Debezium发布历史49
原文地址: https://debezium.io/blog/2019/02/19/reliable-microservices-data-exchange-with-the-outbox-pattern/
欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯.
使用发件箱模式进行可靠的微服务数据交换
二月 19, 2019 作者: Gunnar Morling
讨论 微服务apache-kafka示例
作为业务逻辑的一部分,微服务通常不仅需要更新自己的本地数据存储,还需要通知其他服务发生的数据更改。发件箱模式描述了一种让服务以安全一致的方式执行这两项任务的方法;它为源服务提供即时“读取您自己的写入”语义,同时提供跨服务边界的可靠、最终一致的数据交换。
更新(2019 年 9 月 13 日):为了简化发件箱模式的使用,Debezium 现在提供了一个即用型SMT 来路由发件箱事件。不再需要本博文中讨论的自定义 SMT。
如果您构建了几个微服务,您可能会同意它们最难的部分是数据:微服务并不是孤立存在的,它们通常需要在彼此之间传播数据和数据更改。
例如,考虑一个管理采购订单的微服务:当下一个新订单时,有关该订单的信息可能必须转发到发货服务(以便它可以组装一个或多个订单的发货)和客户服务(以便它可以根据新订单更新客户的总信用余额等)。
有不同的方法可以让订单服务了解有关新采购订单的其他两种方法;例如,它可以调用这些服务提供的一些REST、grpc或其他(同步)API。不过,这可能会产生一些不需要的耦合:发送服务必须知道要调用哪些其他服务以及在哪里可以找到它们。它还必须为这些服务暂时不可用做好准备。Istio等服务网格通过提供请求路由、重试、断路器等功能,可以在这方面派上用场。
任何同步方法的普遍问题是,一个服务如果没有它调用的其他服务就无法真正运行。虽然缓冲和重试可能有助于其他服务仅需要通知某些事件的情况,但如果服务实际上需要查询其他服务以获取信息,则情况并非如此。例如,当下达采购订单时,订单服务可能需要从库存服务获取所采购商品的库存次数信息。
这种同步方法的另一个缺点是它缺乏可重玩性,即新消费者在事件发送后到达并且仍然能够从头开始消费整个事件流的可能性。
这两个问题都可以通过使用异步数据交换方法来解决:即让订单、库存和其他服务通过持久消息日志(例如Apache Kafka)传播事件。通过订阅这些事件流,每个服务都会收到有关其他服务的数据更改的通知。它可以对这些事件做出反应,并且如果需要,可以使用根据自己的需求定制的表示在自己的数据存储中创建该数据的本地表示。例如,此类视图可能会被非规范化以有效支持特定的访问模式,或者它可能仅包含与消费服务相关的原始数据的子集。
持久日志还支持可重玩性,即可以根据需要添加新的使用者,从而启用您最初可能没有想到的用例,并且无需触及源服务。例如,考虑一个数据仓库,它应该保存有关所有已下订单的信息,或者基于Elasticsearch的采购订单的一些全文搜索功能。一旦采购订单事件位于 Kafka 主题中(Kafka 主题的保留策略设置可用于确保事件在给定用例和业务需求所需的时间内保留在主题中),新消费者就可以订阅、处理该主题从一开始就具体化微服务数据库、搜索索引、数据仓库等中所有数据的视图。
应对主题增长
根据数据量(记录的数量和大小、更改频率),将事件长期甚至无限期地保留在主题中可能可行,也可能不可行。很多时候,从业务角度来看,与给定数据项(例如特定采购订单)相关的一些甚至所有事件可能适合在给定时间点之后删除。请参阅下面的“从 Kafka 主题中删除事件”框,了解有关从 Kafka 主题中删除事件以将其大小保持在范围内的更多想法。
双写问题
为了提供其功能,微服务通常会有自己的本地数据存储。例如,订单服务可以使用关系数据库来保存有关采购订单的信息。当下新订单时,这可能会导致对服务数据库中的INSERT表进行操作。PurchaseOrder同时,服务可能希望向 Apache Kafka 发送有关新订单的事件,以便将该信息传播到其他感兴趣的服务。
不过,简单地发出这两个请求可能会导致潜在的不一致。原因是我们不能拥有一个跨服务数据库和 Apache Kafka 的共享事务,因为后者不支持加入分布式 (XA) 事务。因此,在不幸的情况下,我们可能最终将新的采购订单保留在本地数据库中,但没有将相应的消息发送到 Kafka(例如,由于某些网络问题)。或者,相反,我们可能已将消息发送到 Kafka,但未能将采购订单保留在本地数据库中。这两种情况都是不可取的;这可能会导致看似成功下达的订单无法创建发货。或者创建了一个发货,
