模板与STL(C++)
- 七、模板与STL(泛型编程)
-
- 7.1 模板的概念
- 7.2 函数模板
-
- 7.2.1 函数模板的定义
- 7.2.2 函数模板的实例化
- 7.2.3 模板参数
- 7.2.4 函数模板的特化
- 7.3 类模板
-
- 7.3.1 类模板的定义
- 7.3.2 类模板实例化
- 7.3.3 类模板特化
- 7.4 STL容器
-
- 7.4.1 容器
- 1.4.2 迭代器
- 1.4.3 关联式容器
- 1.4.4 算法
七、模板与STL(泛型编程)
模板(template)是C++实现代码重要机制的重要工具,是泛型技术(即与数据类型无关的通用程序设计技术)的基础。模板表示的是概念级的通用程序设计方法,它把算法和数据类型区分开来,能够设计出独立于具体数据类型的模板程序,模板程序能以数据类型为参数生成针对于该类型的实际程序代码。模板分为函数模板和类模板两类,ANSI标准C++库就是使用模板技术实现的。
7.1 模板的概念
某些程序除了所处理的数据类型之外,程序代码和程序功能相同,但为了实现他们,却不得不编写多个与具体数据类型紧密结合的程序,例如
int Min(int a, int b){
return a<b?a:b;
}
float Min(float a, float b){
return a<b?a:b;
}
double Min(double a, double b){
return a<b?a:b;
}
char Min(char a, char b){
return a<b?a:b;
}
如何简化以上编程呢?C语言中,可以通过宏的方式实现以上想法:
#define Min(a,b) ((a) < (b))?(a):(b)
C++中,也可以利用宏来进行类似程序设计,但宏避开了C++类型检查机制,在某些情况下可能引发错误,是不安全的。更好的方法就是模板来实现这样的程序设计。
C++中的模板与制作冰糕的模具很相似,是生产函数或类的模具。模板接收数据类型参数,并根据此类型创建相应的函数或类。
对于上面的所有Min()而已,只需要下面的函数模板就能够生成所有的Min()函数。
template <typename T>
T Min(T a, T b){
return a<b?a:b;
}
template和typenae是用来定义模板的关键字。min模板不涉及任何具体的数据类型,而是用T代表任意数据类型,称为类型参数。Min模板代表了求两个数据最小的通用算法,它与具体数据类型无关,但能够生成计算各种具体数据类型的最小值的函数。编译器的做法是用具体的类型替换模板中的类型参数T,生成具体类型的函数Min()。比如用int替换掉模板中的所有T就能生成求两个int类型数据的函数min()。
#include
template <typename T>
T Min(T a, T b){
return a<b?a:b;
}
int main(void){
int i = 4, j = 8;
char i2 = '4', j2 = '3';
cout << Min(i, j) << endl;
cout << Min(i2, j2) << endl;
return 0;
}
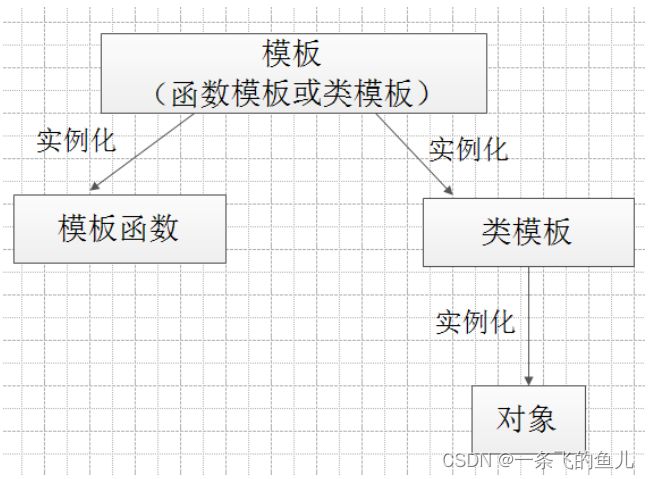
从函数模板Min可以看成,C++模板提供了对逻辑结构相同的数据对象通用行为的定义方法,它把通用算法的实现和具体的数据类型区分开来,模板操作的是参数化的数据类型(类型参数)而非实际数据类型。一个带有类型参数的函数称为函数模板,带有类型参数的类型称为模板类。
在调用模板时,必须为它的类型参数提供实际数据类型,C++将用该数据类型替换模板中的全部类型参数,由编译器生成与具体的数据类型相关的运行的程序代码,这个过程称为模板的实例化。由函数模板实例化生成的函数称为模板函数,由类模板实例化生成的类称为模板类。
7.2 函数模板
函数模板提供了一种通用的函数行为,该函数行为可以用多种不同的数据类型进行调,编译器会根据调用类型自动将它实例化为具体数据类型的函数代码,也就是说函数模板代表了一个函数家族。与普通函数相比,函数模板中某些函数元素的数据类型是未确定的,这些元素的类型将在使用时被参数化;与重载函数相比,函数模板不需要程序员重复编写函数代码,它可以自动生成许多功能相同单参数和返回值类型不同的函数。
7.2.1 函数模板的定义
template <typename T1, typename T2, ...>
返回类型 函数名(参数表){
... ...
