万字长文搞懂c++STL模板
stl概述
1.STL的诞生
长久以来,软件界一直希望建立一种可重复利用的东西。C++的面向对象和泛型编程思想的目的就是提升复用性。然而,大多数情况下,数据结构和算法并没有一套标准,这迫使开发人员不得不进行大量重复的工作。为了建立一套数据结构和算法的标准,STL(标准模板库)应运而生。
2.STL的概念
STL(Standard Template Library,标准模板库):
STL从广义上分为容器(container)、算法(algorithm)和迭代器(iterator)。
容器和算法之间通过迭代器进行无缝连接。
STL几乎所有的代码都采用了模板类或者模板函数。
3.STL六大组件
STL大体分为六大组件,分别是:容器、算法、迭代器、仿函数、适配器和空间配置器。
容器(Containers):包括各种数据结构,如vector、list、deque、set、map等,用于存储和组织数据。
算法(Algorithms):提供各种常用的算法,如sort、find、copy、for_each等,用于对容器中的数据进行处理和操作。
迭代器(Iterators):扮演了容器和算法之间的胶合剂,提供一种统一的访问元素的方式,使得算法可以独立于容器而工作。
仿函数(Functors):行为类似函数的对象,可作为算法的某种策略,用于自定义操作或比较。
适配器(Adapters):一种用来修饰容器、仿函数或迭代器接口的组件,提供了不同接口之间的转换或功能增强。
空间配置器(Allocator):负责空间的配置和管理,用于动态分配和释放内存,提供了灵活的内存管理机制。
4.详解容器算法,迭代器
4.1 容器
置物之所在
容器是STL中的核心概念,它用来存储和组织数据。STL提供了各种常用的数据结构作为容器的实现。
序列式容器(Sequential Containers)强调元素的排序,其中每个元素都有一个固定的位置。常见的序列式容器包括vector(动态数组)、list(双向链表)、deque(双端队列)等。
关联式容器(Associative Containers)基于二叉树结构实现,其中元素之间没有严格的物理上的顺序关系。常见的关联式容器包括set(集合)、map(映射表)等。
通过使用这些容器,STL提供了一种通用的数据存储和操作机制,使得开发人员可以更加方便地处理和管理数据。
4.2算法
问题之解法
算法是解决问题的有限步骤或方法,通常应用于逻辑或数学上的问题。在计算机科学中,算法是一门重要的学科。
算法可以分为质变算法(Mutating Algorithms)和非质变算法(Non-mutating Algorithms)。
质变算法是指在运算过程中会改变区间内元素的内容。例如,拷贝(copy)、替换(replace)、删除(erase)等操作都属于质变算法。
非质变算法是指在运算过程中不会改变区间内元素的内容。例如,查找(find)、计数(count)、遍历(foreach)、寻找极值(min/max)等操作属于非质变算法。
通过使用这些算法,STL提供了一系列高效和通用的操作,使得开发人员可以快速处理和操作容器中的数据。
4.3迭代器
迭代器在STL中充当了容器和算法之间的粘合剂。它提供了一种统一的方式,使得算法可以按顺序访问容器中的元素,同时无需暴露容器的内部表示方式。每个容器都有自己独特的迭代器类型。
迭代器的使用方式非常类似于指针。初学阶段,我们可以将迭代器理解为指针。通过使用迭代器,算法可以在不关心容器内部结构的情况下,遍历和操作容器中的元素。
迭代器提供了一系列操作,如访问当前元素、移动到下一个元素、比较迭代器等。这些操作使得开发人员可以方便地在容器中进行遍历和操作,而无需了解容器内部的具体实现细节。
总而言之,迭代器在STL中扮演着重要的角色,它使得容器和算法能够无缝地协同工作,提供了一种通用的遍历和访问容器元素的接口。
4.3迭代器的种类

初识STL
三种遍历方式
string容器
1.构造函数,使用构造器
代码如下,可以使用下述构造函数的方式对string类型的容器赋值
#include
using namespace std;
int main(){
char *str="helloworld";
string s1(str);
cout< 2.赋值操作,使用的方法
使用assign函数也可以对容器赋值
#include
using namespace std;
int main(){
string s="nihaoa1";
cout< 上述代码最后的输出为
![]()
3.字符串的拼接
string& operator+=(const char* str);
// 重载 += 操作符,将 C 风格字符串 str 连接到当前字符串结尾
string& operator+=(const char c);
// 重载 += 操作符,将字符 c 连接到当前字符串结尾
string& operator+=(const string& str);
// 重载 += 操作符,将字符串 str 连接到当前字符串结尾
string& append(const char* s);
// 将 C 风格字符串 s 连接到当前字符串结尾
string& append(const char* s, int n);
// 将字符串 s 的前 n 个字符连接到当前字符串结尾
string& append(const string& s);
// 将字符串 s 连接到当前字符串结尾,等同于 operator+=(const string& str)
string& append(const string& s, int pos, int n);
// 将字符串 s 中从位置 pos 开始的 n 个字符连接到当前字符串结尾
关于字符串类 string 的成员函数重载和附加操作的定义。它们提供了多种方式来将字符或字符串连接到当前字符串的末尾。重载了 += 操作符的函数和 append 函数都用于实现字符串的连接操作,只是参数形式略有不同。
operator+= 函数重载了 += 操作符,可以用于连接 C 风格字符串、字符和另一个字符串。
append 函数提供了更具体的连接操作,可以连接 C 风格字符串、指定长度的 C 风格字符串、字符串对象以及指定位置和长度的字符串对象的子串。
#include
using namespace std;
#include
void test01() {
string str1 = "I ";
str1 += "Love you";
cout << "str1 = " << str1 << endl;
str1 += 'c';
cout << "str1 = " << str1 << endl;
string str2 = "LOL";
str1 += str2;
cout << "str1 = " << str1 << endl;
string str3 = "I";
str3.append(" love");
cout << "str3 = " << str3 << endl;
str3.append("abcde", 4);
cout << "str3 = " << str3 << endl;
string str4 = "I like";
string str5 = str4;
str4.append(str3);