那么如何避免这种情况呢?答案是仅修改两个资源(数据库或Apache Kafka)之一,并以此为基础以最终一致的方式驱动第二个资源的更新。我们首先考虑只写入 Apache Kafka 的情况。
当收到新的采购订单时,订单服务不会INSERT同步写入数据库;相反,它只会将描述新订单的事件发送到 Kafka 主题。因此一次只会修改一个资源,如果出现问题,我们会立即发现并向订单服务的调用者报告请求失败。
同时,服务本身将订阅该 Kafka 主题。这样,当新消息到达主题时,它将收到通知,并且可以将新的采购订单保留在其数据库中。不过,这里存在一个微妙的挑战,那就是缺乏“读你自己写的”语义。例如,假设订单服务还有一个 API,用于搜索给定客户的所有采购订单。在下达新订单后立即调用该 API 时,由于处理来自 Kafka 主题的消息的异步特性,可能会发生采购订单尚未保存在服务数据库中的情况,因此该查询不会返回该订单。这可能会导致非常混乱的用户体验,因为例如用户可能会错过其购物历史记录中新下的订单。有多种方法可以处理这种情况,例如,服务可以将新下达的采购订单保留在内存中,并据此回答后续查询。不过,当实现更复杂的查询或考虑到订单服务还可能包含集群设置中的多个节点时,这很快就会变得不平凡,这将需要在集群内传播该数据。
现在,当仅同步写入数据库并基于此驱动将消息导出到 Apache Kafka 时,情况会是什么样子?这就是发件箱模式的用武之地。
发件箱模式
这种方法的想法是在服务的数据库中有一个“发件箱”表。当接收到下采购订单的请求时,不仅会执行INSERT到表中的PurchaseOrder操作,而且作为同一事务的一部分,表示要发送的事件的记录也会插入到发件箱表中。
该记录描述了服务中发生的事件,例如,它可以是表示已下达新采购订单这一事实的 JSON 结构,包括订单本身、其订单行以及上下文信息(例如使用情况)的数据案例标识符。通过通过发件箱表中的记录显式发出事件,可以确保事件以适合外部使用者的方式构建。这也有助于确保事件使用者在更改内部域模型或表时不会中断PurchaseOrder。
异步进程监视该表中的新条目。如果有的话,它将事件作为消息传播到 Apache Kafka。这为我们提供了非常好的特性平衡:通过同步写入表PurchaseOrder,源服务受益于“读取您自己的写入”语义。一旦提交了第一笔交易,后续的采购订单查询将返回新保留的订单。同时,我们通过 Apache Kafka 将可靠、异步、最终一致的数据传播到其他服务。
现在,发件箱模式实际上并不是一个新想法。它已经使用了相当长一段时间了。事实上,即使使用实际上可以参与分布式事务的 JMS 风格的消息代理,它也可能是避免远程资源(例如消息代理)停机造成的任何耦合和潜在影响的更好选择。您还可以在 Chris Richardson 的优秀microservices.io网站上找到该模式的描述。
然而,该模式受到的关注远没有应有的那么高,而且它在微服务环境中特别有用。正如我们将看到的,发件箱模式可以使用变更数据捕获和 Debezium 以非常优雅且高效的方式实现。下面我们就来探讨一下如何做。
基于变更数据捕获的实现
基于日志的变更数据捕获(CDC) 非常适合捕获发件箱表中的新条目并将其流式传输到 Apache Kafka。与任何基于轮询的方法相反,事件捕获以非常低的开销进行,几乎是实时的。Debezium 附带了适用于 MySQL、Postgres 和 SQL Server 等多种数据库的CDC 连接器。以下示例将使用Postgres 的 Debezium 连接器。
您可以在 GitHub 上找到该示例的完整源代码。有关构建和运行示例代码的详细信息,请参阅README.md 。该示例以两个微服务为中心:order-service和shipment-service。两者都是用 Java 实现的,使用CDI作为组件模型,使用 JPA/Hibernate 来访问各自的数据库。订单服务在WildFly上运行,并公开一个简单的 REST API,用于下达采购订单和取消特定订单行。它使用 Postgres 数据库作为其本地数据存储。发货服务基于Thorntail; 通过 Apache Kafka,它接收订单服务导出的事件,并在自己的 MySQL 数据库中创建相应的发货条目。Debezium 跟踪订单服务的 Postgres 数据库的事务日志(“预写日志”,WAL),以便捕获发件箱表中的任何新事件并将它们传播到 Apache Kafka。