}
template是模板定义的关键字写在<>中的T1 T2…是模板参数中的typename表示其后的参数可以是任意类型的。
#include
template <typename T>
T Min(T a, T b){
return a<b?a:b;
}
int main(void){
int i = 4, j = 8;
char i2 = '4', j2 = '3';
cout << Min(i, j) << endl;
cout << Min(i2, j2) << endl;
return 0;
}
7.2.2 函数模板的实例化
当编译器遇到关键字template和跟随其后的参数定义时,它只是简单地知道这个函数模板在后面的程序代码中可能会用到。除此之外,编译器并不会做额外的工作。在这个阶段函数模板本身并不能使编译器产生任何代码,因为编译器此时并不知道函数模板要处理的具体数据类型,根本无法生成任何函数代码。
当编译器此时并不知道函数模板要处理的具体数据类型,根本无法生成任何函数代码。
当编译器遇到程序中对函数模板的调用时,它才会根据调用语句中实参的具体类型,确定模板参数的数据类型,并用此类型替换函数模板的模板参数,生成能够处理该类型的函数代码,即模板函数。
对于7.2.1代码可以执行一下命令观察实验效果。
nm a.out | grep a.out
7.2.3 模板参数
-
模板参数的匹配问题
C++在实例化函数模板的过程中,只是简单地将模板参数替换为实参的类型,并以此生成模板函数,不会进行参数类型的任何转换。这种方式与普通函数的参数处理有着极大的区别,以前在普通函数的调用过程中,会进行参数的自动类型转换。
#includeusing namespace std; double Max(double a, double b) { return a>b?a:b; } int main(void) { double a = 2, b = 3.14; float c = 4.6, d = 5.7; cout << "2 3.14 : " << Max(a,b) << endl; cout << "2 4.6 : " << Max(a,c) << endl; cout << "2 100 : " << Max(a,100) << endl; return 0; } 以上程序能够正确执行,现在使用函数模板来实现通用的功能,如下所示
#includeusing namespace std; template <typename T> T Max(T a, T b){ return a>b?a:b; } int main(void) { double a = 2, b = 3.14; float c = 4.6, d = 5.7; cout << "2 3.14 : " << Max(a,b) << endl; cout << "2 4.6 : " << Max(a,c) << endl; cout << "2 100 : " << Max(a,100) << endl; return 0; } 编译以上程序,产生模板参数不匹配的错误。产生这个错误的原因是模板实例化过程中不会进行任何的参数类型转换。编译器在翻译Max(a,c)时,由于实参类型为double和float,而Max函数模板只有一个形参类型T,总不能让T同时取double和float两种类型吧?要知道模板实例化过程中,C++不会进行任何形式的隐式类型转换,于是产生了上述编译错误。
这种问题的解决方式有:
-
在模板调用时进行参数类型的强制转换
cout << "2 4.6 : " << Max(a,double(c)) << endl; cout << "2 100 : " << Max(a,double(100) << endl; -
显示指定函数模板实例化的类型参数
cout << "2 4.6 : " << Max<double>(a,c) << endl; cout << "2 100 : " << Max<double>(a,100) << endl; -
指定多个模板参数
在模板函数的调用过程中,为了避免出现一个模板参数与多个调用实参的类型冲突问题,可以为函数模板指定多个不同的类型参数。
#includeusing namespace std; template <typename T1, typename T2> T1 Max(T1 a, T2 b){ return a>b?a:b; } int main(void) { double a = 2, b = 3.14; float c = 4.6, d = 5.7; cout << "2 3.14 : " << Max(a,b) << endl; cout << "2 4.6 : " << Max(a,c) << endl; cout << "2 100 : " << Max(a,100) << endl; return 0; } -
模板函数的形参表
不要误以为函数模板中的参数只能是类型形参,它也可以包括普通类型的参数。
#includeusing namespace std; template <typename T> void display(T &arr, unsigned int n){ for(int i = 0; i < n; i++){ cout << arr[i] << "\t" ; } cout << endl; } int main(void) { int a[] = {1,2,3,4,5,6,7,8}; char b[] = {'a','b','c','d','e','f'}; display(a, sizeof(a)/sizeof(a[0])); display(b, sizeof(b)/sizeof(b[0])); return 0; } //输出结果 myubuntu@ubuntu:~/lv19/cplusplus/dy08$ ./a.out 1 2 3 4 5 6 7 8 a b c d e f
-
7.2.4 函数模板的特化
在某些情况下,函数模板并不能生成处理特定数据类型的模板函数,上面例子中的Max函数模板可以计算int 或者 char 类型数据的最大值,但对于字符串类型却是无能为力的。解决这类问题的方法就是对函数模板进行特化。所谓特化,就是针对模板不能处理的特殊数据类型,编写与模板同名的特殊函数专门处理这些数据类型。语法格式如下所示。
template<>
返回类型 函数名<特化的数据类型>(参数表){
...
