RabbitMQ高级应用
RabbitMQ的高级应用
1.业务场景:
1.例如某打车软件简化的业务流程如下:
1.用户登录app后点击开发打车进行打车
2.打车服务开始为司机派单
3.司机接单后开始来接用户
4.上车后用户处于行程中的打车状态
5.行程结束后用户完成本次打车服务
2.这个业务下需要解决的问题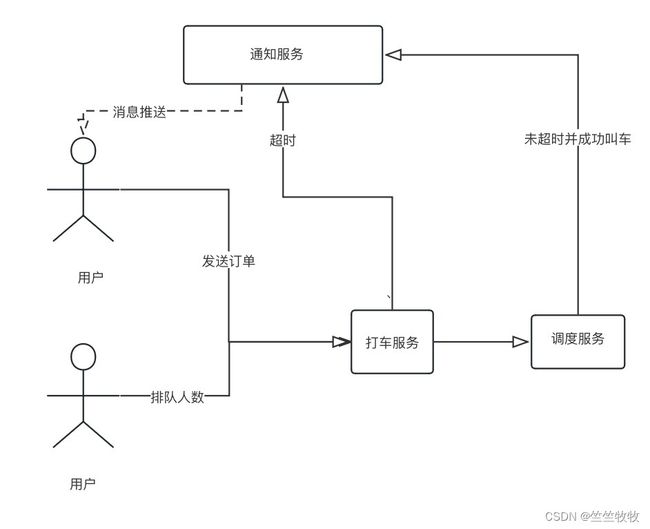
1.打车超时
比如打车后等待多长时间没有打到车后会通知等待超时
2.打车排队
因为排队我们需要获取当前的排队人数,所以需要通过redis的zset结构来实现排队功能(rank命令)
3.消息推送
我们需要将我们的异步处理结构返回到客户端,我们的客户端是使用的websocket连接的,因为websocket是点对点连接的,连接到一台固定的通知服务后,只能从这一台通知服务来获取数据,因为我们的通知服务允许分布式部署
4.解决思路
用户通过调用打车服务将数据放进RabbitMQ的死信队列进行延时操作,等待一段时间后,正常的业务处理还没有处理到我们发起的数据,将会进行超时处理,通过通知服务将我们的处理结构通过websocket方式推送到我们的客户端。
2.延时任务
1.什么是延时任务
生成订单后30分钟未支付自动取消、生成订单10秒后给用户发短信、订单完成后一直不评价48小时后自动为5星好评等业务场景都会用到延时任务。与定时任务不同的是延时任务它是对当前任务的延时不能明确具体为哪天的哪个具体的时间来执行,也没有明确的什么执行周期,延时任务一般就是单个任务并不是批处理。
2.延时任务的常见方案
1.数据库轮询
定时轮询扫描数据库判断订单状态。然后执行接下来的业务操作。不过这种方案存在延时 服务器内存消耗大 如果数据量大db消耗大扛不住这样的方案数据比较大不建议使用。
2.jdk延迟队列(DelayQueue)
delayQueue是一个无界阻塞队列放入DelayQueue的对象需要集成delayed接口
消费者通过poll take 方法获取任务
这样的方案是单机的内存队列宕机重启延时任务全部消失。内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现OOM异常。数据不能够持久化,准确度要求高不建议使用。
3.netty时间轮算法
多轮方案(年月日时分秒轮)
单轮方案
netty有相关的工具
缺点以及存在的问题跟delayQueue差不多。
4.rabbitmq消息队列
生产者 – 交换机 – 普通队列 – ttl过期 – 死信队列交换机 – 死信队列 --消费者
RabbitMQ具有以下两个特性,可以实现延迟队列
1.RabbitMQ可以针对Queue和Message设置 x-message-ttl
控制消息的生存时间,如果超时,则消息变为 dead letter(死信 死了的信息) 最好是针对Queue来设置x-message-ttl(ttl time to live)不要针对消息 消息队列先进先出 如果消息A在前面他的过期时间为30分钟 消息B在后面过期时间为3S 那么A先消费才能轮到B 这时候过期时间为3s的b消息等待了30分钟才消费。也可以用插件处理这个问题不过这个插件会排序消耗mq的性能不推荐使用。
ttl可以设置为0,如果设置为0,在消息的queue中前面有一个消息没有消费掉那么这个设置为0的消息会直接被丢弃掉。
2.RabbitMQ的Queue可以配置 x-dead-letter-exchange 和 x-dead-letter-routing-key(可选会把路由键改为key2)
这两个参数用来控制队列内出现了 dead letter ,则按照这两个参数重新路由。死信队列监听的是死信交换器。
