高级分布式系统-第15讲 分布式机器学习--概念与学习框架
分布式机器学习的概念
人工智能蓬勃发展的原因:“大”
大数据:为人工智能技术的发展奠定了坚实的物质基础。
大规模机器学习模型:具备超强的表达能力,可以解决很多难度非常大的学习问题。
大规模计算机集群:以GPU集群为主,有着强大的并行度和计算能力,可以使复杂的训练过程变得更加高效。
在前所未有的大数据的支撑下,通过庞大的计算机集群,训练大规模的机器学习模型。

面临的问题:
计算量太大
解决方法:以采取基于共享内存(或虚拟内存)的多线程或多机并行运算。
训练数据太多
解决方法:将数据进行划分,并分配到多个工作节点上进行训练。
模型规模太大
解决方法:对模型进行划分,并且分配到不同的工作节点上进行训练。
分布式机器学习:也称为分布式学习,是指利用多个计算节点进行机器学习或者深度学习的算法和系统,旨在提高性能、保护隐私,并可扩展至更大规模的训练数据和更大的模型。
分布式机器学习框架
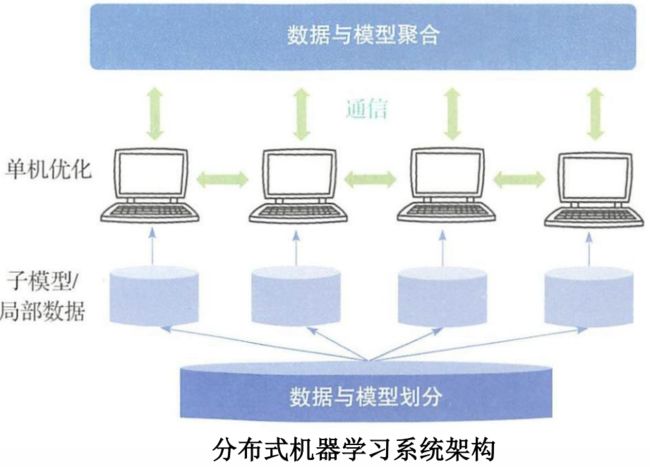
分布式机器学习的主要模块:数据与模型划分模块,单机优化模块,通信模块以及数据与模型聚合模块。
数据与模型划分模块:将数据或模型进行划分并将其分配到各个工作节点上。
单机优化模块:利用分配到的数据进行训练得到本地模型的更新。
通信模块:实现信息共享,把各个工作节点有机的组合到一起。
数据与模型聚合模块:如何将来自不同工作节点的数据、模型(或其更新)进行聚合。
分布式机器学习的主要模块:数据与模型划分模块,单机优化模块,通信模块以及数据与模型聚合模块。
分布式机器学习框架-----数据与模型划分
依据模型是否划分,如何划分,分布式机器学习可以分为计算并行模式,数据并行模式以及模型并行模式。
计算并行模式:所有的工作节点并行执行相应的优化算法。
数据并行模式:对数据集进行划分,并分配到各个工作节点进行训练。
模型并行模式:将对应于不同数据维度的模型参数划分到不同的工作节点,每个节点只独立更新自己负责的参数。

计算并行模式
前提:所有工作节点共享内存(单机多线程环境),对数据和模型有完全的访问和读写权限。
关键问题:
共享的数据如何生成?
工作节点如何获取数据?
数据的两种生成方式:
在线生成:工作节点读取的数据是即时从真实的数据分布中生成,生成过程直至优化算法结束。
离线生成:优化算法执行前从真实的数据分布中生成。算法执行后,不再生成新的数据。
数据并行模型
前提:工作节点拥有本地内存,但不足以存储下所有数据。
关键问题:数据如何划分?
需要考虑的因素:
数据量和数据维度与本地内存的相对大小
优化方法的特点
两种常见的数据划分方法:
数据样本划分:主要有基于随机采样的方法,基于置乱切分的方法。
数据维度划分:面向逻辑回归,支持向量机,线性回归等线性任务。
特点:对模型进行划分,各个工作节点负责本地局部模型的参数更新。对于具有变量可分性的线性模型和变量相关性强的非线性模型,模型并行的方式有所不同。