}
例如:
#include 7.3 类模板
函数模板用于设计程序代码相同而所处理的数据类型不同的通用函数。与此类似,C++也支持用类模板来设计结构和成员函数完全相同,但所处理的数据类型不同的通用类。比如,对于堆栈类而言,可能存在整数栈、双精度栈、字符栈等多种不同数据类型的栈,每个栈除了所处理的数据类型不同之外,类的结构和成员函数完全相同,可为了在非模板的类设计中实现这些栈,不得不重复编写各个栈类的相同代码,例如初始化栈、入栈、出栈等操作。为了解决该问题,C++中用类模板设计这样的类簇最方便,一个类模板就能够实例化生成所需要的栈类。
类模板也称为类属类,它可以接收类型为参数,设计出与具体类型无关的通用类。在设计类模板时,可以使其中的某些数据成员,成员函数的参数或返回值与具体类型无关。
7.3.1 类模板的定义
类模板与函数模板的定义形式类似,如下所示:
template <typename T1, typename T2, ...>
class 类名{
...
}
实例:设计一个栈的类模板Stack,在模板中使用类型参数T表示栈中存放的数据,用非类型参数MAXSIZE代表栈的大小。
vi Stack.cpp
#include 7.3.2 类模板实例化
类模板的实例化包括模板实例化和成员函数实例化。当用类模板定义对象时,将引起类模板的实例化。在实例化模板时,如果模板参数就是类型参数,则必须为它指定具体的类型;如果模板参数是非类型参数,则必须为它指定一个常量值。如对前面的Stack类模板而言,下面是他的一条实例化语句:
Stack<int, 10> istack;
编译器实例化Stack的方法是:将Stack模板声明中的所有的类型参数T替换为int,将所有的非类型参数MAXSIZE替换为10,这样就用Stack模板生成了一个int类型的模板类。为了区别于普通类,暂且将该类记作Stack
class Stack{
private:
int elements[10]; // MAXSIZE 替换为 10 , T类型 替换为 int
int top; //栈顶
public:
Stack():top(0){
}
void push(int e);
int pop();
bool empty(){
return top == 0;
}
bool full(){
return top==MAXSIZE;
}
};
最后C++用这个模板类定义一个对象istack.
注意:在上面的实例化过程中,并不会实例化模板的成员函数,也就是说,在用类模板定义对象时并不会生成类成员函数的代码。类模板成员函数的实例化发生在该成员函数被调用时,这就以为着只有那些被调用的成员才会被实例化。或者说,只有当成员函数被调用了,编译器才会为它生成真正的代码。
#include 可以将pop函数的类外定义删除掉,然后再编译运行程序,可以发现的是程序依然能够正确的执行。
与普通类的对象一样,类模板的对象或引用也可以作为函数的参数,只不过这类函数通常是模板函数,且其调用实参常常是该类模板的模板类对象。
#include 7.3.3 类模板特化
类模板代表了一种通用程序设计的方法,它表示了无限类集合,可以实例化生成基于任何类型的模板类。在通常情况下,由类模板生成的模板类都能够正常的工作,但也有类模板生成的模板类代码对某些数据类型不适用的情况。
如:设计一个通用数组类,它能够直接存取数组元素,并能够输出数组中的最小值。
#include 显然Arr类模板并不完全适用于生成char *类型的模板类,因为Arr类模板的Min成员函数并使用于字符指针类型的计算大小。
解决上述问题的方法就是类模板特化,即用与该模板相同的名字为某种数据类型专门重新一个模板类。特化类模板时,可以随意增减和改写模板原有的成员,成员函数的改写也不受任何限制,可以与原来的成员函数变得完全不同。
类模板有两种特化方式,一种是特化整个类模板,另一种是特化个别成员函数。前者是为某种类型单独建立一个类,后者则只针对特化的数据类型提供个别成员函数的实现代码,特化后的成员函数不再是一个模板函数,而是针对特点类型的普通函数。
与函数模板特化方式相同,类模板成员函数的特化也以templat<>开头。形式如下:
template<>
返回类型 类模板名<特化的数据类型>:: 特化成员函数名(参数表){
...
}
Arr类模板对char * 类型来说,除了Min成员函数不适用外,其余成员都可以,则针对char * 类型重新编写Min成员函数,即特例Arr类模板的Min成员函数就能够解决字符串求大小的问题。特化的Min函数如下:
template<>
char * Arr<char *>::Min(){
char *temp;
temp = arr[0];
for(int i=1; i < size; i++){
if(strcmp(temp, arr[i]) > 0)
temp = arr[i];
}
return temp;
}
为了某种数据类型特化整个类模板也要以template<> 开头,形式如下所示:
template<> class 类模板名<特化的数据类型>{
...
