clickhouse常规的优化方法

一、建表优化
1.1日期字段避免使用String存储
建表时能用数值型或日期时间型表示的字段就不要用字符串,全String 类型在以Hive
为中心的数仓建设中常见,但ClickHouse 环境不应受此影响。
虽然ClickHouse 底层将DateTime 存储为时间戳Long 类型,但不建议存储Long 类型,因为DateTime 不需要经过函数转换处理,执行效率高、可读性好。
1.2 空值存储类型
在ClickHouse表中数据存储时,对于一些列尽量不使用Nullable类型存储,因为此类型需要单独创建额外的文件来存储NULL的标记并且Nullable类型列无法被索引,会拖累性能,在数据存储时如果有空值时,我们可以选择在业务中没有意义的值来替代NULL值。
比如:用户ID或商品ID,用-1表示没有ID
1.3 分区和索引
ClickHouse中一般选择按天分区,可以指定tuple()指定多个列为组合分区。如果不按天分区,每个分区数据量控制在800~1000万为宜。
建表时通过order by 指定索引列,可以指定tuple(),指定多个列为索引列,指定索引列时最好满足高基列在前、查询频率大的列在前的原则。基数过大的列不适合作为索引列,因为如果某列基数特别大,这种情况有索引和没索引效果一样。如用户表的userid 字段;通常筛选后的数据满足在百万以内为最佳。
在这些分区索引的作用下,进行数据查询时能够快速跳过不必要的数据分区目录,从而减少最终需要扫描的数据范围。
比如官方案例的hits_v1 表:
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
visits_v1 表:
PARTITION BY toYYYYMM(StartDate)
ORDER BY (CounterID, StartDate, intHash32(UserID), VisitID)
现场查询按月查询的情况比较多,可以按月进行分区
1.4 表参数
l Index_granularity 是用来控制索引粒度的,默认是8192,如非必须不建议调整。
l 如果表中不是必须保留全量历史数据,建议指定TTL(生存时间值),可以免去手动过期历史数据的麻烦,TTL 也可以通过alter table 语句随时修改。
二、写入查询优化
(1)尽量不要执行单条或小批量删除和插入操作,这样会产生小分区文件,给后台Merge 任务带来巨大压力
(2)不要一次写入太多分区,或数据写入太快,数据写入太快会导致Merge 速度跟不上而报错,一般建议每秒钟发起2-3 次写入操作,每次操作写入2w~5w 条数据(依服务器性能而定)
配置项主要在config.xml 或users.xml 中,基本上都在users.xml 里
➢ config.xml 的配置项
https://clickhouse.tech/docs/en/operations/server-configuration-parameters/settings/
➢ users.xml 的配置项
https://clickhouse.tech/docs/en/operations/settings/settings/
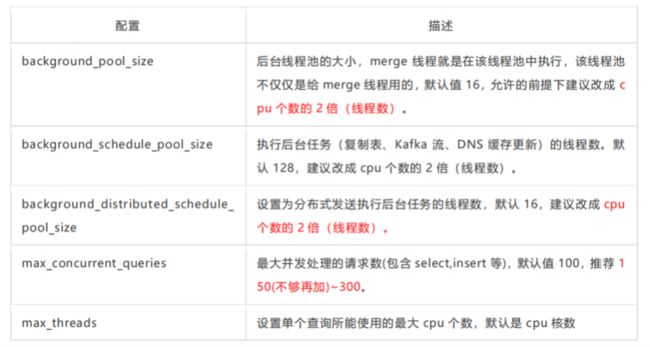
CPU 资源
内存资源

三、查询优化
3.1 单表查询
3.1.1 Prewhere 替代 where
Prewhere 和where 语句的作用相同,用来过滤数据。不同之处在于prewhere 只支持MergeTree 族系列引擎的表,首先会读取指定的列数据,来判断数据过滤,等待数据过滤之后再读取select 声明的列字段来补全其余属性。
当查询列明显多于筛选列时使用Prewhere 可十倍提升查询性能,Prewhere 会自动优化执行过滤阶段的数据读取方式,降低io 操作。
在某些场合下,prewhere 语句比where 语句处理的数据量更少性能更高。
默认情况,我们肯定不会关闭where 自动优化成prewhere,但是某些场景即使开启优化,也不会自动转换prewhere,需要手动指定prewhere:
⚫ 使用常量表达式
⚫ 使用默认值为alias 类型的字段
⚫ 包含了arrayJOIN,globalIn,globalNotIn 或者indexHint 的查询
⚫ select 查询的列字段和where 的谓词相同
⚫ 使用了主键字段
3.1.2 列裁剪与分区裁剪
数据量太大时应避免使用select * 操作,查询的性能会与查询的字段大小和数量成线性表换,字段越少,消耗的io 资源越少,性能就会越高。分区裁剪就是只读取需要的分区,在过滤条件中指定。
3.1.3 orderby 结合 where、limit
千万以上数据集进行order by 查询时需要搭配where 条件和limit 语句一起使用。
3.1.4 避免构建虚拟列
如非必须,不要在结果集上构建虚拟列,虚拟列非常消耗资源浪费性能,可以考虑在前端进行处理,或者在表中构造实际字段进行额外存储。
3.1.5 uniqCombined 替代 distinct
性能可提升10 倍以上,uniqCombined 底层采用类似HyperLogLog 算法实现,能接收2% 左右的数据误差,可直接使用这种去重方式提升查询性能。Count(distinct )会使用uniqExact 精确去重。
不建议在千万级不同数据上执行distinct 去重查询,改为近似去重uniqCombined。
