LeetCode 剑指offer刷题笔记
本文仅仅是个人写代码时遇到的问题总结!
但也欢迎有大佬指出我理解上的错误!
三刷题单
03
03. 数组中重复的数字
很简单的题。三刷主要看了不开任何空间的方法。
主要思路是,让数据归位。一开始数据是混乱的,而且题目给出的数据范围就是在 0 ~ n - 1。如果nums[i] != i ,数据不在原本的位置上,那就跟这个位置的数据交换nums[i], nums[nums[i] ]
相等就i ++ ;continue;
如何确定重复?在后面的遍历中,此时的nums[i] 想要换到 原本的位置,但是发现原本位置nums[nums[i]] 两者相等,说明已经归位了,这个就是重复值。
04. 二维数组中的查找
看解答,k神思路已经很帅了
二刷问题:思路有了记忆,没写出来,首先把列删除是j++,行删除是i - -.
三刷过
05. 替换空格
Q:如何取代已有的字符串中的字符的方法?
A:可以新建一个字符串array,对于满足条件的字符使用push_back()放入array,需要替换的直接将替换后的字符放入array。
也可以使用array[size++]一边增加容量一边放入。
push()对于使用stack和queue,push_back对于使用vector,string等。
二刷:二刷的时候饶了个弯子,先定义了一个vector< char >ans,,按照套路放进ans,然后又定义了个string res,循环把ans的每个字符加进res最后return res,,多此一举,,string可以直接push_back()!!!
06. 从尾到头打印链表
Q:如何倒序输出链表?
A:用另外两个容器一个stack(因为先进后出)一个vector(记录答案的数组容器),将链表的数据push()入stack,再每次取出stack的top() push_back()入vector,并弹出pop(),直到为空。
二刷:直接用一个vector存数据,用reverse函数反转过来就行了。
07. 重建二叉树
二刷依然不会写。总结一下二刷感悟:
二叉树的题左右节点基本都是递归,所以找左右节点的方法更加重要,因为只要递归就行。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution
{
public:
unordered_map<int,int> index;
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder)
{
int n = preorder.size();
for(int i =0;i<n;i++)
{
index[inorder[i]] = i;//记录中序遍历的位置。
}
return mybuildTree(preorder,inorder,0,n-1,0,n-1);//开始递归
}
TreeNode* mybuildTree(vector<int>& preorder, vector<int>& inorder,int preorder_left,int preorder_right,int inorder_left,int inorder_right)
//后四个数据分别是树的先序遍历的左端,右端,中序遍历的左端、右端
{
if(preorder_left > preorder_right)
{
return NULL;
}
int preorder_root = preorder_left;//先序遍历的首位是根节点
int inorder_root = index[preorder[preorder_root]];//找到该根节点在中序遍历中的位置,方便于以之为中心,分成左右子树
TreeNode* root = new TreeNode(preorder[preorder_left]);//构造二叉树,新建一个根节点,然后把左右子树放入
int left_subtree = inorder_root - inorder_left;//计算出左子树的范围,右子树可以根据左子树得出
root->left = mybuildTree(preorder,inorder,preorder_root+1,preorder_root+left_subtree,inorder_left,inorder_root-1);
//左子树 分别是前序遍历的根到前序遍历+左子树大小
//也是中序遍历的左节点到中心根节点-1
root->right = mybuildTree(preorder,inorder,preorder_root+left_subtree+1,preorder_right,inorder_root+1,inorder_right);
return root;//返回这个跟节点
}
};
09. 用两个栈实现队列
笔记:首先一开始没看懂这题输入输出啊,简单写一下。
输入:
["CQueue","appendTail","deleteHead","deleteHead"]
[[],[3],[],[]]
输出:[null,null,3,-1]
意思是:代表一开始声明,输出队列啥也没有,返回第一个null
在队列中放入数3,输出还是啥也没有,返回null
del输出队列第一个元素,返回3,
此时的队列已经没有元素了,再del只能返回默认值-1了。
大致写写解题过程:
两个栈合成一个队列,关键是,一个栈是输入栈,一个栈是输出栈,输入栈放入数据 ,当到输出时,用输出栈来过度,把输入栈的数全部都放入输出栈,此时输出栈的元素恰好是输入时的倒序,这样再从输出栈输出,,就和队列一样,先进先出。
分以下几种情况:
一开始,没有放入数据,s1为空,那直接返回-1;
插入几个数据后开始del输出,那么用while循环输出s1数据放入s2,再把s2的栈顶输出。
插入几个数据输出几个数据但是s2并没有全出去,所以此时再输出数据只需要继续把s2遗留的数据输出了就行。
二刷:思路有,但是写代码的思绪很混乱。理一下思绪。
删除方法:
(1)如果s2已经有数据,就要先返回数据。我错在先判断s1是否为空了,如果先判断s1,有可能在上次输出时,已经把s1中的数据全部给了s2,数据没有输出完s1也为空了,导致错误。
(2)把s1的数据放入s2的时候不需要提前判断s2是否为空,因为已经之前需要提前判断s2不为空就直接返回首位了。
10- I. 斐波那契数列
二刷:二刷出问题了惭愧啊
二刷一上来就递归,妥妥的超时。这题应该使用循环 sum = (a+b) a=b,b=sum,最后返回a。自己手算就知道了。
11. 旋转数组的最小数字
笔记:
这题使用二分法更好,遇到递增数据就要想起二分法!!!