解决方案的整体架构如下图所示:
图片来自于官网原文
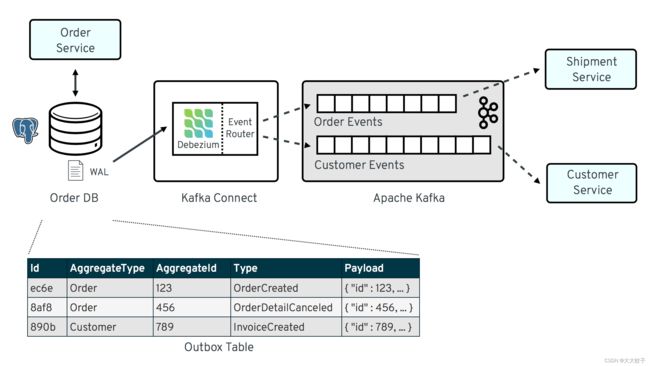
发件箱模式概述
请注意,该模式与这些特定的实现选择没有任何关系。它同样可以使用替代技术来实现,例如 Spring Boot(例如,利用 Spring Data对领域事件的支持)、普通 JDBC 或除 Java 之外的其他编程语言。
现在让我们仔细看看该解决方案的一些相关组件。
发件箱表
该outbox表驻留在订单服务的数据库中,具有以下结构:
Column | Type | Modifiers
--------------±-----------------------±----------
id | uuid | not null
aggregatetype | character varying(255) | not null
aggregateid | character varying(255) | not null
type | character varying(255) | not null
payload | jsonb | not null
它的列是:
id:每条消息的唯一ID;消费者可以使用它来检测任何重复事件,例如在失败后重新启动以读取消息时。创建新事件时生成。
aggregatetype:与给定事件相关的聚合根的类型;这个想法是,依靠域驱动设计的相同概念,导出的事件应该引用一个聚合(“可以被视为单个单元的域对象集群”),其中聚合根提供唯一的入口点用于访问聚合内的任何实体。例如,这可以是“采购订单”或“客户”。
该值将用于将事件路由到 Kafka 中的相应主题,因此与采购订单相关的所有事件都有一个主题,所有与客户相关的事件都有一个主题等。请注意,还有与其中包含的子实体相关的事件这样的聚合应该使用相同的类型。因此,例如代表取消单个订单行(属于采购订单聚合的一部分)的事件也应该使用其聚合根的类型“order”,确保该事件也将进入“order”Kafka 主题。
aggregateid:受给定事件影响的聚合根的 id;例如,这可以是采购订单的 ID 或客户 ID;与聚合类型类似,与聚合中包含的子实体相关的事件应使用包含聚合根的 ID,例如订单行取消事件的采购订单 ID。该 id 稍后将用作 Kafka 消息的密钥。这样,与一个聚合根或其包含的任何子实体相关的所有事件都将进入该 Kafka 主题的同一分区,这确保该主题的使用者将消费与该聚合根中的一个且相同的聚合相关的所有事件。生产时的确切顺序。
type:事件类型,例如“订单已创建”或“订单行已取消”。允许消费者触发合适的事件处理程序。
payload:具有实际事件内容的 JSON 结构,例如包含采购订单、有关购买者的信息、包含的订单行、价格等。
将事件发送到发件箱
为了将事件“发送”到发件箱,订单服务中的代码通常可以只INSERT对发件箱表执行操作。然而,采用稍微抽象一点的 API 是个好主意,这样可以在需要时更轻松地调整发件箱的实现细节。CDI 活动对此非常方便。它们可以在应用程序代码中引发,并由发件箱事件发送者同步处理,这将INSERT在发件箱表中执行所需的操作。
所有发件箱事件类型都应实现以下约定,类似于之前显示的发件箱表的结构:
public interface ExportedEvent {
String getAggregateId();
String getAggregateType();
JsonNode getPayload();
String getType();
}
为了产生此类事件,应用程序代码使用注入的Event实例,例如在类中OrderService:
@ApplicationScoped
public class OrderService {
@PersistenceContext
private EntityManager entityManager;
@Inject
private Event event;
@Transactional
public PurchaseOrder addOrder(PurchaseOrder order) {
order = entityManager.merge(order);
event.fire(OrderCreatedEvent.of(order));
event.fire(InvoiceCreatedEvent.of(order));
return order;
}
@Transactional
public PurchaseOrder updateOrderLine(long orderId, long orderLineId,