}
7.4 STL容器
STL就是标准模板库(Standard Template Library), 它提 供了模板化的通用类和通用函数。STL的核心内容包括 容器、迭代器、算法三部分内容,三者常常协同工作, 为各种编程问题提供有效的解决方案。 STL提供了许多可直接用于程序设计的通用数据结构哈 功能强大的类与算法,是程序设计者的一个巨大宝藏。 程序员可以在STL中找到各种常用的数据结构和算法, 这些数据结构和算法是准确而有效的,用它们来解决编 程中的各种问题,可以减少程序测试时间,写出高质量 的代码,提高编程效率。
7.4.1 容器
容器是用来存储其它对象的对象。容器是容器类的实 例,而容器类使用类模板实现的,适用于各种数据类 型。STL的容器常被分为顺序容器、关联容器和容器适 配器三类。顺序容器常被称为序列容器,它是将相同类 型对象的有限集按顺序组织在一起的容器,用来表示线 性数据解结构,C++提供的顺序类型容器有向量 (vector)、链表(list)、双端队列(deque);关联容器是非线 性容器,是用来根据键(key)进行快速存储、检索数据的 容器。这类容器可以存储值的集合或键值对,C++中的 关联容器主要包括集合(set)、多重集合(multiset)、映射 (map)、多重映射(multimap);容器适配器主要指堆栈 (stack)和队列(queue),它们实际是受限制访问的顺序容 器类型。
STL库中十大容器:
| STL容器名 | 头文件 | 说明 |
|---|---|---|
| vector | 向量,从后面快速插入和删 除,直接访问任何元素 | |
| list | 双向链表 | |
| deque | 双端队列 | |
| set | 元素不重复的集合 | |
| multiset | 元素可重复的集合 | |
| stack | 堆栈,先进后出 | |
| map | 一个键只对应一个值得映射 | |
| mutimap | 一个键可对应对个值得映射 | |
| queue | 队列,先进先出 | |
| priority_queue | 优先级队列 |
STL是经过精心设计的,为了减小操作使用容器的难度,大多数容器都提供了相同的成员函数,如下表所 示。
所有容器都具有 的成员函数
| 成员函数 | 说明 |
|---|---|
| 默认构造函 数 | 对容器进行默认初始化的构造函数,常 有多个,用于提供不同的容器初始化方 法 |
| 拷贝构造函 数 | 用于将容器初始化为同类型的现有容器 的副本 |
| 析构函数 | 执行容器销毁时的清理工作 |
| empty() | 判断容器是否为空,为空返回true |
| max_size() | 返回容器的最大容量 |
| size | 返回容器中当前元素的个数 |
| operator= | 将一个容器赋给另一个同类容器 |
| operator< | 如果第一个容器小于第二个容器,返回 true |
| operator<= | 如果第一个容器小于等于第二个容器, 返回true |
| operator> | 如果第一个容器大于第二个容器,返回 true |
| operator>= | 如果第一个容器大于等于第二个容器, 返回true |
| swap | 交换两个容器中的元素 |
-
vector
vector 容器是STL中最常用的容器之一, vector 实现的是一个动态数组,即可以进行元素的插入和删 除,在此过程中,vector 会动态调整所占用的内存空 间,整个过程无需人工干预。
vector 容器以类模板 vector( T 表示存储元素的类 型)的形式定义在 头文件中,并位于 std 命名空间 中。因此,在创建该容器之前,代码中需包含如下内 容:
#includeusing namespace std; -
创建向量容器的方式
vector<double> values; values.reserve(20); //指定初始值以及元素个数 vector<int> primes {2, 3, 5, 7, 11, 13, 17, 19}; //创建 vector 容器时,指定元素个数 vector<double> values(20); //有 20 个元素,它们的默认初始值都为 0。 vector<double> values(20, 1.0); //有 20 个元素,它们的默认初始值都为 1.0。 //通过存储元素类型相同的其它 vector 容器,创建新的 vector 容器 vector<char>value1(5, 'c'); vector<char>value2(value1); -
vector容器包含的成员函数