二分的原理:
假设数据为
1 3 7 8 10 11 14
第一种可能:中间值大于最右的值
7 8 10 11 14 1 3
那么最小值只能在中间值到右半部分,所以左半部分忽略
low = pivot+1
至于这个**+1**,,显然中间值不是最小值,所以没必要再次列入比较
第二种:中间值小于最右值
11 14 1 3 7 8 10
那么最小值只能在中间值到左半部分,所以右半部分忽略
high = pivot
第三种:中间值与最右值相等
1 2 2 2 2 -> 2 2 2 1 2
虽然无法进行判断,但是可以将最右边的值删除也不影响比较
high -= 1
二刷看笔记就会写了…但还是有点问题。
第二种方法还是没理解透,最小值是在左半部分写错成右半部分了。
12. 矩阵中的路径
一刷没做笔记二刷还是不会。。。
二刷:
(1)dfs()肯定的,但是要剪枝。
(2)dfs中返回真的条件是step == word.size()-1,,搜索路径是从0开始的。
(3)K神有个很秀的方法,每次走过的地方,就把当前的board[i][j]置为
空’\0’,,为空了就一定不会再走到这里了因为不可能匹配成功。但是回溯要把他重新置为原来的值,只需要board[i][j]==word[k].
(4)用res返回每次搜索的值,四个方向只要有一个方向返回true就可,一开始在纠结程序如何判断匹配这个点可以走到的,,看返回false的条件,,如果此时board[i][j]与word[k]不匹配直接返回false了。
13. 机器人的运动范围
二刷:只写了大概的框架,知道是dfs,但是还是有点错误。
(1)行和列的变量搞混乱了晕死。
(2)对于dfs纠结如何返回返回什么值已知在纠结。。他这里只需要得到步数,dfs为void 型就可了,,step为全局变量,每次搜索dfs时都加一,main方法中只需要返回这个step就可。
14- I. 剪绳子
二刷依然不会,看K神数学题解吧。
14-II. 剪绳子 II
二刷:不会,虽然方法跟上面那个一样,但是涉及了一个大数的问题。数据直接求n次方会很大。所以方法是求出a = n/3,然后再定义一个Longlong型变量,循环a-1次,每次乘以3,乘以3后就求余,这样再做余数b的判断时就不会炸掉。至于为什么是a-1次,,因为最后有个余数,那个余数是要跟最后a进行融合的。
15. 二进制中1的个数
死记,两种写法。老经典了。
(1)
int ans = 0;
while(n)
{
ans += n&1;
n>>=1;
}
return ans;
(2)
int i = 0;
while(n)
{
n &= (n-1);
i++;
}
return i;
16. 数值的整数次方
看K神思路。
17. 打印从1到最大的n位数
方法一:有几位数sum就乘几个10,从1输出sum-1,,但是大数不可行。
方法二:分治法。用字符串存储。思路是从第0位到第n-1位,递归枚举每一位,然后去除头0;
关于如何将字符串中的头0去除
思路:ptr从第0位开始判断,如果从第0位开始,计算有多少个0,如果第一个不是0就不用加。然后判断Ptr与s.size()是否相等。不相等就从ptr位开始接取转换成int放入答案中。
void save()
{
int ptr = 0;
while(ptr < s.size() && s[ptr] == '0')//s[ptr] == '0'必须有这个,ptr从第0位开始,如果第一位不是0,就不用加这个值
{
ptr++;//计算从第一位开始头0
}
if(ptr != s.size())
{
num.emplace_back(stoi(s.substr(ptr)));
}
}
//substr只有一个参数,pos,,截取从第pos位以后的字符
18. 删除链表的节点
笔记:删除链表节点需要明确 当前节点cur, 当前节点的前一个节点pre ,当前节点的后一个节点cur->next,作用分别是:
pre:修改引用。当找到val时(cur->val == val)跳出循环,pre->next = cur->next。这里要记住,链表不是数组!不是一个个放入结果里,所以只要记录了pre->next = cur->next这个方向,之后的数据自然就连接上了。相当于只是跳过了删除点,其他的之间的关联不变!
cur:判断当时节点的数据是否相等
cur->next:一是完成循环往下找,二是完成跳过cur->val == val
dummynode定义模板:
ListNode* dummy= new ListNode();
dummy->next = head;
ListNode* pre = dummy, *cur = head;
ListNode* dummyhead= new ListNode();
ListNode* cur = dummyhead;
二刷还是不会,啧。
卡点一:没记住链表题的基本规则,,处理链表中的某个点,是肯定要知道当前点cur和前驱pre 的,另外dummynode还是没记住要New。
卡点二:循环条件错误。这题循环条件只需要判断当前点的值是否为val,不是val继续循环遍历就好了。
卡点三:把cur->val == val的情况处理判断放到循环内了,外循环判断不等于才进入循环,循环内才判断if是否相等删除,,那么第一个点如果就是val,,则无法进入循环且无法删除。
203. 移除链表元素与18很相似,但是18题只考虑了链表中只删除一个值的情况,203考虑多个值。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeElements(ListNode* head, int val)
{
ListNode* dummyhead = new ListNode(-1);
dummyhead->next = head;
ListNode* pre = dummyhead;
ListNode* cur = head;
while(pre->next)
{
if(cur->val == val)
{
pre->next = cur->next;
}
else
{
pre = cur;
}
cur = cur->next;
}
return dummyhead->next;
}
};
还是有几个问题,写这种题还是不熟练。
(1)可以判断出需要定义哑结点,但是并不是用哑结点来操作链表啊,还需要定义一个pre = dummy,,接下来操作pre.