OrderLineStatus newStatus) {
// ...
}
}
在该addOrder()方法中,JPA 实体管理器用于将传入的订单保存在数据库中,并event使用注入来触发相应的OrderCreatedEvent和InvoiceCreatedEvent. 再次请记住,尽管有“事件”的概念,但这两件事发生在同一个事务中。即,在此事务中,三条记录将被插入到数据库中:一条记录在采购订单表中,两条记录在发件箱表中。
实际的事件实现是直接的;作为一个例子,下面是这个OrderCreatedEvent类:
public class OrderCreatedEvent implements ExportedEvent {
private static ObjectMapper mapper = new ObjectMapper();
private final long id;
private final JsonNode order;
private OrderCreatedEvent(long id, JsonNode order) {
this.id = id;
this.order = order;
}
public static OrderCreatedEvent of(PurchaseOrder order) {
ObjectNode asJson = mapper.createObjectNode()
.put("id", order.getId())
.put("customerId", order.getCustomerId())
.put("orderDate", order.getOrderDate().toString());
ArrayNode items = asJson.putArray("lineItems");
for (OrderLine orderLine : order.getLineItems()) {
items.add(
mapper.createObjectNode()
.put("id", orderLine.getId())
.put("item", orderLine.getItem())
.put("quantity", orderLine.getQuantity())
.put("totalPrice", orderLine.getTotalPrice())
.put("status", orderLine.getStatus().name())
);
}
return new OrderCreatedEvent(order.getId(), asJson);
}
@Override
public String getAggregateId() {
return String.valueOf(id);
}
@Override
public String getAggregateType() {
return "Order";
}
@Override
public String getType() {
return "OrderCreated";
}
@Override
public JsonNode getPayload() {
return order;
}
}
请注意Jackson 如何ObjectMapper用于创建事件有效负载的 JSON 表示形式。
现在让我们看一下消耗任何已触发ExportedEvent并对发件箱表进行相应写入的代码:
@ApplicationScoped
public class EventSender {
@PersistenceContext
private EntityManager entityManager;
public void onExportedEvent(@Observes ExportedEvent event) {
OutboxEvent outboxEvent = new OutboxEvent(
event.getAggregateType(),
event.getAggregateId(),
event.getType(),
event.getPayload()
);
entityManager.persist(outboxEvent);
entityManager.remove(outboxEvent);
}
}
这相当简单:对于每个事件,CDI 运行时都会调用该onExportedEvent()方法。该OutboxEvent实体的实例会持久保存在数据库中,并立即删除!
