transbigdata笔记:数据预处理
0 数据
使用 transbigdata/docs/source/gallery/data/TaxiData-Sample.csv at main · ni1o1/transbigdata (github.com)
和transbigdata/docs/source/gallery/data/sz.json at main · ni1o1/transbigdata (github.com)
0.1 导入库
import transbigdata as tbd
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt0.2 读取出租车轨迹数据
data=pd.read_csv('TaxiData-Sample.csv',names= ['VehicleNum', 'Time', 'Lng', 'Lat', 'OpenStatus', 'Speed'])
data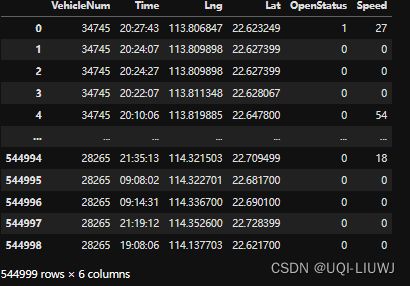
0.3 读取深圳各区json数据(并可视化)
sz=gpd.read_file('sz.json')
sz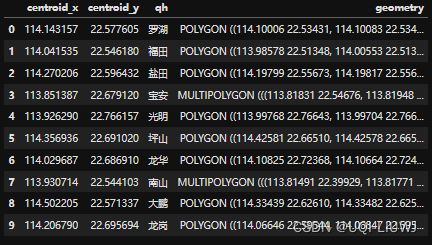
sz.plot(figsize=(15,8))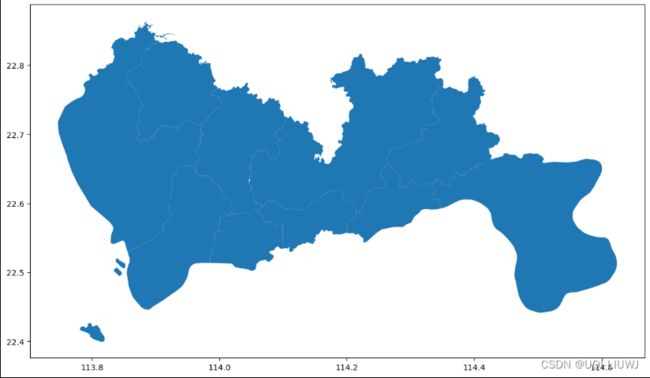
1 数据预处理(和地理坐标相关)
1.1 clean_outofbounds
1.1.1 基本使用方法
transbigdata.clean_outofbounds(
data,
bounds,
col=['Lng', 'Lat'])
并排除研究区域外的数据
1.1.2 主要参数说明
| data | 数据 |
| bounds | 研究区域左下角和右上角的纬度和经度,顺序为 [lon1, lat1, lon2, lat2] |
| col | data中经纬度列名 |
1.1.3 举例
tbd.clean_outofbounds(data,[114.0,22.5,114.3,22.6])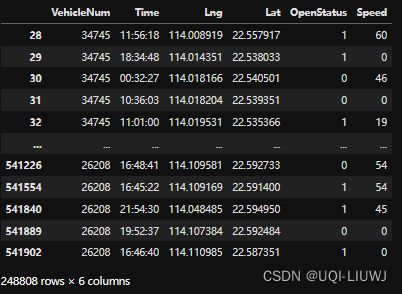
1.2 clean_outofshape
1.2.1 基本使用方法
输入研究区域的地理数据框并排除研究区域以外的数据
transbigdata.clean_outofshape(
data,
shape,
col=['Lng', 'Lat'],
accuracy=500)1.2.2 主要参数
| data | 数据 |
| shape | 研究区的GeoDataFrame |
| col | 经纬度列名 |
| accuracy | 栅格的大小。 原理是先做数据栅格化,然后再做数据清理。 尺寸越小,精度越高 |
1.2.3 举例
tbd.clean_outofshape(data,sz,accuracy=100)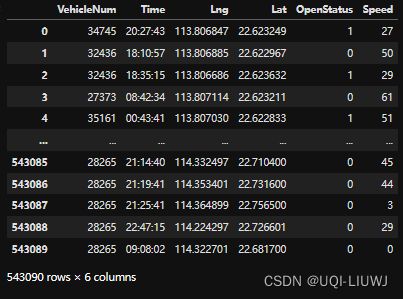
tbd.clean_outofshape(data,sz,accuracy=1000)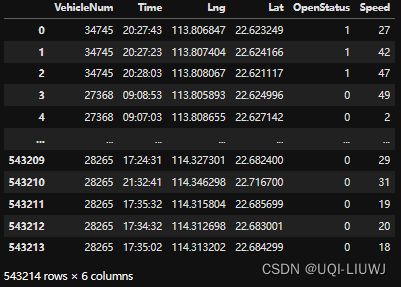
accuracy 越小,筛选得越细
2 数据预处理(和出租车相关)
2.1 clean_taxi_status
- 从出租车数据中删除乘客携带状态的瞬时变化记录。这些异常记录会影响旅行订单判断
- 判断方法:如果同一车辆上一条记录和下一条记录的乘客状态与该记录不同,则应删除该记录【不可以一瞬间接客/不接客】
2.1.1 主要使用方法
transbigdata.clean_taxi_status(