神经网络:
模型规模极大,具有很强的非线性,参数之间的依赖关系更强,不能进行简单的划分。



分布式机器学习框架-----单机优化
优化算法的分类:
依据是否对数据或者变量的维度进行了随机采样,把优化算法分为确定性算法和随机算法;
依据算法在优化过程中所利用的是一阶导数信息还是二阶导数信息,把优化算法分一阶方法和二阶方法;
依据优化算法是在原问题空间还是在对偶空间进行优化,把优化算法分为原始方法和对偶方法。
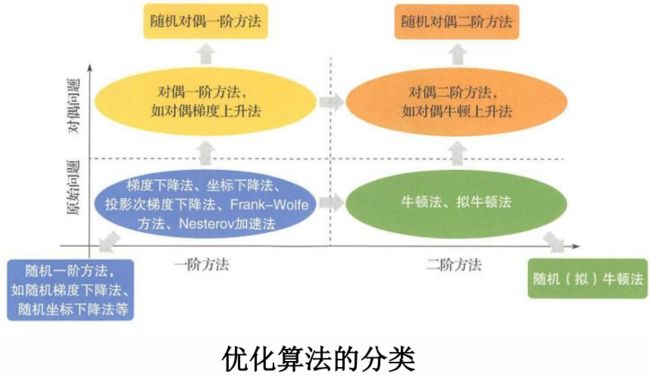
单机优化模块:对于每一个工作节点,本质上是一个传统的单机机器学习任务。

分布式机器学习框架-----通信机制
通信-分布式机器学习的关键
降低通信与计算的时间比例,更加高效地训练出高精度模型。即在算法和系统之间取得平衡。相比于一般的分布式计算,更具挑战性:
通信频率过高
通信的数据量大
需要考虑的内容:
通信的内容:在各个工作节点之间通信的是什么信息。
通信的拓扑结构:通信过程中哪些工作节点之间需要进行通信,即系统中各个工作节点的连接方式。
通信的步调:在通信时如何处理节点之间的速度差异,从而使得众多节点能够一起协作。
通信的频率:是如何有效地在时间和空间上减少通信量,从而提高并行学习效率。
分布式机器学习框架-----通信
通信的内容取决于并行方式,可分为以下两类:
参数或参数的更新:基于数据并行的分布式学习
特点:数据量是稀疏的,随着模型的收敛,参数的更新会越来越少,使得通信量减少。
计算的中间结果:基于模型并行的分布式学习
特点:需要按照模型的连接关系在对应的工作节点之间进行通信。
通信的目的是不断突出各个工作节点在某些方面的判决能力,直到最终各个节点上的模型在各自擅长的问题或擅长处理的部分样本上到达比较高的精度,再综合所有工作节点的判决能力,在整个样本空间更加出色的完成预测任务。
通信的逻辑拓扑:
逻辑拓扑结构的演化与分布式机器学习的发展历史有关。可以分为以下三种拓扑结构。
(1)基于迭代式MapReduce/AllReduce 的通信拓扑

(2)基于参数服务器的通信拓扑

(3)基于数据流的通信拓扑
同步通信和异步通信
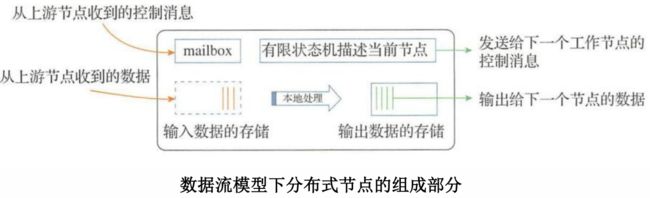
通信的步调根据参数聚合方式的不同可以分为同步通信和异步通信。
目标:更好的对系统中的工作节点进行协调。
同步通信:当集群中的工作节点完成本轮迭代后,需要等待集群中的其他工作节点都完成各自的任务,才能共同进行下一轮迭代。

异步通信:集群中的一个工作节点完成本轮迭代后,无须等待集群中的其他工作节点,继续进行后续训练。
同步和异步的平衡
同步通信的缺点:容易收到速度较慢的工作节点的拖累。
异步通信的缺点:会带来更新的“延迟问题”,影响训练过程的收敛性。
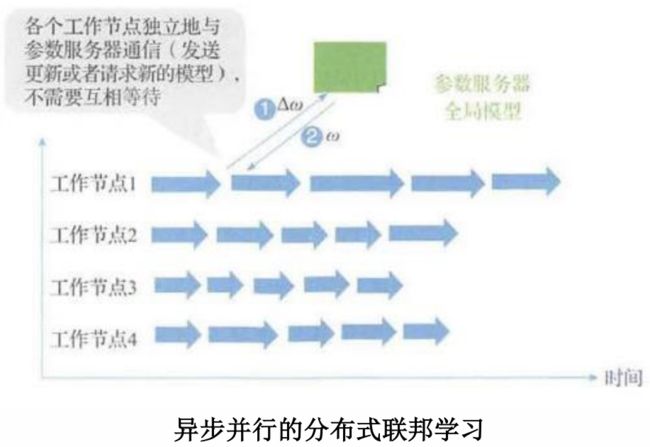
解决方法:提出介于同步和异步之间的通信方式。
经典方法:延时同步并行(Stale Synchronous Parallel, SSP)
同步和异步的平衡
核心思想:控制最快和最慢节点之间相差的迭代次数不超过预设的阈值。