cout << "str4 = " << str4 << endl;
str5.append(str3, 0, 3);
cout << "str5 = " << str5 << endl;
}
int main() {
test01();
system("pause");
return 0;
}
4.字符串的查找和替换
查找
int find(const string& str, int pos = 0) const;
// 从位置 pos 开始查找字符串 str 第一次出现的位置
int find(const char* s, int pos = 0) const;
// 从位置 pos 开始查找 C 风格字符串 s 第一次出现的位置
int find(const char* s, int pos, int n) const;
// 从位置 pos 开始查找字符串 s 的前 n 个字符第一次出现的位置
int find(const char c, int pos = 0) const;
// 从位置 pos 开始查找字符 c 第一次出现的位置
int rfind(const string& str, int pos = npos) const;
// 从位置 pos 开始逆向查找字符串 str 最后一次出现的位置
int rfind(const char* s, int pos = npos) const;
// 从位置 pos 开始逆向查找 C 风格字符串 s 最后一次出现的位置
int rfind(const char* s, int pos, int n) const;
// 从位置 pos 开始逆向查找字符串 s 的前 n 个字符最后一次出现的位置
int rfind(const char c, int pos = 0) const;
// 从位置 pos 开始逆向查找字符 c 最后一次出现的位置
string& replace(int pos, int n, const string& str);
替换
// 替换从位置 pos 开始的 n 个字符为字符串 str
string& replace(int pos, int n, const char* s);
// 替换从位置 pos 开始的 n 个字符为 C 风格字符串 s
在查找和替换的过程中主要分为查找字符/字符串 ,替换字符/字符串,在形参中,查找的时候查找的元素先出现,之后才是从哪个位置上查找的问题,但是在替换的时候,得先指出需要替换的位置在哪里。
5.字符串的比较
字符串的比较是通过ASCII码来比较的
#include
using namespace std;
#include
void test01() {
int i;
string str1 = "abcdefde";
cout << "str1 " << str1 << endl;
string str2 = "abcedasd";
if (str1.compare(str2)) {
cout << "==" << endl;
}
else {
cout << "!==" << endl;
}
str1[1] = '1';
cout << "str1 " << str1 << endl;
cout << "str[2] " << str1[2] << endl;
cout << "str[2] " << str1.at(2) << endl;
}
int main() {
test01();
system("pause");
return 0;
}
6.单个字符串的存取
char& operator[](int n);
// 通过 [] 方式获取索引为 n 的字符
char& at(int n);
// 通过 at 方法获取索引为 n 的字符
字符串类 string 中用于单个字符存取的两种方式。通过重载的 operator[] 和 at 方法可以访问字符串中特定位置的字符。这两种方式都接受一个整数参数 n 表示索引位置,返回一个 char& 引用,允许对该字符进行读取或修改操作。
需要注意的是,operator[] 不会进行范围检查,当访问超出字符串长度的位置时,行为未定义。而 at 方法会进行范围检查,如果索引超出字符串长度,则会引发 std::out_of_range 异常。因此,在需要保证安全性的情况下,推荐使用 at 方法来访问字符串的单个字符。
7.字符串的插入和删除
函数原型
string& insert(int pos, const char* s);
// 在指定位置 pos 插入 C 风格字符串 s
string& insert(int pos, const string& str);
// 在指定位置 pos 插入字符串 str
string& insert(int pos, int n, char c);
// 在指定位置 pos 插入 n 个字符 c
string& erase(int pos, int n = npos);
// 从位置 pos 开始删除 n 个字符,默认删除到末尾
对于插入函数中形参,也要先说插入的位置之后再提插入的内容

8.子串获取
string substr(int pos = 0, int n = npos) const;/I返回由pos开始的n个字符组成的字符串

vector容器
1.构造函数
以下是对上述文本进行格式化的结果:
I/ 采用模板实现类实现,默认构造函数
vector v;
vector(v.begin(), v.end());
// 将 v[begin(), end()) 区间中的元素拷贝给本身。
vector(n, elem);
// 构造函数将 n 个 elem 拷贝给本身。
vector(const vector &vec);
// 拷贝构造函数。
J/ 构造函数将 n 个 elem 拷贝给本身。
2.函数赋值
vector& operator=(const vector &vec);
// 重载等号操作符
assign(beg, end);
// 将 [beg, end) 区间中的数据拷贝赋值给本身。
assign(n, elem);
// 将 n 个 elem 拷贝赋值给本身。
l/ 将 n 个 elem 拷贝赋值给本身。
#include
using namespace std;
void PrintVector(vector v){
for(vector::iterator it=v.begin();it!=v.end();it++){
cout<<*it<<" ";
}
cout< v;
v.push_back(12);
v.push_back(34);
v.push_back(56);
PrintVector(v);
}
void test2(){
vector v;
for(int i=0;i<10;i++){
v.push_back(i+12);
}
PrintVector(v);
vector v2;
v2.assign(v.begin(),v.end());
PrintVector(v2);
vector v3;
// 给容器v3赋值10个100
v3.assign(10,100);
PrintVector(v3);
}
int main(){
test2();
}
3.容器中元素的插入和删除
push_back(ele);