函数成员 函数功能 begin()返回指向容器中第一个元素的迭代器。 end()返回指向容器最后一个元素所在位置后一个位置的迭代器,通常和 begin()结合使用。rbegin()返回指向最后一个元素的迭代器。 rend()返回指向第一个元素所在位置前一个位置的迭代器。 cbegin()和 begin()功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。cend()和 end()功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。crbegin()和 rbegin()功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。crend()和 rend()功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。size()返回实际元素个数。 max_size()返回元素个数的最大值。通常是一个很大的值,一般是 2^32-1,所以我们很少会用到这个函数。 resize()改变实际元素的个数。 capacity()返回当前容量。 empty()判断容器中是否有元素,若无元素,则返回 true;反之,返回 false。 reserve()增加容器的容量。 shrink_to_fit()将内存减少到等于当前元素实际所使用的大小。 operator[]重载了 [ ] 运算符,可以向访问数组中元素那样,通过下标即可访问甚至修改 vector 容器中的元素。 at()使用经过边界检查的索引访问元素。 front()返回第一个元素的引用。 back()返回最后一个元素的引用。 data()返回指向容器中第一个元素的指针。 assign()用新元素替换原有内容。 push_back()在序列的尾部添加一个元素。 pop_back()移出序列尾部的元素。 insert()在指定的位置插入一个或多个元素。 erase()移出一个元素或一段元素。 clear()移出所有的元素,容器大小变为 0。 swap()交换两个容器的所有元素。 emplace()在指定的位置直接生成一个元素。 emplace_back()在序列尾部生成一个元素。
#include#include using namespace std; void display(vector<int> &v){ while(!v.empty()){ cout << v.back() << " "; //读出最后一个元素 v.pop_back(); //抛出最后一个元素 } cout << endl; } int main(void){ vector<int> v1; v1.reserve(10); cout << v1.capacity() << endl; display(v1); vector<int> v2(100); cout << v2.capacity() << endl; vector<int> v3(5, 8); cout << v3.capacity() << endl; v3.insert(v3.begin(), 6886); //在最后一个元素插入 6886 display(v3); return 0; } -
-
list
list 容器,又称双向链表容器,即该容器的底层是以 双向链表的形式实现的。这意味着,list 容器中的元 素可以分散存储在内存空间里,而不是必须存储在一 整块连续的内存空间中。
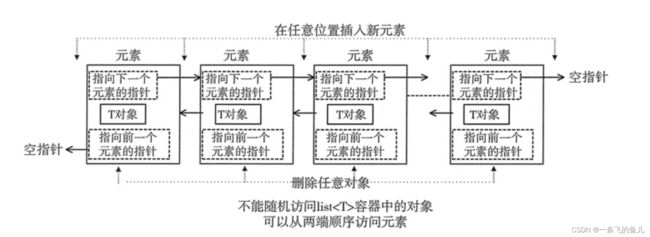
#include-
list容器的创建
list<int> values; // 没有任何元素 list<int> values(10); // 包含10个元素,每个元素的值都为相应类型的默认值(int类型默认值为0) list<int> values(10, 5); // 包含10个元素,并且值都为5。 list<int> value2(values); // 和values元素个数、内容相同 // 拷贝普通数组,创建list容器 int a[] = {1, 2, 3, 4, 5}; std::list<int> values(a, a + 5); // values中有5个元素,分别为1, 2, 3, 4, 5 -
常用成员函数
成员函数 功能 begin()返回指向容器中第一个元素的双向迭代器。 end()返回指向容器中最后一个元素所在位置的下一个位置的双向迭代器。 rbegin()返回指向最后一个元素的反向双向迭代器。 rend()返回指向第一个元素所在位置前一个位置的反向双向迭代器。 cbegin()和 begin()功能相同,只不过在其基础上,增加了const属性,不能用于修改元素。cend()和 end()功能相同,只不过在其基础上,增加了const属性,不能用于修改元素。crbegin()和 rbegin()功能相同,只不过在其基础上,增加了const属性,不能用于修改元素。crend()和 rend()功能相同,只不过在其基础上,增加了const属性,不能用于修改元素。size()返回实际包含的元素个数。 max_size()返回容器所能包含元素个数的最大值。这通常是一个很大的值,一般是2^32-1,所以我们很少会用到这个函数。 front()返回第一个元素的引用。 back()返回最后一个元素的引用。 assign()用新元素替换容器中原有内容。 emplace_front()在容器头部生成一个元素。 push_front()在容器头部插入一个元素。 pop_front()删除容器头部的一个元素。 emplace_back()在容器尾部直接生成一个元素。 push_back()在容器尾部插入一个元素。 pop_back()删除容器尾部的一个元素。 emplace()在容器中的指定位置插入元素。该函数和 insert()功能相同,但效率更高。insert()在容器中的指定位置插入元素。 erase()删除容器中一个或某区域内的元素。 swap()交换两个容器中的元素,必须保证这两个容器中存储的元素类型是相同的。 resize()调整容器的大小。 clear()删除容器存储的所有元素。 splice()将一个list容器中的元素插入到另一个容器的指定位置。 remove(val)删除容器中所有等于 val的元素。remove_if()删除容器中满足条件的元素。 unique()删除容器中相邻的重复元素,只保留一个。 merge()合并两个事先已排好序的list容器,并且合并之后的list容器依然是有序的。 sort()通过更改容器中元素的位置,将它们进行排序。 reverse()反转容器中元素的顺序。 #include#include