(2)一开始超时了,把cur = cur->next写进else里了,这是没有考虑到cur->val == val时,我只移动了pre节点但是没有移动cur节点。
(3)最后的返回值不是dummyhead!!是dummmyhead->next
21. 调整数组顺序使奇数位于偶数前面
笔记:双指针。left和right,nums[left]为奇数,则left++,往后继续判断,反之不加,保留位置;right同,当左边找到奇数,右边找到偶数,交换数据。使用swap函数。在函数里,可以写num[left++],不影响数据,同时位置后移动继续判断。
二刷过了,但是一个细节。交换数据可以用swap函数
22. 链表中倒数第k个节点
笔记:使用双指针,former和Latter,former先走k步,然后只要former不为空,即走到最后,latter同时往后走,此时返回的latter就是答案。
二刷:用了一个朴素的方法。
class Solution
{
public:
ListNode* getKthFromEnd(ListNode* head, int k)
{
ListNode* dummyhead = new ListNode();
dummyhead = head;
int sum = 0,res;
while(dummyhead)
{
sum++;
dummyhead = dummyhead->next;
}
res = sum - k;
// cout<
while(res--)
{
head = head->next;
}
return head;
}
};
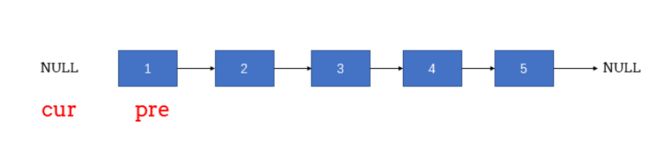
24. 反转链表
二刷还是不会写。思路只有一个,就是记录前驱和当前节点。原状态下pre是cur的后继,cur->next = pre,题目就需要把pre->next = cur。
原状态
更改的状态
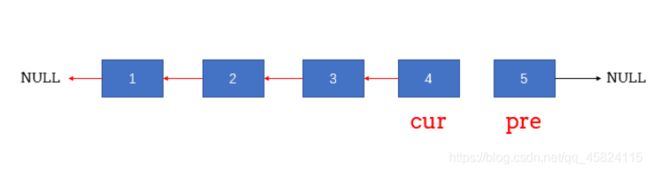
其中变化的细节有一些:
(1)要先记录下pre的next,这是链表不断循环遍历的依据。
(2)然后就是要改变指向了,把pre的next指向cur。
(3)接下来要移动cur和pre。cur 的下一个恰好就是为改变的pre,pre的下一个就是(1)中记录的tmp值。
25. 合并两个排序的链表
笔记:这题就是循环在两个链表里不断对比,谁小用谁。
注意这题用哑结点,答案链表的头结点初始为空。
**二刷:**没写哑结点,思路还是有的。
还有一个点,最后谁先空,就把cur->next直接指向另一个。
26. 树的子结构
笔记:
bool isSubStructure(TreeNode* A, TreeNode* B)
意思是以A,为根节点判断是否有B;
bool isContain(TreeNode* A,TreeNode* B)
是在A各个子节点中找是否有B;
二刷:不会写啊,遇到树我的脑子就一片空白
在 isSubStructure(TreeNode* A, TreeNode* B) 中,一方面判断极端情况,A空或者B空,直接return false。反之开始递归,要么A->left节点里找,与B继续递归,要么在A->right节点找,或者直接搜寻isContain(A,B),三者有一个为true则为true
那么关于isContain(TreeNode* A,TreeNode* B),这个函数里如果B为空了,那么说明遍历完B,为真。如果A先空,或者A,B值不相等,直接false。
反之,搜寻A->left和A->right与B是否都包含了B
27. 二叉树的镜像
笔记:二叉树最重要的就是会递归!!通过递归,记录左右节点,再交换。
TreeNode* lt = mirrorTree(root->left);
TreeNode* rt=mirrorTree(root->right);
root->right=lt;
root->left=rt;
二刷:不会。树好难。。。找到最底层最左和最右,然后交换。当然找底层是用递归找,返回到上一层也是递归返回。最后return root;
28. 对称的二叉树
笔记:是否对称的关键在于,left->left, right->right是否相等&&left->right, right->left 是否相等,或者left和right两者同时为空也可以。其余一者为空或者值不相等皆为false。
二刷:树我跟你不共戴天!!!
思路上,要把大问题分解到小问题小数去看。分解到最底层的树,镜像相同就是,左边的最左侧等于右边的最右侧,左边的右侧等于右边的左侧。
29. 顺时针打印矩阵
笔记:每次进行边界判断,是先++||- -再判断!!!