// 尾部插入元素 ele
pop_back();
// 删除最后一个元素
insert(const_iterator pos, ele);
// 迭代器指向位置 pos 插入元素 ele
insert(const_iterator pos, int count, ele);
// 迭代器指向位置 pos 插入 count 个元素 ele
erase(const_iterator pos);
// 删除迭代器指向的元素
erase(const_iterator start, const_iterator end);
// 删除迭代器从 start 到 end 之间的元素
clear();
// 删除容器中所有元素
4.数据存储
at(int idx);
// 返回索引 idx 所指的数据
operator[];
// 1 返回索引 idx 所指的数据
front();
// 返回容器中第一个数据元素
back();
// 返回容器中最后一个数据元素
#include
using namespace std;
void PrintVector(vector v){
for(vector::iterator it=v.begin();it!=v.end();it++){
cout<<*it;
}
cout< v;
for(int i=0;i<10;i++){
v.push_back(i);
}
PrintVector(v);
cout<<"the begin of vector:"<<*v.begin();
v.clear();
PrintVector(v);
}
int main(){
test1();
}
5.容器交换
#include
using namespace std;
void PrintVector(vector v){
for(vector::iterator it=v.begin();it!=v.end();it++){
cout<<*it;
}
cout< v;
for(int i=0;i<10;i++){
v.push_back(i);
}
PrintVector(v);
cout<<"the begin of vector:"<<*v.begin();
v.clear();
cout<<"the content of v1:";
PrintVector(v);
vector v2;
for(int i=12;i<22;i++){
v2.push_back(i);
}
cout<<"the content of v2:";
PrintVector(v2);
// SWAP函数的作用就是直接交换两个函数的值
cout<<"using swap after the content of v1:";
v.swap(v2);
PrintVector(v);
}
void text2(){
vector v;
for(int i=0;i<10;i++){
v.push_back(i);
}
cout<<"the size of vector:"< 6.预先设置容量
使用reserve函数设置容器的预设值
#include
using namespace std;
void PrintVector(vector v){
for(vector::iterator it=v.begin();it!=v.end();it++){
cout<<*it;
}
cout< v;
v.reserve(14);
for(int i=0;i<11;i++){
v.push_back(i);
}
cout<<"the size of vector:"< 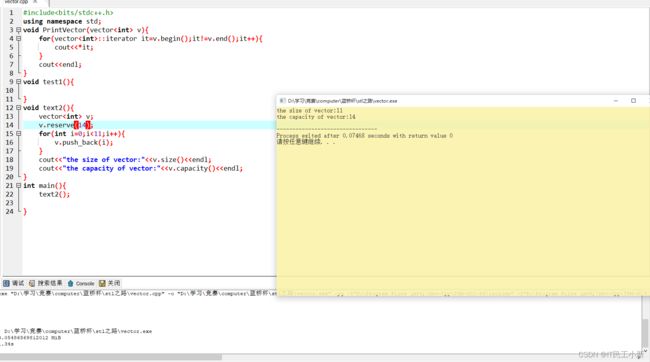
deque容器
在C++中,deque(双端队列)是一种容器,它提供了动态大小的序列,支持在两端高效地进行元素的插入和删除操作。deque 的名称是 “double-ended queue” 的缩写。
功能:
动态大小: deque 允许在运行时动态调整其大小,可以根据需要随时添加或删除元素。
随机访问: deque 支持通过索引进行快速的随机访问,可以像数组一样使用下标操作符 [] 来访问元素。
双端操作: deque 支持在两端进行高效的元素插入和删除操作。可以使用 push_front() 在队列的前端插入元素,使用 push_back() 在队列的后端插入元素。同样,可以使用 pop_front() 和 pop_back() 分别从前端和后端删除元素。
迭代器支持: deque 提供了迭代器(iterator)来遍历容器中的元素。迭代器可以用于访问、修改和删除元素。
动态内存分配: deque 使用动态内存分配来管理其内部存储,可以根据需要动态地增加或减少内存空间。
高效的插入和删除: 与 vector 相比,deque 在两端进行插入和删除操作时更加高效。但是,在中间位置进行插入和删除操作的效率相对较低。
deque 提供了一个灵活的双端队列容器,适用于需要频繁在两端进行元素插入和删除的场景。它具有随机访问、动态大小调整和高效的双端操作等特点,为开发者提供了更多的选择和灵活性。
1.构造函数
deque deqT;
// 默认构造形式
deque(beg, end);
// 构造函数将 [beg, end) 区间中的元素拷贝给本身
deque(n, elem);
// 构造函数将 n 个 elem 拷贝给本身
deque(const deque &deq);
// 拷贝构造函数
同时支持构造函数和拷贝构造
#include
using namespace std;
void PrintDeque(deque d){
for(deque::const_iterator it=d.begin();it!=d.end();it++){
cout<<*it<<" ";
}
cout< d;
for(int i=0;i<10;i++){
d.push_back(i+12);
}
PrintDeque(d);
// 通过构造函数来构造
deque d2(10,100);
PrintDeque(d2);
// 通过拷贝构造的方式来构造
deque d3(d2.begin(),d2.end());
PrintDeque(d3);
}
int main(){
test2();
}
2.赋值操作
依旧是三种·赋值操作,默认构造形式,齐次就是使用拷贝构造,以及使用n个元素的赋值
deque deqT;
// 默认构造形式
deque(beg, end);
// 构造函数将 [beg, end) 区间中的元素拷贝给本身
deque(n, elem);
// 构造函数将 n 个 elem 拷贝给本身
deque(const deque &deq);
// 拷贝构造函数
3.大小操作
deque.empty();
// 判断容器是否为空
deque.size();
// 返回容器中元素的个数
deque.rdsize(num);
// 重新指定容器的长度为 num,若容器变长,则以默认值填充新位置
// 如果容器变短,则末尾超出容器长度的元素被删除。
deque.resize(num, elem);
// 重新指定容器的长度为 num,若容器变长,则以 elem 值填充新位置。
// 如果容器变短,则末尾超出容器长度的元素被删除。
4.插入和删除
deque就是双端队列,就可以执行头插尾插
