J3-DenseNet实战
- 本文为365天深度学习训练营 中的学习记录博客
- 原作者:K同学啊 | 接辅导、项目定制
目录
- 环境
- 步骤
-
- 环境设置
- 数据准备
-
- 图像信息查看
- 模型构建
- 模型训练
- 模型效果展示
- 总结与心得体会
环境
- 系统: Linux
- 语言: Python3.8.10
- 深度学习框架: Pytorch2.0.0+cu118
- 显卡:GTX2080TI
步骤
环境设置
包引用
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
from torchinfo import summary
import random, pathlib, collections, copy
from PIL import Image
全局设备对象
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据准备
从K同学提供的网盘中下载乳腺癌数据集,解压到data目录下,数据集的结构如下:
其中1是乳腺癌,0不是乳腺癌,这个目录结构可以使用torchvision.datasets.ImageFolder直接加载
图像信息查看
- 获取到所有的图像
root_dir = 'J3-data'
root_directory = pathlib.Path(root_dir)
image_list = root_directory.glob("*/*")
- 随机打印5个图像的尺寸
for _ in range(5):
print(np.array(Image.open(str(random.choice(image_list)))).shape)

发现输入并不是224大小的三通道图像,所以我们可以在数据集处理时需要Resize这一步
3. 随机打印20个图像
plt.figure(figsize=(20, 4))
for i in range(20):
plt.subplot(2, 10, i+1)
plt.axis('off')
image = random.choice(image_list)
class_name = image.parts[-2]
plt.title('normal' if class_name == '0' else 'abnormal')
plt.imshow(Image.open(str(image)))
- 创建数据集
首先定义一个图像的预处理
transform = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
),
])
然后通过datasets.ImageFolder加载文件夹
dataset = datasets.ImageFolder(root_dir, transform=transform)
从数据中提取图像不同的分类名称,并转换成文字
class_names = ['正常细胞' if x =='0' else '乳腺癌细胞' for x in dataset.class_to_idx]
划分训练集和验证集
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
最后,将数据集划分批次
batch_size = 8
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
模型构建
模型的参数列表
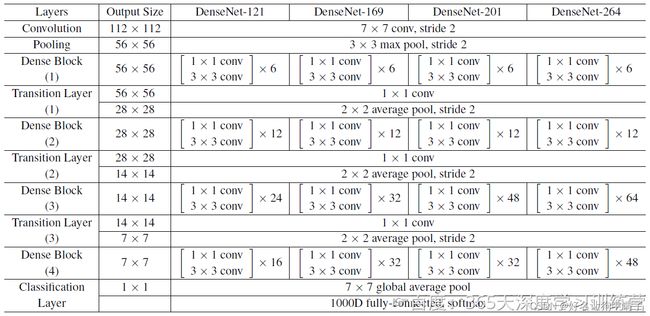
首先编写DenseLayer,它生成自己本层的特征值并与上层的拼接到一起输出
class DenseLayer(nn.Sequential):
def __init__(self, input_size, growth_rate, bn_size, drop_rate):
super().__init__()
self.add_module('norm1', nn.BatchNorm2d(input_size)),
self.add_module('relu1', nn.ReLU(inplace=True)),
self.add_module('conv1', nn.Conv2d(input_size, bn_size*growth_rate, kernel_size=1, stride=1, bias=False))
self.add_module('norm2', nn.BatchNorm2d(bn_size*growth_rate))
self.add_module('relu2', nn.ReLU(inplace=True)),
self.add_module('conv2', nn.Conv2d(bn_size*growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
features = super().forward(x)
if self.drop_rate > 0:
features = F.dropout(features, p = self.drop_rate, training=self.training)
return torch.concat([x, features], 1)
然后编写DenseBlock,它根据参数对DenseLayer进行堆叠
class DenseBlock(nn.Sequential):
def __init__(self, num_layers, input_size, growth_rate, bn_size, drop_rate):
super().__init__()
for i in range(num_layers):
layer = DenseLayer(input_size + i * growth_rate, growth_rate, bn_size, drop_rate)
self.add_module('denselayer%d' % (i + 1,), layer)
然后编写Transition,用来连接不同的DenseBlock,缩小特征图的维度
class Transition(nn.Sequential):
def __init__(self, input_size, output_size):
super().__init__()
self.add_module('norm', nn.BatchNorm2d(input_size))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(input_size, output_size, kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(2, stride=2))
最后编写DenseNet模块
class DenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), init_features=64,
bn_size=4, compress_rate=0.5, drop_rate = 0, num_class=1000):
super().__init__()
self.features = nn.Sequential(collections.OrderedDict([
('conv0', nn.Conv2d(3, init_features, kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', nn.BatchNorm2d(init_features)),
('relu0', nn.ReLU(inplace=True)),
('pool0', nn.MaxPool2d(3, stride=2, padding=1))