![]()
二刷:不会,换了一种方法。使用一个dir数组表示方向,和index来进行方向的变化。
核心算法思路:
先把当前数据放入ans并标记为true。下一步如何走,可以先假设判断。声明nextcol和nextrow变量为原有方向的下一个数据。判断这两个变量是否越界或者这个数值已经走过为true,Index改变index = (index + 1) % 4;。row和col再根据新的index值走向下一步。
tips,ans一开始声明的时候不要初始化又使用push_back放入数据。会有一堆初始化的0堆在正确答案前。
错误示范:
vector<int> ans(cols * rows);
...
ans.push_back(matrix[row][col]);
...结果:
[0,0,0,1,2,3];
30. 包含min函数的栈
笔记:
使用辅助栈B。正常栈的操作A不变,每次放入一个x时,判断当前x是否小于辅助栈的栈顶,小于等于则放入,不小于则不管,则栈顶就是最小值。
取出时pop()判断此时A取出的数是否等于B的栈顶,等于将B中栈顶一起弹出
辅助栈B要初始化!!!
MinStack()
{
B.push(INT_MAX);//初始化辅助栈
}
二刷:看了笔记反复Debug 写出来了,记录一下debug的过程。
(1)x <= B.top() 就放入B,最小值可以有多个相同的数据。
(2)返回最小值是返回B.top(),但是一开始为了比较,B中放入了INT_MAX,所以不能直接return B.top(),否则没有放入数据的时候也会把INT_MAX返回,也不能判断B.top() == INT_MAX而时候返回0,因为可能就只放入了最大值结果else返回了0。要先判断A是否为空。
31. 栈的压入、弹出序列
笔记:难得有一题能和K神思路一致了(哭泣)
这题就是用辅助栈。pushed栈怎么压进去的,stk也怎么压进去,但是如果在popped栈的头遇到了,就循环判断把skt栈的top给弹出去。最后判断skt栈是否为空。
二刷没写出来。。。里循环判断有些问题,要判断skt是否为空,对于popped数组,不需要把popped数据弹出,定义一个i,如果匹配成功,i++;最后判断stk是否为空就可。
32 - I. 从上到下打印二叉树
笔记:这种一层一层遍历的,跟书上说道BFS跟DFS区别时一模一样。所以毫无疑问,BFS。
定义队列q,先把root放进去,(当然要先判断是否有root);循环判断q是否为空,每次都把node的节点的左右节点进行判断是否存在,存在就从左到右压入q,再循环按照BFS的套路打印。
二刷没写出来,但是思路很清晰,不会写代码。首先,错在队列的声明,正确的写法queue而不是int型,如果只是传入数据,无法每次判断左右节点是否存在。
32 - II. 从上到下打印二叉树 II
笔记:(尽量说明白吧)
首先,他需要返回一个二维数组,所以vector
然后开始分析具体首先方法:
先将根节点放入q,只要q不为空则持续循环(模板)
需要定义一个 vector tmp;这是记录每一层的数据,等每一层数据记录完时,将这一层数据的数组放入ans中。
开始内循环。作用是循环每一层的数据,所以从q.size()到1。
用node记录q.front(),将node的val值放入tmp,弹出q.front。然后继续判断node是否有子节点。如果有子节点,将子节点放入q末尾进行下一层判断。
二刷没写出。首先输出结果是二维数组,一个便捷的方法就是定义一个临时一维数组,每一层放入数据完后再将整个临时数组放入二维数组。二是错在没有内循环,需要内循环把每一层遍历一遍。
32 - III. 从上到下打印二叉树 III
笔记:
首先啊,看题啊,结果是二维数组啊res,我同时定义一个一维数组ans来暂时储存每次读取完一层的值,读完一层放入res一次。所以每次也要把ans清空clear();
多一个判断,定义一个数,每次读完一层,就把这个值取反,如果是整数,则正向输出,负数用reverse函数反转ans的数据。
这里,每次读取数据的时候,用了一个for循环,这里的循环边界是q.size()没错,但是不能直接写q.sieze()!!!在这个循环里,每次都在判断根节点是否有左右孩子,如果有就放入q,所以这个时候,q.size()大小又变了啊啊啊!!
只能在外先定义一个int变量储存好这次循环的次数,也就是这一层的数据个数,才不会因为加入下一层的孩子导致q.size()变化。
二刷看了看笔记会了,判空判空判空!!!
