、 配置go的环境变量使其可以在根目录下使用
打开profile并在最后进行配置(vim /etc/profile)
export PATH=$PATH:/usr/local/go/bin
4、查看go语言是否安装成功
go version
二、TSBS的安装
1、使用go get 对TSBS及其相关应用进行下载
$ go get github.com/timescale/tsbs
$ cd /root/go/src/github.com/timescale/tsbs/cmd
$ go get ./...
在下载相关应用时可能会出现如下问题
当出现以上问题时在src目录下创建golang.org/x两个文件夹并在x下下载上述问题中出现的应用例如(git clone https://github.com/golang/crypto)
2、切换到cmd下使用go install进行部分应用的安装
# Install desired binaries. At a minimum this includes tsbs_generate_data,
# tsbs_generate_queries, one tsbs_load_* binary, and one tsbs_run_queries_*
# binary:
$ cd $GOPATH/src/github.com/timescale/tsbs/cmd
$ cd tsbs_generate_data && go install
$ cd ../tsbs_generate_queries && go install
$ cd ../tsbs_load_timescaledb && go install
$ cd ../tsbs_run_queries_timescaledb && go install
3、切换到cmd下使用go install进行剩下的安装
# Optionally, install all binaries:
$ cd $GOPATH/src/github.com/timescale/tsbs/cmd
$ go install ./...
三、TSBS的使用
TSBS的使用分为三个阶段:数据生成、查询生成、数据的插入测试以及查询测试
1、数据的生成
需要的变量:
1)、用例:分为cpu-only和devops,例如 cpu-only
2)、一种用于确定性生成的PRNG种子,例如 123
3)、需要生成的设备数量,例如 4000
4)、数据生成的开始时间,例如 2016-01-01T00:00:00Z
5)、数据生成的结束时间,例如 2016-01-04T00:00:00Z
6)、以秒为单位读取每个设备之间的时间间隔,例如 10
7)、需要生成的数据库, 例如timescaledb (cassandra、clickhouse、cratedb、influx、mongo、siridb、timescaledb)
使用上边的变量可以生成一个数据集(在/tmp下生成timescaledb-data.gz数据压缩文件)
$ tsbs_generate_data -use-case="cpu-only" -seed=123 -scale=4000 \
-timestamp-start="2016-01-01T00:00:00Z" \
-timestamp-end="2016-01-04T00:00:00Z" \
-log-interval="10s" -format="timescaledb" \
| gzip > /tmp/timescaledb-data.gz
上面的示例将生成一个伪CSV文件,可用于将数据批量加载到TimescaleDB中。每个数据库都有自己的格式,用于存储数据,使其对应的加载器最容易写入数据。上面的配置将生成超过100M行(1B指标),这通常是一个很好的起点。将时间段增加一天将增加额外的~33M行,以便例如30天将产生十亿行(10B度量)
2、查询的生成
需要的变量:
1)、与数据生成中使用的相同的用例,种子,设备数和开始时间
2)、数据生成结束后一秒的结束时间。例如,供2016-01-04T00:00:00Z使用2016-01-04T00:00:01Z
3)、要生成的查询数。例如,1000
4)、以及您要生成的查询类型。例如,single-groupby-1-1-1
对于最后一步,有许多查询可供选择,这些查询在附录I中列出。此外,该文件scripts/generate_queries.sh包含所有这些文件 的列表作为环境变量的默认值QUERY_TYPES。如果要生成多种类型的查询,建议使用该帮助程序脚本。
单类型的一组查询
$ tsbs_generate_queries -use-case="cpu-only" -seed=123 -scale=4000 \
-timestamp-start="2016-01-01T00:00:00Z" \
-timestamp-end="2016-01-04T00:00:01Z" \
-queries=1000 -query-type="single-groupby-1-1-1" -format="timescaledb" \
| gzip > /tmp/timescaledb-queries-single-groupby-1-1-1.gz
多类型查询集的生成
$ FORMATS = “ timescaledb ” SCALE = 4000 SEED = 123 \
TS_START = “ 2016-01-01T00:00:00Z ” \
TS_END = “ 2016-01-04T00:00:01Z ” \
QUERIES = 1000 QUERY_TYPES = “ single-groupby-1-1-1 single-groupby-1-1-12 double-groupby-1 ” \
BULK_DATA_DIR = “ / tmp / bulk_queries ” scripts / generate_queries.sh
3、数据写入的性能检测