两端插入操作:
push_back(elem);
// 在容器尾部添加一个数据
push_front(elem);
// 在容器头部插入一个数据
pop_back();
// 删除容器最后一个数据
pop_front();
// 删除容器第一个数据
指定位置操作:
insert(pos, elem);
// 在 pos 位置插入一个 elem 元素的拷贝,返回新数据的位置
insert(pos, n, elem);
// 在 pos 位置插入 n 个 elem 数据,无返回值
insert(pos, beg, end);
// 在 pos 位置插入 [beg, end) 区间的数据,无返回值
clear();
// 清空容器的所有数据
erase(beg, end);
// 删除 [beg, end) 区间的数据,返回下一个数据的位置
erase(pos);
// 删除 pos 位置的数据,返回下一个数据的位置
5.数据存储
不同之处就在front和back这两个函数,放回了容器中第一个元素和最后元素
at(int idx);
// 返回索引 idx 所指的数据
operator[];
// 返回索引 idx 所指的数据
front();
// 返回容器中第一个数据元素
back();
// 返回容器中最后一个数据元素
#include
using namespace std;
void PrintDeque(deque d){
for(deque::iterator it=d.begin();it!=d.end();it++){
cout<<*it<<" ";
}
cout< deq;
while(i>0){
deq.push_front(i--);
}
PrintDeque(deq);
}
int main(){
test1();
return 0;
}
6.排序
sort(iterator beg, iterator end);
// 对 beg 和 end 区间内元素进行排序
#include
using namespace std;
//对基础数组的排序
void sort_arrays(){
int arr[10]={4,3,2,6,7,8,9,90,12,34};
sort(arr,arr+10);
for(int i:arr){
cout< v(2,43,1,67,89,23,333);
//正确的构造函数
vector v;
int arr[]={1,4,6,78,2,5,78,9,05,5,5};
for(int i=0;i<11;i++) v.push_back(arr[i]);
sort(v.begin(),v.end());
for(vector::iterator it=v.begin();it!=v.end();it++){
cout<<*it<<" ";
}
cout< deq;
for(int i=0;i<7;i++){
deq.push_back(arr[i]);
}
for(deque::iterator it=deq.begin();it!=deq.end();it++){
cout<<*it<<" ";
}
cout< 使用sort函数对元素排序
案例
#include
using namespace std;
struct Student{
string name;
double score;
};
void setStudent(Student &student){
cin>>student.name;
cin>>student.score;
}
void PrintStudent(vector stu){
for(vector::iterator it=stu.begin();it!=stu.end();it++){
Student s=*it;
cout<<"the name of the student:"< deq){
for(deque::iterator it=deq.begin();it!=deq.end();it++){
cout<<*it<<" ";
}
cout< s;
s.push_back(s1);
s.push_back(s2);
s.push_back(s3);
s.push_back(s4);
PrintStudent(s);
}
stack容器
stack容器就是栈
在C++中,std::stack 是一个容器适配器,它提供了一种后进先出(Last-In-First-Out,LIFO)的数据结构。std::stack 基于其他容器实现,例如 std::deque 或 std::list,并提供了一组特定的操作函数,使得栈的操作更加方便和高效。
构造函数:
stack stk;
// stack 采用模板类实现,stack 对象的默认构造形式
stack(const stack &stk);
// 拷贝构造函数
赋值操作:
stack& operator=(const stack &stk);
// 重载等号操作符
数据存取:
push(elem);
// 向栈顶添加元素
pop();
// 从栈顶移除第一个元素
top();
// 返回栈顶元素
大小操作:
empty();
// 判断堆栈是否为空
size();
// 返回栈的大小
和之前有所不同的地方在于,因为是栈的一种实现方式,所以在元素入栈的时候不需要使用push_back来操作
#include
#include
int main() {
std::stack myStack;
myStack.push(10);
myStack.push(20);
myStack.push(30);
while (!myStack.empty()) {
std::cout << myStack.top() << " ";
myStack.pop();
}
// 输出: 30 20 10
return 0;
}
对于栈的遍历,不同于vector,deque,string,都是都通过元素的出栈才可以实现栈的遍历
queue容器
就是我们最熟悉的队列,先进先出
C++中的 std::queue 是一个容器适配器,它实现了先进先出(First-In-First-Out,FIFO)的数据结构。std::queue 基于其他容器实现,例如 std::deque 或 std::list,并提供了一组特定的操作函数,使得队列的操作更加方便和高效。
构造函数:
queue que;
// llqueue 采用模板类实现,queue 对象的默认构造形式
queue(const queue &que);
// 拷贝构造函数
赋值操作:
queue& operator=(const queue &que);
// 重载等号操作符
数据存取:
push(elem);
// 往队尾添加元素
pop();
// 从队头移除第一个元素
back();
// 返回最后一个元素
front();
// 返回第一个元素
大小操作
empty();
// 判断队列是否为空
size();
// 返回队列的大小
#include
using namespace std;
struct Node{
int score;
string name;
};
void PrintQueue(queue quq){
while(!quq.empty()){
Node temp=quq.front();