]))
num_features = init_features
for i, layer_conf in enumerate(block_config):
block = DenseBlock(layer_conf, num_features, growth_rate, bn_size, drop_rate)
self.features.add_module('denseblock%d' % (i + 1,), block)
num_features += layer_conf*growth_rate
if i != len(block_config) - 1:
transition = Transition(num_features, int(num_features*compress_rate))
self.features.add_module('transition%d' % (i + 1,), transition)
num_features = int(num_features*compress_rate)
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
self.features.add_module('relu5', nn.ReLU(inplace=True))
self.classifier = nn.Linear(num_features, num_class)
# 参数初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out
由于默认的参数直接对应的就是DenseNet121的,我们直接创建模型对象
model = DenseNet(num_class=len(class_names))
model
打印一下模型的结构如下
DenseNet(
(features): Sequential(
(conv0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(norm0): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu0): ReLU(inplace=True)
(pool0): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(denseblock1): DenseBlock(
(denselayer1): DenseLayer(
(norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): DenseLayer(
(norm1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer3): DenseLayer(
(norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer4): DenseLayer(
(norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer5): DenseLayer(
(norm1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer6): DenseLayer(
(norm1): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition1): Transition(
(norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock2): DenseBlock(
(denselayer1): DenseLayer(
(norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): DenseLayer(
(norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer3): DenseLayer(
(norm1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer4): DenseLayer(
(norm1): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer5): DenseLayer(
(norm1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer6): DenseLayer(
(norm1): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(288, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer7): DenseLayer(
(norm1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(320, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer8): DenseLayer(
(norm1): BatchNorm2d(352, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(352, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer9): DenseLayer(
(norm1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer10): DenseLayer(
(norm1): BatchNorm2d(416, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(416, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer11): DenseLayer(
(norm1): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(448, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer12): DenseLayer(
(norm1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(480, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition2): Transition(
(norm): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock3): DenseBlock(
(denselayer1): DenseLayer(
(norm1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): DenseLayer(
(norm1): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(288, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer3): DenseLayer(
(norm1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(320, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer4): DenseLayer(