乍一看这可能会令人惊讶。但是,当记住基于日志的 CDC 的工作原理时,这是有意义的:它不检查数据库中表的实际内容,而是跟踪仅附加事务日志。一旦事务提交,对persist()和 的调用将在日志中remove()创建一个INSERT和 一个条目。DELETE之后,Debezium 将处理这些事件:对于任何INSERT,带有事件负载的消息将被发送到 Apache Kafka。DELETE另一方面,事件可以被忽略,因为从发件箱表中删除只是一个技术问题,不需要任何传播到消息代理。因此,我们能够通过CDC捕获添加到发件箱表中的事件,但是当查看表本身的内容时,它始终为空。这意味着该表不需要额外的磁盘空间(除了在某些时候会自动丢弃的日志文件元素之外),并且也不需要单独的内务处理来阻止其无限增长。
注册 Debezium 连接器
发件箱实现就位后,就可以注册 Debezium Postgres 连接器了,这样它就可以捕获发件箱表中的任何新事件并将它们中继到 Apache Kafka。这可以通过将以下 JSON 请求 POST 到 Kafka Connect 的 REST API 来完成:
{
“name”: “outbox-connector”,
“config”: {
“connector.class” : “io.debezium.connector.postgresql.PostgresConnector”,
“tasks.max” : “1”,
“database.hostname” : “order-db”,
“database.port” : “5432”,
“database.user” : “postgresuser”,
“database.password” : “postgrespw”,
“database.dbname” : “orderdb”,
“database.server.name” : “dbserver1”,
“schema.whitelist” : “inventory”,
“table.whitelist” : “inventory.outboxevent”,
“tombstones.on.delete” : “false”,
“transforms” : “router”,
“transforms.router.type” : “io.debezium.examples.outbox.routingsmt.EventRouter”
}
}
这将设置 的实例io.debezium.connector.postgresql.PostgresConnector,捕获指定 Postgres 实例的更改。请注意,通过表白名单,仅outboxevent捕获表中的更改。它还应用名为 的单个消息转换 (SMT) EventRouter。
从 Kafka 主题中删除事件
通过设置tombstones.on.deleteto false,当事件记录从发件箱表中删除时,连接器将不会发出删除标记(“逻辑删除”)。这是有道理的,因为从发件箱表中删除不应影响相应 Kafka 主题中事件的保留。相反,可以在 Kafka 中配置事件主题的特定保留时间,例如将所有采购订单事件保留 30 天。
或者,可以使用紧凑的主题。这需要对发件箱表中的事件设计进行一些更改:
他们必须描述整个总体;因此,例如代表取消单个订单行的事件也应描述包含采购订单的完整当前状态;这样,在日志压缩运行后,消费者仅在看到与给定订单相关的最后一个事件时就能够获取采购订单的完整状态。
它们必须还有一个boolean属性来指示特定事件是否表示删除该事件的聚合根。OrderDeleted然后,下一节中描述的事件路由 SMT 可以使用此类事件(例如 类型)来为该聚合根生成删除标记。OrderDeleted当事件已写入主题时,日志压缩将删除与给定采购订单相关的所有事件。
当然,删除事件时,事件流将无法再从头开始重新播放。根据特定的业务需求,仅保留给定采购订单、客户等的最终状态可能就足够了。这可以使用紧凑的主题和主题设置的足够值来实现delete.retention.ms。另一种选择可能是将历史事件移动到某种冷存储(例如 Amazon S3 存储桶),如果需要,可以从那里检索它们,然后从 Kafka 主题中读取最新事件。采用哪种方法取决于具体要求、预期数据量以及开发和运营解决方案的团队的专业知识。
主题路由
默认情况下,Debezium 连接器会将源自给定表的所有更改事件发送到同一主题,即我们最终会得到一个名为的 Kafka 主题,dbserver1.inventory.outboxevent该主题将包含所有事件,无论是订单事件、客户事件等。
OrderEvents不过,为了简化只对特定事件类型感兴趣的消费者的实现,拥有多个主题(例如,CustomerEvents等等)更有意义。例如,运输服务可能对任何客户事件不感兴趣。通过仅订阅该OrderEvents主题,它将确保永远不会收到任何客户事件。
为了将从发件箱表捕获的更改事件路由到不同的主题,EventRouter使用了自定义 SMT。以下是其方法的代码apply(),Kafka Connect 将针对 Debezium 连接器发出的每条记录调用该方法:
@Override
public R apply(R record) {
// Ignoring tombstones just in case