33. 二叉搜索树的后序遍历序列
笔记:从树的左边开始,找到第一个大于根节点的位置,该位置之后到根节点之间的值,一定都是树的右子树,所以一定大于根节点。循环判断,不满足就返回假,否则继续遍历左右子树,直到i>=j走完所有节点返回真。
二刷没写出。二叉搜索树特点, 左子树中所有节点的值 < 根节点的值;右子树中所有节点的值 > 根节点的值;其左、右子树也分别为二叉搜索树。
所以需要递归把每一个子树都判断一遍。而且只需要判断右子树是否符合,递归每个子树都右子树就已经遍历里全部节点。
34. 二叉树中和为某一值的路径
笔记:不断递归咯,递归进一个数,target就减一个数,直到此时递归的root的target==0,且左右节点均为空,就把这组数据放入ans。
二刷不断debug写出来了。记录一下啊debug的过程。
就是数组为空,树里没有数据但是target >= 0,直接返回空数组。
35. 复杂链表的复制
一刷没笔记二刷没思路。
这到题就相当于把原来到链表深拷贝一份并且添加一个新指针random。
利用哈希表的查询特点,考虑构建 原链表节点 和 新链表对应节点 的键值对映射关系,再遍历构建新链表各节点的 next 和 random 引用指向即可。unordered_map
那就先声明一个指针遍历整个链表,head不改变否则找不到头。Node* cur = head;
循环遍历只要cur不为空,新建节点把原链表上到数据给新节点。map[cur] = new Node(cur->val); cur = cur->next;。将cur指回head,再次遍历,把下一个节点和random节点都赋值上。最后返回哈希表。
36. 二叉搜索树与双向链表
看K神的题解
二刷完全不会,构建链表题懵的不行。
判空判空判空啊。首先很明显是中序排列。树的中序排列这种题,就是左节点-中间根节点-右节点。且从小树到大树递归。所以代码写法就是左节点不断递归到底,根节点进行链表处理。pre为空则cur节点为 head,不为空,则可以确定 pre的右节点就是cur。双向链表所以还有cur的左节点为pre,并且更新 pre = cur,然后就是一直递归找右节点的底。递归完毕后不要忘记处理head节点,head要跟尾部连接起来。pre在不断递归到底时就等于链表尾部。
37. 序列化二叉树
这题难swl。总结来说,序列化,就是给了一棵树,要求遍历一遍且能够识别这棵树。但是只有树的前中序列或者中后序列才能还原一棵树。这题有个办法就是,把每个叶节点的左右子空节点都记录,就是一个唯一可以识别的树。
反序列化就是把通过序列化给你的字符串,再还原成树。
具体实现:
序列化:BFS,不难了。是数据放入数据和’,’,非数据放入特殊字符标记和“,”。最后不要忘了pop_back(),因为会多放入一个‘,’。
反序列化:也是BFS。首先需要对字符串分割,把字符串内对‘,’和数据分割开。
for(int i=0;i<=data.size();++i)//注意这里是<=
//data.size()最后一个值是字符串的结尾空值,也是最后一次if执行分割子串放入v的条件
{
cout<<i<<":"<<data[i]<<endl;
if(i==data.size()||data[i]==',')
{
temp=data.substr(pre,i-pre);//将每一个节点分割出来加入到v中
pre=i+1;
}
if(!temp.empty())
{
v.emplace_back(temp);
temp.clear();
}
}
初始放入对根节点需要另外创建,也就是字符串第一个数据定义成树节点。放入queue。
TreeNode* root=new TreeNode(stoi(v.front()));
然后就是熟悉的BFS。对于每个节点构造左右节点,为空则放入空,不为空则放入数据
38. 字符串的排列
笔记:这里添加一下一些有点晕的地方。
Q:为什么使用set?
A:set有两个属性,一个是排好序,另一个是没有重复项。可知。
Q:swap作用:
A:


二刷不会啊,还是不要背代码,理解理解正常的dfs。
用一个vis数组标记查重。dfs里循环遍历每个位置上都可出现的字符。如果当前字符被用或者前一个字符与当前字符相同且被用就continue。直到用完所有字符放入结果数组中。
39. 数组中出现次数超过一半的数字
看别人的题解。
二刷用普通排序+中位数方法写出来了。这题可以掌握一个新算法,摩尔投票法。定义一个vote,遇到众数就加一,反之减一。如果该数是众数那么vote一定大于零。如何使用这个规律呢?遍历数组,假设当前数据是众数。不断投票vote当vote归零则舍弃之前的部分。最后留下来的就是众数。
40. 最小的k个数
笔记:使用堆。先将前k个数放入堆中,然后从k开始遍历比较,如果遍历过程中遇到比堆顶更小的值,那就取出堆顶,放入该值,循环往复。最后把堆中数字给结果数组ans就可。
二刷 sort写出来了,但是没什么用。当做不会吧。这题之前在周赛遇到sort超时到自闭。必须学会用堆。
41. 数据流中的中位数
笔记:思路是维护两个堆,一个大根堆一个小根堆,大根堆从大到小排序放入较大的值,小根堆从小到大排序放入较小的值,这样,两个堆的首位top就是中位数的来源,两个堆的大小一致,答案就是两个堆的top之和除以2,奇数就是大根堆的top()。
如何放入值?如果两边大小一致,那新数据王大根堆放,但是要保证大根堆放入的数是较大值,所以先放入小根堆,小根堆的首位再放入大根堆。
二刷 不会。 priority_queue;//从小到大的优先级队列,可将greater改为less,即为从大到小