-
-
stack
STL 提供了 3 种容器适配器,分别为 stack 栈适配 器、queue 队列适配器以及 priority_queue 优先权 队列适配器。 容器适配器本质上还是容器,只不过此 容器模板类的实现,利用了大量其它基础容器模板类 中已经写好的成员函数。 要使用STL中的堆栈容器,代码中需要包含下面两行 代码:
#includeusing namespace std; STL中提供堆栈容器的主要操作如下:
push(), 将一个元素加入stack内,加入的元素放在栈顶
top(), 返回栈顶元素的值
pop(), 删除栈顶元素
#include#include using namespace std; int main(void) { stack<int> s; s.push(50); s.push(60); s.push(70); s.top() = 100; while(!s.empty()){ cout << s.top() << endl; // 100 60 50 s.pop(); } return 0; }
1.4.2 迭代器
迭代器(iterator)是一个对象,常用它来遍历容器,即 在容器中实现“取得下一个元素”的操作。不管容器是否 直接提供了访问其对象的方法,通过迭代器都能够访问 该容器中的UI小,一次访问一个元素。
迭代器是STL的核心,它定义了哪些算法在哪些容器中 可以使用,把算法和容器连接起来,使算法、容器和迭 代器能够协同工作,实现强大的程序功能。
若某个容器要使用迭代器,它就必须定义迭代器。定义 迭代器时,必须指定迭代器所使用的容器类型。比如, 若定义了一个保存int类型元素的链表:
list<int> L1;
则为int类型的list容器指定迭代器的定义如下:
list<int>::iterator iter;
完成该定义后,STL会自动将此迭代器转换成链表所需 要的双向迭代器,该迭代器可以用于int型的list。 迭代器提供的主要操作如下:
operator* 返回当前位置的元素值
operator++ 将迭代器前进到下一个元素位置
operator-- 将迭代器后退到前一个元素位置
operator==或operator!= 判定两个迭代器是否指向同一个位置
operator= 为迭代器赋值
begin() 指向容器起点(即第一个元素)位置
end() 指向容器的结束点,结束点在最后一个元素之后
rbegin() 指向按反向顺序的第一个元素位置
rend() 指向按反向顺序的最后一个元素后的位置
实例:
#include
using namespace std;
int main(void) {
int i = 0;
list<int> L1, L2, L3(10);
list<int>::iterator iter;
int a1[] = {100, 90, 80, 70, 60};
int a2[] = {30, 40, 50, 60, 60, 60, 80};
// 使用数组a1的元素填充L1
for (i = 0; i < 5; i++)
L1.push_back(a1[i]);
// 使用数组a2的元素填充L2
for (i = 0; i < 7; i++)
L2.push_back(a2[i]);
// 显示L1的元素
for (iter = L1.begin(); iter != L1.end(); iter++) {
cout << *iter << "\t";
}
cout << endl;
int sum = 0;
// 以逆序显示L2的元素
for (iter = --L2.end(); iter != L2.begin(); iter--) {
iter = L2.end();
do {
iter--;
cout << *iter << "\t";
sum += *iter;
} while (iter != L2.begin());
cout << "\nL2: sum=" << sum << endl;
}
int data = 0;
// 为L3分配递增的值
for (iter = L3.begin(); iter != L3.end(); iter++)
*iter = data += 10;
// 显示L3的元素
for (iter = L3.begin(); iter != L3.end(); iter++) {
cout << *iter << "\t";
}
cout << endl;
return 0;
}
STL中的迭代器可分为双向迭代器、前向迭代器、后向 迭代器、输入迭代器和输出迭代器几种类型。前面介绍 的迭代器属于双向迭代器,读者若要了解其他几种迭代 器的用法,可以参考C++帮助文档。
1.4.3 关联式容器
STL关联容器包括集合和映射两大类,集合包括set和 multiset,映射包括map和multimap,它们通过关键字 存储和查找元素。在每种关联容器中,关键字按顺序排 列,容器遍历就可以顺序进行。