(norm1): BatchNorm2d(352, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(352, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer5): DenseLayer(
(norm1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer6): DenseLayer(
(norm1): BatchNorm2d(416, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(416, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer7): DenseLayer(
(norm1): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(448, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer8): DenseLayer(
(norm1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(480, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer9): DenseLayer(
(norm1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer10): DenseLayer(
(norm1): BatchNorm2d(544, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(544, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer11): DenseLayer(
(norm1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(576, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer12): DenseLayer(
(norm1): BatchNorm2d(608, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(608, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer13): DenseLayer(
(norm1): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(640, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer14): DenseLayer(
(norm1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(672, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer15): DenseLayer(
(norm1): BatchNorm2d(704, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(704, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer16): DenseLayer(
(norm1): BatchNorm2d(736, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(736, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer17): DenseLayer(
(norm1): BatchNorm2d(768, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer18): DenseLayer(
(norm1): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(800, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer19): DenseLayer(
(norm1): BatchNorm2d(832, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer20): DenseLayer(
(norm1): BatchNorm2d(864, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(864, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer21): DenseLayer(
(norm1): BatchNorm2d(896, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer22): DenseLayer(
(norm1): BatchNorm2d(928, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(928, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer23): DenseLayer(
(norm1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(960, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer24): DenseLayer(
(norm1): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition3): Transition(
(norm): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock4): DenseBlock(
(denselayer1): DenseLayer(
(norm1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): DenseLayer(
(norm1): BatchNorm2d(544, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(544, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer3): DenseLayer(
(norm1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(576, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer4): DenseLayer(
(norm1): BatchNorm2d(608, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(608, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer5): DenseLayer(