cout<<"the name of Node:"<* student,int num){
Node temp;
for(int i=0;i的时候,是访问的指针所指向的对象
cin>>temp.score>>temp.name;
student->push(temp);
}
}
int main(){
queue qu;
// 形参中为指针,在实参中为引用
SetNode(&qu,2);
PrintQueue(qu);
return 0;
}
list容器
就是数据结构中的链表
C++中,std::list 是标准库提供的一种双向链表容器(Doubly Linked List)。它提供了一系列操作和功能,用于存储和操作一组有序的元素。以下是关于C++中 std::list 集合的简要概述:
双向链表:std::list 使用双向链表来存储元素。每个节点都包含一个值以及指向前一个节点和后一个节点的指针。这种数据结构允许高效地插入、删除和移动元素,不需要移动其他元素。
有序容器:std::list 中的元素按照它们被插入的顺序进行存储,保持了元素的插入顺序。这使得 std::list 适用于需要保持元素顺序的场景。
动态大小:std::list 具有动态调整大小的能力,可以根据需要自动分配和释放内存。这意味着可以在运行时添加或删除元素,而不需要提前指定容器的固定大小。
插入和删除操作:std::list 提供了在任意位置插入和删除元素的操作。相比于其他序列容器(如 std::vector),std::list 在插入和删除元素时的效率更高,因为它不需要移动其他元素。
不支持随机访问:由于 std::list 是以链表形式存储元素,它不支持通过下标进行随机访问。要访问特定位置的元素,需要使用迭代器进行遍历。
迭代器支持:std::list 提供了迭代器来遍历容器中的元素。迭代器可以用于访问和修改元素,以及在容器中插入和删除元素。
总之,std::list 是C++中提供的一种双向链表容器,适用于需要保持元素顺序、频繁插入和删除元素的场景。
1.构造容器
list lst;
// list 采用模板类实现,对象的默认构造形式
list(beg, end);
// 构造函数将 [beg, end) 区间中的元素拷贝给本身
list(n, elem);
// 构造函数将 n 个 elem 拷贝给本身
list(const list &lst);
// 拷贝构造函数
#include
using namespace std;
void PrintList(list li){
for(list::iterator it=li.begin();it!=li.end();it++){
cout<<*it<<" ";
}
cout< &li){
int temp;
for(int i=0;i<4;i++){
cin>>temp;
li.push_back(temp);
}
}
int main(){
list li;
setLIst(li);
cout<<"the size of list is :"< 2.赋值和交换
赋值:
assign(beg, end);
// 将 [beg, end) 区间中的数据拷贝赋值给本身
assign(n, elem);
// 将 n 个 elem 拷贝赋值给本身
交换:
list& operator=(const list &lst);
// 重载等号操作符
swap(lst);
// 将 lst 与本身的元素互换
3.大小操作
size();
// 返回容器中元素的个数
empty();
// 判断容器是否为空
resize(num);
// 重新指定容器的长度为 num,若容器变长,则以默认值填充新位置。
// 如果容器变短,则末尾超出容器长度的元素被删除。
resize(num, elem);
// 重新指定容器的长度为 num,若容器变长,则以 elem 值填充新位置。
// 如果容器变短,则末尾超出容器长度的元素被删除。
4.插入和删除
因为list为双向链表,所以对于list来说,移除元素的时候可以从头部移除也可以从尾部移除
push_back(elem);
// 在容器尾部加入一个元素
pop_back();
// 删除容器中最后一个元素
push_front(elem);
// 在容器开头插入一个元素
pop_front();
// 从容器开头移除第一个元素
insert(pos, elem);
// 在 pos 位置插入 elem 元素的拷贝,返回新数据的位置
insert(pos, n, elem);
// 在 pos 位置插入 n 个 elem 数据,无返回值
insert(pos, beg, end);
// 在 pos 位置插入 [beg, end) 区间的数据,无返回值
clear();
// 移除容器的所有数据
erase(beg, end);
// 删除 [beg, end) 区间的数据,返回下一个数据的位置
erase(pos);
// 删除 pos 位置的数据,返回下一个数据的位置
remove(elem);
// 删除容器中所有与 elem 值匹配的元素
5.数据存储
双向链表返回第一个元素和最后一个元素
front();
// 返回第一个元素
back();
// 返回最后一个元素
6.翻转和排序
reverse(); // 反转链表
sort(); // 链表排序
set容器
二叉树的实现
C++中的std::set是标准库提供的一种关联容器,它实现了一个有序的、不重复的元素集合。下面是对C++中std::set容器的总结:
有序集合:std::set中的元素按照一定的排序顺序进行存储。默认情况下,它以升序的方式对元素进行排序,但也可以通过提供自定义的比较函数来指定其他排序方式。
不重复元素:std::set中的元素是唯一的,不允许重复。当尝试插入重复元素时,插入操作将被忽略。
动态大小:std::set具有动态调整大小的能力,可以根据需要自动分配和释放内存。这意味着可以在运行时添加或删除元素,而不需要提前指定容器的固定大小。
插入和查找操作:std::set提供了高效的插入和查找操作。插入操作将元素按照排序顺序插入到适当的位置,而查找操作可以快速地确定元素是否在集合中。
迭代器支持:std::set提供了迭代器来遍历容器中的元素。可以使用迭代器进行顺序访问或反向访问,也可以使用迭代器进行元素的插入和删除操作。
底层实现为红黑树:std::set通常使用红黑树(Red-Black Tree)实现,这是一种自平衡的二叉搜索树。红黑树的特性使得插入、删除和查找操作的平均时间复杂度为O(logN)。
总之,std::set是C++中的一种关联容器,用于存储一组有序的、不重复的元素。它提供了高效的插入、查找和遍历操作,并以红黑树作为底层实现,保持元素的有序性。
set容器不允许有重复,但是在multiset可以允许重复
1.构造和赋值
#include
using namespace std;
void PrintSet(set s){
for(set::iterator it=s.begin();it!=s.end();it++){
cout<<*it<<" ";
}
cout< s;
s.insert(23);
s.insert(435);
s.insert(343);
PrintSet(s);
s.