-
set和multiset
集合类multiset和set提供了控制数字(包括字符及串) 集合的操作,集合中的数字称为关键字,不需要有另 一个值与关键字相关联。set和multiset会根据特定的 排序准则,自动将元素排序,两者提供的操作方法基 本相同,只是multiset允许元素重复而set不允许重 复。

定义:
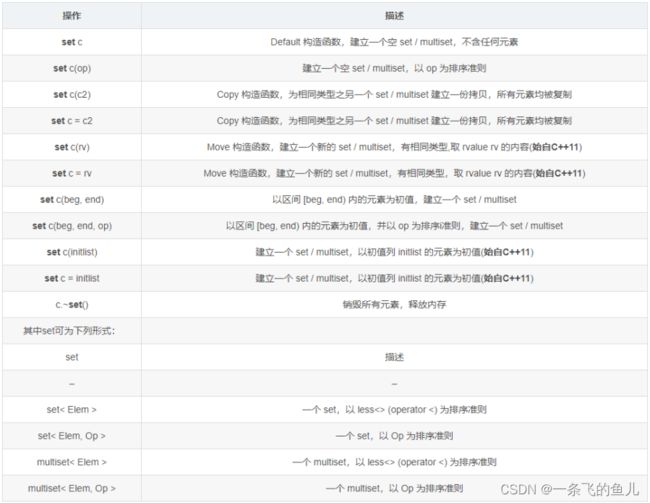
其中op可以是less<>或greater<>之一,应用时 须在<>中写上类型,如greater。less指定排序方式为 从小到大,greater指定排序方式为从大到小,默认 排序方式为less。
非更易型操作:
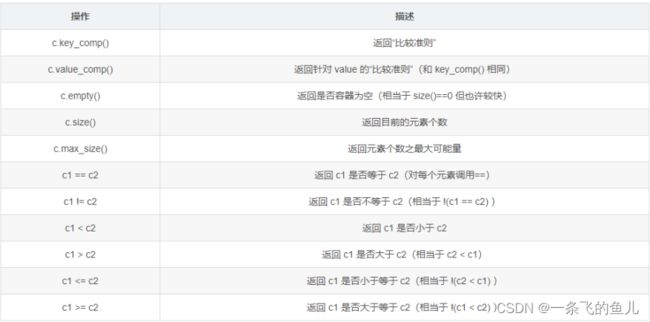
查找操作:

赋值操作:

迭代操作:

插入移除操作:

实例:
#include -
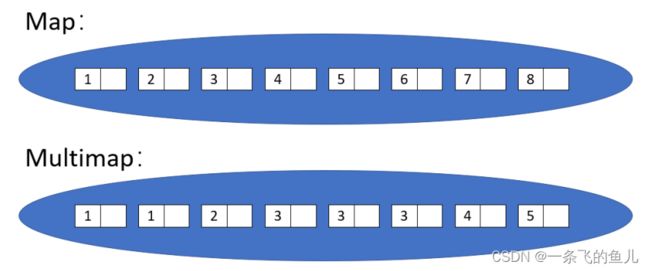
map和multimap
map和multimap提供了操作<键,值>对的方法,它 们存储一对对象,即键对象和值对象,键对象是用于 查找过程中的键,值是与键对应的附加数据。例如, 若键为单词,对应的值是表示该单词在文档中出现此 数的数字,这样的map就成了统计单词在文本中出现 次数的频数表;再如,若键为单词,值是单词出现的 页号链表,用multimap实现这样的键值对象就是可 以构造单词索引表。
map中的元素不允许重复,而multimap中的元素是 可以重复的。
定义:
非更易型操作:

查找操作:

赋值操作:
迭代操作:

插入移除操作:

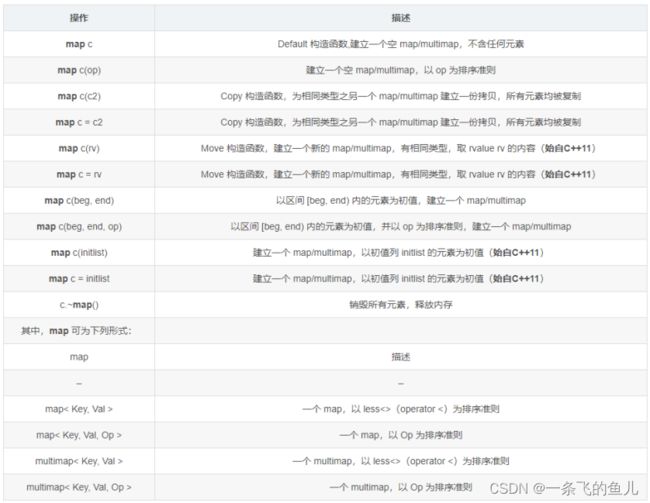
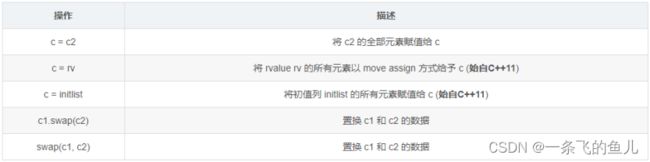
前面介绍的set/multiset集合操作的方法同样适用于 map/multimap,包括集合的建立方法、成员函数、 比较运算、排序规则和方法等,只需要将其中的set 更改为map,将multiset更改为multimap就行了。需 要说明的只有insert函数和元素访问的不同。
insert成员函数
从形式上看,map/multimap集合的insert成员都具 有相同的形式:
insert(e)但insert插入到map/multimap和set/multiset的元素 是有区别的。插入到set/multiset中的元素是单独的 键,而插入到map/multimap中的元素是<键,值>构 成的一对数据,这对数据是一个不可分割的整体。 map/multimap的<键,值>可用make_pair函数构 造,形式如下:
make_pair(e1, e2); //e1代表键 e2代表值元素访问
map/multimap映射的元素是由<键,值>对构成的, 且同一个键可以对应多个不同的值,可以通过相关映 射的迭代器访问他们的元素。 map/multimap类型的迭代器提供了两个数据成员:一 个是first,用于访问键;一个是second用于访问值。 此外map类型的映射可以用键作为数组下标,访问该 键所对应的值,但multimap类型的映射不允许用数 组下标的方式访问其中的元素。
实例1: 用map查询员工工资
#include map和multimap的用法基本相同,区别在于map映 射中的键不允许重复,而multimap中的键允许重 复。此外map允许数组的下标运算访问映射中的值, 而multimap是不允许的,multimap在构造一键对多 值得查询时非常有用。
实例2:用multimap构造汉英对照词典
#include 1.4.4 算法
算法(algorithm)是用于模板技术实现的适用于各种容器 的通用程序。算法常常通过迭代器间接地操作容器元 素,而且通常会返回迭代器作为算法运算的结果。
STL大约提供了70个算法,每个算法都是一个模板函数 或者一组模板函数,能够在许多不同类型的容器上进行 操作,各个容器则可能包含着不同类型的数据元素。 STL中的算法覆盖了在容器上实施的各种常见操作,如 遍历、排序、检索、插入及删除元素等操作。STL中许多算法不仅适用于系统提供的容器类,而且适用于普通 的C++数组或自定义容器。
下面介绍几个常用算法:
-
find 和 count算法
find用于查找指定数据在某个区间中是否存在,该函 数返回等于指定值的第一个元素位置,如果没找到就 返回最后元素位置;count用于统计某个值在指定区 间出现的次数,其用法如下:
find(beg, end, value); count(beg, end, value);#include#include using namespace std; int main(void){ int a1[] = {12,13,14,15,16,17,18,19}; int *ptr = find(a1, a1+8, 17); //操作基本类型 cout << "17在a1数组当中的位置:" << ptr-a1 << endl; list<int> L1; int a2[] = {62,63,64,65,66,67,68,68}; for(int i=0; i<sizeof(a2)/sizeof(a2[0]); i++){ L1.push_back(a2[i]); } list<int>::iterator it; it = find(L1.begin(), L1.end(), 68); //操作容器类型 if(it != L1.end()){ cout << "L1链表中存在元素:" << *it << endl; cout << "它是链表中第 " << distance(L1.begin(), it) + 1 << " 个节点" << endl; } int n1 = count(a1, a1+8, 18); cout << "a1 数组中 18 出现了:" << n1 << " 次" << endl; int n2 = count(L1.begin(), L1.end(), 68); cout << "a2 数组中 68 出现了:" << n2 << " 次" << endl; return 0; } -