if (record.value() == null) {
return record;
}
Struct struct = (Struct) record.value();
String op = struct.getString("op");
// ignoring deletions in the outbox table
if (op.equals("d")) {
return null;
}
else if (op.equals("c")) {
Long timestamp = struct.getInt64("ts_ms");
Struct after = struct.getStruct("after");
String key = after.getString("aggregateid");
String topic = after.getString("aggregatetype") + "Events";
String eventId = after.getString("id");
String eventType = after.getString("type");
String payload = after.getString("payload");
Schema valueSchema = SchemaBuilder.struct()
.field("eventType", after.schema().field("type").schema())
.field("ts_ms", struct.schema().field("ts_ms").schema())
.field("payload", after.schema().field("payload").schema())
.build();
Struct value = new Struct(valueSchema)
.put("eventType", eventType)
.put("ts_ms", timestamp)
.put("payload", payload);
Headers headers = record.headers();
headers.addString("eventId", eventId);
return record.newRecord(topic, null, Schema.STRING_SCHEMA, key, valueSchema, value,
record.timestamp(), headers);
}
// not expecting update events, as the outbox table is "append only",
// i.e. event records will never be updated
else {
throw new IllegalArgumentException("Record of unexpected op type: " + record);
}
}
当接收到删除事件(op= d)时,它将丢弃该事件,因为从发件箱表中删除事件记录与下游消费者无关。当接收到创建事件 ( op= c) 时,事情会变得更有趣。此类记录将传播到 Apache Kafka。
Debezium 的更改事件具有复杂的结构,其中包含所表示行的旧 ( before) 和新 ( ) 状态。after要传播的事件结构是从after状态获得的。捕获的事件记录中的值aggregatetype用于构建要将事件发送到的主题的名称。例如,aggregatetype设置为的事件Order将被发送到OrderEvents主题。aggregateid用作消息键,确保该聚合的所有消息都将进入该主题的同一分区。消息值是一个结构,其中包含原始事件负载(编码为 JSON)、指示事件生成时间的时间戳以及事件类型。最后,事件 UUID 作为 Kafka 标头字段进行传播。这允许消费者进行有效的重复检测,而无需检查实际的消息内容。
Apache Kafka 中的事件
现在让我们来看看OrderEvents和CustomerEvents主题。
如果您已经检查了示例源代码并通过 Docker Compose 启动了所有组件(有关更多详细信息,请参阅示例项目中的README.md文件),您可以通过订单服务的 REST API 下采购订单,如下所示:
cat resources/data/create-order-request.json | http POST http://localhost:8080/order-service/rest/orders
同样,可以取消特定订单行:
cat resources/data/cancel-order-line-request.json | http PUT http://localhost:8080/order-service/rest/orders/1/lines/2
当使用诸如非常实用的kafkacat实用程序之类的工具时,您现在应该在OrderEvents主题中看到类似以下的消息:
kafkacat -b kafka:9092 -C -o beginning -f ‘Headers: %h\nKey: %k\nValue: %s\n’ -q -t OrderEvents