三刷 加深了记忆
42. 连续子数组的最大和
笔记:动态规划题

如果前一个数是负数,那么对给现在的num[i]降低,所以不加更好,如果是正数,则加在一起。最后得到最大值。
二刷:还是不会、想错了一个方向,不是从每个点加上下一个点大于0,是子集和啊。
三刷 自己推写出来。但是还是要对比学习大佬的方法。
自己:
dp[i] = max(dp[i - 1] + nums[i],nums[i]);
maxn = max(maxn,dp[i]);
大佬:
nums[i] += max(nums[i-1],0);
res = max(res,nums[i]);
大佬的想法就是对原数组进行对比,当前值是否值得加入。
43. 1~n 整数中 1 出现的次数
看K神题解。
二刷:完全懵。按照每个位置上出现0~9与其他位置上的字符来计算1出现的次数。
(1)当前cur == 0,那么出现high * digit次
(2)cur==1,high*digit + low +1;
(3)其余,(high+1)*digit;
45. 把数组排成最小的数
笔记:append()作用:在string字符串后添加字符。
二刷:不会。思路错了。以为只要统计每个字符的次数进行排序,后来才发现,排序时员数据的位置不能乱。
这题的核心是比大小,两个数据x,y如果x + y < y + x(字符拼接);那么x小于y
用一个字符串数组,先一份份的把原数据存入再进行排序并取出
46. 把数字翻译成字符串
Q:关于substr()的使用方法。
A: 第一个参数是从第几个字符开始,第二个参数是复制几个字符。
笔记:关于i的问题。dp[1] 是与s[0]对应的,,所以i从2开始,每次tmp取的是s[i-2]+s[i-1]。
比如字符25,s[0] = 2,s[1] = 5;dp[0]=1,dp[1]=1,,dp[1]代表是字符2即s[0],dp[2]是s[2-2]+s[2-1] = 25…
二刷:动规题,没看出来。不难的,就是考虑前两个值是否可以满足。满足则dp[i] = dp[i - 1] + dp[i - 2];反之不加。
47. 礼物的最大价值
笔记:动规题,,一开始还以为是回溯的我是傻叉
分情况考虑,普遍格子而言,他的值来源于自身和左边或者上边的最大值,对于第一列,只能来源于自身和上面的值,对于第一行,只能来源于左边的值和自身。最后返回右下角的值就可。
二刷:又以为是回溯了。。看了笔记是动规马上就会写了。
48. 最长不含重复字符的子字符串
Q1:这一段啥意思?
if(hashmp.count(s[j]))
{
i = hashmp[s[j]];
}
hashmp[s[j]] = j;
A1:首先啊,这个count(s[j])这里,就是在hashmap里找,看看当前字符在之前是否出现了,count是计数的,如果大于0,则找到了,i 就指向当前已经有重复的之前那个重复的位置(比如abba ,第二个b的时候,i就会找到第一个b)
hashmp[s[j]] = j;就是在做更新,保证每次找到的i 都是最近的一个重复字符,因为每到一个字符就更新了位置。
Q2:tmp是什么意思?
A2:tmp就是相当于dp[i-1],,这里也是K神巧妙之处啊,不用再生成数组,每次动态更新记录。tmp只有上一次走过所以才会更新,,相当于每次判断dmp是否大于等于j-i都是判断上一次的tmp(即 dp[i-1]),判断完毕后,才更新这一次的tmp(即dp[i]),然后再与ans做最大值判断。
Q3:tmp与j-i的大小关系?
A3:详细的在k神解答,相当于如果j-i更小,因为找到了重复项导致i前移,所以比tmp更小,那么如果找到了重复项,此时的tmp则要更新为j-i,j意味着当前字符,i是找到了最近的重复字符后,把i之前所有重复的部分全部扔掉。
二刷: 写出来了。
49. 丑数
笔记:动规题,不算太难。
丑数是建立在所有之前的丑数上的,明确这个就好办了。只要动规,把已知的丑数上* 2或者* 3或* 5的最小值,就是最近的一个丑数。
具体看K神。
二刷 有思路但是不会写。三个指针记录位置不是记录dp具体值就好写一些
50 会写
51. 数组中的逆序对
历史遗留问题终于解决了hhh,视频讲解很清楚。
只有当后半段有序数组中有小于前半段的某个值,可构成逆序对。且个数为前半段数组中还剩下数据个数。
52. 两个链表的第一个公共节点
笔记:很巧的一个方法。双指针node1和node2分别循环,node1先从headA开始,Node2从headB开始,谁先到末尾,就去另一个链表循环。因为如果node1独自的访问的长度是L1+c(c为公共部分),node2则需要访问L2+c,访问完自身去访问别人的长度,当L1+L2+c时则两者相等,找到结果。
二刷 思路都有但是代码写不对…循环条件写成while(ptr1 != ptr2)不是比较值。循环是判断是否为空而不是下一个是否存在。
53 - I. 在排序数组中查找数字 I
Q1:为什么第一次循环找右边界时
if(nums[m]<=target)
第二次寻找左边界时
if(nums[m]<target)
A1: 这是最后离开循环后为判断nums[j]的一个处理。
第一次相等也可以继续让i=m+1,因为临界值在[m+1,j]中且无法判断[m+1,j]之间是否还有与target相等的值,i=m+1依然可以缩小范围继续找右边界。
第二次不想等,因为左边界在[i,m-1]之间,在nums[m]==target情况下,缩小右边不必要的范围,让j=m-1.