(norm1): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(640, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer6): DenseLayer(
(norm1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(672, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer7): DenseLayer(
(norm1): BatchNorm2d(704, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(704, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer8): DenseLayer(
(norm1): BatchNorm2d(736, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(736, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer9): DenseLayer(
(norm1): BatchNorm2d(768, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer10): DenseLayer(
(norm1): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(800, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer11): DenseLayer(
(norm1): BatchNorm2d(832, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer12): DenseLayer(
(norm1): BatchNorm2d(864, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(864, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer13): DenseLayer(
(norm1): BatchNorm2d(896, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer14): DenseLayer(
(norm1): BatchNorm2d(928, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(928, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer15): DenseLayer(
(norm1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(960, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer16): DenseLayer(
(norm1): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(norm5): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu5): ReLU(inplace=True)
)
(classifier): Linear(in_features=1024, out_features=2, bias=True)
)
通过torchinfo的summary预估参数量
summary(model, input_size=(32, 3, 224, 224))
打印结果如下:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
DenseNet [32, 2] --
├─Sequential: 1-1 [32, 1024, 7, 7] --
│ └─Conv2d: 2-1 [32, 64, 112, 112] 9,408
│ └─BatchNorm2d: 2-2 [32, 64, 112, 112] 128
│ └─ReLU: 2-3 [32, 64, 112, 112] --
│ └─MaxPool2d: 2-4 [32, 64, 56, 56] --
│ └─DenseBlock: 2-5 [32, 256, 56, 56] --
│ │ └─DenseLayer: 3-1 [32, 96, 56, 56] 45,440
│ │ └─DenseLayer: 3-2 [32, 128, 56, 56] 49,600
│ │ └─DenseLayer: 3-3 [32, 160, 56, 56] 53,760
│ │ └─DenseLayer: 3-4 [32, 192, 56, 56] 57,920
│ │ └─DenseLayer: 3-5 [32, 224, 56, 56] 62,080
│ │ └─DenseLayer: 3-6 [32, 256, 56, 56] 66,240
│ └─Transition: 2-6 [32, 128, 28, 28] --
│ │ └─BatchNorm2d: 3-7 [32, 256, 56, 56] 512
│ │ └─ReLU: 3-8 [32, 256, 56, 56] --
│ │ └─Conv2d: 3-9 [32, 128, 56, 56] 32,768
│ │ └─AvgPool2d: 3-10 [32, 128, 28, 28] --
│ └─DenseBlock: 2-7 [32, 512, 28, 28] --
│ │ └─DenseLayer: 3-11 [32, 160, 28, 28] 53,760
│ │ └─DenseLayer: 3-12 [32, 192, 28, 28] 57,920
│ │ └─DenseLayer: 3-13 [32, 224, 28, 28] 62,080
│ │ └─DenseLayer: 3-14 [32, 256, 28, 28] 66,240
│ │ └─DenseLayer: 3-15 [32, 288, 28, 28] 70,400
│ │ └─DenseLayer: 3-16 [32, 320, 28, 28] 74,560
│ │ └─DenseLayer: 3-17 [32, 352, 28, 28] 78,720
│ │ └─DenseLayer: 3-18 [32, 384, 28, 28] 82,880
│ │ └─DenseLayer: 3-19 [32, 416, 28, 28] 87,040
│ │ └─DenseLayer: 3-20 [32, 448, 28, 28] 91,200
│ │ └─DenseLayer: 3-21 [32, 480, 28, 28] 95,360
│ │ └─DenseLayer: 3-22 [32, 512, 28, 28] 99,520
│ └─Transition: 2-8 [32, 256, 14, 14] --
│ │ └─BatchNorm2d: 3-23 [32, 512, 28, 28] 1,024
│ │ └─ReLU: 3-24 [32, 512, 28, 28] --
│ │ └─Conv2d: 3-25 [32, 256, 28, 28] 131,072
│ │ └─AvgPool2d: 3-26 [32, 256, 14, 14] --