Headers: eventId=d03dfb18-8af8-464d-890b-09eb8b2dbbdd
Key: “4”
Value: {“eventType”:“OrderCreated”,“ts_ms”:1550307598558,“payload”:"{“id”: 4, “lineItems”: [{“id”: 7, “item”: “Debezium in Action”, “status”: “ENTERED”, “quantity”: 2, “totalPrice”: 39.98}, {“id”: 8, “item”: “Debezium for Dummies”, “status”: “ENTERED”, “quantity”: 1, “totalPrice”: 29.99}], “orderDate”: “2019-01-31T12:13:01”, “customerId”: 123}"}
Headers: eventId=49f89ea0-b344-421f-b66f-c635d212f72c
Key: “4”
Value: {“eventType”:“OrderLineUpdated”,“ts_ms”:1550308226963,“payload”:"{“orderId”: 4, “newStatus”: “CANCELLED”, “oldStatus”: “ENTERED”, “orderLineId”: 7}"}
包含消息值的字段payload是原始事件的字符串化 JSON 表示形式。Debezium Postgres 连接器将JSONB列作为字符串发出(使用io.debezium.data.Json逻辑类型名称),这就是引号被转义的原因。jq实用程序,更具体地说,它的fromjson运算符可以方便地以更易读的方式显示事件负载:
kafkacat -b kafka:9092 -C -o beginning -t Order | jq ‘.payload | fromjson’
{
“id”: 4,
“lineItems”: [
{
“id”: 7,
“item”: “Debezium in Action”,
“status”: “ENTERED”,
“quantity”: 2,
“totalPrice”: 39.98
},
{
“id”: 8,
“item”: “Debezium for Dummies”,
“status”: “ENTERED”,
“quantity”: 1,
“totalPrice”: 29.99
}
],
“orderDate”: “2019-01-31T12:13:01”,
“customerId”: 123
}
{
“orderId”: 4,
“newStatus”: “CANCELLED”,
“oldStatus”: “ENTERED”,
“orderLineId”: 7
}
您还可以查看该CustomerEvents主题来检查表示添加采购订单时创建发票的事件。
消费服务中的重复检测
至此,我们的发件箱模式实现已功能齐全;当订单服务收到下订单(或取消订单行)的请求时,它将在其数据库的purchaseorder和表中保留相应的状态。orderline同时,在同一事务内,相应的事件条目将被添加到同一数据库的发件箱表中。Debezium Postgres 连接器捕获对该表的任何插入,并将事件路由到与给定事件表示的聚合类型相对应的 Kafka 主题。
最后,让我们探讨一下另一个微服务(例如发货服务)如何使用这些消息。该服务的入口点是常规的 Kafka 消费者实现,这并不是太令人兴奋,因此为了简洁起见,此处省略。您可以在示例存储库中找到其源代码。对于该主题的每条传入消息Order,消费者调用OrderEventHandler:
@ApplicationScoped
public class OrderEventHandler {
private static final Logger LOGGER = LoggerFactory.getLogger(OrderEventHandler.class);
@Inject
private MessageLog log;
@Inject
private ShipmentService shipmentService;
@Transactional
public void onOrderEvent(UUID eventId, String key, String event) {
if (log.alreadyProcessed(eventId)) {
LOGGER.info("Event with UUID {} was already retrieved, ignoring it", eventId);
return;
}
JsonObject json = Json.createReader(new StringReader(event)).readObject();
JsonObject payload = json.containsKey("schema") ? json.getJsonObject("payload") :json;
String eventType = payload.getString("eventType");