Q2:为什么第一次二分后nums[j]=target?
A2:第一次二分时最后一次循环前,i=j,意思是nums[i]=nums[j]=右边界=9。最后一次循环,j=m-1,刚好是右边界的前一个数8,也就是target。
二刷没写出来。思路有,知道是二分找左右点,当然lower_bound函数也是可以的。
换了一个写法,仔细记录一下边界查找过程。
首先查找右边界。
if(nums[mid] <= target)
{
l = mid + 1;
}
else
{
r = mid - 1;
}
当nums[mid] == target,右边可能还有等于target的值,所以压缩左边部分,这也恰好是当nums[mid] < target的操作。
查找左边界
if(nums[mid] >= target)
{
r = mid - 1;
}
else
{
l = mid + 1;
}
当nums[mid] == target,左边可能还有等于target的值,所以压缩右边部分,这也恰好是当nums[mid] > target的操作。
最后的返回值是 right - left - 1,因为找到的边界都是恰好不等于target的边界。
53 - II. 0~n-1中缺失的数字
笔记:老规矩,递增想到二分法。
这题思路是,将数组分为两个部分,一部分是nums[i]==i,另一部分是因为缺失数字而不等于的。二分法要找的就是这个不等于的部分,因为第一个不等于的数就是缺失数字。
然而代码有几个理解的小问题
Q: i,j分别代表什么?为什么最后的答案是返回的i值而不是j值?
A:
结论:变量 i 和 j 分别指向 “右子数组的首位元素” 和 “左子数组的末位元素” 。因此返回 i 即可。
二刷: 没写出来,有思路。想复杂了,用了另一个正确数组每次去比较。其实 l, r记录就是位置,位置就是正确值。只要把位置与数组值进行比较就可以判断出来了。
54. 二叉搜索树的第k大节点
笔记:众所周知,而查实中序遍历是递增的,中序遍历的方法是 左 中 右 那么倒着的中序遍历 右 中 左 就可。用一个数组存储倒着的中序遍历,然后再输出第k-1个值(从0开始)。
二刷: 思路有,但是树题真的不会写代码。遍历需要另外写一个dfs。并且,直接中序遍历是从小到大顺序,题目要求倒着中序遍历更方便。
55 - I. 二叉树的深度
笔记:求深度,递归。要么往左走到底,要么往右走到底,得到左或者右的最大值加一(root自身)
二刷: 不会写二叉树的代码啊晕。这题别想复杂了,当dfs写
56 - I. 数组中数字出现的次数
二刷: 不会。先把所有数据异或一遍。相同的就是 0 ,最后只剩下两个不同数据a ^ b 的异或值。这个异或值中,1代表着a和b中二进制位上不同。通过这个异或值第一个不同的位置,再与其他值异或来分组。
遍历所有的num : nums,(nums & target )== 0分一组,为1 分另外一组。每组数据不断异或。相同的为0不同的留下,最后两组数据剩下的数据就是答案
56 - II. 数组中数字出现的次数 II
二刷: 真的好难啊。尽可能的记录清楚。
关于状态机的部分就不写了,自己手动试试就行。
Q1首先判断语句是如何一点点浓缩成位运算的?
细看K神题解。

首先里if。one的取反与否取决于n 为 0 还是 1 ,1则取反。异或运算中,同为0不同为1
![]()
所以先精简成异或
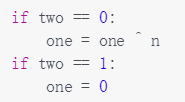
最后一层if。取决于tow是0是1。0则去One ^ n,反之 one为0.
![]()
把if中two判断看成真假就好辨别了,最后的结果
![]()
Q2 为什么只要返回One?
二进制只是表示状态。如果这个数出现了三次,自动机刚好一轮回,回到00。如果只有一次,那么就从00变成了01,只有one部分记录了有效数据,two部分是0,可有可无
57. 和为s的两个数字
笔记:递增–>二分法
分别计算左右点,左右点的和大于target右点左移,反之左点右移,达到了就输出
二刷已过
57 - II. 和为s的连续正数序列
笔记:滑动窗口。
两个指针,一开始都指向1,记录两个指针间的值的和sum。如果sum 更大,左指针加一往右舍掉最左的数据,sum较小则右指针往右加入新数据。
Q1:为什么循环条件i <= target/2???
A1:额???
Q2:为什么for(int k =i;k
A2:仔细看每次的循环,先加入j值,然后就把j+1,也就是说,在刚好sum = target的时候,j也多加了一个1,所以不能去到j。
二刷 没搞出来貌似。这题左右点都从1开始。让r不断递增加入sum,,如果sum加到某个右值过大,那就把左侧 l 遍历减掉,直到等于target。再用一个循环把 l ~ r 之间数据遍历存入答案。
58 - I. 翻转单词顺序
笔记:双指针方法。
i 从尾部开始遍历,遇到一个非空就记录位置right,,然后从这个位置while里循环,非空就i–,每次单词的位置就是i+1到right-i,,如果i==-1,就说明已经到头了。得到单词就放入ans里,别忘了加上空格,也要把最后一个单词的空格删掉。
二刷 我真不会写这种题。
在外循环的 i 是一个 i,内循环改变了 i 的话,就需要在内条件做出相应的答案。离开这个内部条件再次循环,i 就会改变。最后的结果输出需要做切割return ans.substr(0,ans.size() - 1);
58 - II. 左旋转字符串
笔记:记一个有趣的方法。
把s后接一个s,这样从第n个取s.size()个就是答案。
二刷已过
59 - II. 队列的最大值
Q:在每次加入新数据b的时候,为什么可以直接把维护队列最后小于该数据a的值直接删除?不会影响每次取最大值吗?