通信的频率
通信的频率:可分为时间频率和空间频率。
时间频率:通信的频次,优化从时域滤波进行。
时域滤波从通信的过程出发,通过控制通信的时机,减少通信次数,从而降低通信代价。
主要方法:增加通信间隔、对称的推送和获取以及计算和传输流水线。
空间频率:通信的内容大小,优化从空域滤波方面进行。
空域滤波从通信的内容出发,尽量减少通信的数据量,对传输的内容行过滤、压缩和量化,降低每一次通信的时间。
主要方法:模型过滤,模型低秩化处理和模型量化。
时域滤波
增加通信间隔:通信的频率从原来本地模型每次更新后都通信一次,变成本地模型多次更新后才通信一次。
非对称的推送和获取:对推送模型更新和获取最新的全局模型更新这两种通信操作采用不同的通信频率。
计算和传输流水线:在系统中设置两个不同的模型缓存,分别负责训练线程和通信线程,两个线程同时进行。

空域滤波
模型过滤:将一次迭代中某些没有明显变化的参数过滤,从而减少通信量。
模型低秩化处理:通过低秩分解压缩参数来减少通信量。
模型量化:通过降低参数的每一维浮点数的精度来减少通信量。
分布式机器学习框架-----数据与模型聚合
聚合:分布式机器学习特有的逻辑。
需求:1、聚合本身的时间代价比较少;
2、聚合算法合理、有效,整体的收敛性仍然能保持与单机算法大体一致。
基于模型加和的聚合方法:基于全部模型加和的聚合、基于部分模型加和的聚合。
典型方法:模型平均、ADMM算法、同步随机梯度下降法、带备份节点的同步随机梯度下降法、异步ADMM 算法以及去中心化方法。
基于模型集成的聚合方法:基于输出加和的聚合、基于投票的聚合。典型方法:集成-压缩算法。
基于全部模型加和的聚合
最常用的模型聚合方法,在参数服务器端将来自不同工作节点的模型或者模型更新进行加权求和。
优点:运算复杂度低,逻辑简单,不会对整个分布式训练过程带来过多的额外压力。
缺点:适合同步聚合,存在被拖垮的风险。

基于部分模型加和的聚合
基本思想:在聚合梯度时,仅聚合一定比例的梯度,防止计算很慢的节点拖累聚合的效率。
优点:避免了以同步并行机制运行时,少量速度慢的工作节点拖累甚至阻塞整个系统学习进度的情况出现。
带备份节点的同步随机梯度下降法。
采用了空间换时间的思想:用 ( + )个工作节点来保证每次取前个工作节点作为聚合对象时会保持比较高的效率。
基于部分模型的加权聚合
去中心化方法
让每个工作节点有更多的自主性,使模型的维护和更新更加分散化,易于扩展。每个工作节点可以根据自己的需求来选择性地仅与少数其他节点通信。

基于输出加和的聚合

神经网络的损失函数关于模型参数是非凸的,但是损失函数关于模型的输出一般是凸的。
基本思想:对局部模型的输出进行加和或者平均。
优点:通过集成多个模型的预测结果,可以取得比单个模型更好的性能。
缺点:模型集成后产生的新模型参数量是局部模型的K倍。考虑到模型聚合会在分布式学习的迭代算法中多次发生,这很可能导致模型规模爆炸。
集成-压缩算法
1)各个工作节点依照本地局部数据训练出局部模型;
2)工作节点之间相互通信获取彼此的局部模型,集成所有的局部模型得到集成模型,并对(一部分)局部数据使用集成模型进行再标注;
3)利用模型压缩技术,结合数据的再标注信息,在每个工作节点上分别进行模型压缩,获得与局部模型大小相同的新模型作为最终的聚合结果。