Long ts = payload.getJsonNumber("ts_ms").longValue();
String eventPayload = payload.getString("payload");
JsonReader payloadReader = Json.createReader(new StringReader(eventPayload));
JsonObject payloadObject = payloadReader.readObject();
if (eventType.equals("OrderCreated")) {
shipmentService.orderCreated(payloadObject);
}
else if (eventType.equals("OrderLineUpdated")) {
shipmentService.orderLineUpdated(payloadObject);
}
else {
LOGGER.warn("Unkown event type");
}
log.processed(eventId);
}
}
首先要做的onOrderEvent()是检查具有给定 UUID 的事件之前是否已被处理过。如果是这样,对同一事件的任何进一步调用都将被忽略。这是为了防止由该数据管道的“至少一次”语义引起的任何事件的重复处理。例如,在分别使用源数据库或消息代理确认特定事件的检索之前,Debezium 连接器或消费服务可能会失败。在这种情况下,重新启动 Debezium 或消费服务后,可能会再次处理一些事件。将事件 UUID 作为 Kafka 消息头进行传播,可以有效检测和排除消费者中的重复项。
如果是第一次接收到消息,则解析消息值,并ShippingService使用事件负载调用与特定事件类型对应的方法的业务方法。最后,消息在消息日志中标记为已处理。
这MessageLog只是跟踪服务本地数据库中表中的所有消费事件:
@ApplicationScoped
public class MessageLog {
@PersistenceContext
private EntityManager entityManager;
@Transactional(value=TxType.MANDATORY)
public void processed(UUID eventId) {
entityManager.persist(new ConsumedMessage(eventId, Instant.now()));
}
@Transactional(value=TxType.MANDATORY)
public boolean alreadyProcessed(UUID eventId) {
return entityManager.find(ConsumedMessage.class, eventId) != null;
}
}
这样,如果事务因某种原因回滚,原始消息也不会被标记为已处理,并且异常将冒泡到 Kafka 事件消费者循环。这允许稍后重新尝试处理该消息。
请注意,更完整的实现应该只在将任何无法处理的消息重新路由到死信队列或类似队列之前,仅重试给定的消息一定次数。消息日志表上还应该有一些管理工作;定期地,所有早于消费者向代理提交的当前偏移量的事件都可能被删除,因为它确保此类消息不会再次传播给消费者。
概括
发件箱模式是在不同微服务之间传播数据的好方法。
通过仅修改单个资源(源服务自己的数据库),可以避免同时更改不共享一个公共事务上下文(数据库和 Apache Kafka)的多个资源时出现的任何潜在不一致情况。通过首先写入数据库,源服务具有即时“读取您自己的写入”语义,这对于一致的用户体验非常重要,允许在写入后调用查询方法以立即反映任何数据更改。
同时,该模式支持将异步事件传播到其他微服务。Apache Kafka 充当服务之间消息传递的高度可扩展且可靠的骨干。如果有正确的主题保留设置,新的消费者可能会在事件最初生成后很长时间内出现,并根据事件历史记录建立自己的本地状态。
将Apache Kafka置于整体架构的中心也保证了所涉及服务的解耦。例如,如果解决方案的单个组件发生故障或在一段时间内不可用(例如在更新期间),事件将在稍后处理:重新启动后,Debezium 连接器将继续从其离开的位置跟踪发件箱表之前关掉。同样,任何消费者都将继续处理其先前偏移量中的主题。通过跟踪已成功处理的消息,可以检测到重复消息并将其排除在重复处理之外。
当然,不同服务之间的这种事件管道最终是一致的,即诸如运输服务之类的消费者可能会稍微落后于诸如订单服务之类的生产者。不过,通常情况下,这很好,并且可以根据应用程序的业务逻辑进行处理。例如,通常不需要在下订单的同一秒内创建发货。此外,由于基于日志的变更数据捕获允许近乎实时地发出事件,整个解决方案的端到端延迟通常很低(秒甚至亚秒范围)。
最后要记住的一件事是,通过发件箱公开的事件的结构应被视为发出服务的 API 的一部分。即,当需要时,应仔细调整它们的结构并考虑兼容性。这是为了确保在升级生产服务时不会意外破坏任何消费者。同时,消费者在处理消息时应该宽容,例如在接收到的事件中遇到未知属性时不要失败。
非常感谢 Hans-Peter Grahsl、Jiri Pechanec、Justin Holmes 和 René Kerner 在撰写本文时提供的反馈!