search算法
find算法从一个容器中查找指定的值,search算法则 是从一个容器查找由另一个容器所指定的顺序值。 search用法如下所示:
search(beg1, end1, beg2, end2);//左闭右开search将在[beg1, end1)区间查找有无与[beg2, end2)相同的子区间,如果找到就返回[beg1, end1) 内第一个相同元素的位置,如果没有找到返回end1;
#include#include #include using namespace std; int main(void){ int a1[] = {12,13,14,15,16,17,18,19}; int a2[] = {17,18,19}; int *ptr = search(a1, a1+8, a2, a2+3); if(ptr == a1+9) cout << "not match" << endl; else cout << "match: " << ptr-a1 << endl; list<int> L; vector<int> V; for(int i=0; i<9; i++){ L.push_back(a1[i]); } for(int i=0; i<3; i++){ V.push_back(a2[i]); } list<int>::iterator pos; pos = search(L.begin(), L.end(), V.begin(), V.end()); if(pos == L.end()) cout << "not match" << endl; else cout << "match: " << distance(L.begin(), pos) << endl; return 0; } -
merge
merge可对两个容器进行合并,将结果存放在第3个 容器中,其用法如下:
merge(beg1, end1, beg2, end2, dest);merge将[beg1,end1)与[beg2, end2)区间合并,把 结果存放在dest容器中。如果参与合并的两个容器中 的元素是有序的,则合并的结果也是有序的。
list链表也提供了一个merge成员函数, 它能够把两 个list类型的链表合并在一起。同样地,如果合并前 的链表是有序的,则合并后的链表仍然有序。
#include#include #include using namespace std; int main(void){ int a1[] = {12,13,14,15,16,17,18,19}; int a2[] = {17,18,19}; int a3[20] = {0}; merge(a1, a1+8, a2, a2+3, a3); for(int i=0; i<11; i++){ cout << a3[i] << "\t"; } cout << endl; list<int> L1; list<int> L2; for(int i=0; i<8; i++){ L1.push_back(a1[i]); } for(int i=0; i<3; i++){ L2.push_back(a2[i]); } L1.merge(L2); list<int>::iterator it; for(it=L1.begin(); it!=L1.end(); it++){ cout << *it << "\t" ; } cout << endl; return 0; } -
sort
sort可对指定容器区间内的元素进行排序,默认排序 的方式为从小到大,其用法入下:
sort(beg, end);[beg, end)是要排序的区间,sort将按从小到大的顺 序对该区间的元素进行排序。
#include#include #include using namespace std; int main(void){ int a1[] = {18,23,34,55,26,10,101,11}; int a2[] = {38,29,94,85,76,60,301,31}; sort(a1, a1+8); for(int i=0; i<8; i++){ cout << a1[i] << " " ; } cout << endl; vector<int> V; for(int i=0; i<8; i++){ V.push_back(a2[i]); } sort(V.begin(), V.end()); //排序 vector<int>::iterator it; for(it=V.begin(); it!=V.end(); it++){ cout << *it << " " ; } cout << endl; return 0; }