data,
col=['VehicleNum', 'Time', 'OpenStatus'],
timelimit=None)2.1.2 主要参数
| data | 数据 |
| col | 列名,顺序为[‘VehicleNum’, ‘Time’, ‘OpenStatus’] |
| timelimit | 可选,以秒为单位。 如果上一条记录和下一条记录之间的时间小于时间阈值,则将删除该记录 【个人觉得是,和上一条记录的时间差 & 和下一条记录的时间差 都小于阈值,那么删除该记录】 这个阈值表示允许状态变化的最短时间间隔
|
2.1.3 举例
data = tbd.clean_outofshape(data, sz, col=['Lng', 'Lat'], accuracy=500)
data
data2 = tbd.clean_taxi_status(data, col=['VehicleNum', 'Time', 'OpenStatus'])
data2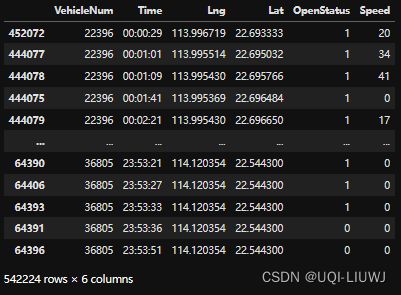
2.1.4 删去的那些行举例说明
我们看一下删去的行都是什么特点呢?
根据pandas笔记:找出在一个dataframe但不在另一个中的index-CSDN博客
我们得到在data,但不在data2中的index
diff_index = data.index.difference(data2.index)
diff_index
'''
Index([ 710, 807, 844, 1372, 1564, 1684, 1690, 1753, 2842,
4150,
...
532055, 533757, 534219, 540261, 540471, 540481, 541260, 541263, 541889,
542487],
dtype='int64', length=914)
'''看一下710行是什么东西吧:
data.iloc[710]
'''
VehicleNum 24741
Time 16:16:00
Lng 113.810135
Lat 22.626522
OpenStatus 0
Speed 0
Name: 710, dtype: object
'''然后看一下24741号车辆的记录
pd.set_option('display.max_rows', None)
#显示dataframe所有行
data[data['VehicleNum']==24741].sort_values('Time')
#筛选 24741号 车辆,按照Time排序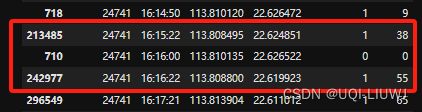
确实上一条记录和下一条记录的乘客状态与该记录不同
2.1.5 timelimit
pd.set_option('display.max_rows', 10)
data3 = tbd.clean_taxi_status(data, col=['VehicleNum', 'Time', 'OpenStatus'],timelimit=25)
data.index.difference(data3.index)
'''
Index([ 807, 844, 1684, 1753, 6433, 6437, 7709, 7739, 9741,
10852,
...
507166, 511979, 514909, 514954, 523687, 524631, 540471, 540481, 541260,
541263],
dtype='int64', length=329)
'''此时710和后一条记录的时间间隔(38秒)大于阈值25秒,说明不是噪声,所以不删去