│ └─DenseBlock: 2-9 [32, 1024, 14, 14] --
│ │ └─DenseLayer: 3-27 [32, 288, 14, 14] 70,400
│ │ └─DenseLayer: 3-28 [32, 320, 14, 14] 74,560
│ │ └─DenseLayer: 3-29 [32, 352, 14, 14] 78,720
│ │ └─DenseLayer: 3-30 [32, 384, 14, 14] 82,880
│ │ └─DenseLayer: 3-31 [32, 416, 14, 14] 87,040
│ │ └─DenseLayer: 3-32 [32, 448, 14, 14] 91,200
│ │ └─DenseLayer: 3-33 [32, 480, 14, 14] 95,360
│ │ └─DenseLayer: 3-34 [32, 512, 14, 14] 99,520
│ │ └─DenseLayer: 3-35 [32, 544, 14, 14] 103,680
│ │ └─DenseLayer: 3-36 [32, 576, 14, 14] 107,840
│ │ └─DenseLayer: 3-37 [32, 608, 14, 14] 112,000
│ │ └─DenseLayer: 3-38 [32, 640, 14, 14] 116,160
│ │ └─DenseLayer: 3-39 [32, 672, 14, 14] 120,320
│ │ └─DenseLayer: 3-40 [32, 704, 14, 14] 124,480
│ │ └─DenseLayer: 3-41 [32, 736, 14, 14] 128,640
│ │ └─DenseLayer: 3-42 [32, 768, 14, 14] 132,800
│ │ └─DenseLayer: 3-43 [32, 800, 14, 14] 136,960
│ │ └─DenseLayer: 3-44 [32, 832, 14, 14] 141,120
│ │ └─DenseLayer: 3-45 [32, 864, 14, 14] 145,280
│ │ └─DenseLayer: 3-46 [32, 896, 14, 14] 149,440
│ │ └─DenseLayer: 3-47 [32, 928, 14, 14] 153,600
│ │ └─DenseLayer: 3-48 [32, 960, 14, 14] 157,760
│ │ └─DenseLayer: 3-49 [32, 992, 14, 14] 161,920
│ │ └─DenseLayer: 3-50 [32, 1024, 14, 14] 166,080
│ └─Transition: 2-10 [32, 512, 7, 7] --
│ │ └─BatchNorm2d: 3-51 [32, 1024, 14, 14] 2,048
│ │ └─ReLU: 3-52 [32, 1024, 14, 14] --
│ │ └─Conv2d: 3-53 [32, 512, 14, 14] 524,288
│ │ └─AvgPool2d: 3-54 [32, 512, 7, 7] --
│ └─DenseBlock: 2-11 [32, 1024, 7, 7] --
│ │ └─DenseLayer: 3-55 [32, 544, 7, 7] 103,680
│ │ └─DenseLayer: 3-56 [32, 576, 7, 7] 107,840
│ │ └─DenseLayer: 3-57 [32, 608, 7, 7] 112,000
│ │ └─DenseLayer: 3-58 [32, 640, 7, 7] 116,160
│ │ └─DenseLayer: 3-59 [32, 672, 7, 7] 120,320
│ │ └─DenseLayer: 3-60 [32, 704, 7, 7] 124,480
│ │ └─DenseLayer: 3-61 [32, 736, 7, 7] 128,640
│ │ └─DenseLayer: 3-62 [32, 768, 7, 7] 132,800
│ │ └─DenseLayer: 3-63 [32, 800, 7, 7] 136,960
│ │ └─DenseLayer: 3-64 [32, 832, 7, 7] 141,120
│ │ └─DenseLayer: 3-65 [32, 864, 7, 7] 145,280
│ │ └─DenseLayer: 3-66 [32, 896, 7, 7] 149,440
│ │ └─DenseLayer: 3-67 [32, 928, 7, 7] 153,600
│ │ └─DenseLayer: 3-68 [32, 960, 7, 7] 157,760
│ │ └─DenseLayer: 3-69 [32, 992, 7, 7] 161,920
│ │ └─DenseLayer: 3-70 [32, 1024, 7, 7] 166,080
│ └─BatchNorm2d: 2-12 [32, 1024, 7, 7] 2,048
│ └─ReLU: 2-13 [32, 1024, 7, 7] --
├─Linear: 1-2 [32, 2] 2,050
==========================================================================================
Total params: 6,955,906
Trainable params: 6,955,906
Non-trainable params: 0
Total mult-adds (G): 90.66
==========================================================================================
Input size (MB): 19.27
Forward/backward pass size (MB): 5777.06
Params size (MB): 27.82
Estimated Total Size (MB): 5824.16
==========================================================================================
模型训练
编写训练函数
def train(train_loader, model, loss_fn, optimizer):
size = len(train_loader.dataset)
num_batches = len(train_loader)
train_loss, train_acc = 0, 0
for x, y in train_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss /= num_batches
train_acc /= size
return train_loss, train_acc
编写测试函数
def test(test_loader, model, loss_fn):
size = len(test_loader.dataset)
num_batches = len(test_loader)
test_loss, test_acc = 0, 0
for x, y in test_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
test_loss += loss.item()