return 0;
}
2.大小和交换
#include
#include
#include
#include
using namespace std;
void PrintSet(set s1,string name) {
cout << "打印" << name << ": " << endl;
for (set::iterator it = s1.begin(); it != s1.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
void test() {
set s1;
s1.insert(12);
s1.insert(52);
s1.insert(62);
s1.insert(17);
s1.insert(13);
PrintSet(s1,"s1");
sets2;
s2.insert(10);
s2.insert(50);
s2.insert(70);
s2.insert(40);
PrintSet(s2, "s2");
cout << "大小: " << s1.size() << endl;
cout << "交换操作: "< 3.插入与删除
insert(elem);
// 在容器中插入元素
clear();
// 清除所有元素
erase(pos);
// 删除 pos 迭代器所指的元素,返回下一个元素的迭代器
erase(beg, end);
// 删除区间 [beg, end) 的所有元素,返回下一个元素的迭代器
erase(elem);
// 删除容器中值为 elem 的元素
#include
using namespace std;
void PrintSet(set s){
for(set::iterator it=s.begin();it!=s.end();it++){
cout<<*it<<" ";
}
cout< se,int n){
set::iterator it=se.find(n);
return it!=se.end()?1:0;
}
int main(){
set s;
s.insert(23);
s.insert(435);
s.insert(343);
s.insert(5);
s.insert(78);
cout<<"the size of set:"< 4.查找和统计
find(key);
// 查找 key 是否存在,若存在,返回该键的元素的迭代器;若不存在,返回 set.end()
count(key);
// 统计 key 的元素个数
5.set和multiset之间区别
#include
#include
#include
#include
using namespace std;
void PrintSet(set s1, string name) {
cout << "PRINT" << name << ": " << endl;
for (set::iterator it = s1.begin(); it != s1.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
int Find(set s, int n) {
set::iterator it = s.find(n);
return it != s.end() ? 1 : 0;
}
void test() {
int s;
set s1;
s1.insert(12);
s1.insert(52);
s1.insert(62);
s1.insert(17);
s1.insert(13);
PrintSet(s1, "s1");
cout << "place input a numner which you want to search:" << endl;
cin >> s;
Find(s1, s) == 1 ? cout << "find it" << endl : cout << "not find" << endl;
cout << "the count of number: " << s1.count(12) << endl;
multiset s2;
s2.insert(10);
s2.insert(10);
s2.insert(10);
s2.insert(10);
s2.insert(10);
for (multiset::iterator it = s2.begin(); it != s2.end(); it++) {
cout << *it << " ";
}
cout << endl;
cout << "the 10 of number: " << s2.count(10) << endl;
cout<<"the size of set:"< 6.pair对组的创建
成对出现的数据,利用对组可以返回两个数据。
两种创建方式:
pair
pair
#include
using namespace std;
void setPair(vector> &students){
pair student;
string tempName;
double tempScore;
for(int i=0;i<2;i++){
cin>>tempName>>tempScore;
student=make_pair(tempName,tempScore);
students.push_back(student);
}
}
void PrintVector(vector> student){
int i=1;
for (vector>::iterator it = student.begin(); it != student.end(); it++) {
printf("the %d student's name is %s, and the score is %f\n", i, it->first.c_str(), it->second);
}
}
int main(){
vector> student;
setPair(student);
PrintVector(student);
cout<<"the size of student in main class:"< 7.unordered_set
set与unorder_set之间的区别
在C++中,set和unordered_set都是标准库提供的关联容器,用于存储唯一的元素。它们之间的主要区别如下:
底层实现方式:set使用红黑树(Red-Black Tree)实现,它是一种自平衡的二叉搜索树,确保了元素的有序存储。而unordered_set使用哈希表(Hash Table)实现,它通过哈希函数将元素映射到桶(Bucket),并提供了快速的插入、查找和删除操作,但元素的存储顺序是不确定的。
元素的顺序:set中的元素按照元素值的升序进行排序,并且保持有序状态。这使得set适用于需要有序集合的场景,可以高效地进行范围查找和有序遍历。而unordered_set中的元素没有特定的顺序,存储和遍历的顺序是不确定的。
插入和查找效率:set的插入、查找和删除操作的时间复杂度为O(log n),其中n是元素的数量。这是由于红黑树的平衡性质,保证了这些操作的对数时间复杂度。而unordered_set的插入、查找和删除操作的平均时间复杂度为O(1),具有常数时间复杂度。这是因为哈希表使用哈希函数进行元素查找,具有很高的查找效率。
内存占用:unordered_set通常比set占用更多的内存。这是因为unordered_set需要维护哈希表的结构,包括桶和哈希函数等。而set只需要维护红黑树的结构。
元素的唯一性:set和unordered_set都保证元素的唯一性,不允许重复元素的存在。在插入重复元素时,set会忽略重复元素的插入操作,而unordered_set会直接返回插入失败的结果。
综上所述,选择使用set还是unordered_set取决于具体的需求。如果需要有序的集合、范围查找和有序遍历,可以选择set。如果不需要有序性,并且对插入、查找和删除操作的性能有更高的要求,可以选择unordered_set。
map容器
简介:
map 中所有元素都是 pair。
pair 中第一个元素为 key (键值),起到索引作用,第二个元素为 value (实值)。
所有元素都会根据元素的键值自动排序。
本质:
map/multimap 属于关联式容器,底层结构是用二叉树实现。
优点:
可以根据 key 值快速找到 value 值。
map 和 multimap 区别:
map 不允许容器中有重复 key 值元素。
multimap 允许容器中有重复 key 值元素。
1.构造和赋值
#include
#include 2.大小和交换
获取大小:
size()函数:返回std::map中键值对的数量,即容器的大小。
empty()函数:检查std::map是否为空,如果为空则返回true,否则返回false。
交换容器内容:
swap()函数:用于交换两个std::map容器的内容。可以将一个std::map与另一个具有相同类型的std::map进行交换,以交换它们之间的元素。
#include
#include 3.插入与删除
#include
#include 4.查找于统计
查找元素的函数和操作:
find()函数:用于按键查找元素,返回指向该元素的迭代器,如果元素不存在,则返回end()迭代器。
count()函数:用于统计指定键的元素数量,返回0或1,因为std::map中每个键只能对应一个元素。
lower_bound()函数:用于返回一个迭代器,指向第一个大于或等于给定键的元素。
upper_bound()函数:用于返回一个迭代器,指向第一个大于给定键的元素。
equal_range()函数:用于返回一个std::pair,其中包含lower_bound()和upper_bound()的结果,表示给定键的范围。
员工分组(案例)
下述案例中为使用set容器和vector容器所写的案例。
#include
using namespace std;
class Worker{
public:
string name;
int money;
};
void createWorker(vector &workers){