TSBS通过获取上一步中生成的数据并将其用作特定于数据库的命令行程序的输入来测量插入/写入性能。在可以共享插入程序的程度上,我们已经努力做到这一点(例如,如果需要,TimescaleDB加载器可以与常规PostgreSQL数据库一起使用)。每个加载器都共享一些公共标志 - 例如,批量大小(插入在一起的读数),工作者(并发插入客户端的数量),连接详细信息(主机和端口)等 - 但它们也具有特定于数据库的调整标志。要查找特定数据库的-help标志,请使用标志(例如,tsbs_load_timescaledb -help)。
除了直接调用这些二进制文件之外,我们还提供 scripts/load_
# Will insert using 2 clients, batch sizes of 10k, from a file
# named `timescaledb-data.gz` in directory `/tmp`
$ NUM_WORKERS=2 BATCH_SIZE=10000 BULK_DATA_DIR=/tmp \
scripts/load_timescaledb.sh
这将创建一个名为benchmark存储数据的新数据库。如果数据库存在,它将覆盖数据库; 如果您不希望发生这种情况,请提供DATABASE_NAME与上述命令不同的内容。缺少的可以跟据tsbs_load_timescaledb -help进行查找添加到load_timescaledb.sh中。
默认情况下,每10秒打印一次有关负载性能的统计信息,并且在加载完整数据集时,如下所示:
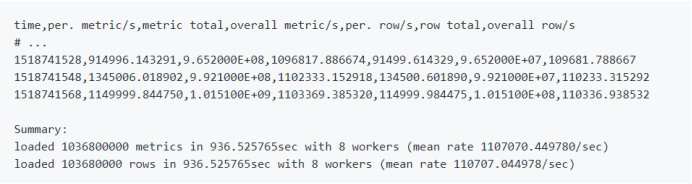
除最后两行之外的所有行都包含CSV格式的数据,标题中包含列名。这些列名对应于:
时间戳、期间每秒的指标、插入总指标、每秒总体指标、期间每秒行数、总行数、每秒总行数。
对于像Cassandra这样在插入时不使用行的数据库,最后三个值始终为空(用a表示-)。
最后两行是插入了多少指标(和适用的行),挂壁时间和平均插入速率的摘要。
4、查询执行的性能检测
要在TSBS中测量查询执行性能,首先需要使用上一节加载数据并生成如前所述的查询。加载数据并生成查询后,只需tsbs_run_queries_对要测试的数据库使用相应的二进制文件:
$ cat /tmp/queries/timescaledb-cpu-max-all-eight-hosts-queries.gz | \
gunzip | tsbs_run_queries_timescaledb --workers=8 \
--postgres="host=localhost user=postgres sslmode=disable"
缺少的条件也可以根据help进行查询
可以更改--workers标志的值以控制同时运行的并行查询的级别。结果:

附录:查询类型
Devops / cpu-only
Query type Description
single-groupby-1-1-1 Simple aggregrate (MAX) on one metric for 1 host, every 5 mins for 1 hour
single-groupby-1-1-12 Simple aggregrate (MAX) on one metric for 1 host, every 5 mins for 12 hours
single-groupby-1-8-1 Simple aggregrate (MAX) on one metric for 8 hosts, every 5 mins for 1 hour
single-groupby-5-1-1 Simple aggregrate (MAX) on 5 metrics for 1 host, every 5 mins for 1 hour
single-groupby-5-1-12 Simple aggregrate (MAX) on 5 metrics for 1 host, every 5 mins for 12 hours
single-groupby-5-8-1 Simple aggregrate (MAX) on 5 metrics for 8 hosts, every 5 mins for 1 hour
cpu-max-all-1 Aggregate across all CPU metrics per hour over 1 hour for a single host
cpu-max-all-8 Aggregate across all CPU metrics per hour over 1 hour for eight hosts
double-groupby-1 Aggregate on across both time and host, giving the average of 1 CPU metric per host per hour for 24 hours
double-groupby-5 Aggregate on across both time and host, giving the average of 5 CPU metrics per host per hour for 24 hours
double-groupby-all Aggregate on across both time and host, giving the average of all (10) CPU metrics per host per hour for 24 hours
high-cpu-all All the readings where one metric is above a threshold across all hosts
high-cpu-1 All the readings where one metric is above a threshold for a particular host
lastpoint The last reading for each host
groupby-orderby-limit The last 5 aggregate readings (across time) before a randomly chosen endpoint
详细信息可见:https://github.com/timescale/tsbs