5.rabbitmq的死信队列
1.什么是死信队列
就是无法被消费的消息,一般来说,producer将消息投递到broker或者直接到queue里了,consumer从queue取出消息进行消费,但某些时候由于特定的原因导致queue中的某些消息无法被消费,这样的消息如果没有后续的处理,就变成了死信,有死信,自然就有了死信队列;
2.死信队列使用场景
死信交换器不是默认的设置,这里是被投递消息被拒绝后的一个可选行为,是在创建队列的时进行声明的,往往用在对问题消息的诊断上。死信交换器仍然只是一个普通的交换器,创建时并没有特别要求和操作,在创建队列的时候,声明该交换器将用作保存被拒绝的消息即可,相关的参数是 x-dead-letter-exchange 。
RabbitMQ中的死信交换器(dead letter exchange)可以接收下面三种场景中的消息:
1.消费者对消息使用了 basicReject 或者 basicNack 回复,并且 requeue 参数设置为 false ,即不再将该消息重新在消费者间进行投递,或者重复多次失败了(注意业务上应该有个失败重试重回队列的次数不然会一直消费阻塞队列达到一定次数以后就要拒绝)。
2.消息在队列中超时,RabbitMQ可以在单个消息或者队列中设置 TTL 属性。
3.队列中的消息已经超过其设置的最大消息个数。
3.RabbitMQ消息可靠性保障
1.RabbitMQ消息投递的流程
producer (生产者 )-- broker – consumer (消费者)
broker 里面有虚拟主机 virtual host
virtual host里面有 exchange (交换机) – binding key (绑定键) – queue (队列)
2.哪里会丢失消息
1.生产者到broker
网络波动、 生产者宕机
2.broker中exchange到queque
binding key错误、broker宕机
3.消费者消费
消费者消费失败、提交偏移量失败
4.控制台操作失误
要控制开发权限,不要没事给交换机或者队列干掉了这样是找不回来的消息就丢失了。
3.RabbitMQ保证消息不丢失
在rabbiitmq中队列通过路由键(rounting key)绑定到交换器,生产者将消息发布到交换器,交换器根据绑定的路由键将消息路由到指定的队列上,然后由订阅这个队列的消费者进行接收。
消息到达无人订阅的队列会一直在队列中等待。
多个消费者订阅同一个队列,消息会以循环的方式推给消费者,只会发送给一个消费者。
消息路由到了不存在的队列一般情况下rabbitmq会直接忽略消息会直接丢失。
1.生产者保证
这里指的是生产者发送消息到broker的过程中
不做任何配置的情况下,生产者是不知道消息是否真正到达RabbitMQ,也就是说消息发布操作不返回任何消息给生产者。
1.失败通知(只负责确认路由是否成功)
如果出现消息无法投递到队列要失败通知
发送消息时要设置mandatory标志,即可开始故障检测模式,它只会让mq向你通知失败不会通知成功, 生产者实现 ReturnCallback 接口方可实现失败通知,如果消息正确的路由到队列那么生产者就不会受到任何的通知。只要路由到了队列就判定为成功是否落盘了我们是无从知晓的。
2.发送方确认(只负责投递是否成功)
失败通知如果消息正确路由到队列,则发布者不会受到任何通知,带来的问题是无法确保发布消息一定是成功的,因为路由到队列的消息也可能会丢失。我们可以使用RabbitMQ的发送方确认来实现,它不仅仅在路由失败的时候给我们发送消息,并且能够在消息路由成功的时候也给我们发送消息。