test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
test_acc /= size
return test_loss, test_acc
正式训练
optimizer = optim.Adam(model.parameters(), lr=1e-4)
loss_fn = nn.CrossEntropyLoss()
epochs = 20
train_loss, train_acc = [], []
test_loss, test_acc = [], []
best_acc = 0
for epoch in range(epochs):
model.train()
epoch_train_loss, epoch_train_acc = train(train_loader, model, loss_fn, optimizer)
model.eval()
with torch.no_grad():
epoch_test_loss, epoch_test_acc = test(test_loader, model, loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = optimizer.state_dict['param_groups'][0]['lr']
print(f"Epoch:{epoch+1:2d}, Train_acc:{epoch_train_acc*100:.1f}, Train_loss: {epoch_train_loss:.3f}, Test_acc: {epoch_test_acc*100:.1f}, Test_loss: {epoch_test_loss:.3f}, Lr: {lr:.2E}")
PATH = './best_model.pth'
torch.save(best_model.state_dict(), PATH)
print('Done')
过程日志如下:
Epoch: 1, Train_acc:87.4, Train_loss: 0.304, Test_acc: 87.7, Test_loss: 0.302, Lr: 1.00E-04
Epoch: 2, Train_acc:88.9, Train_loss: 0.273, Test_acc: 86.0, Test_loss: 0.314, Lr: 1.00E-04
Epoch: 3, Train_acc:89.9, Train_loss: 0.244, Test_acc: 89.0, Test_loss: 0.268, Lr: 1.00E-04
Epoch: 4, Train_acc:90.5, Train_loss: 0.230, Test_acc: 88.7, Test_loss: 0.255, Lr: 1.00E-04
Epoch: 5, Train_acc:91.3, Train_loss: 0.213, Test_acc: 88.5, Test_loss: 0.293, Lr: 1.00E-04
Epoch: 6, Train_acc:91.6, Train_loss: 0.205, Test_acc: 89.9, Test_loss: 0.265, Lr: 1.00E-04
Epoch: 7, Train_acc:92.5, Train_loss: 0.191, Test_acc: 89.3, Test_loss: 0.267, Lr: 1.00E-04
Epoch: 8, Train_acc:92.9, Train_loss: 0.176, Test_acc: 88.7, Test_loss: 0.277, Lr: 1.00E-04
Epoch: 9, Train_acc:93.3, Train_loss: 0.166, Test_acc: 89.9, Test_loss: 0.236, Lr: 1.00E-04
Epoch:10, Train_acc:93.8, Train_loss: 0.157, Test_acc: 90.5, Test_loss: 0.248, Lr: 1.00E-04
Epoch:11, Train_acc:94.5, Train_loss: 0.141, Test_acc: 91.6, Test_loss: 0.219, Lr: 1.00E-04
Epoch:12, Train_acc:95.2, Train_loss: 0.122, Test_acc: 90.2, Test_loss: 0.274, Lr: 1.00E-04
Epoch:13, Train_acc:95.3, Train_loss: 0.128, Test_acc: 90.0, Test_loss: 0.302, Lr: 1.00E-04
Epoch:14, Train_acc:95.5, Train_loss: 0.115, Test_acc: 92.3, Test_loss: 0.229, Lr: 1.00E-04
Epoch:15, Train_acc:96.5, Train_loss: 0.090, Test_acc: 90.2, Test_loss: 0.311, Lr: 1.00E-04
Epoch:16, Train_acc:97.0, Train_loss: 0.087, Test_acc: 89.6, Test_loss: 0.297, Lr: 1.00E-04
Epoch:17, Train_acc:96.4, Train_loss: 0.096, Test_acc: 93.0, Test_loss: 0.216, Lr: 1.00E-04
Epoch:18, Train_acc:97.7, Train_loss: 0.067, Test_acc: 90.5, Test_loss: 0.324, Lr: 1.00E-04
Epoch:19, Train_acc:97.0, Train_loss: 0.081, Test_acc: 91.6, Test_loss: 0.272, Lr: 1.00E-04
Epoch:20, Train_acc:98.2, Train_loss: 0.060, Test_acc: 89.9, Test_loss: 0.352, Lr: 1.00E-04
Done
模型效果展示
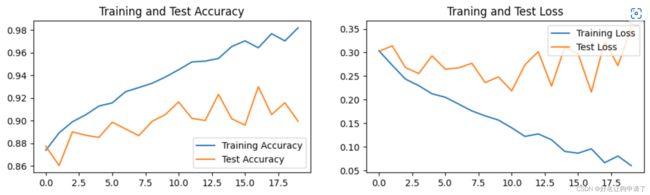
展示Loss和Accuracy图
epochs_range = range(epochs)
plt.figure(figsize=(12,3))
plt.subplot(1,2,1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Test Accuracy')
plt.subplot(1,2,2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Traning and Test Loss')
plt.show()
模型评估
best_model.load_state_dict(torch.load(PATH, map_location=device))
epoch_test_acc, epoch_test_loss =test(test_loader, best_model, loss_fn)
print(epoch_test_acc, epoch_test_loss)
![]()
总结与心得体会
DenseNet在跨层连接也是使用了RestNet2的BN-RELU-CONV的顺序,但是在ResNet的基础上把前面模型的输出堆叠起来,使得层间的连接更加密集。这种连接让我感觉和U-Net等连接有些同样的妙处,可以减少模型特征图中的特征丢失。但是如此密集的连接会增大参数量,训练的速度显著的变慢了(或许下次应该弄个新的机器),因此还有很大的改进空间。