A:不会。仔细看队列,如果在维护队列中当前这个b还在原来的队列中,最大值的取值永远不会轮到a,然而每次pop出去的值,因为a先存在维护队列里,说明a先进,则先出,也永远不会出现求最大值时b先出a还在的情况。
二刷: 套路都在脑子里但是没写对。首先,确实需要两个队列,但另一个是deque,这样在放入弹出数据的时候,可以选定front或者back.
60. n个骰子的点数
二刷 没写出来,话说我一刷真是分析代码不分析过程的么我在干嘛
动规,正常必超时。这题有背包的味道了。dp[i][j],i个色子总点数 j 的次数。那么边界就是一个色子的时候,1 ~ 6 各出现一次。
对于 i > 2 ,每个 j 是在上一个i - 1个色子的基础上,加上当前cur点。
dp[i][j] += dp[i-1][j-cur];
枚举每个色子,每个点数,以及当前点数的情况。
笔记:不好理解,尽量写懂。
for(int i=1;i<=6;i++)
{
dp[1][i] = 1;
}
这就是动规边界了,即只取了一个筛子的时候,1~6点均出现一次。
for(int i=2;i<=n;i++)//枚举2~n个色子的情况
{
for(int j=i;j<=6*i;j++)//j代表的是所有的点数和。j=i是指此时i个色子,最小也是i个点(i*1),枚举所有点数的情况
{
for(int cur=1;cur<=6;cur++)//当前第i个色子的点数枚举1~6点的情况
{
if(j-cur < i-1)//相当于i-1个色子有j-cur个点数,如果这个点数比i-i还少一定不成立,i-1可以理解为(i-1)*1,相当于两个色子不会出现只有一点数的可能
{
break;
}
dp[i][j] += dp[i-1][j-cur];
}
}
}//这里真的好难啊
61. 扑克牌中的顺子
笔记:首先排序,所以用set存就可;只有不违反两个点则都是真。
一:没有重复的牌;
二:最大值到最小值之间不超过5;
其中:
return *s.rbegin()-*s.begin() < 5;
set访问首位用指针,s.end() != s的最后一个!!是s的最后一个的下一个,所以这里用到的是s.rbegin(),反向第一个,也就是最大值。
二刷: 看了记录也没搞出来啧啧啧,这里的方法很巧妙,就是关于重复数据和 0 数据的处理。如何处理重复数据?使用set 的 find 函数,查到s.end()就说明不存在。而且是先判断在放入数据,放入数据是直接判断是否为 0 ,不为 0 则放入。
62. 圆圈中最后剩下的数字

从第二个人开始往回推
二刷: 还是不会。推算下标
63. 股票的最大利润
二刷: 不难啊没搞出来。dp[i] 表示 i 天为止包括之前的最大利润,这个利润最大值要么是昨天的最大,要么今天做交易prices[i] - cost 最大。至于cost也需要不断变化,要不断取最小值。
64. 求1+2+…+n
笔记:K神知识点,&&运算和|| 运算的短路性质。

另外,ans要定义全局变量,放在里面每次会清零的(感觉自己像个憨憨)
二刷: 递归求和,至于关键就是判断当前值是否小于 0 ,那就用上面的方法,设置一个bool值,不需要对结果做什么只要能短路就行。
65. 不用加减乘除做加法
同371,这算是三刷了。我不知道除了背下来还有什么方法,道理我都懂,但是不会写啊哭
66. 构建乘积数组
笔记:看K神,写一下为什么不能双层循环判断i!=j的时候就把A[j]乘进B[i]
会超时
二刷: 相当于前缀积?前一遍前缀积,求除了自身所有前面的成绩,再一遍后缀积,求除了自己所有后面的数据成积。两者相乘
67. 把字符串转换成整数
一步步从左往右考虑。先考虑空格,为空i++。在判断是否是符号符,为 - 则sign 为true.循环开始,只要不为数字则跳出。反之不断加入ans,如果大于INT_MAX根据符号决定是取最大还是最小。
68 - I. 二叉搜索树的最近公共祖先
笔记:公共祖先意味着,两个孩子刚好一个大于他一个小于他。
二刷: 看了上面那句话写出来了。
68 - II. 二叉树的最近公共祖先
笔记:这题与I的区别在于,不是搜索树,没有排好序,不能用比大小的方式判断了。
所以根据K神的答案,至少,公共祖先不变的是,俩孩子一定在异侧。

Q:这里说明一下第三种情况,为啥一个空一个不空直接可以得到结果?
A:理解错误。这里的return right不是指结果就是right,这里是递归啊,这里是把right这个结果往上返回了。
二刷: 就是上面的内容。