开启消息确认机制:
rabbitmq: publisher-confirm-type: correlated
代码中开启发送方确认,channel.confirmSelect();
生产者实现 ConfirmCallback 接口来监听通知结果。
发送方确认是指生产者投递消息后,如果 Broker 接收到消息,则会给生产者一个应答,生产者进行接收应答,用来确认这条消息是否正常的发送到 Broker,这种方式也是消息可靠性投递的核心保障。
rabbitmq将消息发送到broker,即发送到exchage交换机消息通过交换机exchange被路由到队列queue,一旦消息投递到队列,队列则会向生产者发送一个通知,如果设置了消息持久化到磁盘,则会等待消息持久化到磁盘之后再发送通知。
发送方确认只有出现RabbitMQ内部错误无法投递才会出现发送发确认失败。
1.不可路由
消息发送到交换器无法路由到队列,但是确定到达了交换器也会认为消息发送方确认成功了。这里就要结合失败通知一起来确认消息投递的可靠性了。
2.可以路由
只要消息能够到达队列即可进行确认,一般是RabbitMQ发生内部错误才会出现失败。如果消息和队列是可持久化的,那么确认消息会在将消息写入磁盘之后发出,broker回传给生产者的确认消息中delivery-tag域包含了确认消息的序列号。
2.Broker保证
1.broker丢失消息问题
如果消息已经成功的路由到了队列,消费者还未进行消费的时候mq宕机了,如果宕机重启后消息不见了那消息岂不是丢失了么?为了保证消息的持久化需要开启rabbiltmq的持久化,投递到交换机或者队列后要持久化到磁盘即使mq宕机了重启之后也会自动读取之前存储的数据。所以需要的是持久化的message、持久化的exchange、持久化的queue。
2.如果还没等持久化呢 rabbitmq就宕机了怎么办?
mq的持久化和前面的confirm进行配合使用,只有当消息写入磁盘后才返回ack,那么就是在持久化之前mq挂掉了,但是由于生产者没有接收到ack信号,此时可以进行消息重发。
3.消费方保证
消费者接收到消息,但是还未处理或者还未处理完,此时消费者进程挂掉了,比如重启或者异常断电等,此时mq认为消费者已经完成消息消费,就会从队列中删除消息,从而导致消息丢失。不能使用rabbitmq的自动ack机制。
1.消费者手动ack
rabbitmq:
listener:
simple:
acknowledge-mode: manual (手动ack配置)
auto:消费者根据程序执行正常或者抛出异常来决定是提交ack或者nack(消费者宕机时候消息丢失)
manual: 手动ack,用户必须手动提交ack或者nack
none: 没有ack机制
channel.basicAck(tag, false);单条ack
channel.basicAck(tag, true); 批量ack
在代码中确定消息已经处理完成手动提交ack,此时如果再遇到消息未处理进程就挂掉的情况,由于没有提交ack,RabbitMQ就不会删除这条消息,而是会把这条消息发送给其他消费者处理,可以避免消息丢失的。
多次失败可以放入死信队列
4.rabbitmq推模型的问题
rabbitmq的响应速度最快源于它的推模型设计,不过如果消息过多,或者设置了手动ack代码中忘记手动推送,rocketmq的queue中会有大量的没有被确认的消息堆积,消费者重启还会重新消费一次,并且如果流量过大的时候也可能直接给消费者干宕机,这时候消费者再次重启又是一堆没有消费的消息推过来,可以尝试开启qos限流控制消息最多允许有多少条不被消费确认防止出现这样的问题。