string tempNumber="ABCDEFG";
Worker worker;
for(int i=0;i &workerMap,vector worker){
for(vector::iterator it=worker.begin();it!=worker.end();it++){
int department=rand()%3;
workerMap.insert(make_pair(department,*it));
}
}
void Find(multimap workers,int n){
//这个迭代器的赋值是查找出部门为n的所有位置
multimap::iterator it=workers.find(n);
if(it!=workers.end()){
int nums=workers.count(n);
for(int i=0;ifirst << " the money is: " << it->second << endl;
//在访问迭代器的元素的时候,因为迭代器迭代的是一个set,存储的形式为键值对,第二个的值为一个对象,我们只需要访问对象里面的东西
cout << "the department of staff: " << it->first << " the money is: " << it->second.money << endl;
it++;
}
}
}
int main(){
vector worker;
srand((unsigned int)time(NULL));
multimap workers;
createWorker(worker);
setMap(workers, worker);
Find(workers, 1);
return 0;
return 0;
}
函数对象
概念:
重载函数调用操作符的类,其对象常称为函数对象。
函数对象使用重载的 () 时,行为类似函数调用,也叫仿函数。
本质:
函数对象(仿函数)是一个类,不是一个函数。
函数对象使用的特点:
函数对象在使用时,可以像普通函数那样调用,可以有参数,可以有返回值。
函数对象超出普通函数的概念,函数对象可以有自己的状态。
函数对象可以作为参数传递。
#include
using namespace std;
class MyFunctor {
public:
int operator()(int x, int y) {
return x + y;
}
};
int main() {
MyFunctor functor;
int result = functor(3, 4); // 调用函数对象
cout< 内建函数对象
1.算数与仿函数
算数仿函数
功能描述:
实现四则运算。
其中,negate 是一元运算,其他都是二元运算。
// 加法仿函数
template T plus;
// 减法仿函数
template T minus;
// 乘法仿函数
template T multiplies;
// 除法仿函数
template T divides;
// 取模仿函数
template T modulus;
// 取反仿函数
template T negate;
#include
#include
using namespace std;
int main() {
plus add;
int result1 = add(2, 3); // 2 + 3 = 5
minus subtract;
int result2 = subtract(5, 2); // 5 - 2 = 3
multiplies multiply;
int result3 = multiply(4, 3); // 4 * 3 = 12
divides divide;
int result4 = divide(10, 2); // 10 / 2 = 5
modulus modulus;
int result5 = modulus(11, 3); // 11 % 3 = 2
negate negate;
int result6 = negate(7); // -7
cout << "Result 1: " << result1 << endl;
cout << "Result 2: " << result2 << endl;
cout << "Result 3: " << result3 << endl;
cout << "Result 4: " << result4 << endl;
cout << "Result 5: " << result5 << endl;
cout << "Result 6: " << result6 << endl;
return 0;
}
2.关系仿函数
// 等于仿函数
template bool equal_to;
// 不等于仿函数
template bool not_equal_to;
// 大于仿函数
template bool greater;
// 大于等于仿函数
template bool greater_equal;
// 小于仿函数
template bool less;
// 小于等于仿函数
template bool less_equal;
#include
#include
using namespace std;
int main() {
equal_to equals;
bool result1 = equals(2, 3); // 2 == 3, false
not_equal_to notEquals;
bool result2 = notEquals(5, 2); // 5 != 2, true
greater greaterThan;
bool result3 = greaterThan(4, 3); // 4 > 3, true
greater_equal greaterEqual;
bool result4 = greaterEqual(10, 2); // 10 >= 2, true
less lessThan;
bool result5 = lessThan(11, 3); // 11 < 3, false
less_equal lessEqual;
bool result6 = lessEqual(7, 7); // 7 <= 7, true
cout << "Result 1: " << boolalpha << result1 << endl;
cout << "Result 2: " << boolalpha << result2 << endl;
cout << "Result 3: " << boolalpha << result3 << endl;
cout << "Result 4: " << boolalpha << result4 << endl;
cout << "Result 5: " << boolalpha << result5 << endl;
cout << "Result 6: " << boolalpha << result6 << endl;
return 0;
}
3.逻辑仿函数
在逻辑仿函数中,返回值只有true和false,你可以把它类比为一个数据类型
// 逻辑与仿函数
template bool logical_and;
// 逻辑或仿函数
template bool logical_or;
// 逻辑非仿函数
template bool logical_not;
#include
#include
using namespace std;
int main() {
logical_and logicalAnd;
bool result1 = logicalAnd(true, false); // true && false, false
logical_or logicalOr;
bool result2 = logicalOr(true, false); // true || false, true
logical_not logicalNot;
bool result3 = logicalNot(true); // !true, false
cout << "Result 1: " << boolalpha << result1 << endl;
cout << "Result 2: " << boolalpha << result2 << endl;
cout << "Result 3: " << boolalpha << result3 << endl;
return 0;
}
常见遍历算法
1.for_each
for_each函数接受一个起始迭代器一个结束迭代器,并且对范围内的元素执行指定的操作,所以就直接调用print01中的operator函数
for_each:遍历容器
transform:复制一个容器到另外一个容器
#include
#include
using namespace std;
#include
class print01 {
public:
//operator是函数重载运算符
void operator() (int val) {
cout << val << " ";
}
};
int main() {
int i;
vector v;
for (i = 0; i < 10; i++) {
v.push_back(i * 10);
}
//for_each函数接受一个起始迭代器一个结束迭代器,并且对范围内的元素执行指定的操作,所以就直接调用print01中的operator函数
for_each(v.begin(), v.end(),print01());
}
2.transform
transform(iterator beg1, iterator end1, iterator beg2, _func);
// beg1: 源容器开始迭代器
// end1: 源容器结束迭代器
// beg2: 目标容器开始迭代器
// _func: 函数或函数对象
#include
#include
using namespace std;
#include
class print01 {
public:
void operator() (int val) {