3.2 多表关联
3.2.1 用 IN 代替JOIN
当多表联查时,查询的数据仅从其中一张表出时,可考虑用IN 操作而不是JOIN
3.2.2 大小表 JOIN
多表join 时要满足小表在右的原则。
右表关联时被加载到内存中与左表进行比较,ClickHouse 中无论是 Left join 、Right join 还是 Inner join 永远都是拿着右表中的每一条记录到左表中查找该记录是否存在,所以右表必须是小表。
3.2.3 谓词下推(版本差异)
ClickHouse 在join 查询时不会主动发起谓词下推的操作,需要每个子查询提前完成过滤操作,需要注意的是,是否执行谓词下推,对性能影响差别很大(新版本中已经不存在此问题,但是需要注意谓词的位置的不同依然有性能的差异)
3.2.4 分布式表使用 GLOBAL
两张分布式表上的IN 和JOIN 之前必须加上GLOBAL 关键字,右表只会在接收查询请求
的那个节点查询一次,并将其分发到其他节点上。
如果不加GLOBAL 关键字的话,每个节点都会单独发起一次对右表的查询,而右表又是分布式表,就导致右表一共会被查询N²次(N 是该分布式表的分片数量),这就是查询放大,会带来很大开销。
示例:
对分布式表使用join 或者 in时,ClickHouse会将当前SQL分发到各个ClickHouse节点上执行,例如有如下SQL:
select a.id,a.name,b.score from a join b on a.id = b.id
如果以上a表和b表都是分布式表,ClickHouse集群有3个节点,那么上面SQL会分发到ClickHouse所有节点执行,b表会在每个节点上收集其他节点对应b表数据并放在内存,这样的话,每个ClickHouse节点都会从对应的3台节点上将b表数据进行汇集。
如果使用global关键字,执行如下SQL:
select a.id,a.name,b.score from a global join b on a.id = b.id
这样执行SQL的话,相当于在当前写SQL节点会将查询得到b表所有数据,然后统一分发到其他ClickHouse各个节点上,然后每个节点在执行与a表关联。这样使用global就减少了集群之间查询次数。假设b表有N个分片分布在N个ClickHouse节点上,不使用global时,每个节点获取b表全量数据需要执行N的平方次查询,使用global时只需要执行N次查询即可。
所以在使用分布式表进行join或者in时,可以优先考虑使用global,使用用法如下:
select a.id,a.name,b.score from a global join b on a.id = b.id
select a.id,a.name from a global where a.id global in (select id from b)
3.2.5 提前过滤
通过增加逻辑过滤可以减少数据扫描,达到提高执行速度及降低内存消耗的目的
3.2.6 使用with子句代替重复查询
https://blog.csdn.net/weixin_39025362/article/details/122559488
3.3 Explain 查看执行计划
3.3.1 基本语法
EXPLAIN [AST | SYNTAX | PLAN | PIPELINE] [setting = value, …]
SELECT … [FORMAT …]
PLAN:用于查看执行计划,默认值。
◼ header 打印计划中各个步骤的 head 说明,默认关闭,默认值 0;
◼ description 打印计划中各个步骤的描述,默认开启,默认值 1;
◼ actions 打印计划中各个步骤的详细信息,默认关闭,默认值 0。
AST :用于查看语法树;
SYNTAX:用于优化语法;
PIPELINE:用于查看 PIPELINE 计划。
◼ header 打印计划中各个步骤的 head 说明,默认关闭;
◼ graph 用 DOT 图形语言描述管道图,默认关闭,需要查看相关的图形需要配合graphviz 查看;
◼ actions 如果开启了 graph,紧凑打印打,默认开启。
3.3.2日志中的SQL查询计划查看
clickhouse-client -h --port --password --send_logs_level=trace <<< "
// SQL statement here
" > /dev/null
4. 其他
(1)查询熔断
为了避免因个别慢查询引起的服务雪崩的问题,除了可以为单个查询设置超时以外,还可以配置周期熔断,在一个查询周期内,如果用户频繁进行慢查询操作超出规定阈值后将无法继续进行查询操作。
(2)关闭虚拟内存
物理内存和虚拟内存的数据交换,会导致查询变慢,资源允许的情况下关闭虚拟内存。
(3)配置 join_use_nulls
为每一个账户添加 join_use_nulls 配置,左表中的一条记录在右表中不存在,右表的相应字段会返回该字段相应数据类型的默认值,而不是标准 SQL 中的 Null 值。
(4)批量写入时先排序
批量写入数据时,必须控制每个批次的数据中涉及到的分区的数量,在写入之前最好对需要导入的数据进行排序。无序的数据或者涉及的分区太多,会导致 ClickHouse 无法及时对新导入的数据进行合并,从而影响查询性能。
(5)关注 CPU
cpu 一般在 50%左右会出现查询波动,达到 70%会出现大范围的查询超时,cpu 是最关键的指标,要非常关注。