cout << val << " ";
}
};
class trans {
public:
int operator() (int val) {
return val;
}
};
int main() {
int i;
vector v;
for (i = 0; i < 10; i++) {
v.push_back(i * 10);
}
for_each(v.begin(), v.end(), print01());
vector v2;
v2.resize(v.size());
transform(v.begin(), v.end(), v2.begin(), trans());
cout << endl;
for_each(v2.begin(), v2.end(), print01());
}
常见查找算法
1.find
#include
using namespace std;
int test1(vector v){
//如果没有找到那么find函数最后的值就是等于v.end
return find(v.begin(),v.end(),45)==v.end()?0:1;
}
int main(){
vector v;
for(int i=0;i<100;i++){
v.push_back(i);
}
cout<<(test1(v)==1?"find it":"NOT FIND");
}
2.find_if
#include
using namespace std;
class Persion{
public:
string name;
int age;
Persion(string name,int age){
this->name=name;
this->age=age;
}
bool operator==(const Persion per){
if(this->name==per.name&&this->age==per.age) return true;
else return false;
}
};
class Per{
public:
bool operator()(Persion per){
return per.age>20;
}
};
int main(){
int i;
vector per;
Persion p1("XIAOZHANG",34);
Persion p2("xiaoghei",45);
Persion p3("hihi",3);
per.push_back(p1);
per.push_back(p2);
per.push_back(p3);
vector::iterator it=find_if(per.begin(),per.end(),Per());
if(it!=per.end()){
int count=count_if(per.begin(),per.end(),Per());
for (int i = 0; i < count; i++) {
cout << "the name of person: " << it->name << " the age of person: " << it->age << endl;
it++;
}
}
}
3.adjacent_find
函数原型:
adjacent_find(iterator beg, iterator end) ;
查找相邻重复元素,返回相邻元素的第一个位置的迭代器ll beg 开始迭代器
end结束迭代器
#include
#include
using namespace std;
#include
int main() {
int i;
vector v;
v.push_back(0);
v.push_back(1);
v.push_back(1);
v.push_back(0);
v.push_back(3);
v.push_back(4);
v.push_back(4);
vector::iterator it = adjacent_find(v.begin(), v.end());
if (it != v.end()) {
cout << "找到了" << *it << endl;
}
}
4.binary_search
bool binary_search(iterator beg, iterator end, value);
// beg: 开始迭代器
// end: 结束迭代器
// value: 查找的元素
注意:在有序序列中可用,在无序序列中不可用
#include
#include
using namespace std;
#include
int main() {
int i;
vector v;
v.push_back(0);
v.push_back(1);
v.push_back(4);
v.push_back(6);
v.push_back(3);
v.push_back(56);
v.push_back(7);
sort(v.begin(), v.end());
bool sus = binary_search(v.begin(), v.end(),56);
if (sus) {
cout << "找到了" << endl;
}
}
5.count
count(iterator beg, iterator end, value);
// beg: 开始迭代器
// end: 结束迭代器
// value: 统计的元素
统计元素出现次数
#include
#include
using namespace std;
#include
int main() {
int i;
vector v;
v.push_back(0);
v.push_back(1);
v.push_back(4);
v.push_back(6);
v.push_back(6);
v.push_back(6);
v.push_back(6);
v.push_back(6);
v.push_back(3);
v.push_back(56);
v.push_back(7);
int sus = count(v.begin(), v.end(),6);
cout << "个数:" << sus << endl;
}
6.count_if
count_if(iterator beg, iterator end, _Pred);
// beg: 开始迭代器
// end: 结束迭代器
// _Pred: 谓词
按条件统计元素出现次数
#include
#include
using namespace std;
#include
#include
class Person {
public:
int age;
string name;
Person(int age, string name) {
this->age = age;
this->name = name;
}
bool operator ==(const Person per) {
if (this->name == per.name && this->age == per.age) {
return true;
}
else {
return false;
}
}
};
class Per {
public:
bool operator()(Person per) {
return per.age == 2;
}
};
int main() {
int i;
vector per;
Person p1(23, "张三");
Person p2(26, "张sg");
Person p3(24, "张df");
Person p4(2, "张d");
Person p5(2, "网d");
Person p6(2, "佛d");
Person p7(2, "张d");
per.push_back(p1);
per.push_back(p2);
per.push_back(p3);
per.push_back(p4);
per.push_back(p5);
per.push_back(p6);
per.push_back(p7);
int sus = count_if(per.begin(), per.end(), Per());
cout << "age为2的人数: " << sus << endl;
}
常见排序算法
#include
#include
using namespace std;
#include
void Print(vector &v) {
for (vector::iterator it = v.begin(); it != v.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
int main() {
int i;
vector v;
vector v2;
vector v3;
for (i = 0; i < 10; i++) {
v2.push_back(i);
}
v.push_back(0);
v.push_back(1);
v.push_back(4);
v.push_back(6);
v.push_back(62);
v.push_back(5);
v.push_back(78);
v.push_back(9);
v.push_back(10);
v.push_back(56);
v.push_back(7);
cout << "sort" << endl;
sort(v.begin(), v.end());
Print(v);
cout << "random sort" << endl;
random_shuffle(v.begin(), v.end());
Print(v);
cout << "reverse " << endl;
reverse(v.begin(), v.end());
Print(v);
cout << "resize" << endl;
v3.resize(v.size() + v2.size());
sort(v.begin(), v.end());
sort(v2.begin(), v2.end());
merge(v.begin(), v.end(), v2.begin(), v2.end(), v3.begin());
Print(v3);
}